
@Walrus 🦭/acc starts from an assumption many decentralized systems quietly cling to: that coordination is cheap and reliable. Most architectures still treat writes as collective rituals everyone must respond, everyone must agree, and the slowest participant effectively governs progress. In theory, this looks careful. In real networks, it introduces tension, fragility, and a subtle pull toward centralization that only becomes obvious once conditions deteriorate.
Walrus exists because this model repeatedly fails in practice. Not through sudden collapse, but through small inefficiencies that accumulate over time. When data writes depend on broad synchronization, participants begin optimizing for speed instead of durability. They disengage when latency rises. They design around the fastest paths rather than the most resilient ones. Gradually, shortcuts harden into norms, and decentralization turns performative instead of structural.
Rather than treating global synchronization as a virtue, Walrus treats it as a risk. A write doesn’t wait for universal confirmation. It doesn’t stall for the least reliable node. Progress is allowed once a mathematically sufficient threshold of independent confirmations is reached. This isn’t haste it’s discipline. The system advances when safety is proven, not when consensus is theatrically complete.
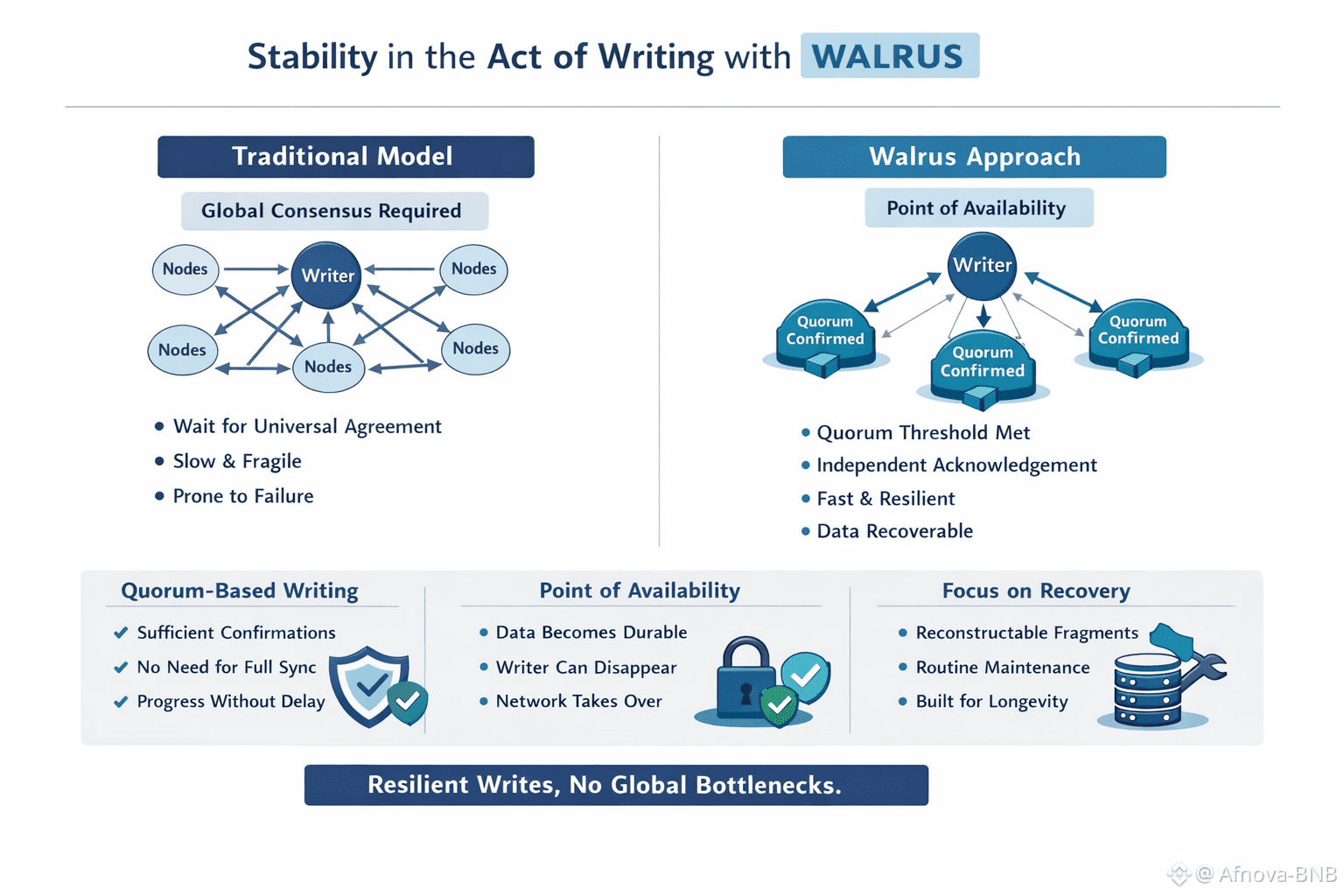
That distinction matters because real networks are hostile environments by default. Nodes vanish. Connections degrade. Some participants act maliciously; others simply disengage. Walrus doesn’t classify these as edge cases. It assumes them as baseline conditions. Writing data becomes the act of establishing enough independent structure to move forward without pretending the network is healthy, synchronized, or cooperative.
From this standpoint, availability stops being an abstract promise and becomes a precise boundary. Walrus formalizes this boundary as the Point of Availability. Before it, data remains provisional. After it, responsibility shifts. Once that point is crossed, the system no longer depends on the original writer’s presence, honesty, or continued participation. Obligation transfers to the network itself not by storing full replicas everywhere, but by preserving the conditions required for reconstruction.
This separation is easy to overlook. Many systems quietly assume writers will remain involved longer than stated re-uploading fragments, responding to disputes, or maintaining availability indefinitely. When those writers disappear, failures surface slowly and opaquely. Walrus eliminates that dependency entirely. Once availability is established, the writer becomes irrelevant. The data stands independently.
Acknowledgments play a key role here, but not in the traditional sense. They don’t certify that data is fully replicated across the network. They serve as evidence that enough correct fragments exist across independent actors to guarantee recoverability. This subtle shift radically alters the risk profile. Safety doesn’t hinge on optimistic replication it rests on quorum mathematics that remains valid even when some participants fail, lie, or quietly decay.
As a result, Walrus doesn’t chase instant completeness. It prioritizes the existence of recovery paths. Once those paths are in place, the system can tolerate loss without panic. Data doesn’t need to be perfect everywhere at once it needs to be reconstructible when required. That’s a fundamentally different contract, and one far better aligned with how long-lived systems actually endure.

Recovery, in this design, isn’t treated as an emergency. It’s continuous and expected. Hardware degrades. Storage fails. Participants churn. Walrus treats these events as routine maintenance rather than existential threats. Fragments are structured so recovery effort scales with what’s missing, not with the total volume stored. This keeps bandwidth demands predictable and prevents the cascading failures common in large repair events.
This approach also avoids a quieter inefficiency in decentralized systems: capital trapped in defensive postures against rare catastrophes instead of supporting everyday operation. Systems that assume disaster is exceptional tend to over-engineer safeguards that rarely activate. Walrus assumes loss is ordinary and builds around it. The result isn’t spectacle it’s longevity.
One of the most overlooked consequences of this design is the freedom it gives writers. Once a blob reaches its Point of Availability, the writer can disappear entirely. Keys can be lost. Accounts abandoned. None of it weakens the system. Reads, verification, and recovery continue without dependence on the original author. Data outlives intent by construction, not by hope.
This matters over long horizons. Most protocols look coherent in their first year. Far fewer remain coherent after five. People leave. Incentives drift. Governance tires. Walrus avoids many of these slow failures by refusing to depend on continued good behavior from any single role. Responsibility is embedded into structure rather than trust.
Walrus doesn’t promise excitement or optimize for attention. It does something more difficult: it accepts the limits of coordination and designs within them. By allowing progress without global agreement, by defining availability as a binding boundary, and by treating recovery as a constant background process, it builds a system that doesn’t flinch when participants do.
In the long run, the protocols that matter are rarely the loudest. They’re the ones that keep working after enthusiasm fades and conditions worsen. Walrus belongs to that quieter class not because it avoids risk, but because it understands where risk actually lives and refuses to pretend otherwise.

