
As AI systems become more autonomous, the question of trust shifts away from models and toward data. It’s no longer enough to know how a model was trained. You need to know exactly what data it was trained on, whether that data stayed intact, and whether anyone could have changed it without being noticed. This is where most data pipelines quietly fail.
@Walrus 🦭/acc is built around a simple but powerful idea: datasets should be verifiable by default, not trusted by assumption.
Walrus doesn’t try to solve this by adding more monitoring or access control. It changes how data is committed, referenced, and reused across systems, so verification becomes part of the workflow itself.
Why traditional datasets are hard to verify
In most AI pipelines today, datasets live in centralized storage. Files are uploaded, updated, overwritten, and versioned through conventions rather than guarantees. Even when teams keep good records, verification still depends on trust.
You trust that:
the dataset wasn’t altered after training started
the version label actually reflects the underlying data
the storage provider didn’t silently replace or remove records
Once models are trained, proving these assumptions becomes difficult. Logs can be edited. Files can be replaced. Older versions may no longer exist. For regulated or high-stakes AI systems, this lack of verifiability is a serious weakness.
Walrus starts by assuming this trust model is insufficient.
Commit first, verify forever
At the core of Walrus is the idea of cryptographic data commitments.
When a dataset is added to Walrus, the network agrees on a precise representation of that data at that moment. This commitment acts like a permanent fingerprint. If even a single byte changes later, the commitment no longer matches.
For AI workflows, this means a training job can reference a specific dataset commitment instead of a mutable file path. Anyone reviewing the model later can independently verify that the data used for training is exactly the data that was committed.
Verification no longer depends on who stored the data. It depends on the commitment itself.
Availability that doesn’t depend on a single party
Verifiability is meaningless if data can disappear.
Walrus pairs commitments with network-backed availability. Data is distributed and coordinated so that it can’t be selectively withheld or quietly dropped by a single actor. If one participant goes offline or refuses to serve data, others can still provide it.
This matters for datasets because partial availability can distort training just as much as incorrect data. A model trained on an incomplete dataset may look fine in testing but behave unpredictably in production.
With Walrus, availability is a property of the system, not a promise from a provider.
Explicit versioning instead of silent overwrites
One of the most common ways datasets lose integrity is through version drift. Updates overwrite previous files. Labels change. Over time, no one is sure which version was actually used.
Walrus makes versioning explicit.
Each dataset update produces a new commitment. Older versions remain addressable and verifiable. Nothing is overwritten. This creates a clear lineage of data changes over time.
For AI teams, this means:
you can reproduce training exactly
you can audit how datasets evolved
you can compare model behavior across data versions
Importantly, this doesn’t expose the data publicly. It exposes the existence and identity of versions, which is what verifiability requires.
Verifiable references across the AI pipeline
Walrus treats data references as first-class objects.
Training jobs, models, agents, and downstream systems can all point to the same dataset commitment. If a model claims it was trained on a specific dataset, that claim can be checked independently. There’s no ambiguity about which data was used.
This removes an entire category of errors caused by mismatched files, broken links, or off-chain coordination mistakes.
For autonomous agents, this is especially important. An agent that can verify its own data source is far more reliable than one that blindly trusts upstream systems.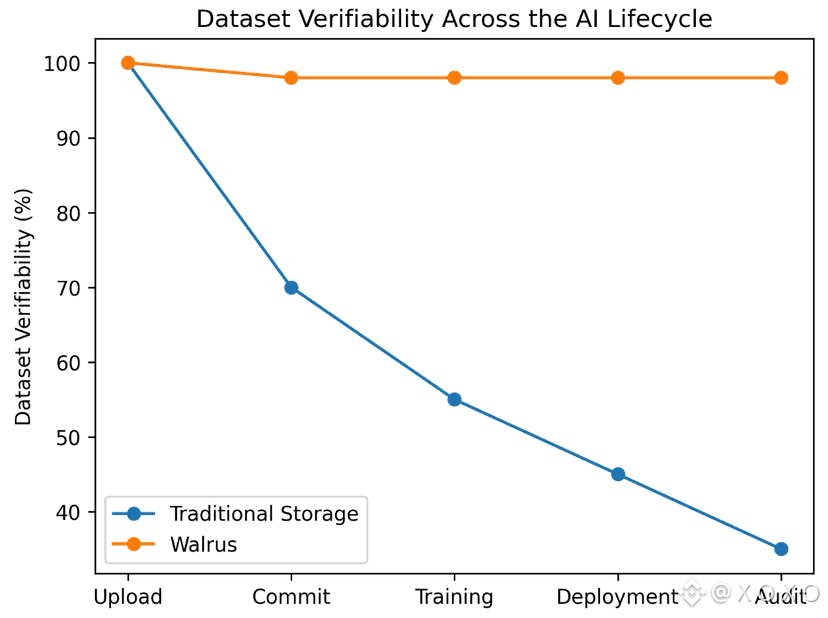
Why this matters more as AI becomes autonomous
As AI systems move from passive tools to active decision-makers, the cost of data uncertainty rises sharply. Small inconsistencies in training data can scale into large behavioral differences. When retraining happens automatically, manipulation becomes easier and harder to detect.
Walrus enables datasets that can defend themselves.
Instead of asking “Do we trust the data source?”, systems can ask “Does this data match the committed dataset?” That shift turns trust into verification.
From storage to data credibility
Walrus isn’t positioning itself as just another storage layer. It’s positioning itself as credibility infrastructure for data.
By combining immutable commitments, guaranteed availability, explicit versioning, and verifiable references, Walrus makes datasets something that can be proven correct long after they’re created.
For AI training, auditing, and deployment, that’s the difference between data you hope is right and data you can actually stand behind.
My take
AI safety discussions often focus on models, alignment, or compute limits. But models are downstream of data. If the data can’t be verified, nothing built on top of it is fully trustworthy.
Walrus addresses this problem at its root. By making datasets verifiable, persistent, and resistant to silent change, it gives AI systems something they’ve largely lacked so far: a solid, provable foundation.
As AI systems take on more responsibility, that foundation will matter more than any single model upgrade.