
@Walrus 🦭/acc Decentralized storage is having a very practical moment. AI workflows move large files constantly, rollup-style systems need cheap data availability, and more teams are uncomfortable with a “decentralized app” that quietly depends on one cloud bucket. That mix explains why Walrus keeps showing up in benchmarking threads: people want something that feels closer to object storage in day-to-day use, but with independent verifiability and fewer brittle dependencies.
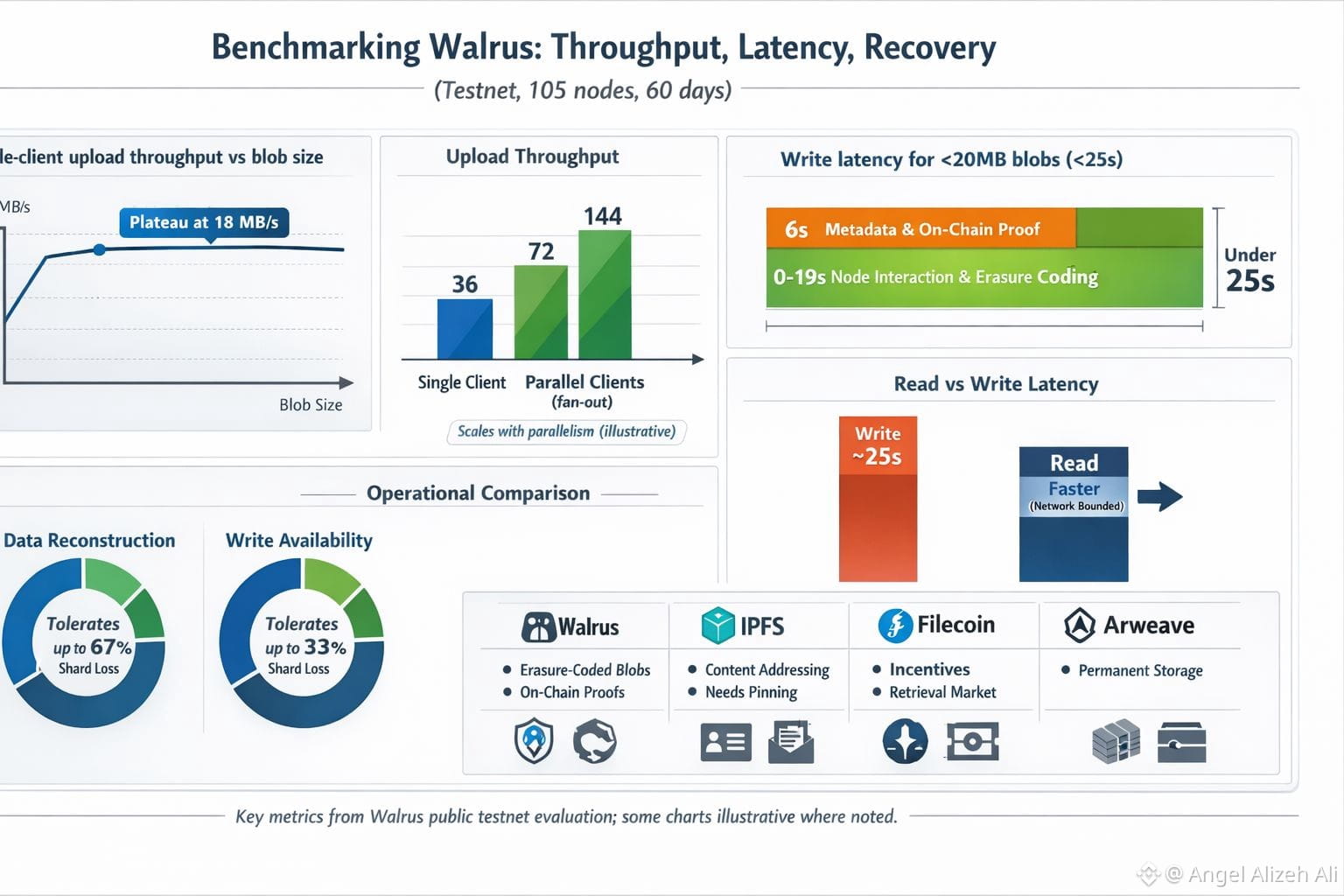
Walrus is a blob storage network built around erasure coding, with coordination and proofs handled through the Sui chain. What stands out in its main performance write-up is the setting. The evaluation looks at a publicly available testnet observed over 60 days and describes a testbed of 105 independently operated storage nodes spread across many regions and hosting providers. Benchmarks done “in the wild” are messy, but they’re also harder to massage into a flattering story.
On upload throughput, Walrus is clear about its ceiling for a single client: write throughput plateaus around 18 MB/s. The reason is architectural, not a tuning problem. A write includes multiple interactions with storage nodes plus a final step that publishes a proof of availability on-chain, so you’re paying for coordination as well as bandwidth. If you need more ingest, the evaluation suggests parallel clients uploading chunks in a fan-out pattern so aggregate throughput scales with parallelism, not with heroic tuning.
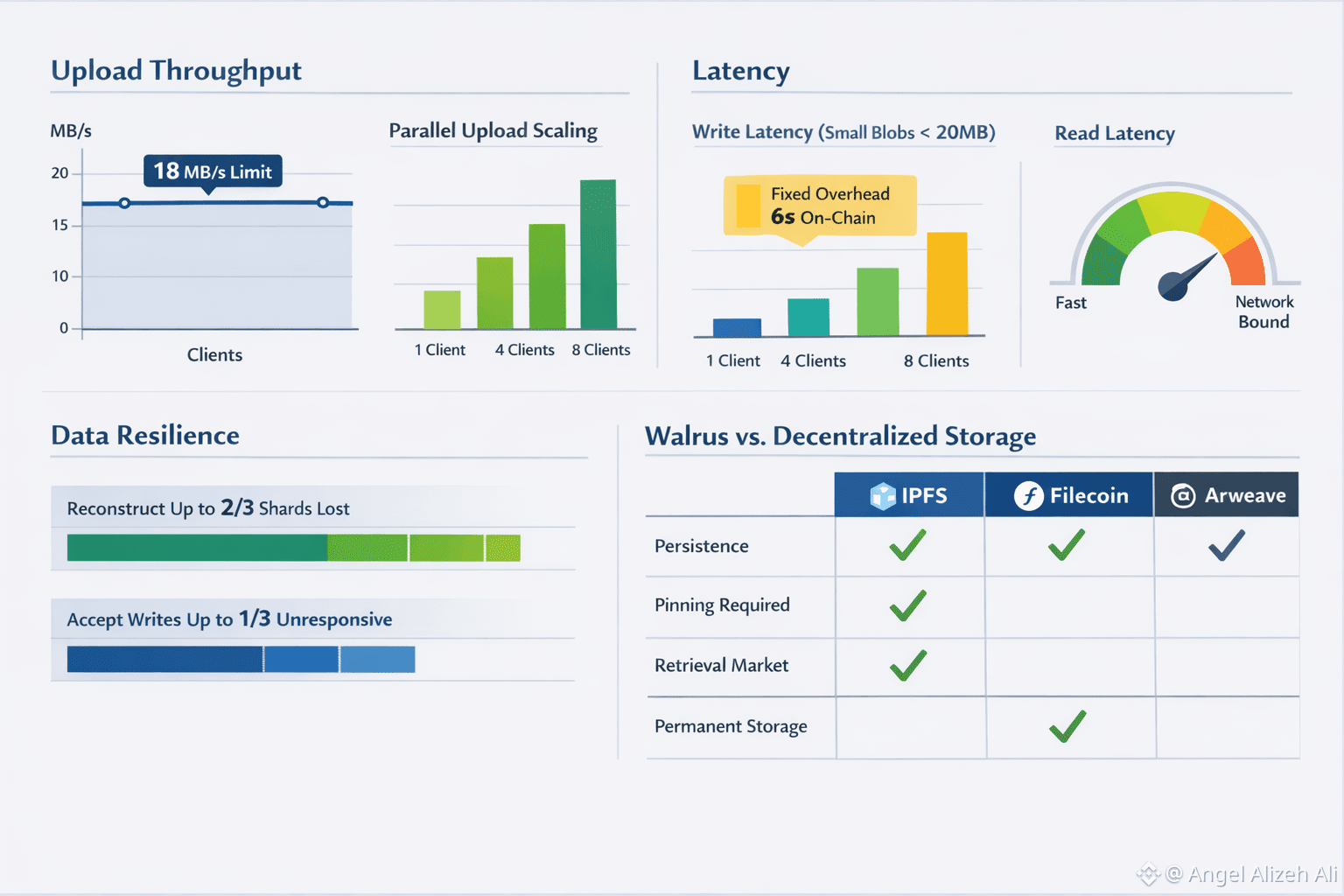
Latency is where you feel the design choices most sharply. For small blobs (under 20 MB), the evaluation reports write latency staying under 25 seconds, and it explains that blob size isn’t the main driver at that scale; fixed overhead dominates. Roughly six seconds comes from metadata handling and publishing the proof on-chain. Reads are consistently faster than writes and are described as bounded by network delay, which is a restrained way of saying that geography and routing matter more than protocol overhead once the blob is already placed.
Data recovery is the benchmark that rarely gets celebrated, yet it’s the one that decides whether a storage network survives real life. Walrus’s paper makes two concrete resilience claims: it can reconstruct data even if up to two-thirds of shards are lost, and it can keep accepting writes even if up to one-third of shards are unresponsive. It also argues that efficient repair is essential in erasure-coded systems, because a scheme that can’t heal cheaply tends to accumulate small gaps until the “rebuild” becomes an emergency.
Compared with the usual alternatives, the differences become less philosophical and more operational. IPFS is excellent for content addressing and distribution, but persistence is not automatic; the IPFS docs are blunt that you need to pin content (yourself or via a service) if you want it to stick around and not get garbage-collected. Filecoin adds incentives and a retrieval market; its docs describe clients requesting data from storage providers and paying for retrieval. Arweave takes a different bet: permanent storage as a core feature, backed by its protocol design and “permaweb” framing.
Why is Walrus trending now? In part because it aims directly at the AI-era “blob problem,” and its docs talk openly about making unstructured data reliable and governable. There’s also a maturity signal: coverage describes governance via a Walrus Foundation, which implies the project is trying to outgrow the single-team phase. If you benchmark it, I’d resist the urge to run one upload and declare victory. Test cold reads and warm reads, push parallel uploads, and then do something slightly cruel: drop a slice of nodes and measure how quickly you can still retrieve and reconstitute data. When a system promises both speed and recovery, it deserves to be tested on both.