A few months back, I was running a small AI experiment on-chain. Nothing fancy. Just feeding a set of images into a basic model to test pattern recognition. I’d stored the data on a decentralized storage network, assuming availability wouldn’t be an issue. Halfway through the run, things started breaking down. A couple of nodes dropped, access slowed, and pulling the full dataset turned into a cycle of retries and partial fetches. I’ve traded infrastructure tokens long enough to know this isn’t unusual, but it still hit the same nerve. The cost wasn’t the problem. It was the uncertainty. When data needs to be there now, not eventually, even short interruptions derail everything. What should have been a clean experiment stretched into a messy workaround, and it made me question how ready this stack really is once you move past demos.
That gets to the real pain point in decentralized storage. It’s not raw capacity. It’s availability. Cloud providers sell uptime by overbuilding redundancy, but they centralize control, charge aggressively for frequent access, and leave users trusting someone else’s guarantees. On the decentralized side, storage is often treated as an accessory, bundled alongside execution layers that care more about throughput than persistence. The result is uneven retrieval, especially for large blobs like videos, models, or datasets. Users pay for decentralization, but when networks get stressed, access slows, costs spike, and the experience feels stitched together. Managing keys, waiting on confirmations, and hoping the right nodes stay online isn’t how most developers want to ship real products. That gap keeps serious applications on the sidelines, especially anything involving AI, media, or live data.
I usually think about it like a city library system. Books are spread across branches so no single location gets overloaded. That works until a few branches close unexpectedly. Suddenly requests pile up, transfers take longer, and access degrades across the whole system. The design challenge isn’t just distributing content. It’s ensuring that everyday closures don’t affect readers at all. True availability means users never notice when parts of the system disappear.
Walrus takes a narrower approach to that problem. Instead of trying to be everything, it focuses on blob storage that stays available even when parts of the network fail. Built on Sui, it handles large, unstructured data by splitting files into fragments and distributing them across independent nodes. As long as enough of those nodes remain online, the data can be reconstructed. It deliberately avoids full smart contract execution, using Sui mainly for coordination, metadata, and verification. The goal is simple: strong cryptographic guarantees around availability without dragging in unnecessary complexity. By keeping computation off the storage layer and relying on fast finality for proofs, it targets use cases where downtime isn’t acceptable, like AI systems pulling datasets mid-run or applications serving user content without delays. In theory it’s chain-agnostic, but in practice it leans on Sui’s responsiveness to keep verification fast.
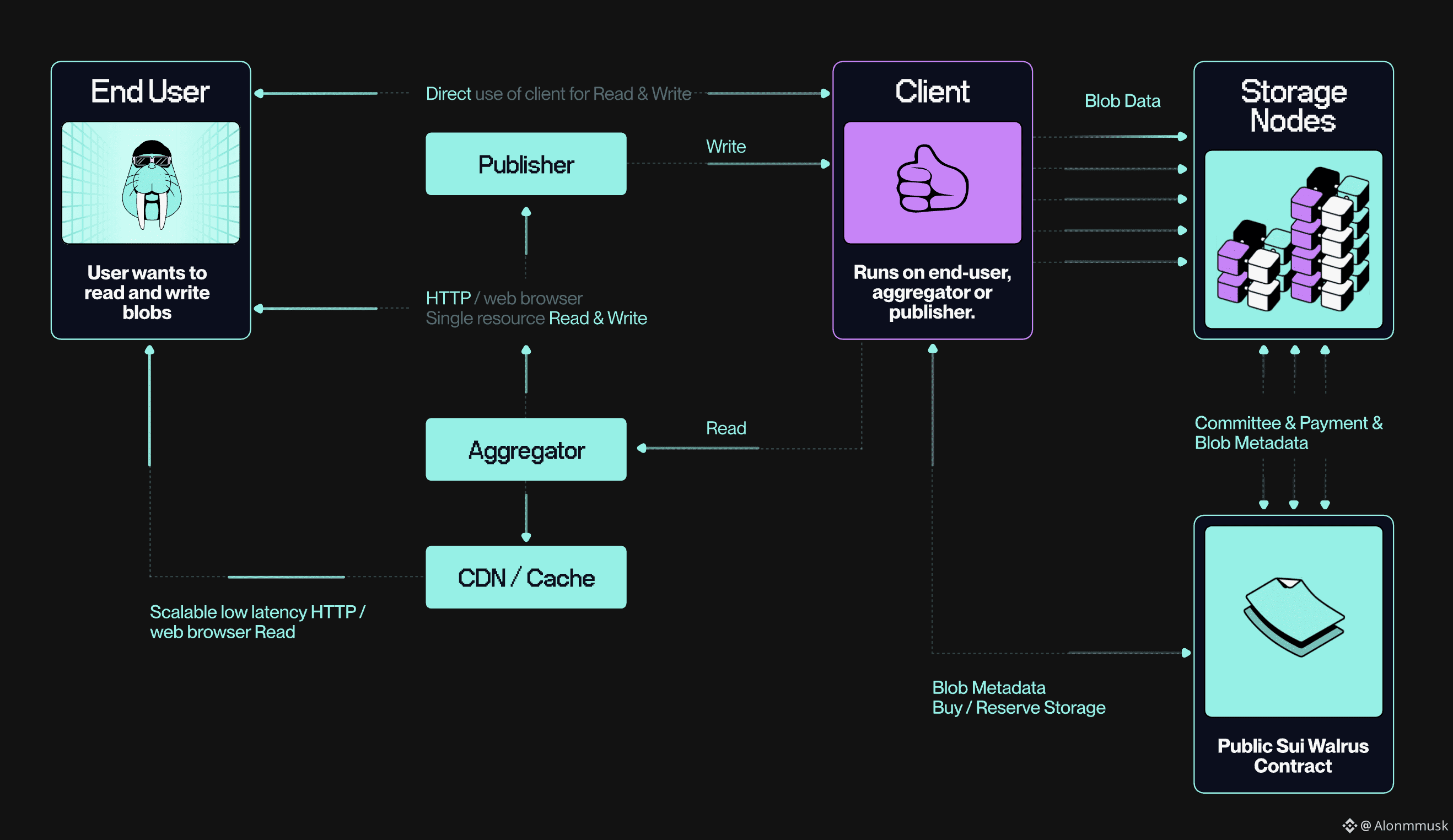
One concrete design choice is its Red Stuff encoding. Instead of full replication, data gets split into shards using fast XOR-based erasure coding. A one gigabyte file might become a hundred fragments, with only seventy needed to rebuild it. That keeps storage efficient and spreads risk across the network, but it comes with trade-offs. If too many shards disappear at once, reconstruction costs spike. Another layer is how availability gets certified. Sui objects act as lightweight certificates that confirm a blob exists and can be retrieved, letting applications verify availability without downloading the data itself. That keeps checks cheap and fast, but it also ties scale to Sui’s throughput limits, which puts a ceiling on how many blob operations can be processed in each block.
The WAL token sits quietly underneath all of this. It’s used to pay for uploads and ongoing storage, with costs smoothed over time so users aren’t exposed to wild price swings. Storage deals lock WAL based on usage duration, while nodes stake it to participate in the network. If they pass periodic availability challenges, they earn rewards. If they don’t, they get slashed. Settlement happens on Sui, where WAL transfers finalize storage agreements, and governance uses staked tokens to adjust parameters like encoding thresholds or reward curves. Everything ties back to uptime. There’s no attempt to dress it up with flashy incentives. The economics exist to keep nodes online and data accessible.
From a market perspective, supply sits around 1.58 billion tokens, with capitalization near 210 million dollars and daily volume around 11 million. Liquid enough to move, but not driven by constant speculation.
Short-term price action usually follows narratives. Campaigns like the Binance Square CreatorPad push in early January brought attention and short-lived volume spikes, followed by predictable pullbacks. Unlocks, especially the large tranche expected in March 2026, create volatility windows that traders try to time. I’ve seen this cycle enough times to know how quickly focus shifts. Long-term, though, the question is simpler. Does reliability create habit? If Walrus becomes the default storage layer for teams building on Sui, especially for AI workflows that need verifiable data access, demand grows naturally through fees and staking. That kind of adoption doesn’t show up overnight. It shows up in quiet metrics and steady usage.
The risks are real. Filecoin and Arweave already have massive networks and mindshare. If Sui’s ecosystem doesn’t expand fast enough, developers may stick with what they know. Regulatory scrutiny around data-heavy protocols, especially in AI contexts, adds another unknown. One failure scenario that’s hard to ignore is correlated outages. If Sui itself stalls or a large portion of storage nodes drop simultaneously, availability guarantees weaken fast. Falling below reconstruction thresholds during a high-demand event could lock data out for hours, and trust is hard to rebuild once that happens.
In the end, storage infrastructure doesn’t win by being loud. It wins by disappearing into the background. The real signal isn’t launch announcements or incentives. It’s whether the second, tenth, or hundredth data fetch just works without anyone thinking about it. Watching how Walrus behaves as usage compounds will show whether availability becomes a habit, or remains just another constraint developers have to work around.
@Walrus 🦭/acc #Walrus $WAL


