El punto de partida de este artículo es muy simple: explicar cómo entiendo la metodología de Pyth Network de la manera más clara y reutilizable posible; al mismo tiempo, ponerlo en el contexto de la industria de datos de mercado más amplia y las aplicaciones a nivel institucional. En los últimos años, he seguido de cerca la evolución de los oráculos y la ruta de comercialización de datos, formando gradualmente un juicio simple pero útil: lo que realmente importa en la cadena de suministro de datos no es la "descentralización" decorativa, sino la producción confiable y la entrega verificable. Cuando la oferta y la demanda pueden conectarse directamente en la cadena, de manera auditada, el valor es más fácil de capturar de manera estable.
Para mí, Pyth no es solo "otro componente de precios", sino una línea de producción de datos de precios que va desde su origen hasta su distribución multi-cadena. El modelo tradicional es más parecido a un "transmisor de información", donde los datos pasan por intermediarios, agregadores y nodos intermedios; la latencia, la incertidumbre y la falta de trazabilidad a lo largo del camino a menudo se convierten en un terreno fértil para riesgos sistémicos. Pyth adopta un modelo de datos de primera fuente, permitiendo que los exchanges, market makers y proveedores de datos profesionales firmen y publiquen directamente en cadena; luego, Pythnet los agrega, verifica y calcula el intervalo de confianza, distribuyéndolos a aplicaciones de préstamos, opciones, activos sintéticos e índices mediante suscripciones bajo demanda. Resumo esta trayectoria como: no ser un simple eco, sino construir una "línea de producción de precios verificables".
I. Techo de mercado y necesidades reales.
El valor en la industria de datos proviene de ambos extremos: un extremo es la calidad y la actualidad de la fuente, y el otro es la accesibilidad y sensibilidad al costo del consumidor. En los mercados financieros tradicionales, la distribución de datos y los precios en tiempo real son categorías de pago estables a largo plazo; al trasladarse al mundo cripto, la demanda no ha cambiado, solo se ha elevado la exigencia de "verificabilidad" y "programabilidad". Las estrategias de préstamos y liquidación requieren actualizaciones de baja latencia y estables; la fijación de precios de opciones depende de estimaciones razonables de volatilidad; los activos sintéticos requieren consistencia en la fijación de precios durante altas volatilidades. Estas necesidades básicas generan una demanda continua de precios de alta calidad, que es la motivación fundamental de mi inversión continua en investigación y creación. La visión de Pyth, que comienza en DeFi, se extiende hacia servicios de datos de mercado más amplios; considero que es el camino "difícil pero correcto".
II. Descomposición operativa de producto y arquitectura.
Suelo descomponer cualquier producto de datos en cinco etapas: producción original, publicación confiable, agregación y verificación, distribución y liquidación, retroalimentación y optimización. En Pyth, la producción original proviene de exchanges de primera línea, market makers y proveedores de datos profesionales; estos actúan como "publicadores" en cadena, y cada mensaje lleva una firma de origen, lo que constituye el fundamento de la trazabilidad. La publicación confiable se basa en Pythnet, que realiza deduplicación, limpieza y alineación de marcas de tiempo, y calcula el intervalo de confianza a partir de múltiples fuentes. Después de la verificación, los precios se distribuyen a través de canales multi-cadena a las aplicaciones; el mecanismo de "suscripción y solicitud" permite a los usuarios decidir la frecuencia de activación según sus preferencias de costo y latencia, reduciendo transacciones innecesarias y ruido en cadena. Este diseño integra los dos indicadores aparentemente contradictorios de "velocidad" y "estabilidad" en un solo objetivo técnico. Desde mi experiencia práctica, los desarrolladores solo necesitan comprender la estructura de campos del objeto de precio, la precisión temporal y el intervalo de confianza para integrarse sin problemas.
La siguiente gráfica estructural muestra los nodos clave y puntos verificables desde la fuente hasta la aplicación, facilitando la comunicación con el equipo sobre detalles estrictos de implementación y límites.
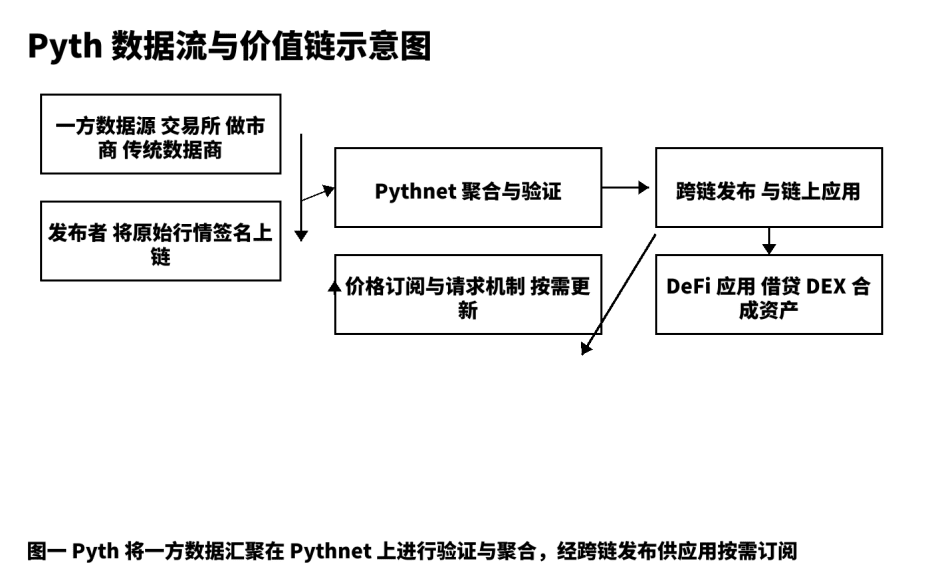
III. Comparación de cinco dimensiones y elección estratégica.
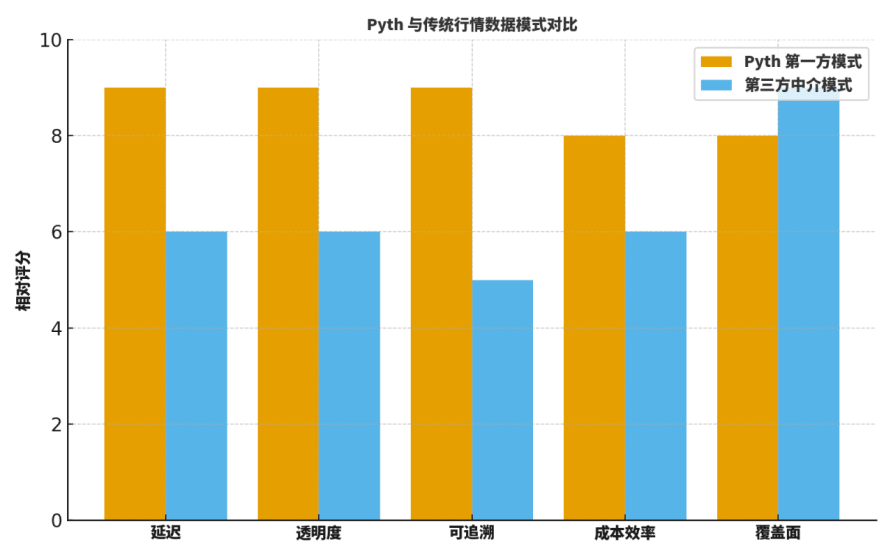
Muchos compañeros preguntan: ¿cuál es la diferencia real entre Pyth y los "oráculos mediadores" tradicionales o los proveedores de datos establecidos? Por lo general, los comparo desde cinco dimensiones: latencia, transparencia, trazabilidad, eficiencia de costos y cobertura.
En primer lugar, en cuanto a latencia, la publicación directa de primera fuente reduce significativamente los pasos intermedios, lo que se traduce en actualizaciones más rápidas;
En segundo lugar, en transparencia y trazabilidad, las firmas de origen y los procesos de agregación verificables ofrecen visibilidad a nivel detallado;
En tercer lugar, en eficiencia de costos, se eliminan grandes cantidades de costos asociados a la recuperación externa y la retransmisión de múltiples niveles;
En cuarto lugar, en cobertura, los grandes actores tradicionales aún tienen ventaja en categorías históricas y distribución geográfica;
En quinto lugar, en colaboración técnica, el modelo de "suscripción bajo demanda" de Pyth facilita la integración con parámetros de riesgo y sistemas de alerta.
Por lo tanto, la estrategia no es "todo o nada", sino priorizar el uso de Pyth en escenarios clave: los sectores de préstamos, liquidación, opciones y activos sintéticos son los "ejemplos de referencia" que más valoro al tomar decisiones de selección.
Para ayudar a los lectores a desarrollar intuición, ofrezco un gráfico de "calificación relativa", que no es una conclusión absoluta, pero es muy adecuado como punto de partida para discusiones y plantillas de revisión.
IV. La "segunda fase" en la ruta de desarrollo: suscripción de datos de nivel institucional.
En la práctica de creación de contenido y consultoría, divido la estrategia de Pyth en dos fases interconectadas:
Primera fase: establecer estándares de precios en escenarios de alta velocidad de DeFi, con enfoque principal en calidad y velocidad;
Segunda fase: transición hacia un producto de suscripción de datos de nivel institucional, incluyendo: niveles de latencia en servicios de nivel de servicio (SLA), registros auditables, un sistema de etiquetas de anomalías para riesgos, interfaces modulares de facturación y reconciliación, entre otros.
Este paso extiende la capacidad técnica en servicios: conecta las señales de precios con capacidades organizativas como regulación, cumplimiento y gestión de riesgos; también vincula de forma real el ingreso sostenible con la gobernanza de la red. Me preocupa especialmente si el modelo de servicio repetible puede funcionar, por ejemplo:
(1) ofrecer planes de suscripción con diferentes niveles de latencia y frecuencia de actualización;
(2) exportar y registrar el origen, firma y marca de tiempo de cada actualización de precio, así como la lista de publicadores que participan en la agregación;
(3) las etiquetas de anomalías para riesgos deben permitir reproducción, revisión posterior y asociación con eventos de riesgo.
Estos detalles determinan si las instituciones están dispuestas a migrar y hasta qué punto están dispuestas a pagar.
V. Utilidad del token y cierre económico.
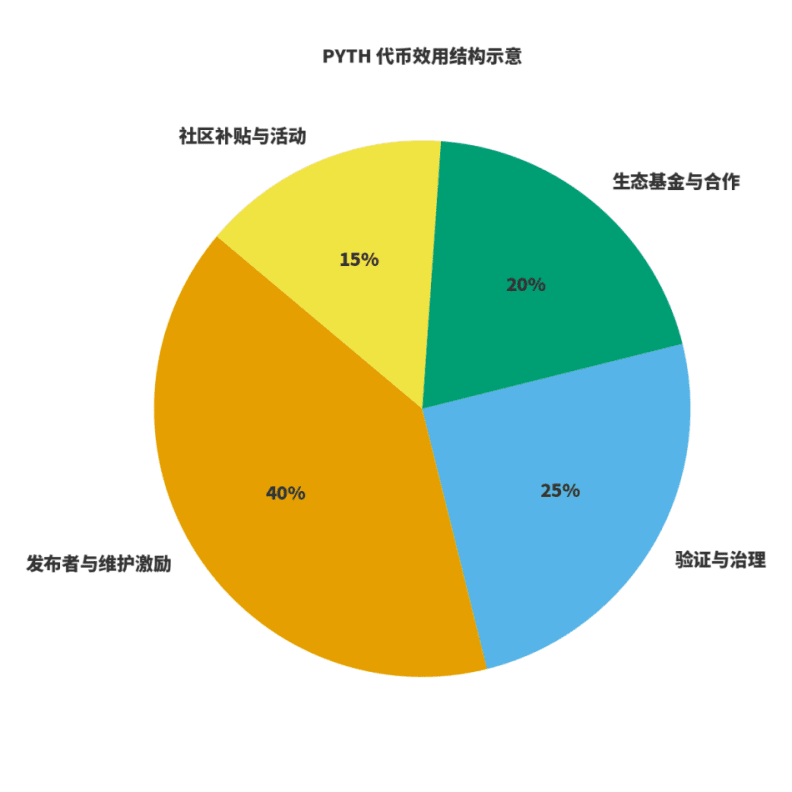
Para evaluar si una red está sana, hay dos aspectos clave: primero, si los ingresos están vinculados a la creación de valor; segundo, si los incentivos están ligados a la calidad a largo plazo. Para $PYTH , lo entiendo como tres roles: combustible para la producción y mantenimiento de datos; peso en gobernanza y verificación; palanca para el crecimiento ecológico. Los publicadores y mantenedores participan con incentivos de tokens predecibles; los ingresos de la red provienen de suscripciones y uso de datos, y la gobernanza distribuye estos ingresos entre mantenimiento, incentivos y expansión ecológica. Con base en esto, he elaborado un diagrama de "distribución de utilidad", cuyas proporciones se ajustarán ligeramente con la evolución de la gobernanza, pero el principio permanece constante: el mantenimiento y publicación tienen un peso mayor; la gobernanza y verificación aseguran la estabilidad; la ecosfera y la comunidad se encargan de la expansión y el rompimiento de barreras.
VI. Lista de implementación orientada a instituciones.
Basado en experiencias previas de integración, he elaborado una lista directamente utilizable:
Primero, definir el dominio de datos y los límites de servicio: qué es una cotización básica y qué pertenece a capas adicionales;
Segundo, alinear el acuerdo de nivel de servicio (SLA): incluyendo latencia de actualización, estabilidad, manejo de anomalías, estrategia de alerta y planes de contingencia;
Tercero, proporcionar una canalización de registros auditables: registrar el origen, los cambios en el intervalo de confianza y las etiquetas de anomalías de cada actualización de precio;
Cuarto, integrar con el marco interno de riesgo y backtesting: conectar el flujo de precios al sistema de reproducción para verificar la estabilidad de la estrategia bajo distintos umbrales y ventanas temporales;
Quinto, estandarizar la facturación y reconciliación: las instituciones se preocupan más por plazos predecibles y detalles claros de reconciliación.
En esta lista, la ventaja explícita de Pyth es la verificabilidad desde la fuente hasta la agregación, lo que reduce significativamente el tiempo de evaluación de cumplimiento y riesgo.
VII. Mapa de riesgos y diseño anti-frágil.
Clasifico los riesgos en tres tipos: publicación anómala en la fuente, sincronización anómala entre cadenas y amplificación de latencia en mercados extremos. Los mecanismos de mitigación deben ser "institucionalizados" en el diseño técnico. Mis prácticas habituales incluyen: suscripciones múltiples con verificación por umbrales; reducción automática de apalancamiento vinculada al intervalo de confianza; protección contra deslizamientos y ponderación temporal en el contrato de transacción; y simulaciones trimestrales en mercados extremos, acompañadas de scripts de reproducción y plantillas de revisión. Estas prácticas técnicas disciplinadas, combinadas con los registros verificables de Pyth, pueden mejorar significativamente la capacidad de resistencia del sistema.
VIII. Sugerencias narrativas para creadores de contenido y desarrolladores.
Siempre he enfatizado: el valor del creador consiste en traducir el valor técnico complejo en un lenguaje que los lectores y usuarios puedan entender y utilizar. Si se quiere hablar de Pyth, recomiendo comenzar con la "transformación de paradigma", más que quedarse en la "competencia de oráculos". Hablar de cómo alinea la oferta y la demanda en cadena de forma auditable; cómo reduce el riesgo de cola mediante intervalos de confianza y procesos de agregación visuales; cómo conecta la capacidad de servicio con el cierre comercial a través de suscripciones de nivel institucional. Esto es más convincente para los profesionales que simplemente enumerar métricas generales.
IX. Los indicadores que seguiré durante el próximo año.
Primero, amplitud y profundidad de integración ecológica: cobertura de los principales proyectos en cuatro categorías: préstamos, activos sintéticos, opciones e índices;
Segundo, progreso en la productivización de suscripciones institucionales: si los niveles de latencia, el acuerdo de nivel de servicio (SLA) y los registros auditables se actualizan según lo planeado;
Tercero, transparencia en ingresos y asignación del protocolo: si se ha establecido una métrica pública y verificable;
Cuarto, avances regulatorios en diferentes jurisdicciones: incluyendo cumplimiento de exportación de datos y cumplimiento de servicios financieros.
Estos indicadores influirán directamente en mis temas de contenido y ritmo, y también en mi evaluación a largo plazo del valor de PYTH.
X. Guía para desarrolladores: de cero a uno.
Para ayudar a los nuevos colaboradores a avanzar más rápido, ofrezco una "método de tres pasos" ejecutable.
Primer paso: completar una llamada de suscripción de precios en un entorno de prueba; entender la estructura de precios, la precisión temporal y los campos de intervalo de confianza;
Segundo paso: integrar la "estrategia de suscripción y solicitud" en contratos o robots de trading, comparando mediante un sistema de backtesting las diferencias de rendimiento entre distintos umbrales y ventanas temporales;
Tercer paso: integrar alertas y monitoreo; establecer umbrales de alerta según indicadores de riesgo y incorporar las etiquetas de anomalías en la reproducción y revisión posterior.
Cuando completes estos tres pasos, no solo estarás usando Pyth, sino que también habrás implementado el concepto de "datos verificables" en tu código.
XI. Comparación entre industrias y espacios de colaboración.
No defiendo una mentalidad de suma cero. En escenarios con mayor cobertura pero menor exigencia de latencia, los proveedores de datos tradicionales aún tienen ventajas; mientras que en escenarios altamente sensibles a la latencia y verificabilidad, el modelo de primera fuente de Pyth tiene más ventaja. En el futuro, espero que los desarrolladores combinen flujos de datos de diferentes fuentes de forma modular, ajustando dinámicamente el equilibrio entre costo y rendimiento según su función objetivo.
@Pyth Network #PythRoadmap $PYTH