When people hear “high performance transaction engine,” the expected reaction is awe. More TPS, faster finality, lower latency — the usual benchmarks meant to signal technical superiority. My reaction is different. Relief. Not because speed is impressive, but because most blockchain performance claims quietly ignore the real issue: users don’t experience throughput charts. They experience waiting, uncertainty, and failure. If a transaction engine meaningfully reduces those frictions, it’s not a performance upgrade. It’s a usability correction.
For years, transaction processing in many networks has been constrained by sequential execution models that treat every transaction like a car at a single-lane toll booth. Order must be preserved, state must be updated linearly, and throughput becomes a function of how quickly the slowest step completes. This design made sense when security and determinism were the only priorities. But as usage grew, the side effects became impossible to ignore: congestion, fee spikes, unpredictable confirmations, and an experience that feels less like software and more like standing in line.
Fogo’s transaction processing engine reframes that constraint. Instead of forcing every transaction into a single execution path it treats the network like a multi lane system where independent operations can be processed in parallel. The shift sounds technical but its real significance lies in responsibility. The burden of managing contention moves away from the user — who previously had to time transactions, adjust fees, or retry failures — and into the execution environment itself.
Parallelization, however, is not magic. Transactions still contend for shared state. If two operations attempt to modify the same account or contract storage simultaneously, the system must detect conflicts order execution, and preserve determinism. This introduces a scheduling layer that becomes far more important than raw compute. The engine must decide what can run concurrently what must wait, and how to resolve collisions without turning performance gains into inconsistency risks.
That scheduling layer is where the invisible complexity lives. Conflict detection, dependency graphs, and optimistic execution strategies form a pricing surface of a different kind: not monetary, but computational. How aggressively should the engine parallelize? What is the cost of rolling back conflicted transactions? How does the system behave under adversarial workloads designed to trigger maximum contention? These questions determine whether parallel execution feels seamless or fragile.
This is why the conversation shouldn’t stop at “higher throughput.” Higher throughput in calm conditions is trivial. The deeper question is how the engine behaves when demand becomes chaotic. In sequential systems, congestion is visible and predictable — fees rise, queues lengthen, users wait. In parallel systems, congestion can manifest as cascading conflicts, repeated retries, and resource exhaustion in places users never see. The failure modes change shape rather than disappear.
In older models, transaction failure is often personal and local: you set the fee too low, you submitted at the wrong time, you ran out of gas. It’s frustrating, but legible. In a highly parallel engine, failure becomes systemic. The scheduler reprioritizes. Conflicts spike. A hotspot contract throttles throughput for an entire application cluster. The user still sees a failed transaction, but the cause lives in execution policies, not their own actions. Reliability becomes an emergent property of the engine’s coordination logic.
That shift quietly moves trust up the stack. Users are no longer just trusting the protocol’s consensus rules; they are trusting the execution engine’s ability to manage concurrency fairly and predictably. If the scheduler favors certain transaction patterns, if resource allocation changes under load, or if conflict resolution introduces subtle delays, the experience can diverge across applications in ways that feel arbitrary. Performance becomes a governance question disguised as an engineering detail.
There’s also a security dimension that emerges once transactions can be processed in richer parallel flows. Faster execution reduces exposure to front-running windows, but it also introduces new surfaces for denial-of-service strategies that exploit conflict mechanics rather than network bandwidth. An attacker no longer needs to flood the network they can craft transactions that maximize contention, forcing repeated rollbacks and degrading effective throughput. The engine must not only be fast — it must be adversarially resilient.
From a product perspective, this changes what developers are responsible for. In slower, sequential environments, performance bottlenecks are often blamed on “the chain.” In a parallel execution model, application design becomes inseparable from network performance. Poor state management, unnecessary shared storage writes, or hotspot contract patterns can degrade concurrency for everyone. Developers are no longer just writing logic; they are participating in a shared execution economy.
That creates a new competitive arena. Applications won’t just compete on features; they’ll compete on how efficiently they coexist with the transaction engine. Which apps minimize contention? Which design patterns preserve parallelism? Which teams understand the scheduler well enough to avoid self-inflicted bottlenecks? The smoothest user experiences may come not from the most powerful apps, but from the ones that align their architecture with the engine’s concurrency model.
If you’re thinking like a serious ecosystem participant, the most interesting outcome isn’t that transactions execute faster. It’s that execution quality becomes a differentiator. Predictable confirmation times, low conflict rates, and graceful behavior under load become product features, even if users never see the mechanics. The best teams will treat concurrency not as a backend detail, but as a first-class design constraint.
That’s why I see Fogo’s transaction processing engine as a structural shift rather than a performance patch. It’s the network choosing to treat execution like infrastructure that must scale with real usage patterns, rather than a queue that users must patiently endure. It’s an attempt to make blockchain interaction feel like modern software: responsive, reliable, and boring in the best possible way.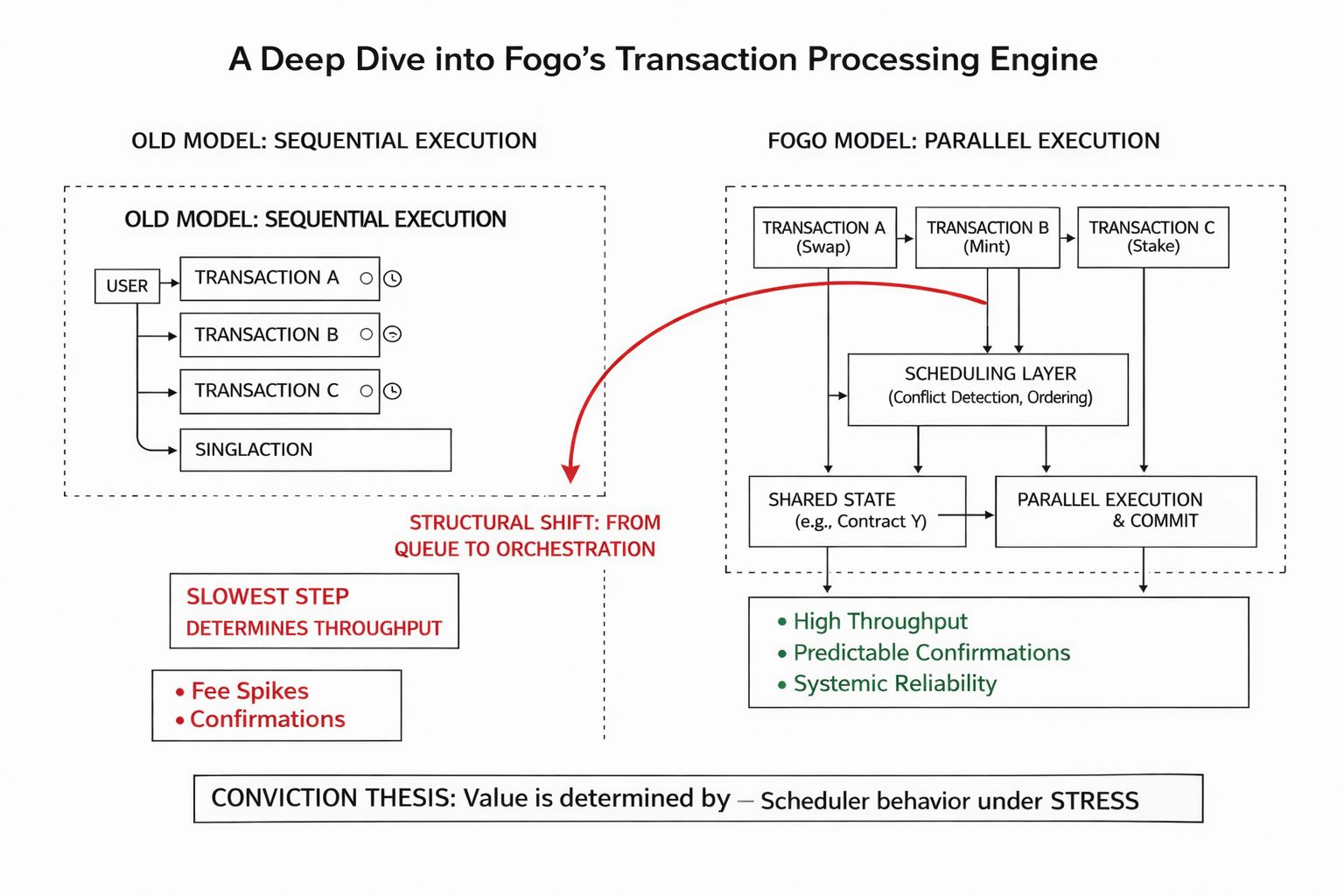
The conviction thesis, if I had to pin it down, is this: the long-term value of Fogo’s execution model will be determined not by peak throughput numbers, but by how the scheduler behaves under stress. In quiet conditions, almost any parallel engine looks efficient. In volatile conditions, only disciplined coordination keeps transactions flowing without hidden delays, cascading conflicts, or unpredictable behavior.
So the question I care about isn’t “how many transactions per second can it process?” It’s “how does the engine decide what runs, what waits, and what fails when everyone shows up at once?”
