
A blockchain does not fail loudly when something goes wrong. More often, it fails quietly. Blocks stop appearing. Transactions wait. Users refresh their wallets and wonder if the issue is local or systemic. This kind of failure is called a liveness failure, and it is one of the most underestimated risks in blockchain design. Plasma starts from this uncomfortable truth. It does not assume validators will always act correctly, stay online, or coordinate smoothly. It assumes the opposite. Some validators will fail. Some will stall. Some may even try to disrupt progress. The real question is not whether this happens, but whether the network can continue operating when it does. Plasma’s architecture is built around that question. Instead of treating liveness as an operational problem to be solved later, it treats it as a core design constraint. The result is a system that focuses less on ideal behavior and more on predictable recovery. This matters because real-world usage is messy. Networks experience outages. Leaders go offline. Validators hesitate or act slowly. Plasma accepts these conditions as normal and designs the network to move forward anyway, even under pressure.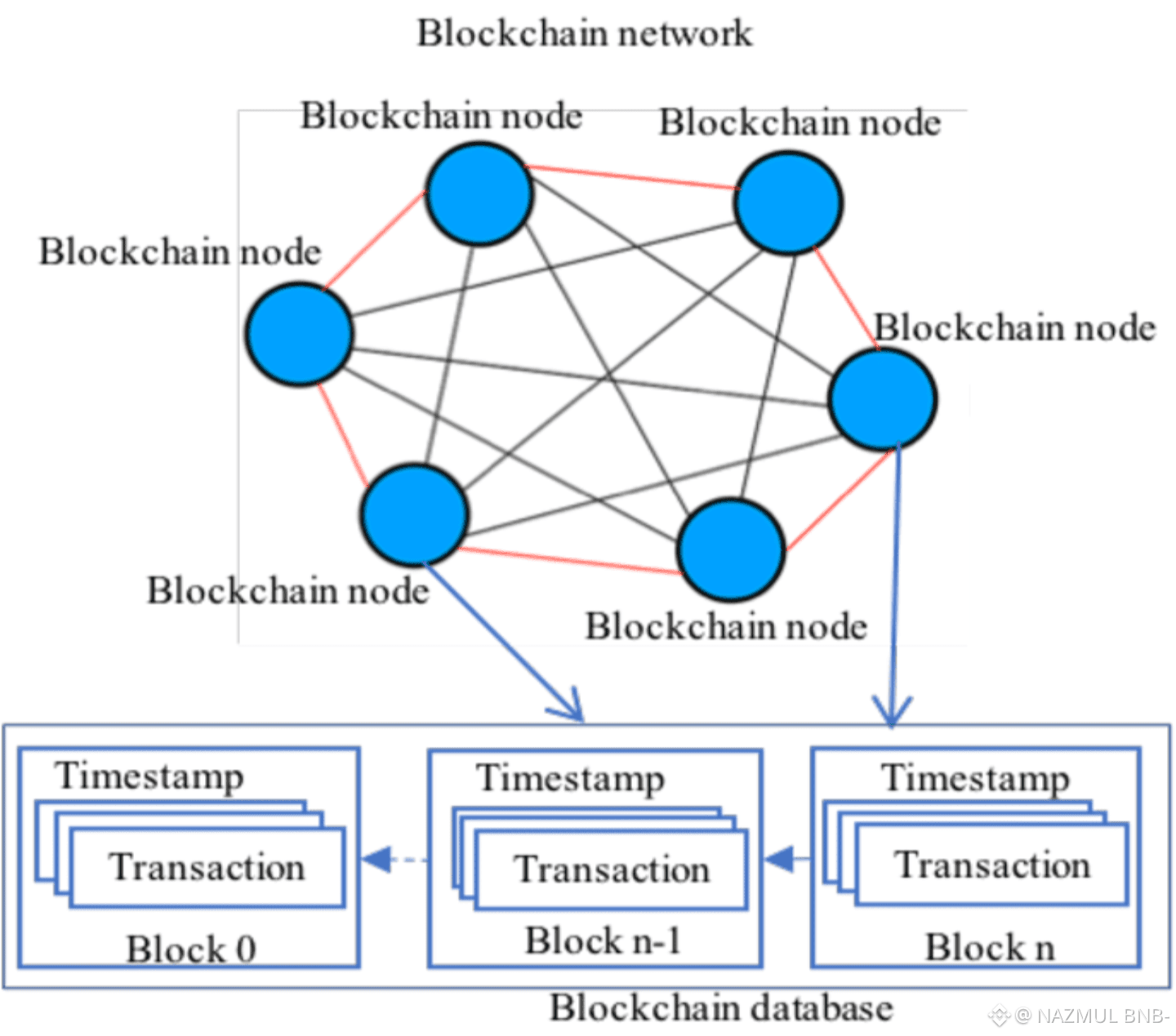
To understand why this matters, it helps to picture what a liveness attack actually looks like. It is rarely dramatic. There is no invalid block, no obvious double spend. Instead, one or more validators, often including the current leader, simply stop doing their job. They do not propose blocks. They do not vote. They do nothing. From the outside, the network appears frozen. In many systems, this silence is enough to halt progress entirely. Plasma assumes this will happen and builds around it. Its consensus mechanism, PlasmaBFT, is designed so that no single validator, and no small group of validators, can stall the network for long. Leadership rotates quickly and predictably. If a leader fails to act within a defined time window, the network does not wait or negotiate. It moves on. Silence is treated as a fault, not an inconvenience. This is a subtle but important distinction. By detecting inactivity through timeouts and triggering automatic leader changes, Plasma limits the damage any one participant can cause. The network does not need perfect coordination or unanimous agreement. It only needs a sufficiently large honest majority to keep going.
This approach is especially important for networks that handle stablecoins and payments. If you are experimenting with NFTs or governance votes, a short network stall is frustrating but survivable. If you are settling payments, delays quickly become unacceptable. People expect money to move when they press send. Plasma’s design reflects this reality. PlasmaBFT follows a well-understood principle from Byzantine fault tolerant systems: as long as fewer than one third of validators are faulty or malicious, the network can continue to make progress. This is not an aspirational goal. It is a mathematical property of the system. Blocks are finalized once a supermajority agrees, which means the network does not need every validator to participate in every round. A portion of the validator set can be offline or unresponsive without stopping the chain. This makes liveness less fragile. Progress does not depend on perfect behavior, only on sufficient participation. Over time, this difference shapes how the network feels to users. Instead of sudden, unexplained halts, the system degrades gracefully and recovers automatically.
Technical mechanisms alone are not enough to protect liveness. Plasma also uses economic incentives to reinforce good behavior. Validators are required to stake XPL to participate. That stake is not just symbolic. Validators who fail to meet their responsibilities risk losing rewards and, in some cases, facing penalties. The goal is not punishment for its own sake, but alignment. Keeping the network live is in the validator’s direct economic interest. At the same time, Plasma recognizes that not all failures are malicious. Hardware fails. Networks drop packets. Data centers experience outages. This is why the system also emphasizes operational discipline. Validator infrastructure is expected to meet high performance standards, with attention to latency, redundancy, and geographic diversity. If too many validators rely on the same provider or region, a single outage can look like a coordinated attack. Plasma treats this as a design risk, not an edge case. By encouraging diversity at the infrastructure level, it reduces correlated failures that could threaten liveness even when no one is acting maliciously.
Ultimately, liveness is a measure of maturity. Early blockchains focused on correctness: making sure nothing bad could happen. Modern blockchains must also focus on availability: making sure something good can still happen when parts of the system fail. Plasma’s approach reflects this shift. It does not promise that the network will never stall. No serious system can make that claim. What it offers instead is structure. Clear assumptions about failure. Clear rules for recovery. Clear incentives for participation. When validators stop responding, the network does not rely on goodwill or manual intervention. It follows its design and moves forward. For users and builders, this translates into reliability that is felt rather than advertised. Transactions settle. Applications remain usable. The system behaves like infrastructure, not an experiment. In a space where trust is often earned through slogans and throughput charts, Plasma makes a quieter claim. When things go wrong, it knows what to do next.

