
@Vanarchain Cuando la gente dice que quiere "dApps nativas de IA", lo que suelen querer decir es algo más simple y más incómodo: están cansados del software que olvida. Están cansados de herramientas que pueden "generar", pero no pueden mantenerse consistentes, no pueden sostener un hilo, no pueden aprender sin convertirse en una pesadilla de privacidad, y no pueden actuar sin pedir constantemente permiso como un pasante nervioso. El último año llevó esta frustración a la superficie. Los agentes mejoraron en hacer cosas, pero la mayoría de ellos todavía se comportan como si tuvieran amnesia. Pueden redactar, comerciar, resumir, enrutar tickets, incluso coordinar con otros agentes, sin embargo, en el momento en que reinicias un proceso, cambias modelos, o mueves dispositivos, la inteligencia se escapa del sistema.
Por eso el marco de Vanar ha comenzado a resonar con personas que realmente construyen: tratar la memoria y el razonamiento como infraestructura, no como una característica adicional que se añade a una aplicación. En los propios materiales de Vanar, la cadena se posiciona como “construida desde cero para potenciar agentes de IA”, con soporte nativo para cargas de trabajo de IA y primitivas como almacenamiento vectorial y búsqueda de similitud integradas en el stack. La parte que me importa no es el eslogan. Es la implicación: si la cadena misma asume que tus aplicaciones serán inteligentes, entonces las dApps más útiles dejan de parecer interfaces estáticas y comienzan a parecer sistemas que pueden recordar, predecir y coordinar bajo presión real.
El movimiento más concreto “nativo de IA” al que Vanar sigue apuntando es Neutron. Neutron no se presenta como otra capa de almacenamiento donde aparcas archivos y rezas para que los enlaces no se pudran. Se describe como la transformación de archivos y conversaciones en “Semillas programables”, comprimiendo y reestructurando datos para que se vuelvan consultables y listos para agentes. Vanar establece un número claro en esto: comprimir 25MB en 50KB, e incluso menciona una relación de compresión de 500:1 como un objetivo operativo en lugar de una demostración de laboratorio. Creas o no cada afirmación de marketing, el objetivo es claro: hacer que los datos sean lo suficientemente pequeños para compartir fácilmente, organizados lo suficiente para examinar y sólidos lo suficiente para verificar.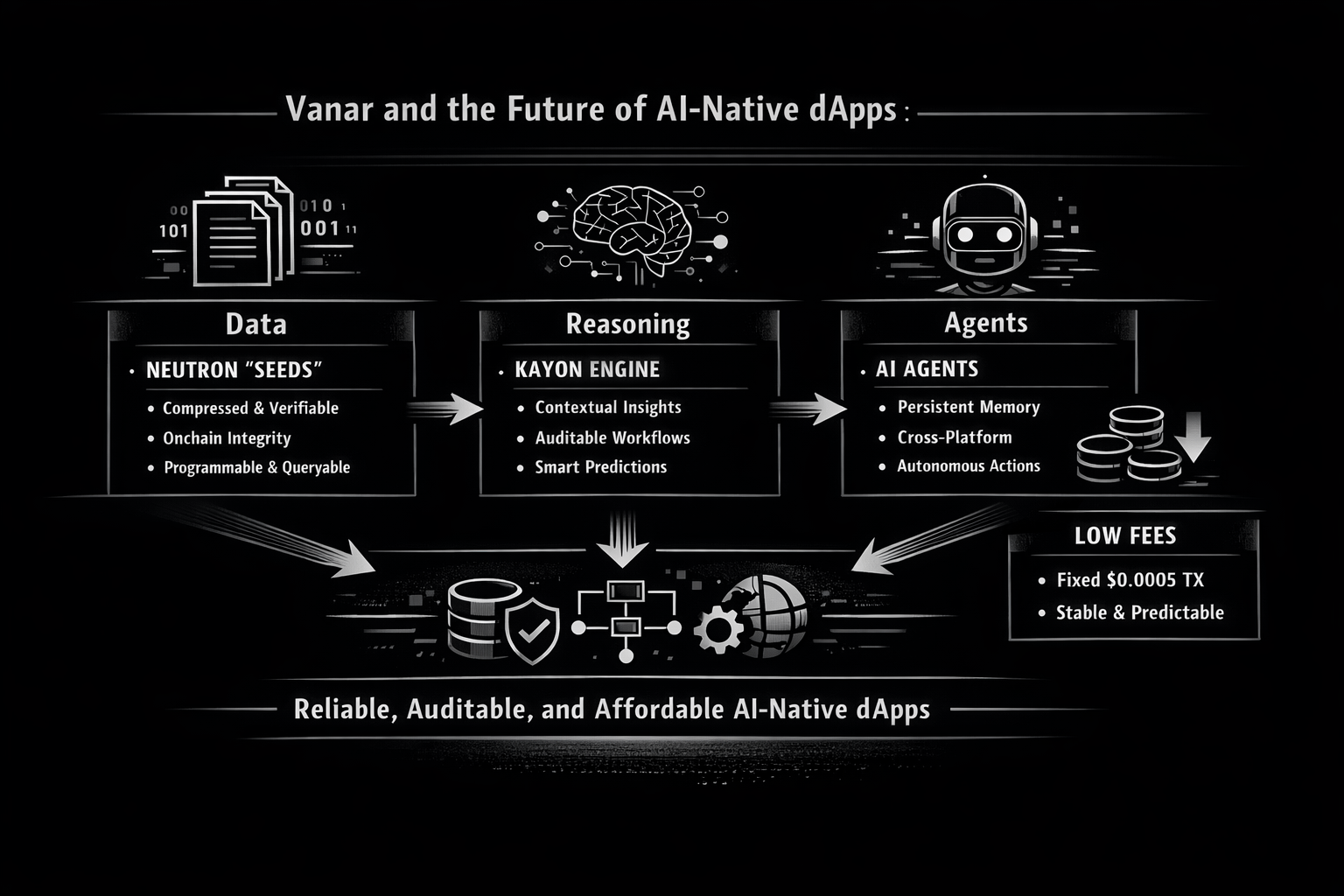 La confianza es el cuello de botella silencioso en cada historia de agentes. La mayoría de las “herramientas predictivas” hoy en día son ingeniosas hasta que se equivocan, y entonces son peligrosas porque no pueden mostrar su trabajo. El lenguaje Neutron de Vanar se enfoca en la prueba y la verificabilidad: las Semillas se enmarcan como “totalmente verificables”, y el sistema habla sobre pruebas criptográficas y “fidelidad basada en pruebas”, por lo que lo que recuperas sigue siendo válido incluso cuando está fuertemente comprimido. En la documentación, la misma filosofía aparece en una forma más sobria: las Semillas se pueden almacenar fuera de la cadena por defecto para mayor velocidad, con una capa opcional en la cadena para verificación, propiedad e integridad a largo plazo, además de cosas como metadatos inmutables, seguimiento de propiedad y registros de auditoría. Me gusta esta división porque admite una verdad con la que viven los constructores: no todo pertenece en la cadena, pero las cosas que más importan a menudo necesitan un ancla final, resistente a manipulaciones.
La confianza es el cuello de botella silencioso en cada historia de agentes. La mayoría de las “herramientas predictivas” hoy en día son ingeniosas hasta que se equivocan, y entonces son peligrosas porque no pueden mostrar su trabajo. El lenguaje Neutron de Vanar se enfoca en la prueba y la verificabilidad: las Semillas se enmarcan como “totalmente verificables”, y el sistema habla sobre pruebas criptográficas y “fidelidad basada en pruebas”, por lo que lo que recuperas sigue siendo válido incluso cuando está fuertemente comprimido. En la documentación, la misma filosofía aparece en una forma más sobria: las Semillas se pueden almacenar fuera de la cadena por defecto para mayor velocidad, con una capa opcional en la cadena para verificación, propiedad e integridad a largo plazo, además de cosas como metadatos inmutables, seguimiento de propiedad y registros de auditoría. Me gusta esta división porque admite una verdad con la que viven los constructores: no todo pertenece en la cadena, pero las cosas que más importan a menudo necesitan un ancla final, resistente a manipulaciones.
Una vez que aceptas eso, puedes ver cómo “agentes” se convierten en más que una palabra de moda. Se convierten en una nueva interfaz de usuario para finanzas, flujos de trabajo y cumplimiento—áreas donde olvidar es costoso. Vanar describe explícitamente las Semillas de Neutron como capaces de “ejecutar aplicaciones”, iniciar contratos inteligentes, o servir como entrada para agentes autónomos, y incluso afirma que la ejecución de IA en la cadena está embebida directamente en nodos validador. Esa es una dirección ambiciosa, pero señala el problema correcto: los agentes no deberían estar pegados a frágiles tuberías fuera de la cadena que se rompen en el momento en que un límite de tasa de API te limita o una base de datos cambia de forma.
Kayon es la otra mitad del argumento de “utilidad real”: razonamiento. Vanar posiciona a Kayon como un motor de razonamiento contextual que convierte Semillas y datos empresariales en “insights, predicciones y flujos de trabajo auditable”, y menciona API nativas basadas en MCP que se conectan a exploradores, tableros, ERPs y backends personalizados. Aquí es donde las herramientas predictivas se vuelven menos místicas y más prácticas. Una predicción útil en un contexto empresarial rara vez es “el precio va a subir”. Es “este patrón de pago de proveedor parece anómalo”, o “estas billeteras se comportaron así antes de una votación de gobernanza”, o “este grupo de direcciones tocó entidades sancionadas recientemente”. Los propios ejemplos de Vanar se inclinan en esa dirección, incluyendo monitoreo de cumplimiento a través de jurisdicciones y convirtiendo resultados en alertas y casos.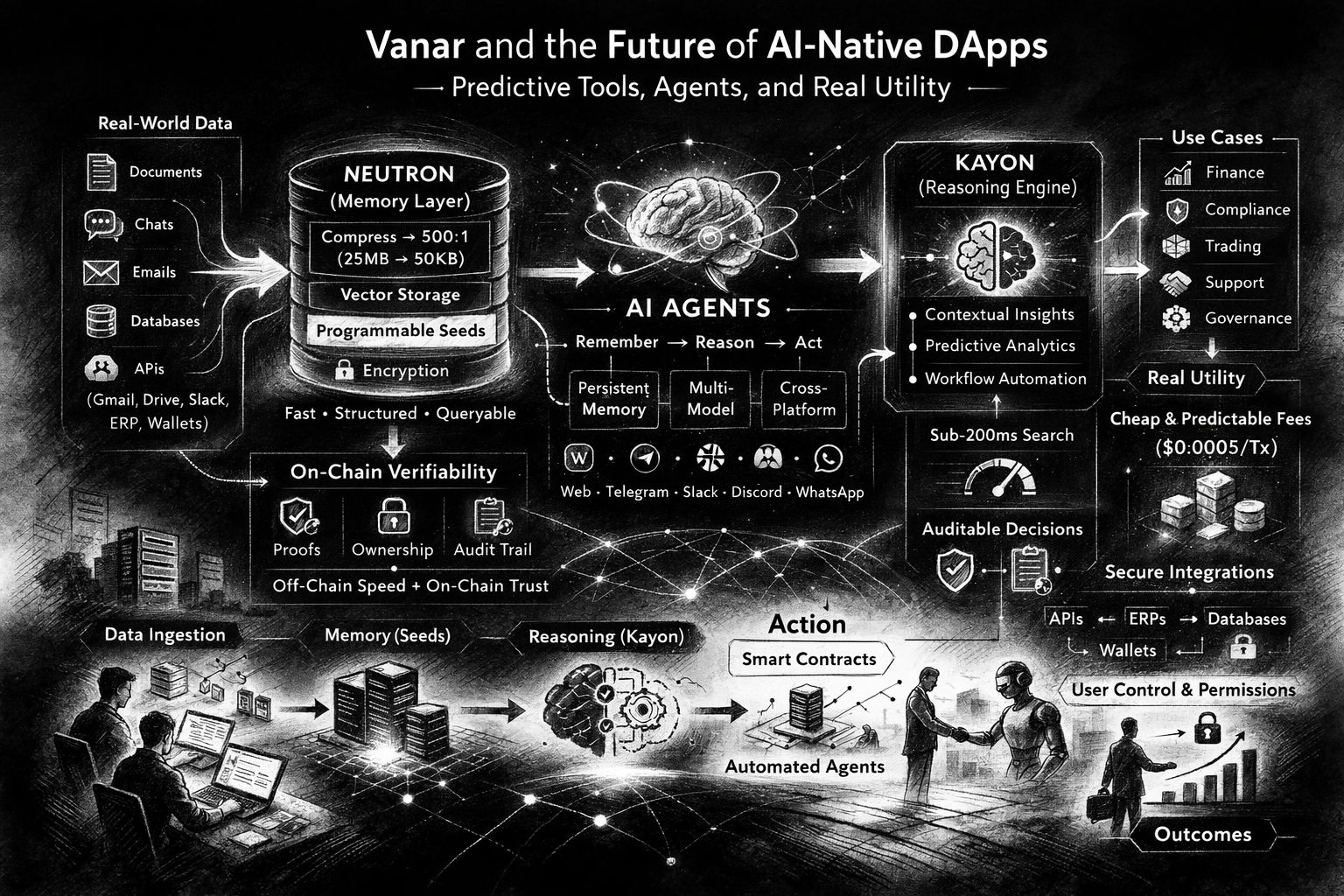
Lo que hace que esta tendencia se sienta especialmente actual es que el mundo de la IA finalmente está estandarizando cómo se mueve el contexto. En el momento en que las conexiones estilo MCP se vuelven normales, la pregunta cambia de “¿puede mi agente hacer X?” a “¿puede mi agente recordar de manera confiable las cosas que debería recordar y olvidar las cosas que debería olvidar?” Los documentos de Neutron de Vanar enfatizan conexiones seguras, permisos otorgados por el usuario, tokens encriptados, sincronización continua y eliminación rápida de contenido revocado—básicamente, la gobernanza aburrida del acceso a datos que requieren implementaciones reales. La lista de integraciones también es un indicio: Gmail y Google Drive están “actualmente disponibles”, con una larga hoja de ruta de sistemas de trabajo que vendrán a continuación, desde Slack y Notion hasta GitHub y APIs bancarias. Eso no es una lista de deseos de criptomonedas. Eso es un mapa de dónde vive realmente la memoria institucional.
La ilustración más vívida del problema de la memoria—y la razón por la que la gente está hablando de esto ahora—es el ecosistema de agentes en sí. La página de Neutron orientada a OpenClaw de Vanar describe memoria persistente para agentes a través de canales de mensajería como WhatsApp, Telegram, Discord, Slack e iMessage, y se vuelve inusualmente específica sobre el rendimiento: búsqueda semántica de menos de 200ms, recuperación respaldada por pgvector y embeddings Jina v4 de 1024 dimensiones para búsqueda multimodal a través de texto, imágenes y documentos. También menciona aislamiento multi-tenant, paquetes para organizar el conocimiento, y una API REST con un SDK de TypeScript. Estos detalles importan porque mueven la idea de “magia de IA” a “superficie de desarrollo”. Puedes imaginar construir un agente de soporte que no solo responda tickets, sino que recuerde la historia del cliente a través de canales y pueda probar qué versión de la política utilizó cuando tomó una decisión.
También hay una restricción más silenciosa que aparece tan pronto como los agentes comienzan a hacer trabajo real: la previsibilidad de costos. Si tu sistema depende de millones de pequeñas consultas y microacciones, no puedes ejecutarlo con tarifas que se comportan como un cambio de humor. Los materiales para desarrolladores de Vanar establecen un objetivo de precio de transacción fijo de $0.0005 por transacción. Y en la documentación, incluso hay una descripción de arquitectura de cómo se agregan y limpian los feeds de precios de tokens, cómo se eliminan los valores atípicos, y cómo se actualizan las tarifas a nivel de protocolo en una cadencia de bloques con un comportamiento de retroceso si el feed falla. Eso no es glamuroso, pero es la diferencia entre un agente que puede actuar continuamente y uno que se detiene porque la economía cambió de la noche a la mañana.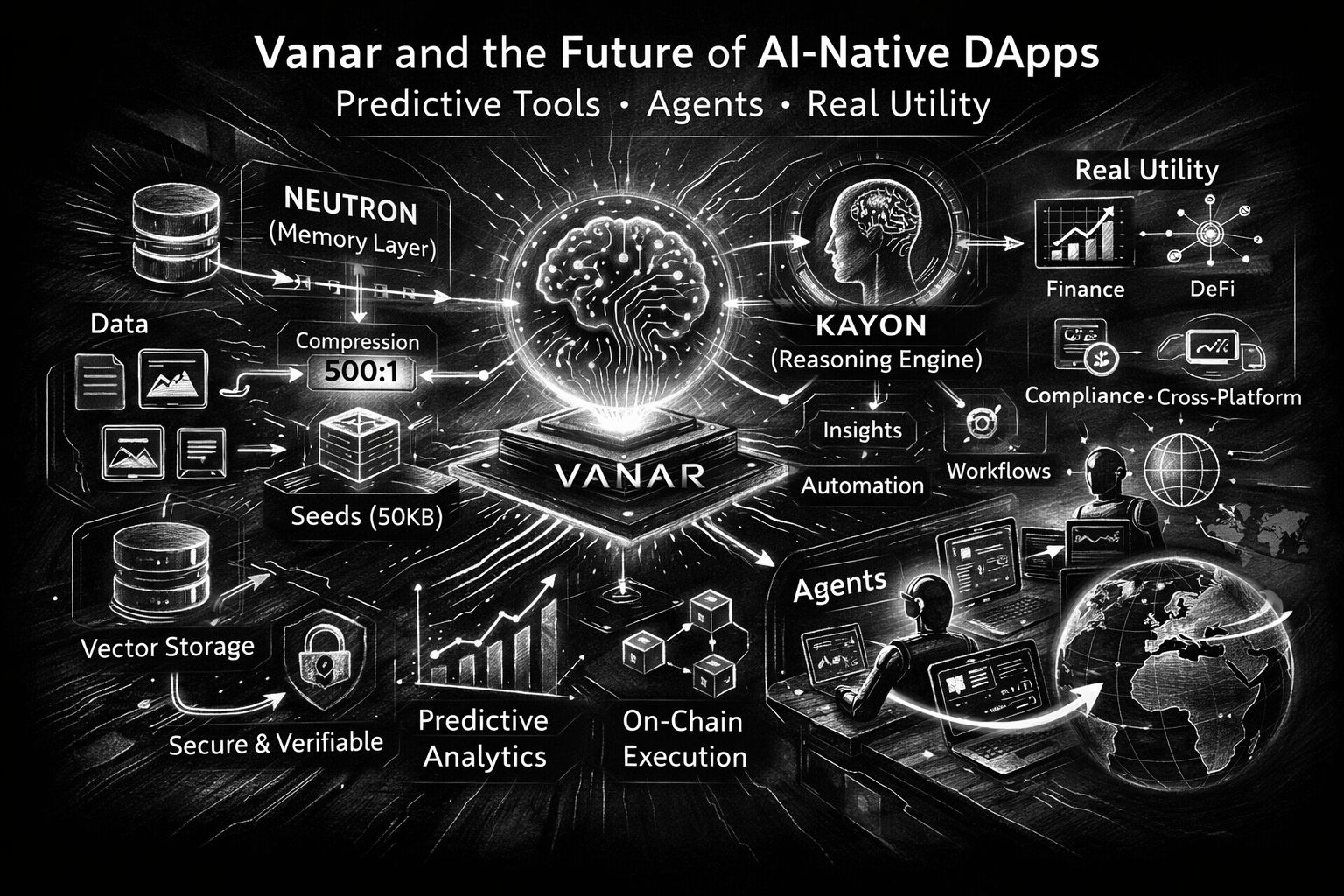
Si hago un zoom hacia atrás, la tesis de Vanar para dApps nativos de IA es básicamente esta: hacer que el conocimiento sea duradero, hacer que el razonamiento sea auditable, hacer que las acciones sean económicas y predecibles, y dar a los constructores un camino para integrarse con las herramientas donde realmente ocurre la vida. Neutron transforma datos en bruto en Semillas compactas y buscables con integridad opcional en la cadena. Kayon convierte esas Semillas en preguntas que puedes hacer en lenguaje sencillo, luego en flujos de trabajo que puedes defender en una auditoría. Y la capa de agentes se vuelve creíble cuando la memoria es rápida, portátil y debidamente autorizada, no atrapada dentro de la ventana de contexto de un solo modelo.
Mi conclusión, por lo que vale, es que la próxima ola de dApps no ganará al sentirse más futurista. Ganarán al sentirse más confiables. Las herramientas predictivas serán juzgadas menos por lo ingeniosas que suenan y más por lo bien que se mantienen consistentes a lo largo de semanas de uso. Los agentes serán juzgados menos por una demostración impresionante y más por si su inteligencia sobrevive reinicios, migraciones y cambio de proveedores de modelos. Si Vanar puede seguir traduciendo su stack en resultados aburridos y repetibles—memoria que no se pudre, razonamiento que puede ser verificado, y costos que no te sorprenden—entonces “dApps nativas de IA” deja de ser una narrativa y comienza a ser una categoría en la que la gente realmente puede confiar.
\u003cm-50/\u003e\u003ct-51/\u003e\u003cc-52/\u003e