Most infrastructure forgets stress the moment it passes.
A spike hits. Nodes scramble. Queues swell. Then the graph smooths out and the story resets to “normal.” The system acts like the event never happened. Teams are encouraged to do the same.
Walrus doesn’t reset that way.
On Walrus, stress leaves residue.
The blob that barely made it through repair doesn’t get promoted back to innocence. It remains the same object, with the same history, re-entering the same environment that already proved hostile once. Nothing is flagged. Nothing is quarantined. But everyone involved knows this object has already tested the margins.
And that changes behavior.
Why “Recovered” Isn’t a Clean State
In most storage systems, recovery is a conclusion. Once data is back, the incident is over. You move on.
Walrus treats recovery as continuation.
Repair restores structure, not confidence. The system doesn’t promise that the next churn window will be kinder. It simply enforces durability again, under the same rules, with the same exposure.
So teams stop celebrating recovery and start budgeting for recurrence.
That’s a subtle but profound shift. Infrastructure stops being something you assume will behave, and becomes something you actively reason about.
Institutional Systems Don’t Price Uptime — They Price Memory
Institutions don’t fear downtime as much as they fear patterns. A single outage is forgivable. Repeated stress near the same boundary is not.
Walrus surfaces that pattern without editorializing it.
The object survives, but its survival story is still part of the system. Repair pressure doesn’t disappear just because the math checks out. Durability keeps competing for resources. Availability keeps asking to be trusted again.
This is uncomfortable because it removes plausible deniability. You can’t say “it was a one-off” when the system never fully forgets.
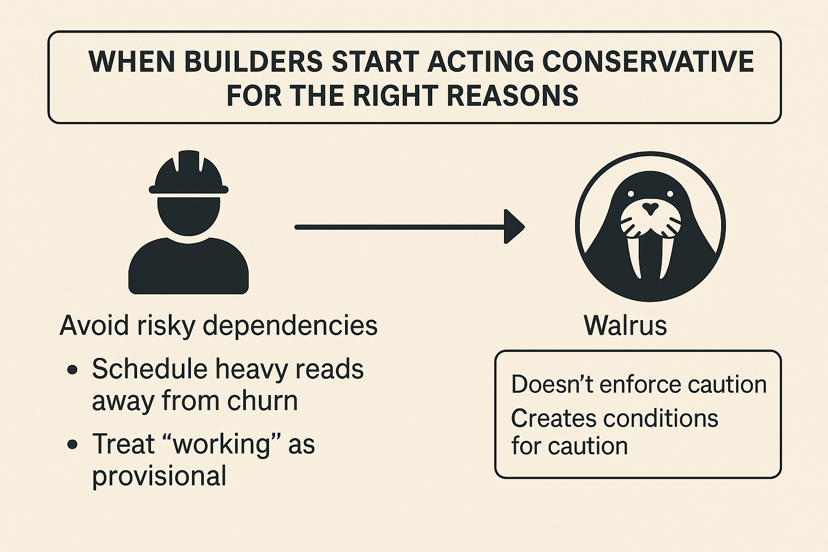
When Builders Start Acting Conservatively for the Right Reasons
You see it in small decisions.
Teams avoid tying critical flows to objects that have a history of near-miss recovery. They schedule heavy reads away from known churn windows. They treat “working” as provisional instead of absolute.
None of this is mandated by Walrus. That’s the point.
The protocol doesn’t enforce caution. It creates conditions where caution is the rational response.
Most infrastructure tries to engineer confidence by hiding complexity. Walrus does the opposite: it makes the cost of durability legible enough that teams internalize it.
Conclusion
Walrus isn’t just durable because it repairs data.
It’s durable because it preserves the memory of stress.
That memory changes how systems are designed, how dependencies are formed, and how risk is managed over time. Availability becomes something you earn repeatedly, not something you assume forever.
For institutions and serious builders, that’s not a weakness.
That’s the difference between infrastructure that looks stable… and infrastructure that actually survives being relied on.