
There is lots of discussion about the velocity of markets. We care about quick trades, quick settlement, quick block times. And in the world of storage, there is a counterpart to the value of velocities: the value of durability. And over the last year or so, Walrus has actually been a nice model or case study for the tension between the two. As someone who has seen the cycles of infrastructure underway now in both traditional markets and cryptocurrency markets, I find that much more fascinating than the moves in the price.
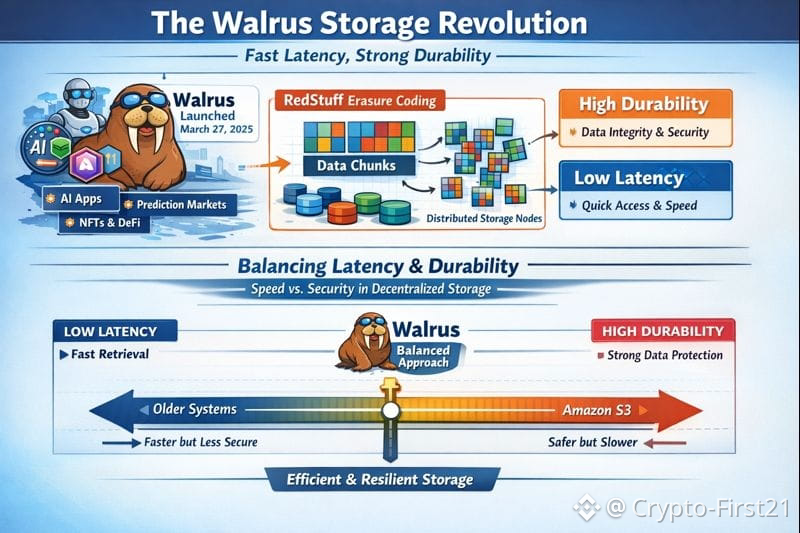
The official public mainnet launch of Walrus occurred on March 27th, 2025. By the end of 2025, it was integrated with dozens of applications in artificial intelligence, prediction markets, NFTs, and DeFi coins, while in January 2026, it was storing millions of objects in total. While what made Walrus unique was not so much its throughput potential but rather how it was attempting to balance latency requirements against durability requirements in the store, it’s also worth mentioning that this is a balance every serious store has to maintain – be it Amazon S3 or a decentralized store.
And by latency, I just mean how long a process, a read, a write, a put, a take, however you look at it, actually takes. So, less latency makes things go more quickly. The question of durability is, how long does that information exist, okay, in a form that's more secure, in a sense, if machines fail, networks fail, people try to cheat, etc., etc., etc. Being more durable involves a lot of machines, naturally, because that makes things go more slowly.
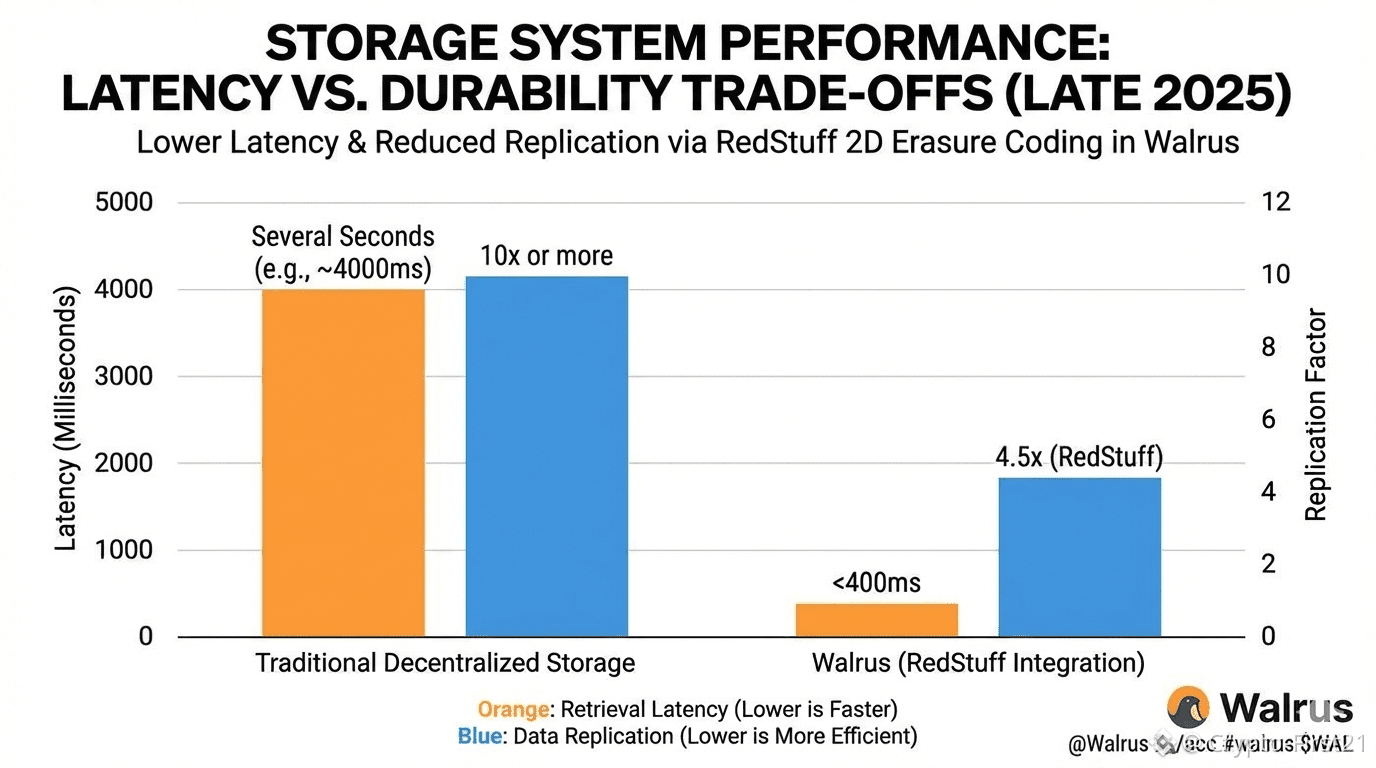
Walrus achieves this through the use of a technique called two-dimensional erasure coding, dubbed "RedStuff." In short words, instead of copying the whole file many times over the network, Walrus divides its data into many small pieces and stores those pieces remotely from each other. Nevertheless, the original file could be re-created even when more nodes within the network fail compared to the total number of nodes. Research done in May 2025 proved the ability to offer the same comparison to traditional durability by using just 4.5x data replication instead of 10x or more.
That matters because durability is expensive. Traditional decentralized storage networks often sacrifice speed for safety, leading to slow upload and retrieval times. Walrus aimed to reduce that gap. Internal benchmarks published in late 2025 showed median retrieval latency under 400 milliseconds for medium-sized files, even while maintaining strong recovery guarantees. That puts it in a very different class from early decentralized storage systems that often took several seconds.
This is not without its cost, however. For durability, Walrus employs constant cryptographic challenges to ensure that storage providers are indeed in possession of data. This incurs some overhead. If Walrus were to remove these checks, latency would decrease but the system would be more susceptible to exploitation. This, of course, is the very trade-off an engineer has to make: shave milliseconds, or preserve trust.
Why is this trending now? Because the AI workloads are forcing the issue. Training datasets, model checkpoints, and real-time inference logs are enormous. By late 2025, decentralized AI apps were storing terabytes of data monthly. Systems that are durable but slow become unusable in that environment; systems that are fast but fragile become risky. Walrus sits directly in that tension.
One integration that epitomized this is Myriad, a prediction market platform which partnered with Walrus in December 2025. Their system required fast writes for live market data but long-term storage so results could be audited months later. In interviews, their team cited Walrus' balance between latency and durability as the main reason for the adoption. That's just the kind of real-world pressure that shapes protocol design more than whitepapers ever do.
Infrastructure, from a market perspective, rarely gets attention until something breaks. Many outages of centralized storage services at the end of 2024 and beginning of 2025 reminded developers that speed without redundancy is fragile. Older decentralized systems were too slow for real-time applications. That gap was the open door through which Walrus stepped at the right moment.
This reminds me, from my experience, of early electronic trading. At first, the game was all about speed. Then a few big systems failures made resilience the hot topic. Eventually, the industry learned to engineer for both. Crypto infrastructure is going through the same cycle; it's just getting compressed from decades into a couple of years.
However, the deeper message is that latency and durability are not necessarily enemies. Both are limitations and define how design should proceed. It is not that Walrus avoids the trade-off, but transforms it fundamentally. It makes durability cheaper and faster, and thus puts more possibilities in the hands of decentralized applications to attempt.
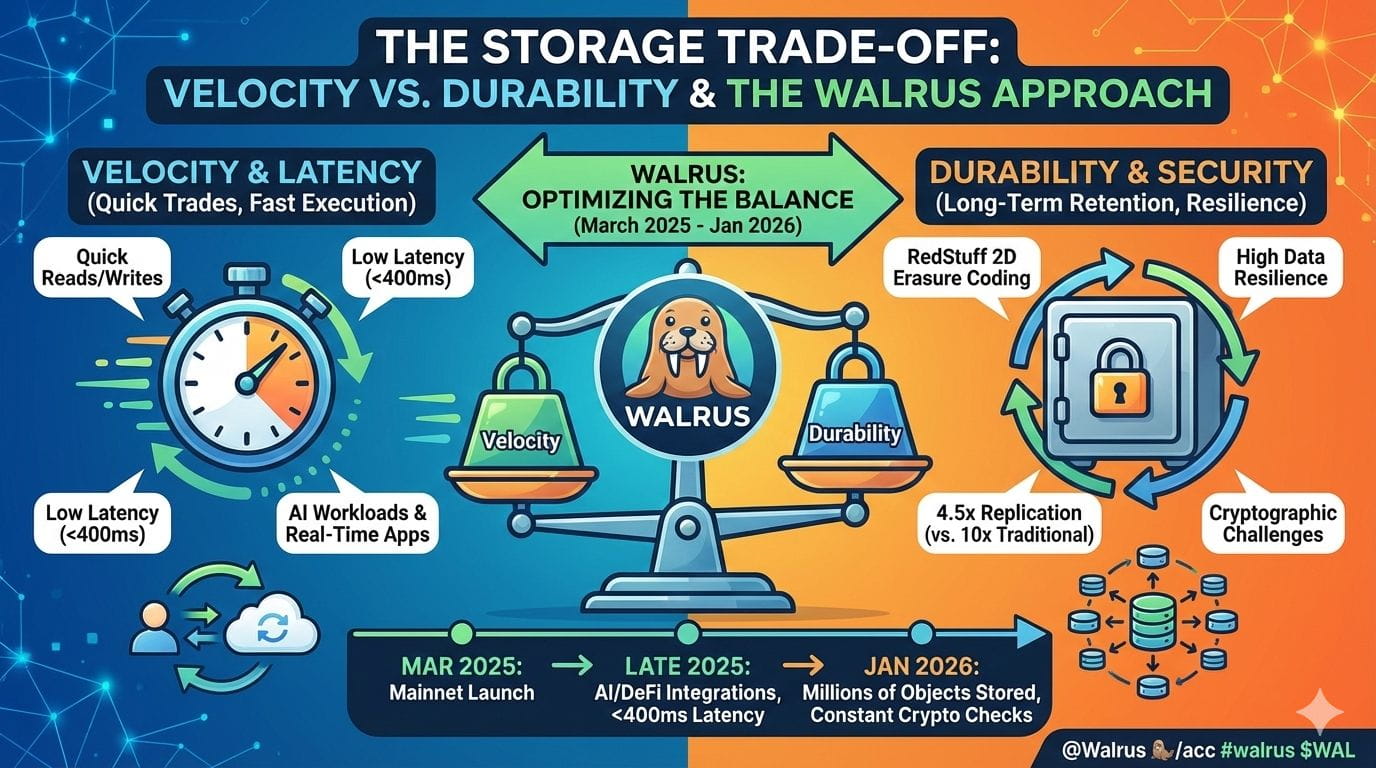
As the code stands now, in January of 2026, Walrus is still in its youth. Storage volume and integration are up, while engineering challenges persist. But the work done over the past ten months proves the age-old trade-off between speed and staying power isn’t necessarily an either-or proposition at all – rather, it becomes a continuum that code makers should be able to dial in.
It's much more important than any given market trend in the short term. Systems that find a balance between those factors are well-suited to last in the end, while those that go too far in either direction often don't last at all. Walrus is an interesting case of how to balance those factors well enough to last, though it's also interesting to see how it's changing to learn what's next in decentralized infrastructure.
