
The Symmetry Principle Nobody Talks About
Walrus introduces a principle that sounds deceptively simple: every storage node assigned to hold fragments of a blob receives not just its primary sliver, but also a paired secondary encoding. This pairing is deterministic and identical across all honest participants. When fragments go missing, the protocol doesn't scramble to find replacements or negotiate which node should reconstruct what. Instead, each node knows exactly which peer holds the complementary sliver needed to regenerate its own lost data. The system becomes self-referential—peers help each other recover by design.
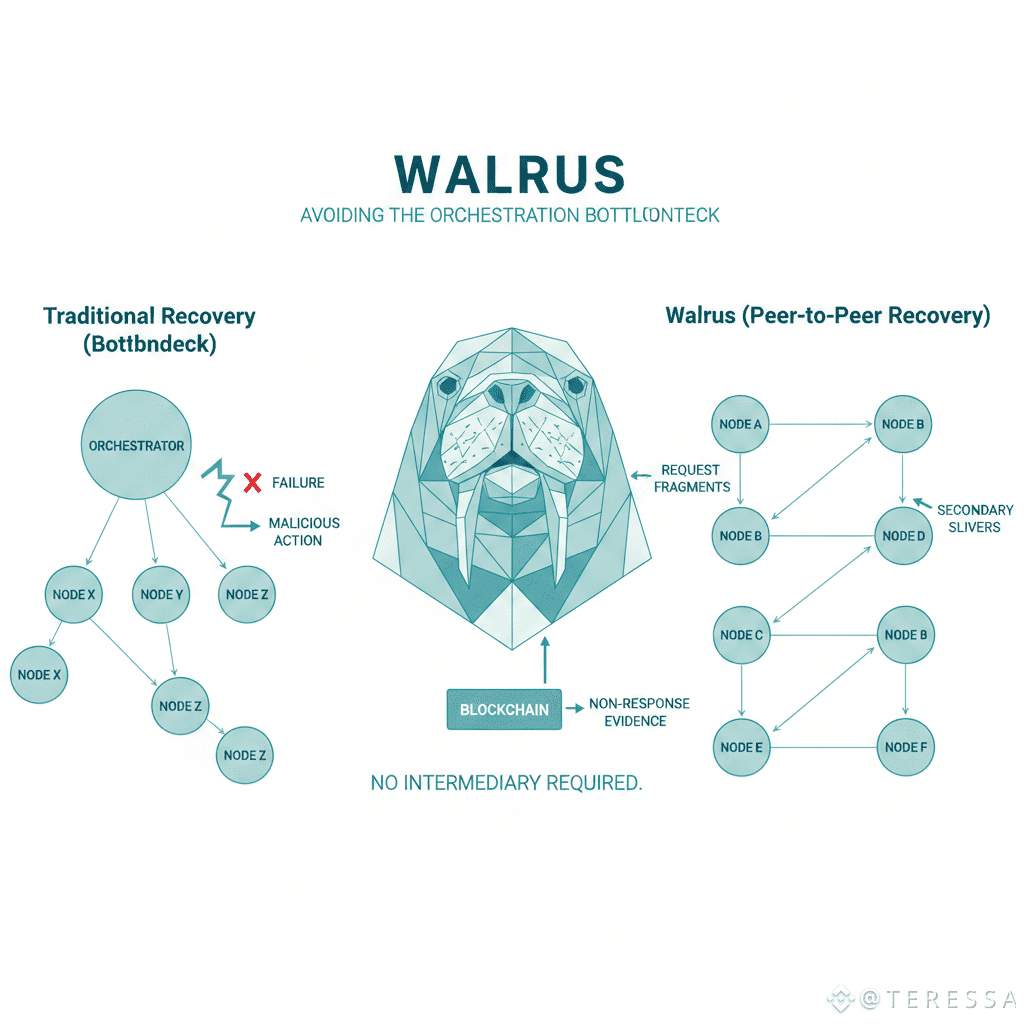
Avoiding the Orchestration Bottleneck
Traditional recovery mechanisms rely on a recovery orchestrator: either a designated node, a supermajority vote, or a centralized service. This creates a single point of failure for the healing process itself. If the orchestrator goes offline, recovery stalls. If it misbehaves, it can direct reconstruction in adversarial ways. Walrus eliminates this entirely. Because every node knows its sliver pairs, recovery is peer-to-peer. Node A needs to recover missing fragments, so it contacts its designated peer partners directly. They either respond with secondary slivers or provide evidence of non-response to the blockchain. No intermediary required.
Deterministic Pairing Prevents Collusion
The sliver pair assignments are computed deterministically from the blob's cryptographic commitment and the epoch's validator set. No node can be surprised by who its partners are, and no adversary can rearrange assignments to isolate honest nodes. An attacker would need to control all pairs simultaneously to prevent recovery. With honest majority assumptions, this is cryptographically impossible. The pairing structure itself encodes Byzantine resilience—honest nodes can always find recovery partners.
Secondary Slivers as Mutual Backup
Each assigned node stores both its primary fragment (the minimum necessary to reconstruct the blob given threshold participation) and a secondary sliver (an erasure-coded backup of related fragments). These secondaries are not redundant copies—they're algebraically independent encodings. If node X loses its primary fragment, it requests secondary slivers from its designated peers. These peers send pre-computed redundancy that, when combined, regenerates X's missing data. Crucially, the peers don't need to recompute or coordinate. They simply transmit what they already hold.
The Pair Exchange Protocol
When node A detects that it has lost fragments, it broadcasts a recovery request to its designated peer set. Node B receives this and checks: do I have the secondary sliver that corresponds to A's lost primary? If yes, it transmits immediately. If no, the absence is itself a signal. Multiple non-responses can be aggregated and posted to the blockchain as evidence of failure. The protocol then escalates to broader network healing, involving less-preferred peers or on-chain adjudication. But in the normal case, pairs respond within milliseconds, and recovery completes locally.
Verification Without Reconstruction
Here lies a subtle power: verifying recovery doesn't require reconstructing the original blob. When peers exchange secondary slivers, they prove cryptographic correctness through commitments without revealing the data itself. Merkle roots and zk-proofs confirm that transmitted pieces are authentic without requiring the receiving node to decode. This keeps verification cheap and fast. The blockchain records only that recovery occurred, not the recovery data itself. This separation—verification on-chain, data transfer off-chain—is where Walrus achieves both security and efficiency.
Cascading Pairs for Graduated Resilience
Nodes don't maintain a single pair but rather a small set of preferred recovery partners, ranked by historical reliability and network proximity. If the primary pair doesn't respond, secondary pairs activate automatically. This creates graduated resilience—the most efficient path succeeds most of the time, but failure modes degrade gracefully rather than catastrophically. A node might recover fragments from three different peers simultaneously, taking the fastest responses and discarding redundant transmissions. The protocol adapts to network conditions without explicit reconfiguration.
Honest Majority Makes Pairing Sufficient
This entire mechanism depends on honest majority. If more than half of all nodes are honest, then by pigeonhole principle, at least one of any node's designated pairs must be honest. This mathematical guarantee is what makes self-healing recovery possible without orchestration. The protocol is designed around this invariant: honest nodes will always have access to partners who can help them heal. It's a consequence of Byzantine fault tolerance theory applied to storage.
Economics of Paired Recovery
Because recovery happens between pairs rather than globally, bandwidth is localized. Instead of a failed node pulling from all remaining nodes, it pulls only from its designated partners. This reduces network load and keeps recovery costs proportional to fragment size rather than network size. Partners are incentivized to respond quickly because slow recovery reduces overall system rewards. There's no tragedy of the commons—each node benefits directly from helping its partners heal efficiently.
Why Pairing Beats Voting
Voting-based recovery requires every node to participate in deciding which fragments to regenerate and where. At thousand-node scale, this becomes a coordination nightmare. Walrus' pair-based model requires only two or three nodes to collaborate at a time. Recovery decisions are local, parallel, and independent. A thousand nodes can heal simultaneously without interfering with each other. The protocol scales sublinearly with network size because healing complexity is bounded by pair size, not total network size.

Continuous Healing as Normal Operation
The most profound implication: recovery isn't a special event but continuous background operation. Nodes check their pairs' health constantly. When any sliver goes missing, the next query triggers pair activation. By the time an operator notices a node failure, the network has already redistributed the affected fragments across multiple peers. Durability becomes a property of the protocol, not something bolted on through explicit recovery procedures. The system heals because it's structured to heal. @Walrus 🦭/acc $WAL #Walrus

