
A missing file is not a headline until it costs you money. For traders and investors, that moment usually arrives quietly. A counterparty asks for the exact dataset behind a model decision. An exchange wants a time stamped record during a compliance review. A research teammate needs the original version of a report that moved a position. If the file is gone, or you cannot prove it is the same file you saw yesterday, the loss is not only operational. It is confidence, and confidence is what keeps systems used rather than abandoned.
Walrus is built around that practical anxiety: keeping data both safe and consistently retrievable, even when parts of a network fail. It is a decentralized storage and data availability protocol originally introduced by Mysten Labs, with Sui acting as the control plane for coordination, attestations, and economics. Walrus focuses on storing large binary objects, often called blobs, the kind of data that dominates real workloads: media, datasets, archives, and application state that is too heavy to keep directly on a base chain.
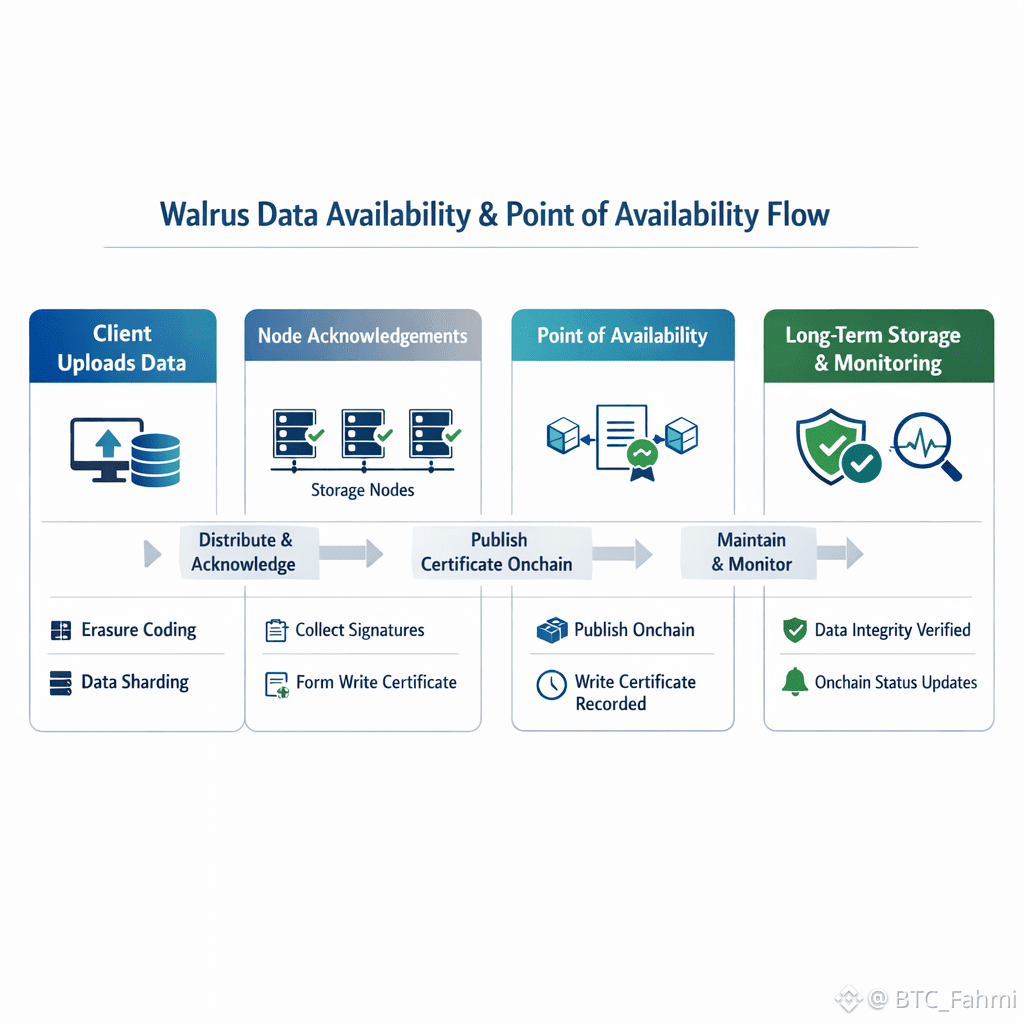
Security in storage is often discussed as if it is only encryption. In practice it is three separate questions: can the network keep your data available, can you verify integrity, and can you reason about service guarantees without trusting a single operator. Walrus leans into verifiability through an onchain milestone called the Point of Availability. The protocol’s design describes a flow where a writer collects acknowledgments that form a write certificate, then publishes that certificate onchain, which marks when Walrus takes responsibility for maintaining the blob for a specified period. Before that point, the client is responsible for keeping the data reachable; after it, the service obligation becomes observable via onchain events. This matters because consistent systems are not built on promises. They are built on states you can check.
The other pillar is resilience under churn, the boring but decisive reality that nodes go offline, disks fail, and incentives fluctuate. Walrus’s technical core is an erasure coding scheme called Red Stuff, described as a two dimensional approach designed to reduce the blunt cost of full replication while still enabling fast recovery when parts of the network disappear. In the Walrus research paper, Red Stuff is presented as achieving high security with a replication factor around 4.5x, positioning it between naive full replication and erasure coding designs that become painful to repair under real churn. You do not need to be a distributed systems engineer to appreciate the implication: a network that can recover quickly from partial failure is a network where applications do not randomly degrade, and users do not learn to expect missing content.
Consistency also means predictable operational rules. Walrus publishes network level parameters and release details, including testnet versus mainnet characteristics such as epoch duration and shard counts, which is the kind of transparency builders use to reason about how long storage commitments last and how frequently the system updates its state. For an investor, these details are not trivia. They are part of whether the protocol can support real businesses with service level expectations rather than hobby deployments.
Now to the part traders inevitably ask: does any of this show up in the market, and how should it be interpreted without storytelling. As of January 27, 2026, major price trackers show WAL trading around twelve cents, with reported daily volume in the high single digit to low double digit millions of dollars and a market cap around two hundred million dollars. That is not a verdict, it is a snapshot. What it does tell you is that the token is liquid enough to respond to real narratives, and the network is far enough along in public markets that you can measure sentiment in real time rather than extrapolate from private rounds.
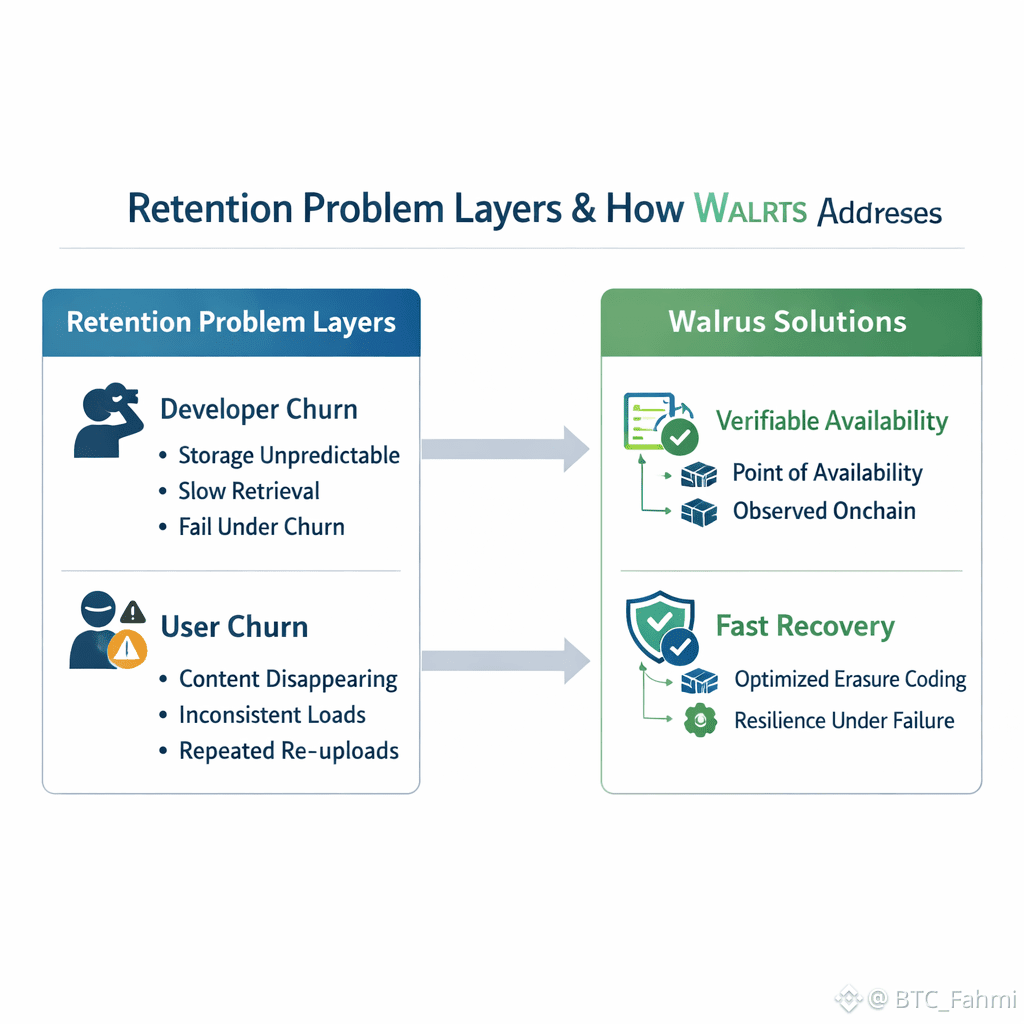
The more durable question is what drives retention, because retention is where infrastructure either compounds or evaporates. In decentralized storage, the retention problem has two layers. First, developer retention: teams leave when storage is unpredictable, slow to retrieve, or hard to reason about under failure. Second, user retention: users leave when an app’s content disappears, loads inconsistently, or requires repeated re uploads and manual fixes. Walrus is explicitly designed to reduce both types of churn by making availability a verifiable state and by optimizing recovery so applications are less likely to experience the silent failures that teach users to stop trusting the product.
If you want a grounded way to think about this, imagine a research group that ships a paid signal product. The signal itself is small, but the supporting evidence is not: notebooks, feature stores, and archived market data slices that prove why a signal changed. If the archive is centralized the failure mode is a single operational mistake or vendor outage that blocks access at the worst time. If the archive is decentralized but poorly engineered the failure mode is different but just as corrosive retrieval works most days then randomly fails when node churn spikes. The clients do not care which technical label caused the outage. They only care that the product feels unreliable, and unreliability is the fastest route to cancellations.
For traders and investors doing due diligence, treat Walrus as a business of guarantees, not slogans. Track whether usage is rising in ways that indicate repeat behavior rather than one time experiments, and watch whether the protocol continues to publish clear operational assurances around when data becomes the network’s responsibility and how long it is maintained. If you are building, the call to action is even simpler: store something you cannot afford to lose, then verify you can independently reason about its availability state and retrieval behavior under stress. If Walrus can earn trust in those everyday moments, it solves the retention problem at its root, and that is what turns infrastructure into something the market keeps coming back to.