
The AI Second Brain: How @Vanarchain 's Neutron Is Changing What It Means for AI to Remember🧠
There is a problem baked into almost every AI agent running today, and it is so fundamental that most people have stopped noticing it. Every time you start a new conversation, the AI forgets everything. Not some things. Everything. The project you briefed it on last Tuesday, the decisions you made, the workflow it was halfway through executing, all of it gone the moment the session ends. It is like hiring a brilliant assistant who suffers total amnesia every night at midnight.

#vanar , an AI-native blockchain company, has decided to treat this not as a minor inconvenience but as the defining structural flaw of the current AI era. Their answer is Neutron, a semantic memory layer that functions, in their words, as a second brain for AI agents. And with their latest move integrating Neutron directly into OpenClaw, one of the fastest-growing open-source AI agent frameworks in the world, the implications are starting to become very real.
What is Neutron, and what is this "semantic memory" thing?
To understand what Neutron does, you first need to understand the difference between how AI agents store information today versus how human memory actually works.
Current AI agents mostly rely on what is called session-bound memory. When you talk to an AI, it keeps track of the conversation in something called a context window, essentially a running transcript of your exchange. When that session closes, the transcript disappears. Some agents do slightly better by keeping local logs or basic vector databases on the device, but even these are fragile, isolated to one machine, and not designed to survive restarts, redeployments, or moving to a different platform.
Semantic memory is a different beast entirely. Rather than storing raw transcripts or files, semantic memory captures the meaning, context, and relationships within information. Your brain does not store memories as word-for-word recordings. It stores concepts, associations, and patterns. Semantic memory for AI works on a similar principle, using high-dimensional mathematical structures called vector embeddings to represent the meaning of information, not just the literal words. This means when an agent needs to retrieve something, it searches by meaning rather than by exact keyword match, in the same way you might recall a conversation not by the precise words spoken but by what the conversation was about.
Neutron compresses and restructures data into what Vanar calls Seeds, which are fully on-chain, fully verifiable, and built for agents, apps, and AI. The system uses a combination of neural structuring, semantic embedding, and cryptographic proofs to reduce files down to a fraction of their original size, with Vanar claiming compression ratios as high as 500 times, while preserving the meaning and making it retrievable by AI.

Think of a Seed as a compressed, cryptographically sealed capsule of knowledge. It does not just store what something said. It stores what it meant, in a form that any AI agent can later query and understand.
The problem Neutron was built to solve
Every conversation with AI starts from zero. Every platform switch requires uploading the same documents again. Every brilliant insight risks being lost forever. That is how Vanar's CEO Jawad Ashraf framed the core problem when launching Neutron Personal last August, and it captures the frustration that anyone who has worked seriously with AI agents knows well.
The consequences go beyond inconvenience. For autonomous AI agents that are meant to operate continuously, handle multi-stage workflows, manage on-chain transactions, or serve as enterprise knowledge systems, session-bound memory is not just annoying. It is a fundamental blocker. An agent that forgets everything it did cannot compound learning over time. It cannot pick up where it left off. It cannot be upgraded or migrated without starting from scratch. Every reboot is a reset to zero.
Neutron organizes both structured and unstructured inputs into compact, cryptographically verifiable knowledge units referred to as Seeds, allowing for durable memory recall across distributed environments. As a result, agents can be restarted, redeployed, or replaced without losing accumulated knowledge.
This is the shift Neutron is designed to make possible. Memory that survives the agent, rather than dying with the session.
Enter OpenClaw
To understand why this integration matters, you need to know what OpenClaw is. OpenClaw is a self-hosted AI agent assistant created by developer Peter Steinberger. Unlike a standard chatbot, OpenClaw is designed to live on your local hardware and execute real-world tasks. Its local-first architecture means your private data never leaves your server.
OpenClaw is a viral open-source personal AI agent with over 68,000 GitHub stars, bringing together the technology of agents with the data and apps you use on your local machine to serve as a high-powered, high-context AI assistant. Many describe it as self-improving because it can enhance its own capabilities by autonomously writing code to create relevant new skills to execute desired tasks.
OpenClaw has been described as the closest thing to JARVIS that actually exists today. It can talk to you via WhatsApp, Telegram, Discord, or Slack. It can browse the web, manage files, run code, and operate autonomously for extended periods. It is one of the most significant open-source AI agent projects of early 2026, and it already had over 100,000 GitHub stars at its peak of viral growth.
But before the Neutron integration, OpenClaw had the same memory problem as everything else. OpenClaw's existing memory model relied largely on ephemeral session logs and local vector indexing, which restricted an agent's ability to maintain durable continuity across multiple sessions. Every time you restarted your machine, or switched to a different device, or updated the software, the accumulated context could be partially or fully lost.
What the integration actually does
With Neutron's semantic memory incorporated directly into OpenClaw workflows, agents are able to preserve conversational context, operational state, and decision history across restarts, machine changes, and lifecycle transitions.
In plain terms: your OpenClaw agent now has a persistent brain. It can be shut down, upgraded, moved to a new machine, or completely redeployed, and it will remember who you are, what you are working on, what decisions have already been made, and what context matters. The knowledge does not live on one device. It lives in Neutron Seeds stored on-chain, cryptographically bound and always retrievable.
The integration enables OpenClaw agents to maintain continuity across communication platforms such as Discord, Slack, WhatsApp, and web interfaces, supporting long-running and multi-stage workflows. This broadens the range of potential deployments across customer support automation, on-chain operations, compliance tooling, enterprise knowledge systems, and decentralized finance.
Neutron employs high-dimensional vector embeddings for semantic recall, allowing agents to retrieve relevant context through natural-language queries rather than fixed keyword matching. The system is designed to achieve semantic search latency below 200 milliseconds, supporting real-time interaction at production scale.
That last point matters more than it might seem. Semantic search under 200 milliseconds means the memory retrieval is fast enough to feel natural inside a live conversation. The agent is not pausing to dig through an archive. It is remembering in real time.
For developers, the integration comes through a REST API and TypeScript SDK, meaning teams can plug Neutron into existing OpenClaw architectures without rebuilding from scratch. Multi-tenant support keeps memory isolated across different organizations, users, and projects, which is essential for enterprise deployments where data separation is non-negotiable.
The bigger picture: what Vanar is actually building
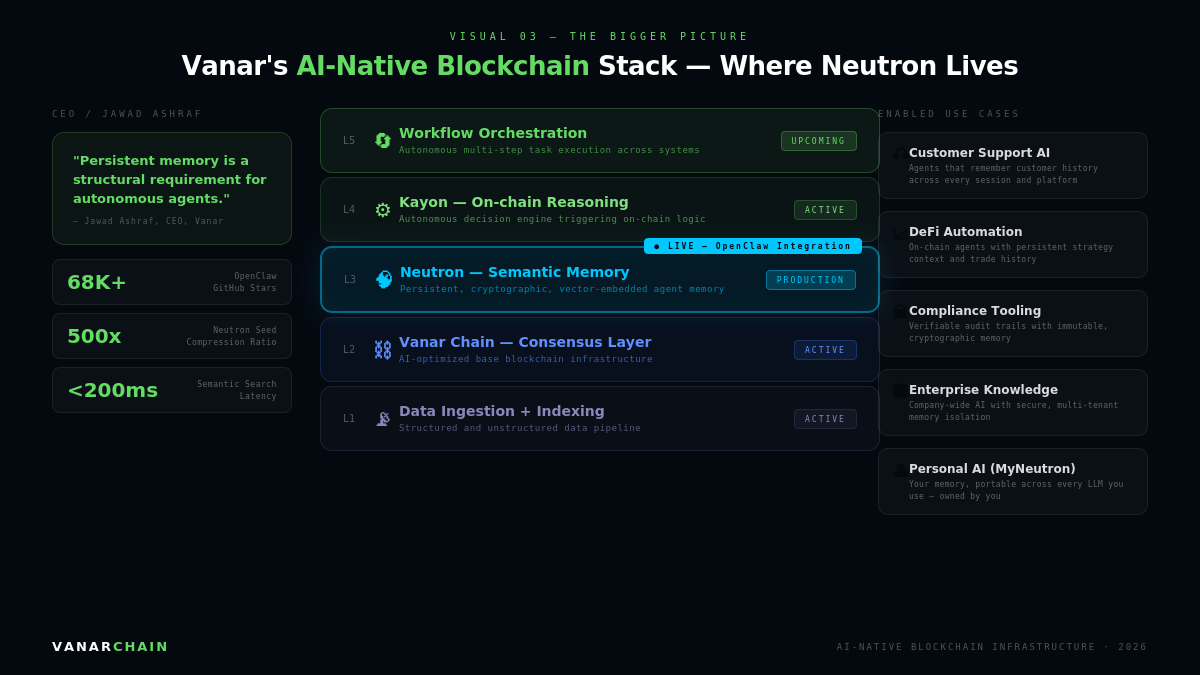
The OpenClaw integration is one piece of a larger architectural vision. Vanar Chain is designed as the first blockchain infrastructure stack purpose-built for AI workloads, with a five-layer architecture that enables every Web3 application to be intelligent by default. Neutron serves as the intelligent data storage layer that understands meaning, context, and relationships, transforming raw data into queryable, AI-readable knowledge objects.
The broader stack also includes Kayon, an on-chain reasoning engine, and upcoming layers for task automation and workflow orchestration. The vision is not just memory for agents but a full intelligent infrastructure where data does not just sit on a blockchain passively. It thinks, triggers logic, and feeds into autonomous workflows.
Seeds are portable, verifiable, and composable across chains and apps, meaning your AI context finally belongs to you. Users can capture anything with one click including webpages, PDFs, Gmail, Drive, Slack, or LLM chats, with Seeds auto-organizing into semantic, searchable memory units. They can then inject those Seeds into ChatGPT, Claude, or Gemini with one click, and anchor them on-chain for permanent, verifiable storage.
This is where the "second brain" framing becomes meaningful. MyNeutron is not just a developer tool. It is designed for individuals who want their AI memory to be portable and permanent across every platform they use, owned by them rather than by whichever company runs the AI service they happen to be using that day.
Why this matters now
The timing of this development is not coincidental. 2026 is shaping up as the year where the AI agent conversation moves from "can agents do tasks" to "can agents do tasks reliably and continuously over time." The single-session, forget-everything model is increasingly being recognized as a ceiling, not a baseline. Vanar is betting that whoever solves memory at the infrastructure level, and solves it in a way that is verifiable, portable, and decentralized, will become foundational to where AI agents go next.
Jawad Ashraf put it directly: "Without continuity, agents are limited to isolated tasks. With memory, they can operate across time, systems, and workflows, compounding intelligence instead of resetting context."
Compounding intelligence. That is the phrase worth sitting with. The most powerful human professionals are not simply smart in isolated moments. They accumulate context, pattern recognition, and institutional knowledge over years. If AI agents are going to operate at the level people actually need from them, they need the same ability to build on what they already know rather than starting fresh every single time.
Vanar is not the only company thinking about this problem. But they are one of the few who have built a production-ready answer that sits on-chain, is cryptographically verifiable, achieves sub-200ms retrieval, and is now live inside one of the most widely used open-source agent frameworks in the world. The second brain for AI agents is no longer theoretical. It is already running.
