You ever train a model and get that weird feeling like… “wait, did my data just change?”
Not a new file. Not a clear edit. Just a silent drift. And suddenly your results don’t match yesterday.
I’ve seen teams treat AI datasets like a folder on one “trusted” server. A bucket. A drive link. One admin account. One vendor. One place where a tiny switch can flip and nobody notices until it’s too late. That’s the scary part with data poisoning and quiet tamper risk. It’s not always loud. It’s often boring. A label changed. A few images swapped. A CSV row nudged. And then your model learns the wrong thing with a straight face. So the real question becomes simple and kind of uncomfortable: who do you actually trust to hold your dataset?
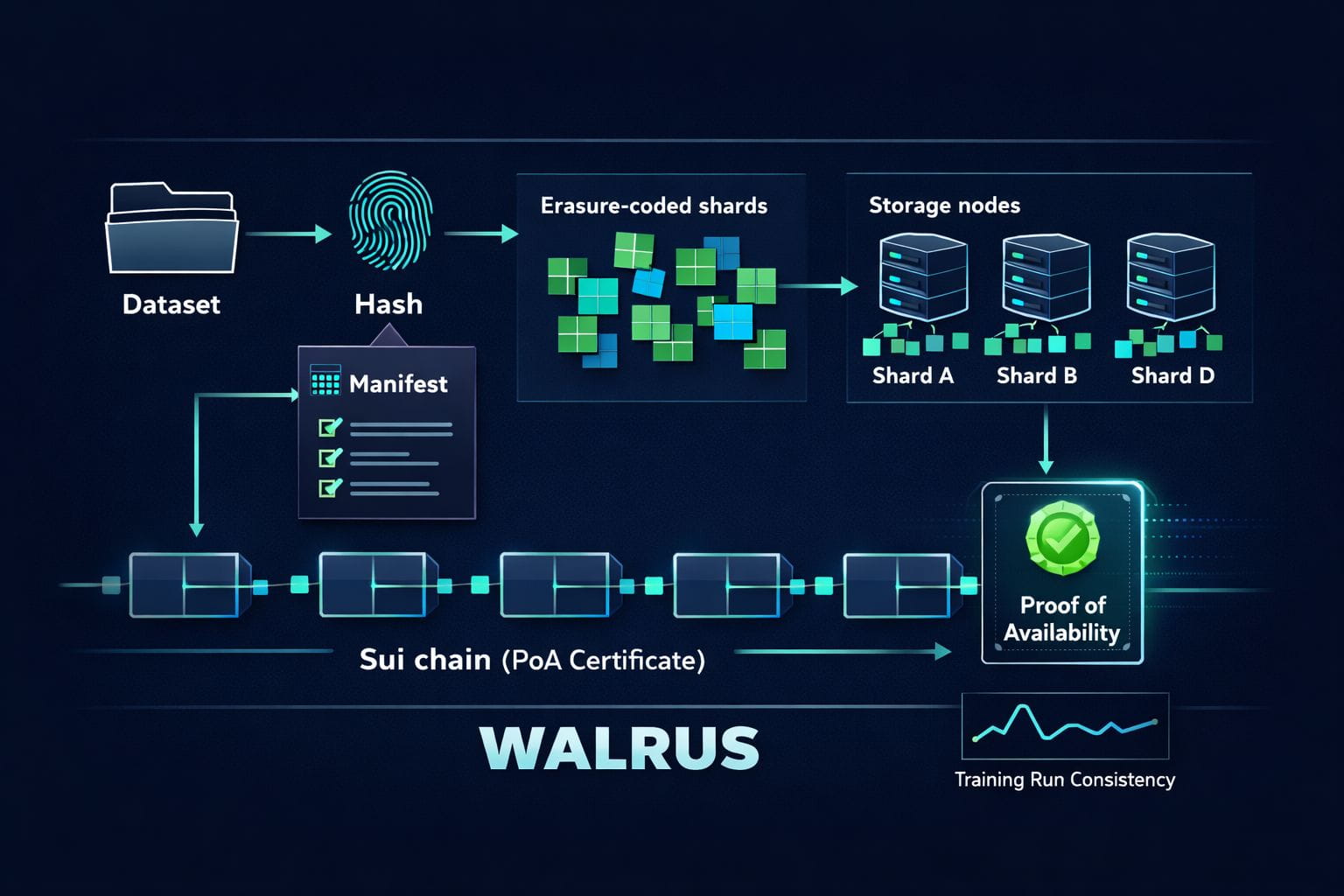
This is where Walrus comes in. Walrus (WAL) is built for big “blob” data, meaning large files like images, video, archives, or full dataset chunks. Instead of parking those blobs on one host and praying, Walrus spreads the job across many storage nodes. The clever bit is that it uses Sui as a control layer for the important “receipt” part: metadata, commitments, and an onchain Proof-of-Availability certificate. In plain words, that certificate is like a public stamp that says, “this exact data was stored and is now owed to the network for reads.”
Now let’s unpack the main idea that makes “integrity without trusting a single host” feel real. Walrus relies on erasure coding. Think of it like turning your dataset into a puzzle. You cut it into many pieces, add some extra pieces, and spread them around. You don’t need every piece back to rebuild the original. You only need “enough.” That means a few nodes can go offline, or act weird, and you can still recover the full blob. Walrus docs talk about storing encoded parts across storage nodes, aiming for strong resilience without full copy-paste replication everywhere.
Integrity is the other half. The simple version: you tie the dataset to a fingerprint. A hash is that fingerprint - a short string made from the data itself. Change even one tiny byte, and the fingerprint changes. So if your training pipeline says “I want blob X,” it can check that the bytes it got match the fingerprint it expected. If some host tries to hand you a “close enough” file, it fails the check. No trust needed. Just math. And when the network publishes availability proof on-chain, it becomes easier to show third parties, “this dataset version existed, at this time, and it’s the same one I used.”
Okay, so how does this play out for AI datasets in real life? Picture a dataset not as one giant zip, but as a living thing: shards, versions, patches, new labels, removed samples. Most teams track this with hope and naming habits. “final_final_v7.” You know the vibe. Walrus pushes you toward something cleaner: treat each dataset chunk as an addressable object, then treat the dataset itself as a manifest - a simple list that says which chunks belong, plus their fingerprints. When you update the dataset, you publish a new manifest. Old one stays. New one is distinct. No silent overwrite.
That changes the daily workflow. A researcher can say, “I trained on manifest A.” Another can fetch the same manifest A later and get the same bytes, even if some storage nodes changed. A reviewer can reproduce results without begging for access to a private drive. And if you’re building a model for something serious - finance, health, safety, compliance - this audit trail vibe matters. Not because it’s flashy. Because it reduces “trust me” moments.
There’s also a subtle win here: you stop trusting the hosting story, and start trusting the proof story. With a single host, the host is the truth. With Walrus, the data fingerprint and the onchain certificate become the truth, and storage nodes are just workers that must match the receipt. That’s a big mental shift. It’s like moving from “I believe the librarian” to “I can verify the book seal myself.”
One more honest note, because it’s important: data integrity is not the same as data quality. Walrus can help you prove you got the same dataset you asked for, and that it stayed available. It can’t magically tell you whether the dataset is biased, licensed correctly, or ethically sourced. You still need good rules for consent, privacy, and curation. But as a base layer for “no silent edits, no single point of trust,” it’s a strong idea. Not financial advice. Just a view on data rails. And if you’re building with AI right now, ask yourself this: when your model output changes, can you prove your dataset didn’t? Or are you still relying on “pretty sure nobody touched it”?
@Walrus 🦭/acc #Walrus $WAL #Web3

