
Analyse der Auswahl für AI-Start-ups: Kosten- und ROI-Vergleich zwischen Cloud- und On-Premises-Deployment von GPU (dieser Artikel basiert auf Inhalten, die von der offiziellen Seite bereitgestellt wurden, und dient der Zusammenfassung und Forschung).
Hier sind die detaillierten Kostenaufschlüsselungen für GPU-Deployment in der Cloud und vor Ort (On-Premises).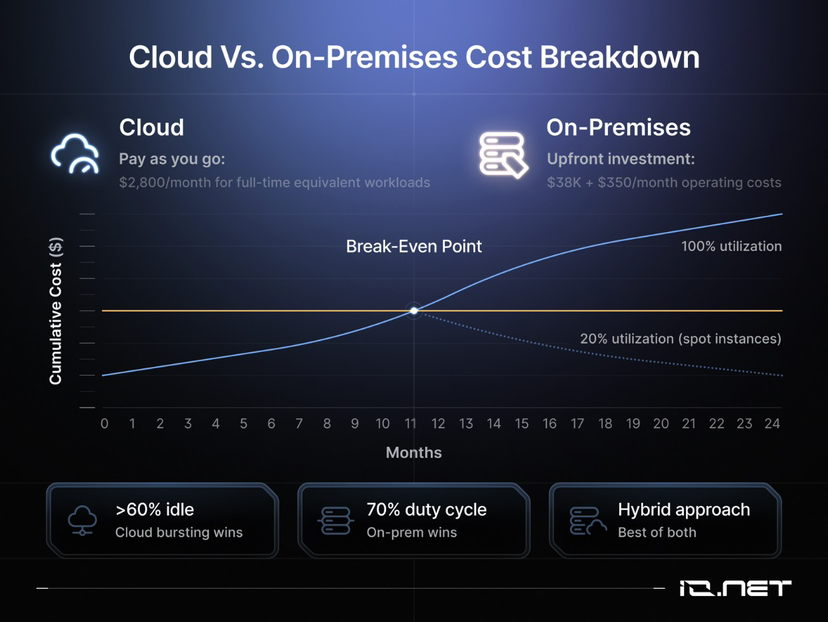
1. Kostenvergleichsdaten
• On-Premises-Deployment: Die Anfangsinvestition für einen 64-Kern-GPU-Cluster beträgt etwa 38.000 US-Dollar, zusätzlich fallen jährlich etwa 4.200 US-Dollar an Stromkosten an.
• Cloud-Miete: Die Kosten für gleichwertige Cloud-Ressourcen betragen etwa 2.800 US-Dollar pro Monat.
2. Gewinn- und Verlust-Grenze sowie Analyse der Einsatzszenarien
Der Break-even-Punkt für die lokale Bereitstellung liegt bei 14 Monaten, dies gilt jedoch nur, wenn die Geräte 24/7 rund um die Uhr betrieben werden. Wenn die Betriebszeit der Arbeitslast nur 20 % beträgt, hat die Nutzung von Cloud-Spot-Instanzen (Spot Instances) eine bessere Kapitalausgaben (Capex) Effizienz.
3. Ressourcenorchestrierung und Flexibilität
Ressourcenorchestrierung ist der Schlüssel zur Erreichung von architektonischer Flexibilität. Bezugnehmend auf gängige Architekturen von Fintech-Unternehmen: Verwenden Sie Tools wie Slurm-on-Kubernetes, um sensible Modelle lokal auszuführen, während bei Bedarf an großflächiger Rechenleistung (z. B. nächtliche Tests) auf über 10.000 Cloud-Kerne skaliert wird.
4. Beschaffungsentscheidungsgrenze
Es wird empfohlen, Entscheidungen auf der Grundlage von Kernstunden (Core-hours) zu treffen:
• Hardware kaufen: Die Arbeitslast übersteigt 1.200 Kernstunden/Monat.
• Cloud mieten: Die Arbeitslast liegt unter diesem Wert.
5. Überwachung der Auslastung und Ressourcenanpassung
Es sollten die tatsächlichen GPU-Auslastungsdaten aufgezeichnet werden, anstatt zu raten:
• Wenn die freie Zeit > 60 % beträgt: Dies weist auf eine Verschwendung von Hardware-Ressourcen hin, und es sollte in den Cloud-Bursting-Modus gewechselt werden.
• Wenn die Auslastungsrate (Duty Cycle) über 70 % anhält: Es wird empfohlen, Hardware zu kaufen oder Bare-Metal-Server zu mieten.
6. Strategien für großangelegte parallele Verarbeitung
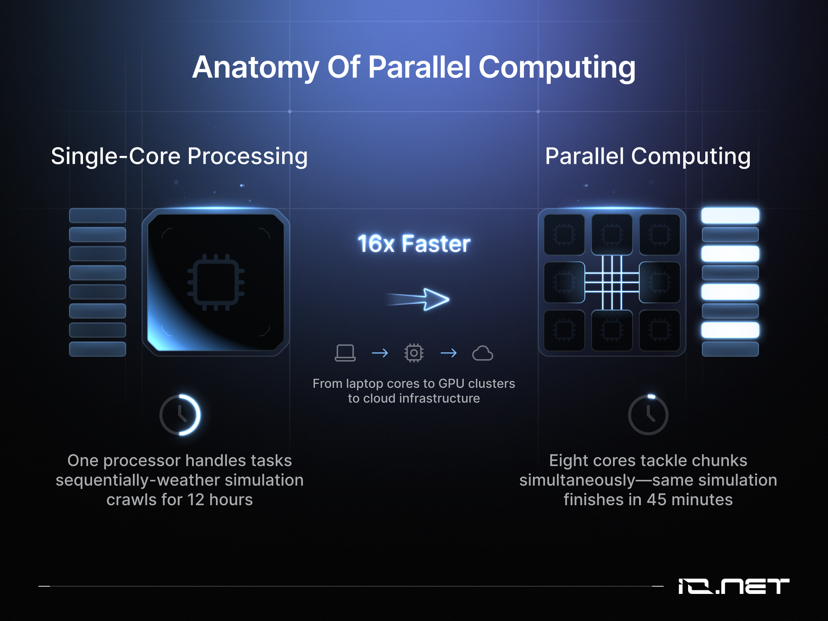
Für großangelegte Arbeitslasten wird empfohlen, eine hybride Strategie zu verwenden: Die grundlegende Rechenleistung bleibt lokal, während dezentralisierte Cloud-Ressourcen zur Deckung von Spitzenbedarfen genutzt werden. Die Nutzungsdaten sollten kontinuierlich überwacht und die Ressourcengröße dynamisch angepasst werden.


