

Lange Zeit habe ich beobachtet, wie der AI-Bereich von der Aufforderungs-Engineering besessen war. Jeder versuchte, die perfekte Formulierung, den cleveren Trick, die magische Abfolge von Tokens zu finden, die bessere Antworten aus großen Sprachmodellen herausholen könnte. Aber je mehr ich mit diesen Systemen arbeitete, desto offensichtlicher wurde mir, dass Aufforderungen nie das eigentliche Problem waren. Sie waren eine Umgehung für einen viel tiefer liegenden Fehler. Moderne AI-Systeme erinnern sich tatsächlich an nichts. Sie sind von Natur aus zustandslos. Jeder neue Chat ist ein Reset, und diese einzelne architektonische Wahl zwingt die Benutzer in eine endlose Schleife des erneuten Erklärens, des erneuten Hochladens von Dokumenten und des wiederholten Aussetzens sensibler Informationen.
Diese Abhängigkeit von öffentlichen Eingabeaufforderungen - bei denen jede Anweisung, Datei und jedes Kontextstück offen an einen Modellanbieter gesendet wird - fühlt sich für jeden ernsthaften Anwendungsfall grundlegend defekt an. Sie schafft unnötige Sicherheitsrisiken, Datenschutz-Albträume und die Offenlegung von geistigem Eigentum. Aus meiner Sicht hat die Zukunft vertrauenswürdiger KI sehr wenig mit besseren Eingabeaufforderungen zu tun und alles mit einem strukturellen Wandel hin zu verschlüsseltem, persistentem, benutzereigenem Kontext.
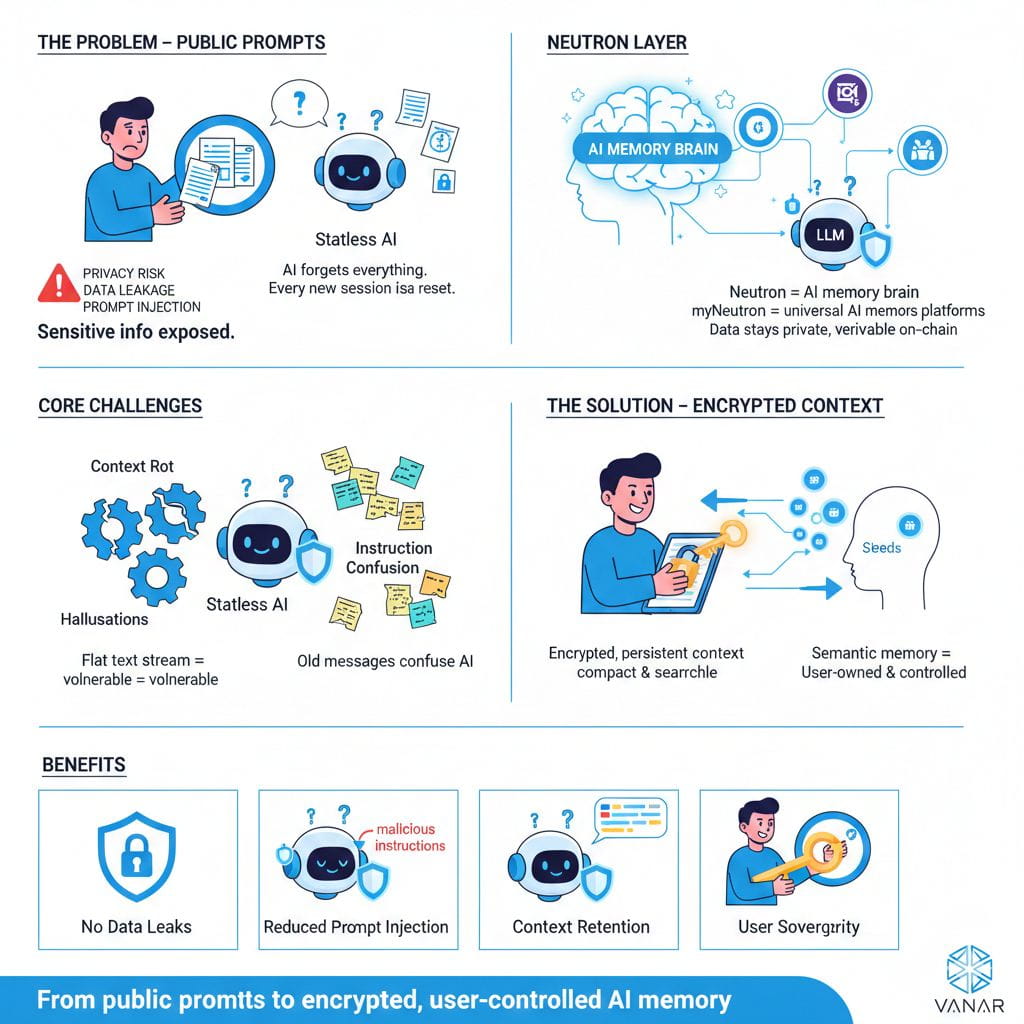
Das öffentliche Prompt-Modell scheitert auf einer sehr grundlegenden Ebene. Jedes Mal, wenn Sie vertrauliche Daten in einen KI-Chat einfügen, verlieren Sie die Kontrolle darüber. Hochkarätige Vorfälle wie die Samsung-Leaks, bei denen Mitarbeiter versehentlich proprietären Quellcode und interne Besprechungsaufzeichnungen mit ChatGPT teilten, waren keine Ausnahmefälle. Sie waren vorhersehbare Ergebnisse eines Systems, das annimmt, dass Benutzer sich immer perfekt verhalten. In Wirklichkeit bewegen sich Menschen schnell, kopieren und fügen impulsiv ein und vertrauen Werkzeugen, die sich gesprächsartig anfühlen. Deshalb zeigen Umfragen konsequent, dass Datensicherheit das größte Hindernis für die Einführung von KI darstellt und warum ein erheblicher Teil der Daten, die von Mitarbeitern in öffentliche KI-Tools eingefügt werden, als vertrauliche Unternehmensinformationen eingestuft wird. Sobald diese Daten in einfacher Form Ihr Gerät verlassen, können sie protokolliert, gespeichert oder sogar verwendet werden, um zukünftige Modelle zu verbessern. An diesem Punkt ist Ihr Wettbewerbsvorteil - Ihre echte „Geheimzutat“ - nicht länger vollständig Ihr Eigentum.
Noch besorgniserregender für mich ist das Problem der Eingabeaufforderungsinjektion. Es geht nicht darum, dass Benutzer nachlässig sind; es handelt sich um eine strukturelle Verwundbarkeit in der Funktionsweise von LLMs. Diese Modelle haben keine native Möglichkeit, zwischen Anweisungen und Daten zu unterscheiden. Wenn ich eine KI frage, ein Dokument zu analysieren, und dieses Dokument versteckte Anweisungen enthält - vielleicht in weißem Text oder tief in den Metadaten vergraben - kann das Modell manipuliert werden, diesen Anweisungen zu folgen, anstatt meinen. In einem rechtlichen, finanziellen oder medizinischen Kontext ist eine solche Art von Fehler nicht nur unbequem, sondern gefährlich. Das Problem liegt nicht darin, dass Modelle schlecht trainiert sind; es liegt daran, dass die Architektur selbst alles als einen einzigen, flachen Textstrom behandelt.
Obendrauf gibt es das Problem der Zuverlässigkeit, das ich als „Kontextverfall“ betrachte. Wenn Gespräche länger werden, füllt sich das Kontextfenster mit einem chaotischen Anhäufung alter Nachrichten, halb relevanten Details und vergessenen Annahmen. Die KI beginnt, den Fokus zu verlieren. Sie halluziniert, fixiert sich auf irrelevante Punkte oder widerspricht sich selbst. Ich vergleiche es oft mit dem Film Memento - eine Intelligenz umgeben von Notizen, die nicht mehr erkennen kann, welche davon wichtig sind. Bei langwierigen Aufgaben oder autonomen Agenten macht diese Instabilität das System grundsätzlich unzuverlässig.
Für mich ist die Lösung klar: KI-Systeme benötigen verschlüsselten Kontext, keine öffentlichen Eingabeaufforderungen. Das ist keine Funktion, die man später anbringt; es ist eine grundlegende Schicht. In einem verschlüsselten Kontextmodell ist der Benutzer souverän. Er hält die Schlüssel. Ihre Daten bestehen über Sitzungen hinweg als private Wissensdatenbank, anstatt nach jedem Gespräch gelöscht zu werden. Informationen werden semantisch gespeichert, als kompakte Einheiten von Bedeutung, die eine KI effizient abrufen kann, anstatt als aufgeblähte Rohdateien. Am wichtigsten ist, dass die Integrität und Herkunft dieses Kontexts kryptografisch verifiziert werden kann, ohne jemals die Inhalte offenzulegen.
Sobald Sie in diesen Begriffen denken, werden die Vorteile offensichtlich. Datenlecks werden neutralisiert, weil sensible Informationen vor dem Betreten eines Netzwerks auf dem Gerät des Benutzers verschlüsselt werden. Dienstanbieter sehen nur Chiffretext. Die Eingabeaufforderung wird viel schwieriger, weil vertrauenswürdiger, benutzereigener Kontext sauber von unzuverlässigen externen Dokumenten getrennt ist, und die Anweisungshierarchie kann auf architektonischer Ebene durchgesetzt werden. Kontextverfall verschwindet, weil die KI nur die genauen Fragmente des Kontexts abruft, die sie für eine bestimmte Aufgabe benötigt, und ihr Arbeitsgedächtnis fokussiert und sauber hält.
Deshalb finde ich den Ansatz von VANAR mit der Neutron-Intelligenzschicht so überzeugend. Neutron ist als persistente, abfragbare Gedächtnisschicht konzipiert - eine Art Gehirn für Daten in Web3. Anstatt Gedächtnis als nachträglichen Gedanken zu behandeln, macht es es zum zentralen Element.
Im Kern von Neutron steht das Konzept eines Samens. Ein Samen ist ein eigenständiges, KI-verbessertes Wissensobjekt. Er kann ein Dokument, eine E-Mail, ein Bild oder strukturierte Daten darstellen, wird jedoch von Grund auf mit Blick auf die Privatsphäre gebaut. Alle Verarbeitung und Verschlüsselung erfolgt lokal auf dem Gerät des Benutzers. Das System komprimiert den Inhalt semantisch und erstellt durchsuchbare Darstellungen seiner Bedeutung, anstatt rohe, offengelegte Dateien zu speichern. Wenn der Benutzer es wünscht, kann ein verschlüsselter Hash und Metadaten on-chain für einen unveränderlichen Nachweis der Existenz und Zeitstempel verankert werden, während die tatsächlichen Daten privat bleiben. Die zentrale Idee ist einfach, aber mächtig: Nur der Eigentümer kann entschlüsseln, was gespeichert ist.
Was das wirklich greifbar macht, ist die benutzerfreundliche Erfahrung über myNeutron. Es fungiert als universelles KI-Gedächtnis, das über Plattformen wie ChatGPT, Claude und Gemini hinweg funktioniert. Anstatt Dateien jedes Mal erneut hochzuladen, kann ich genau den Kontext, den ich von meinen privaten Samen oder Bündeln möchte, mit einem einzigen Klick einfügen. Die KI hört auf, amnesisch zu sein. Sie erinnert sich an das, was ich ihr beigebracht habe, über Sitzungen und über Werkzeuge hinweg, ohne mich zu zwingen, ständig sensible Informationen offenzulegen. Das fühlt sich für mich an, als hätte KI von Anfang an so funktionieren sollen.
VANAR ist nicht allein auf diesem Weg. Andere Projekte, wie NEAR AI Cloud, erkunden vertrauliches Rechnen mit vertrauenswürdigen Ausführungsumgebungen, um sicherzustellen, dass Daten auch während der Inferenz geschützt bleiben. Diese Ansätze sind komplementär. Gemeinsam weisen sie auf eine Zukunft hin, in der Privatsphäre kein Versprechen in einem Vertrag über Dienstleistungen ist, sondern eine Eigenschaft, die durch Kryptographie und Hardware durchgesetzt wird.
Dieser Wandel verändert auch, wie ich über Fähigkeiten in der Ära der KI nachdenke. Die Zukunft gehört nicht den Menschen, die clevere Eingabeaufforderungen erstellen können. Sie gehört Architekten, die Systeme entwerfen, in denen verschlüsselter Kontext automatisch, sicher und deterministisch verwaltet wird. In dieser Welt ist das LLM nur eine Komponente - mächtig, aber kontrolliert - und nicht ein mysteriöser Orakel, von dem wir hoffen, dass es sich benimmt.
Von meiner Perspektive aus steht die Ära der öffentlichen Aufforderungen vor dem Ende. Ihre Mängel in Bezug auf Sicherheit, Zuverlässigkeit und Benutzerkontrolle sind zu schwerwiegend, um die nächste Generation von Unternehmens- und agentischen KI zu unterstützen. Verschlüsselter Kontext stellt einen Schritt weg von flüchtigen Tricks und hin zu echter Infrastruktur dar. Plattformen wie VANARs Neutron legen das Fundament für KI-Systeme, die nicht nur Fragen beantworten, sondern auch erinnern - sicher, privat und zu den Bedingungen des Benutzers. Das ist die Art von Partnerschaft mit KI, die ich für wertvoll halte.
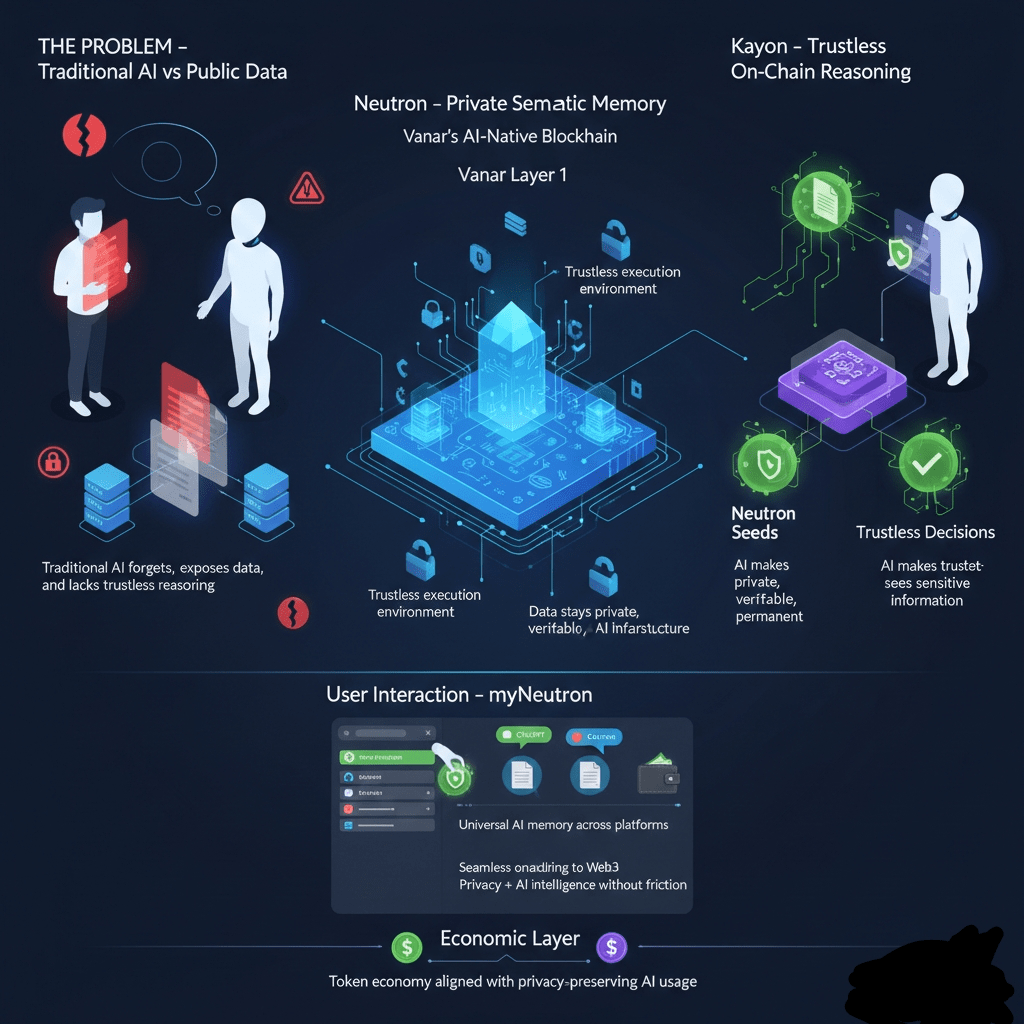
Wenn ich mir anschaue, wohin die KI geht, sehe ich eine klare Spannung, die die Branche nicht länger ignorieren kann. Wir fordern von KI-Systemen, autonomer zu werden - Brieftaschen zu verwalten, Zahlungen auszuführen, private Dokumente zu analysieren und Entscheidungen in unserem Namen zu treffen. Gleichzeitig sind wir uns jedoch zunehmend bewusst, dass es nicht nachhaltig ist, unsere Daten an zentrale Systeme zu übergeben. Intelligenz benötigt Gedächtnis und Kontext, doch Kontext ist zutiefst persönlich und sensibel. Dieser Konflikt ist einer der Hauptgründe, warum KI Schwierigkeiten hat, sich sinnvoll mit Web3 zu integrieren. Öffentliche Blockchains verlangen nach Transparenz, während nützliche KI nach Privatsphäre verlangt. Was meine Aufmerksamkeit auf Vanar Chain lenkte, ist, dass es nicht versucht, einen Kompromiss zwischen beiden einzugehen - es entwirft die Architektur neu, sodass beide koexistieren können.
Aus meiner Sicht ist Vanar nicht nur eine Blockchain mit einigen darauf aufgesetzten KI-Tools. Es fühlt sich eher wie ein KI-native Infrastruktur-Stack an, der von Grund auf dafür entworfen wurde, eine einzige schwierige Frage zu beantworten: Wie ermöglicht man vertrauenslose KI, ohne Benutzerdaten offenzulegen? Anstatt Benutzer zu zwingen, zwischen leistungsfähiger, aber zentralisierter KI oder transparenter, aber kontextblinder on-chain-Logik zu wählen, führt Vanar einen dritten Weg ein, auf dem Intelligenz auf privaten Daten auf eine verifizierbare Weise operieren kann.
Die Wurzel des Problems ist einfach. Intelligenz benötigt Kontext. Eine KI, die Ihre vergangenen Handlungen, Ihre Dokumente oder Ihre Einschränkungen nicht versteht, ist flach und unzuverlässig. Aber genau dieser Kontext - Verträge, Rechnungen, persönliche Präferenzen, finanzielle Geschichte - ist genau das, was Sie nicht in ein öffentliches Hauptbuch oder in eine öffentliche KI-Eingabeaufforderung stellen können. Deshalb ist die meiste „on-chain-KI“ heute entweder trivial oder gefährlich naiv, und warum die meisten leistungsfähigen KIs in zentralisierten Black Boxes leben. Vanars zentrale Innovation besteht darin, diese Abwägung abzulehnen.
Alles beginnt mit Vanars Layer 1, der speziell für KI-Arbeitslasten gebaut wurde. Anstatt KI-Unterstützung auf eine allgemeine Blockchain nachträglich hinzuzufügen, behandelt Vanar KI-Operationen, semantische Datenverarbeitung und intelligente Abfragen als erstklassige Bürger. Diese Basisschicht bietet die vertrauenslose Ausführungsumgebung, aber der eigentliche Durchbruch geschieht eine Schicht darüber, mit Neutron.
Neutron verändert vollständig, wie ich über die Datenspeicherung on-chain denke. Anstatt rohe Dateien oder Hashes zu speichern, die ohne off-chain Kontext nutzlos sind, verwandelt Neutron Daten in etwas, das sowohl privat als auch intelligent ist. Rohdokumente - PDFs, Urkunden, Rechnungen, E-Mails - werden in das umgewandelt, was Vanar Samen nennt. Diese Samen sind nicht nur komprimierte Dateien; sie sind semantische Objekte. Das System extrahiert Bedeutung, Struktur und Beziehungen aus den Daten und komprimiert sie dramatisch, manchmal um Hunderte von Malen, während es bewahrt, was wirklich wichtig ist: den Kontext.
Was hier entscheidend ist, ist, dass die Rohdaten nie offengelegt werden. Was on-chain lebt, ist eine komprimierte, strukturierte Darstellung von Bedeutung, nicht das ursprüngliche Dokument. Die Originaldatei bleibt unter der Kontrolle des Benutzers, typischerweise verschlüsselt. Dennoch ist der Samen selbst KI-lesbar und verifizierbar. Für mich fühlt sich das wie ein fehlender Grundbaustein in Web3 an: eine „Datei, die denkt“, eine, die abgefragt und über die nachgedacht werden kann, ohne ihren Inhalt preiszugeben. Da diese Samen on-chain leben, sind sie permanente, manipulationssichere Aufzeichnungen, die ihnen rechtliche und wirtschaftliche Gewichtung verleihen, ohne die Privatsphäre zu opfern.
Die Argumentation über diesen privaten Kontext wird von Kayon übernommen, und hier wird Vanars Vision von vertrauensloser KI wirklich für mich klar. Kayon ist eine on-chain-Argumentationsmaschine, die es Smart Contracts und KI-Agenten ermöglicht, Fragen zu Neutron-Samen zu stellen und verifizierbare Antworten zu erhalten, ohne auf die Rohdaten zuzugreifen. Anstatt einem zentralisierten KI-Dienst zu vertrauen, um „das Richtige zu tun“, verlässt sich das System auf kryptografische Garantien und deterministische Logik.
Stellen Sie sich einen autonomen Agenten vor, der eine Rechnung nur dann bezahlen darf, wenn bestimmte Compliance-Regeln erfüllt sind. Die Rechnung wird in einen privaten Samen umgewandelt. Ein Smart Contract, der Kayon verwendet, fragt diesen Samen ab, um zu überprüfen, ob bestimmte Klauseln und Beträge existieren. Kayon denkt über die semantische Struktur nach, produziert eine Antwort, und der Vertrag wird ausgeführt - oder nicht. Zu keinem Zeitpunkt wird die Rechnung öffentlich offengelegt. Die KI muss die Rohdatei nicht sehen, und dennoch ist das Ergebnis verifizierbar und vertrauenswürdig. Für mich ist dies das erste Mal, dass on-chain KI wirklich nützlich erscheint, anstatt theoretisch.
Was das noch überzeugender macht, ist, wie zugänglich es auf Benutzerebene ist. myNeutron, die erste verbraucherorientierte Anwendung, die auf diesem Stack aufgebaut wurde, zeigt, wie all diese Komplexität hinter einer sauberen Erfahrung verschwinden kann. Es funktioniert als universelles KI-Gedächtnis über eine Browsererweiterung. Ich kann Dokumente, Webseiten und Chats als private Samen speichern, sie in Bündeln organisieren und diesen Kontext dann mit einem einzigen Klick in jeden KI-Chat - ChatGPT, Claude, Gemini - injizieren. Die KI erinnert sich plötzlich an das, was ich ihr beigebracht habe, aber meine Daten werden nie direkt an das Drittanbieter-Modell übergeben. Dies löst stillschweigend das Problem der „KI-Amnesie“, ohne die Benutzer dazu zu zwingen, Krypto-Experten zu werden.
Was ich besonders clever finde, ist die Idee der stillen Annahme. myNeutron kann automatisch eine Brieftasche für Benutzer erstellen und sie ohne Fachjargon oder Reibung in Web3 onboarden. Die Menschen kommen wegen besserem KI-Gedächtnis und Privatsphäre und erkennen erst später, dass sie mit einer dezentralisierten Infrastruktur interagieren. Das fühlt sich wie die richtige Wachstumsstrategie für Web3 an.
Die wirtschaftliche Schicht ist ebenfalls durchdacht ausgerichtet. Das \u003cc-102/\u003etoken ist nicht nur für Spekulation da. Es befeuert das Netzwerk, bezahlt für KI-Dienste wie Neutron und Kayon, sichert die Kette durch Staking und wird teilweise durch reale Produktnutzung wie Abonnements verbrannt. Das bindet den Wertzuwachs direkt an die Nachfrage nach datenschutzbewahrender KI, was genau das ist, wie ich denke, dass Token-Ökonomien funktionieren sollten.
Wenn ich einen Schritt zurücktrete, fühlt sich das, was Vanar aufbaut, weniger wie eine weitere Blockchain und mehr wie eine fehlende Intelligenzschicht für Web3 an. Es bricht die falsche Wahl zwischen intelligentem, aber zentralisiertem KI und privatem, aber dummem Systemen. Durch die Kombination von semantischem Gedächtnis mit on-chain-Argumentation ermöglicht Vanar, dass KI auf private Daten auf eine Weise agiert, die verifizierbar, autonom und vertrauenswürdig ist.
Für Unternehmen, Institutionen und jeden, der ernsthaft AI-Agenten im Finanzwesen, in der Compliance oder im Management realer Vermögenswerte einsetzen möchte, beseitigt diese Architektur einige der größten Blockaden. Noch wichtiger ist, dass sie die Souveränität der Benutzer bewahrt. In einer Zukunft, in der KI ein ständiger Begleiter wird, wird Vertrauen nicht aus glänzenden Versprechungen oder Nutzungsbedingungen kommen. Es wird aus Infrastrukturen kommen, die Missbrauch und Datenlecks strukturell unmöglich machen. Aus dem, was ich sehe, ist das genau die Richtung, in die Vanar Chain drängt.
Wenn Menschen über dezentrale KI sprechen, habe ich oft das Gefühl, dass das eigentliche Problem stillschweigend ignoriert wird. Smart Contracts sind großartig darin, Logik auszuführen, aber sie sind blind. Sie verstehen keine Dokumente, Sprache oder Nuancen der realen Welt. KI hingegen kann all dies verstehen - aber ihr Denken findet normalerweise off-chain in zentralisierten Systemen statt, die alles sehen. In dem Moment, in dem Sie versuchen, die beiden zu kombinieren, tritt ein gefährlicher Kompromiss auf. Entweder Sie halten die Dinge on-chain und dumm, oder Sie machen sie intelligent und akzeptieren Überwachung. Für die meisten aktuellen Designs bedeutet on-chain-Argumentation einfach, dass Benutzerdaten irgendwo anders zur Analyse offengelegt werden und man hofft, dass niemand es missbraucht.
Genau hier denke ich, dass Kayon das Gespräch verändert. Vanar Chain behandelt Privatsphäre nicht als nachträglichen Gedanken oder als Compliance-Checkbox. Mit Kayon ist das Ziel von Anfang an klar: echte on-chain-Argumentation zu ermöglichen, ohne KI zu einer Überwachungsschicht zu machen. Nicht ein Orakel, dem Sie blind vertrauen, und nicht eine off-chain Schwarzkiste, sondern eine native Argumentationsmaschine, die die Datensouveränität respektiert und dennoch verifizierbar bleibt.
Der Grund, warum die meisten on-chain-KI-Versuche in Bezug auf die Privatsphäre scheitern, ist strukturell. Sie erfordern, dass Daten gesehen werden. Entweder werden sensible Dateien direkt in ein öffentliches Hauptbuch gestellt, was offensichtlich inakzeptabel ist, oder sie werden off-chain gespeichert und bei Bedarf in ein Orakel oder einen KI-Dienst gezogen, wenn eine Analyse erforderlich ist. Der Moment des Abrufens ist der Punkt, an dem die Privatsphäre bricht. Jemand oder etwas außerhalb der Kontrolle des Benutzers sieht die Rohdaten. Noch schlimmer ist, dass der Smart Contract keinen Einblick hat, wie die KI zu ihrem Schluss gekommen ist. Er erhält einfach ein „Ja“ oder „Nein“ und wird erwartet, dass er darauf vertraut. Dies ersetzt das Vertrauen in Institutionen durch Vertrauen in undurchsichtige KI-Anbieter, was die Ethik von Web3 völlig widerspricht.
Kayon ist so konzipiert, dass es beide dieser Fallen vermeidet. Es sitzt als Argumentationsschicht im KI-nativen Stack von Vanar, direkt über Neutron. Diese Positionierung ist wichtig. Kayon denkt nie über Rohdateien nach. Es zieht niemals PDFs, Bilder oder Textdokumente in eine sichtbare Umgebung. Stattdessen arbeitet es mit Neutron-Samen - semantischen Darstellungen von Daten, die Bedeutung bewahren, ohne Inhalte offenzulegen.
Ein Neutron-Samen ist einfach ausgedrückt komprimierte Intelligenz. Ein großes Dokument wird in ein strukturiertes, KI-lesbares Wissensobjekt umgewandelt, das Kontext, Beziehungen und Bedeutung erfasst. Dieser Samen kann verschlüsselt und on-chain verankert werden, während die Originaldatei vollständig privat und unter der Kontrolle des Benutzers bleibt. Von dort aus tritt Kayon nicht als Leser von Dokumenten auf, sondern als Denker über Bedeutung.
Wenn ein Smart Contract oder Agent Kayon aufruft, übergibt er keine sensiblen Daten. Er stellt eine präzise Frage zu einem bestimmten Samen. Kayon führt diese Abfrage on-chain aus, extrahiert nur die erforderlichen Erkenntnisse und gibt eine kryptographisch verifizierbare Antwort zurück. Nichts weiter. Der Vertrag kann überprüfen, dass die Antwort vom richtigen Samen kam und korrekt berechnet wurde, ohne jemals die zugrunde liegenden Daten zu sehen. Diese Unterscheidung ist entscheidend. Kayon denkt über Semantik nach, nicht über offengelegte Texte. Über Wissen, nicht Überwachung.
Für mich ist dies der Punkt, an dem Theorie praktisch wird. Stellen Sie sich einen finanziellen Workflow vor, bei dem eine Zahlung nur freigegeben wird, wenn eine Rechnung bestimmten Compliance-Regeln entspricht. In traditionellen Designs würde die Rechnung hochgeladen, von einer off-chain KI gescannt und von einem Orakel genehmigt, dem jeder vertrauen muss. Die KI würde alles sehen - Beträge, Gegenparteien, interne Bedingungen. Mit Kayon wird die Rechnung zu einem privaten Samen. Der Vertrag stellt eine enge Frage: Bestätigt dieser Samen Klausel X und Betrag Y? Kayon antwortet mit Nachweis, und der Vertrag wird ausgeführt. Der Rest der Rechnung bleibt der Welt unsichtbar.
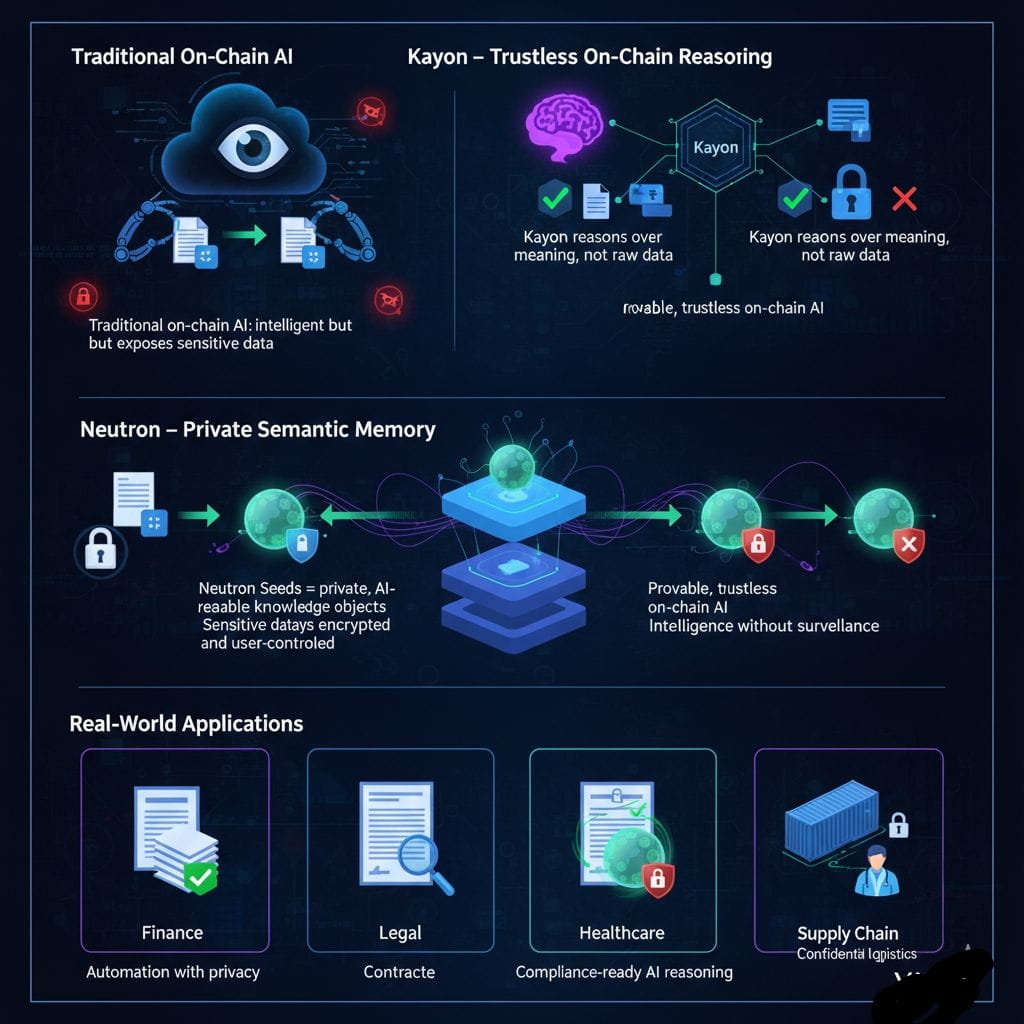
Die gleiche Logik gilt für Lieferketten, Gesundheitswesen, rechtliche Automatisierung oder jede Umgebung, in der Entscheidungen von vertraulichen Dokumenten abhängen. Nur das Ergebnis des Denkprozesses wird offenbart, niemals die Daten, die ihn informierten. Das ist der Unterschied zwischen Intelligenz und Überwachung.
Dieser Ansatz der Privatsphäre durch Design ist nicht nur philosophisch sauberer, sondern strategisch notwendig. Vorschriften wie GDPR und HIPAA verlangen Datenminimierung und strenge Kontrollen über persönliche Informationen. Unternehmen werden on-chain-KI nicht übernehmen, wenn es vollständige Datenoffenlegung nur zur Funktionsfähigkeit erfordert. Autonome KI-Agenten, die eindeutig die Richtung sind, in die die Branche geht, werden ständig über E-Mails, Kalender, Verträge und Finanzunterlagen nachdenken müssen. Ohne ein Modell wie Kayon wird diese Zukunft zu einer Datenschutzkatastrophe.
Was ich am wichtigsten finde, ist, dass Kayon die Verifizierbarkeit nicht schwächt, um Privatsphäre zu erlangen. Es stärkt beides. Das Denken findet innerhalb des Protokolls statt, die Ausgaben sind beweisbar, und Vertrauen wird in Kryptographie und Architektur gesetzt, nicht in Versprechen, die von KI-Anbietern gemacht werden. Das ist es, was diese wirklich „vertrauenslose“ Intelligenz ausmacht.
Meiner Meinung nach definiert Kayon neu, was on-chain-Argumentation bedeuten sollte. Es geht nicht darum, KI um jeden Preis auf eine Blockchain zu bringen. Es geht darum, Intelligenz auf eine Weise einzubetten, die die Souveränität des Benutzers von Grund auf respektiert. Durch die Kombination von Neutrons semantischem Gedächtnis mit Kayons privater Argumentation ermöglicht Vanar die Automatisierung realer Logik - finanziell, rechtlich, operativ - ohne die sensiblen Daten dahinter offenzulegen.
\u003cm-127/\u003er \u003ct-129/\u003e\u003cc-130/\u003e
Deshalb sehe ich den Vorteil von Kayons Privatsphäre nicht als Funktion, sondern als Voraussetzung. Ohne sie bleibt on-chain-KI eine Demo. Mit ihr können intelligente, autonome und vertrauliche Systeme endlich on-chain existieren, bereit für den echten wirtschaftlichen und unternehmerischen Einsatz.
