Plasma breaks retries at the edge of custody.
The payment clears. USDT settles. PlasmaBFT finality lands while the asset is still moving between internal hands.
It doesn’t show up on-chain. It shows up in the handoff.
A platform routes funds into a hot wallet first. Standard. From there, it sweeps to a custody account, then onward to wherever balances are actually managed. The sweep job runs every few seconds. Usually that’s fine.
This time it overlaps.
The first sweep starts after finality. The retry starts before the first sweep commits its internal state. Same tx reference. Same amount. Different internal step.
At first glance, nothing’s wrong.
The Plasma network relayer already did its part. Sponsored lane accepted the transfer. PlasmaBFT closed it. The chain has no concept of “custody stages.” It just knows the payment exists.
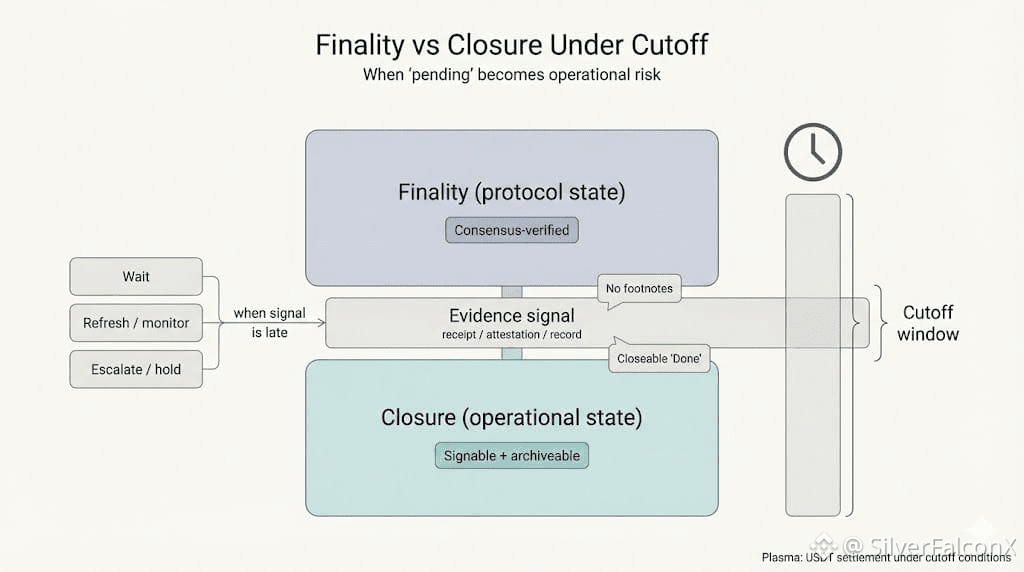
Inside the platform, the bookkeeping isn’t caught up yet.
One process marks the balance available. Another still treats it as in-flight. A guardrail doesn’t see the first update fast enough and fires a retry. Funds get earmarked twice. Not sent twice. Not stolen. Just reserved in two different places, both acting like they’re the truth.
Treasury notices later, not because money is missing, but because liquidity looks thinner than it should. The numbers don’t reconcile cleanly. A balance that should be free is locked in two places and nobody can tell which lock to respect without breaking something else.
Support can’t see it. Users can’t see it. The chain is already finished.
Ops starts tracing execution order. Timestamp against timestamp. PlasmaBFT finality at one end. Internal custody commit at the other. The gap is tiny. Still wide enough to slip a retry through.
On slower systems, that gap gets buried under settlement lag. Here it’s exposed. Finality lands before custody logic finishes agreeing with itself.
The questions come out half-formed.
Is the retry logic too aggressive, or is custody too slow? Should the sweep be single-threaded—wait, would that just bottleneck everything? And why was “available” marked before the sweep finished in the first place?
None of that rewinds what’s already happened.
You don’t end up with a double spend. You end up with internal contention: two pieces of the same stack trying to be correct at the same time, because the chain got certain before the custody path did.
I’ve seen teams miss this in testing because load tests quietly assume a little delay. Production doesn’t give you that luxury once PlasmaBFT is closing in sub-second windows.
The fixes are annoying, not heroic.
Some teams stop marking balances early and wait for custody confirmation, even if it costs perceived speed. Others tighten retry guards so they only fire after custody state commits, not just after chain confirmation. A few serialize the whole path and eat the throughput loss to buy clarity.
A lot don’t change the core. They patch symptoms. Manual unlocks. Emergency scripts. “Why is this wallet locked?” in Slack at odd hours, again.
Plasma didn’t break custody.
It just made the disagreement impossible to ignore. #Plasma

