
 Durability is often misunderstood as simple replication. Copy the same data to many nodes, hope enough of them stay online, and call the problem solved. This approach works until scale, cost, and failure patterns collide. Replication is expensive, brittle under correlated outages, and inefficient for long-term storage. Walrus approaches durability from a different angle because availability is not a probability problem it is a structural one.
Durability is often misunderstood as simple replication. Copy the same data to many nodes, hope enough of them stay online, and call the problem solved. This approach works until scale, cost, and failure patterns collide. Replication is expensive, brittle under correlated outages, and inefficient for long-term storage. Walrus approaches durability from a different angle because availability is not a probability problem it is a structural one.
Erasure coding rethinks what failure survivability means. Rather than replicating data, Walrus shatters data into pieces and encodes these pieces so that only some of them are necessary. The system does not depend on any single node, region, or provider. Loss becomes tolerable by design rather than catastrophic by accident.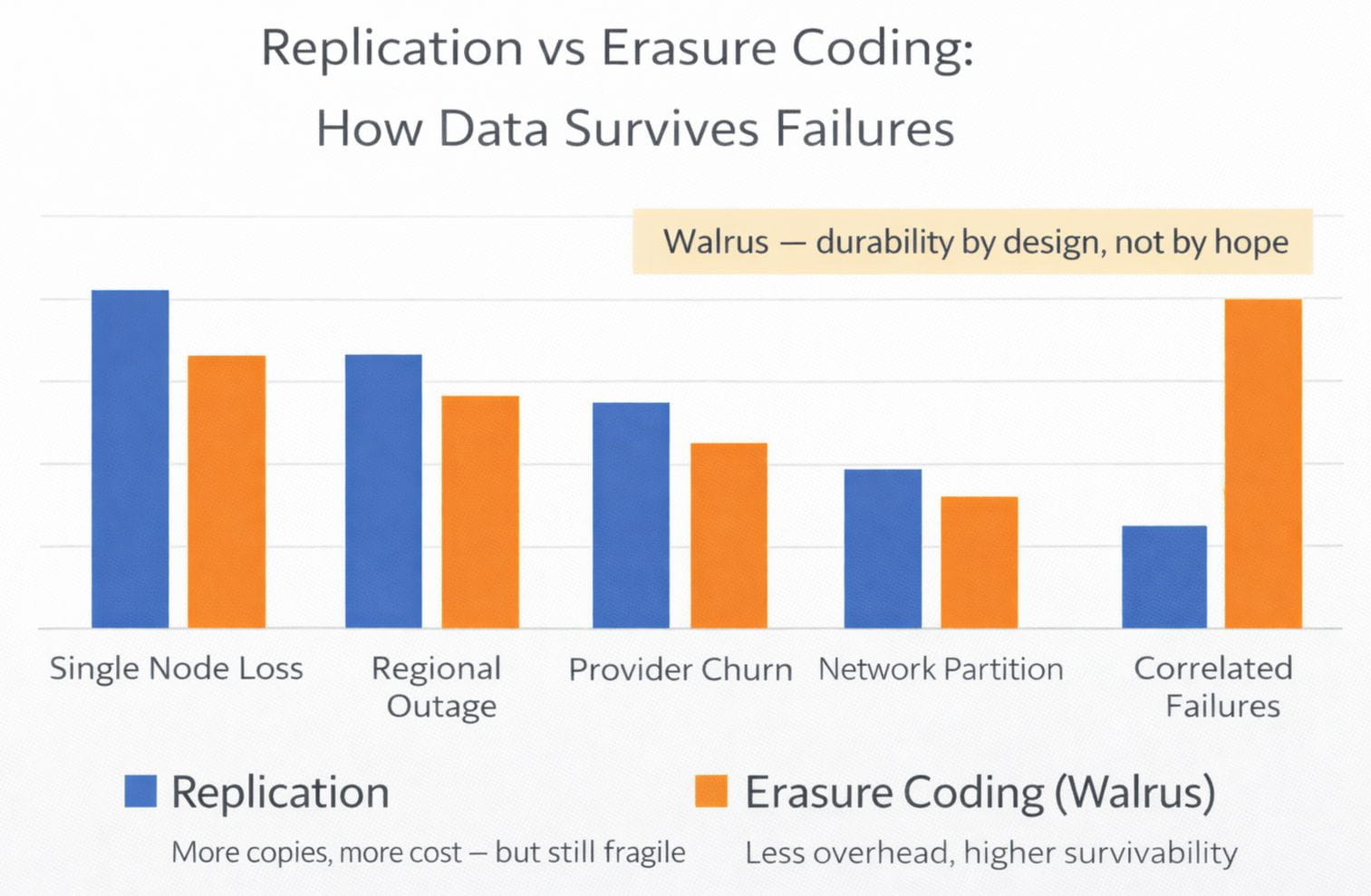
This matters because decentralized storage fails differently than centralized systems. Nodes churn. Networks partition. Providers disappear without warning. Replication assumes stability and overpays to compensate for its absence. Erasure coding assumes instability and designs around it. Walrus treats failure as a normal operating condition, not an edge case.
The deeper advantage is economic. With replication, durability scales linearly with cost. More safety means more copies. Erasure coding breaks that relationship. Walrus can achieve higher fault tolerance with less total storage overhead, aligning incentives for providers without pushing costs onto users. Durability becomes efficient instead of extractive.
Erasure coding also changes how trust is distributed. No single storage provider holds complete data. No small coalition can reconstruct it alone. This reduces both accidental loss and intentional compromise. Security emerges from fragmentation rather than secrecy. The data survives not because anyone is trusted, but because no one is indispensable.
Crucially, durability is enforced at the protocol level. Walrus does not rely on promises that data will be kept. Providers must prove that fragments are stored and retrievable. Missing shards do not quietly degrade reliability; they are detectable failures with economic consequences. Durability is measured continuously, not assumed indefinitely.
Another subtle benefit is resilience against uneven participation. Storage networks rarely fail uniformly. They fail in clusters. Erasure coding allows Walrus to remain functional even when entire segments of the network go offline. Recovery does not require perfect conditions, only sufficient diversity.
Walrus uses erasure coding because decentralized storage cannot depend on optimism. Data that matters must survive bad assumptions, bad actors, and bad luck. By encoding durability directly into how data is written and recovered, Walrus shifts reliability from a hope into a guarantee. In a system built for long-term on-chain coordination, that distinction is everything.