If Walrus mainnet adoption has a backbone, Red Stuff is it. Not as a buzzword, not as a whitepaper flex, but as the reason real teams are comfortable putting important data on Walrus and walking away. Red Stuff is the part of Walrus that turns storage from “hopefully available” into something you can actually build products on without hedging every decision.
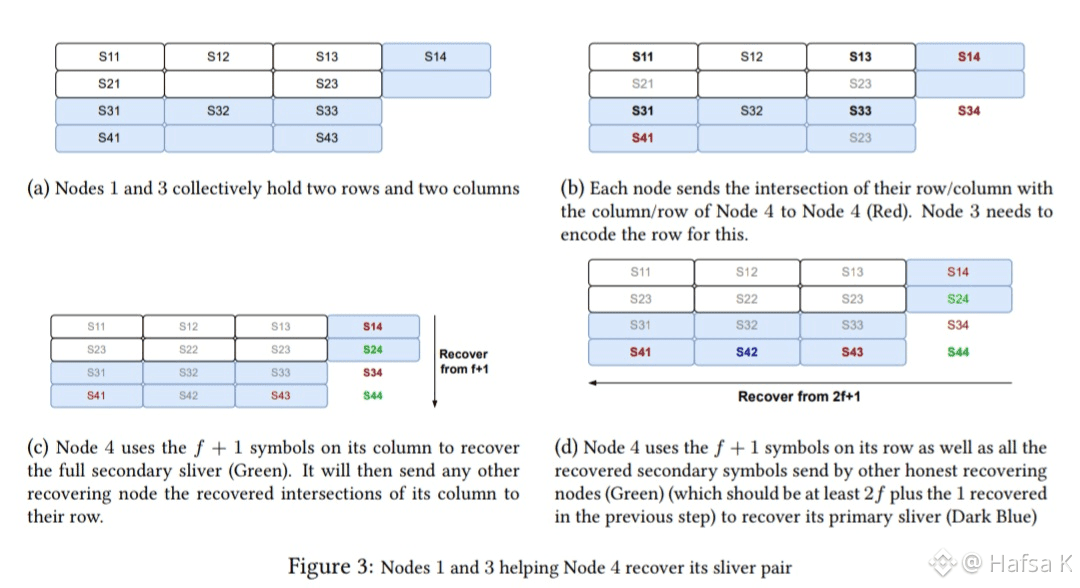
Red Stuff is Walrus’s two-dimensional erasure coding scheme. That sounds academic until you see what it replaces. Traditional decentralized storage either copies full files many times or uses one-dimensional erasure coding where losing a small fragment forces you to re-download almost everything. Walrus does neither. When a blob is uploaded to Walrus, Red Stuff slices it into structured slivers across a committee. Each sliver carries just enough information that missing pieces can be reconstructed by fetching only what is lost. Recovery cost scales with failure, not with total data size. That is the core difference.
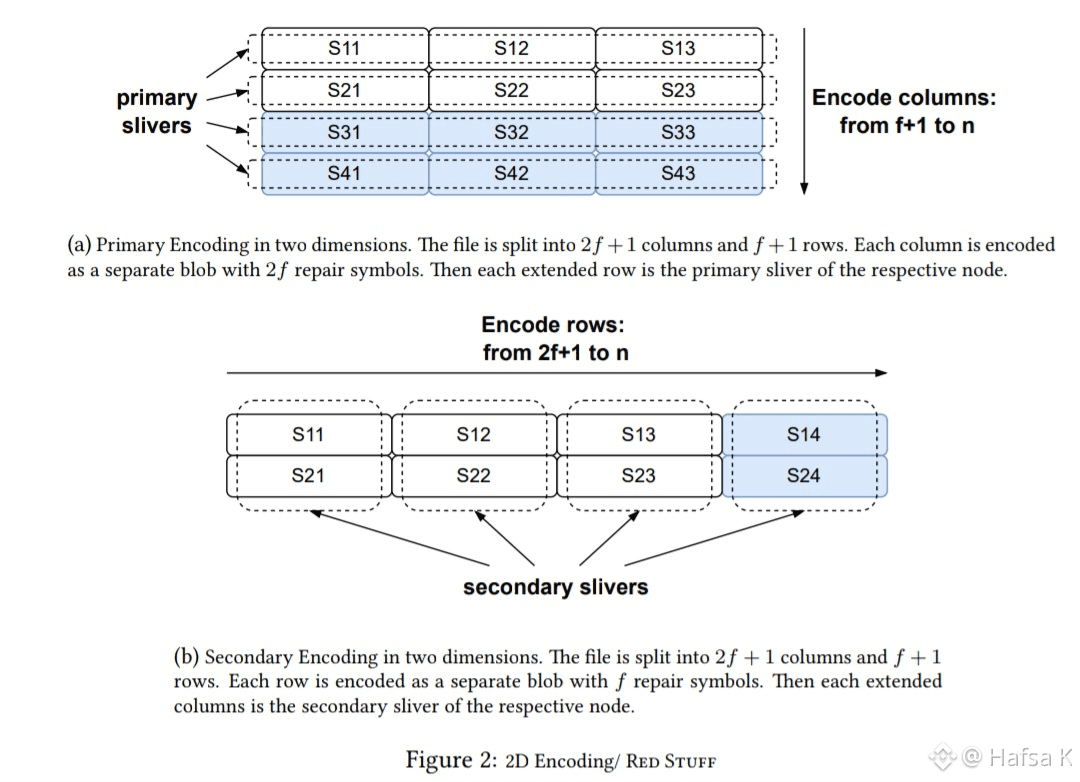
This matters immediately in production. On Walrus, storage nodes do not need to hold full replicas to be trusted. They hold slivers, serve them when asked, and prove availability during epochs. If a node drops out, the network does not panic and rebuild the world. It repairs the missing pieces precisely. That efficiency is why Walrus can hit durability targets with roughly 4.5x overhead instead of the double-digit replication factors seen in other systems. Less redundancy means fewer disks, less bandwidth, and lower ongoing costs.
Compare that to Filecoin’s proof-of-replication model. Filecoin focuses on proving that a full copy exists over time. That works well for long-term deals but creates heavy storage and verification overhead. IPFS, on the other hand, does not guarantee anything on its own. It moves data efficiently but relies on external pinning to keep content alive. Walrus, through Red Stuff, sits in a different place. Availability is enforced by protocol economics, and efficiency is enforced by math. Walrus does not ask nodes to lie less. It asks them to store less, more intelligently.
In practice, Red Stuff changes recovery behavior dramatically. Imagine a large media file or dataset stored on Walrus. If one node disappears mid-epoch, the system does not reassemble the entire blob just to patch a hole. It reconstructs only the missing sliver. That keeps recovery bandwidth low and predictable. For applications serving users in real time, predictability matters more than theoretical throughput. Walrus trades peak speed for stable behavior under stress, which is exactly what infrastructure should do.
This becomes especially important for AI workloads. AI datasets are large, reused, and frequently audited. Training runs may need to fetch specific subsets of data repeatedly. Inference systems may need to verify provenance without pulling everything down. Red Stuff enables this pattern. Data can be reconstructed partially and efficiently. Availability proofs do not explode with dataset size. Walrus becomes a place where AI teams can store data once and reuse it many times without drowning in bandwidth costs.
Real-time applications benefit in a similar way. Think of analytics feeds, gaming state snapshots, or content platforms serving large assets. With Red Stuff, Walrus can tolerate node churn without creating latency spikes that users feel. When a user requests a blob, the system fetches slivers in parallel from a committee. If one path fails, others compensate. The user sees a load time that stays within a narrow range instead of occasionally breaking. That consistency is why teams trust Walrus for live products, not just archives.
There is a subtle integrity angle here that often gets overlooked. Because Red Stuff ties data encoding to committee membership and epochs, availability is auditable on chain. Walrus does not rely on trust that “someone somewhere has a copy.” It relies on continuous checks that slivers are actually being served. If not, stake is at risk. Red Stuff is not just about efficiency. It is about making integrity verifiable without copying everything everywhere.
This design also forces discipline. Walrus does not let developers pretend data is free to keep forever. Red Stuff makes storage efficient, but it does not make it infinite. Blobs expire unless renewed. That means teams must decide what deserves to live. Red Stuff lowers the cost of honesty, but it does not remove the need for it.
The real implication lands when you connect everything. Red Stuff is why Walrus can support media platforms, AI systems, identity infrastructure, and real-time apps on the same network without collapsing under its own weight. It is why WAL pricing can reflect real demand instead of worst-case paranoia. And it is why Walrus storage feels boring in the best possible way.
If you are interacting with Walrus today, whether as a builder, node operator, or observer, Red Stuff is the reason the system behaves predictably. It is not a feature you toggle. It is the reason the protocol can afford to exist at scale.

