After reading countless next-generation L1 pitches, a pattern becomes obvious. They begin with TPS numbers, end with a token chart, and somewhere in the middle declare themselves enterprise-ready as if readiness were a switch you flip. What pulled my attention toward Vanar was not a single feature but an attitude. The project behaves less like a lab experiment and more like a system expected to survive contact with reality.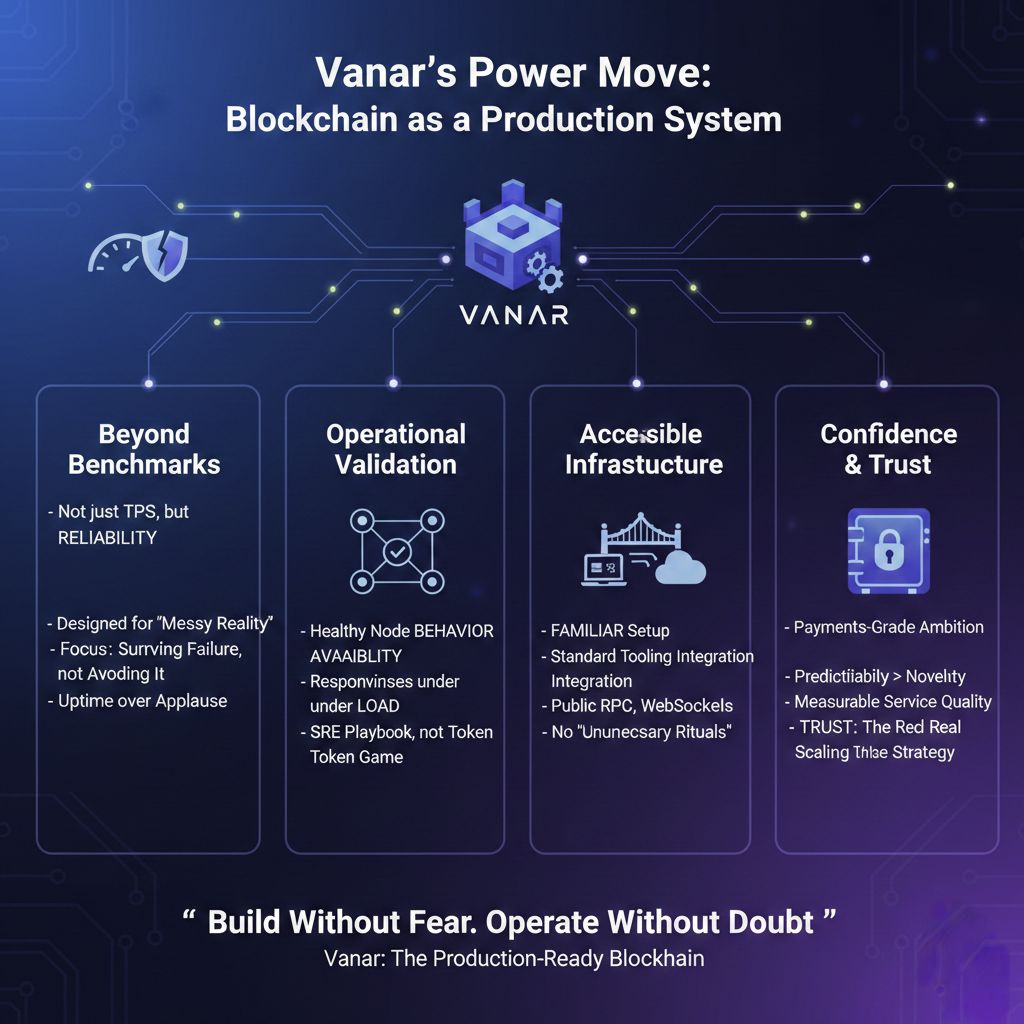
Most chains perform well in controlled environments. Real usage is different. Nodes fail, endpoints stall, traffic spikes, and users refresh impatiently. Payments cannot wait. Vanar’s positioning suggests the network is designed for that messy environment rather than an ideal benchmark scenario. This sounds unexciting until you realize where adoption actually lives. Teams launching applications rarely choose the fastest chain; they choose the one that will not surprise them in production. Unexpected behavior destroys timelines, budgets, and trust faster than slow performance ever could. Reliability quietly becomes the real feature.
The messaging around the V23 protocol upgrade stood out because it did not celebrate raw throughput. Instead it emphasized resilience, recovery, and operational continuity. The design direction resembles payments infrastructure thinking, closer to stability-first consensus philosophy than benchmark-first engineering. The focus is not eliminating failure but surviving it. In distributed systems collapse is optional but failure is inevitable, and a mature network plans for the second. The network appears designed for uptime rather than applause.
Many networks treat validation as a participation game: join, stake, earn. The presence of nodes becomes a marketing metric rather than an operational one. But a node count does not equal a healthy network. What matters is whether nodes are reachable, synchronized, and useful. When incentives reward claims rather than service, networks accumulate inactive validators, inflated decentralization, and unpredictable uptime. Rewarding operational behavior availability, responsiveness, reliability transforms the network from a token economy into something resembling an SRE playbook. It is not a crypto novelty but a production principle.
Systems do not scale by never breaking. They scale by breaking safely. Hardware fails, connections drop, humans misconfigure. The real question is whether the application collapses when these events happen. The resilience-heavy direction suggests a competition based on confidence rather than novelty. Distributed systems are never perfectly solved, but choosing stability as the battleground changes how builders evaluate risk. Confidence becomes adoption infrastructure.
I have learned a simple way to judge whether a chain genuinely wants adoption: ignore the whitepaper and inspect onboarding. If developers struggle to connect, the ecosystem stalls before it begins. What appears instead is familiarity standard configuration flows, accessible endpoints, and normal tooling integration. Public infrastructure matters: RPC access, WebSocket connectivity, clear chain identification, and a working explorer. These details are not glamorous, yet they determine whether experimentation happens at all. Developers rarely resist learning complexity, but they avoid unnecessary rituals. Familiar setup removes hesitation, and hesitation is the biggest barrier to ecosystem growth.
Payments infrastructure exposes weaknesses quickly. It tolerates neither latency theatrics nor operational fragility. Errors are not bugs but financial events. Leaning toward real payment rails signals something different from experimentation. Handling large-scale transaction flows requires discipline beyond technical correctness; it demands predictability. Enterprise readiness stops being a phrase and becomes an obligation. Entering that arena is not the safest strategy but the most revealing one.
Large node counts impress marketing; healthy node behavior impresses operators. A meaningful metric is not how many validators exist but how many remain responsive during load. High throughput means little if reliability drops when activity rises. Operational standards matter more than participation numbers. Networks built around verifiable service quality naturally produce stronger trust because availability becomes measurable rather than assumed. Trust is statistical before it is reputational.
Winning platforms are often not the most advanced but the easiest to continue using. When a network fits existing workflows developers experiment once, then again, then bring teams. Growth rarely comes from announcements but from repeated low-friction decisions. Familiar infrastructure quietly distributes the ecosystem.
The pattern across resilience messaging, operational validator expectations, accessible infrastructure, and payment-grade ambitions forms a consistent narrative: the project is attempting to sell confidence rather than capability. Confidence is expensive because it cannot be declared; it must be demonstrated repeatedly. Speed attracts attention, predictability retains users.
The next adoption wave will likely not be decided by feature count but by which networks allow builders and businesses to operate without fear. The significant bet here is not a headline feature but a philosophy: treat the blockchain as a production machine where verification, reliability, and operational clarity outweigh spectacle. If that direction holds, the result is not just technology. It is trust, and trust is the only scaling strategy that compounds.
@Vanarchain #Vanar #vanar $VANRY
