


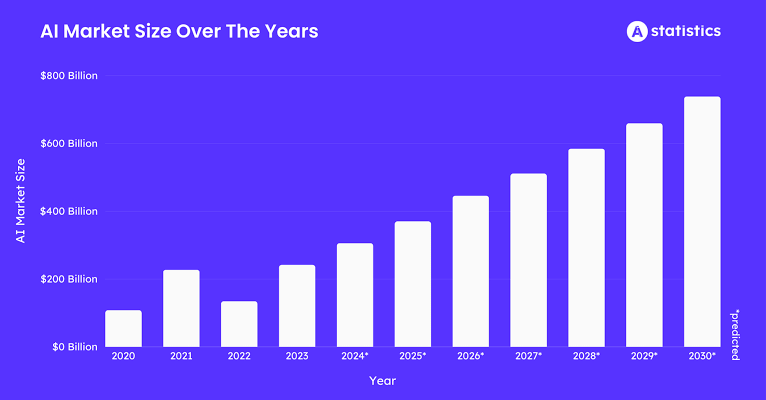
Comme l'a dit un jour le maître Léonard de Vinci, "Apprendre n'épuise jamais l'esprit." Mais à l'ère de l'intelligence artificielle, il semble que l'apprentissage pourrait simplement épuiser l'approvisionnement en puissance de calcul de notre planète. La révolution de l'IA, qui devrait injecter plus de 15,7 trillions de dollars dans l'économie mondiale d'ici 2030, repose fondamentalement sur deux choses : les données et la force brute du calcul. Le problème est que l'échelle des modèles d'IA croît à un rythme effréné, avec le calcul nécessaire pour l'entraînement doublant à peu près tous les cinq mois. Cela a créé un énorme goulet d'étranglement. Une petite poignée de géants du cloud détient les clés du royaume, contrôlant l'approvisionnement en GPU et créant un système coûteux, sous permission et, franchement, un peu fragile pour quelque chose d'aussi important.
C'est là que l'histoire devient intéressante. Nous assistons à un changement de paradigme, une arène émergente appelée formation de modèle d'IA décentralisée (DeAI), qui utilise les idées fondamentales de la blockchain et du Web3 pour contester ce contrôle centralisé.
Regardons les chiffres. Le marché des données d'entraînement en IA devrait atteindre environ 3,5 milliards de dollars d'ici 2025, croissant à un rythme d'environ 25 % chaque année. Toutes ces données ont besoin d'être traitées. Le marché de l'IA Blockchain lui-même devrait valoir près de 681 millions de dollars en 2025, avec une croissance saine de 23 % à 28 % CAGR. Et si nous élargissons la vue d'ensemble, l'ensemble de l'infrastructure physique décentralisée (DePIN), dont DeAI fait partie, devrait dépasser les 32 milliards de dollars en 2025.
Tout cela signifie que la soif de l'IA pour les données et le calcul crée une énorme demande. DePIN et la blockchain interviennent pour fournir l'offre, un réseau mondial, ouvert et économiquement intelligent pour construire l'intelligence. Nous avons déjà vu comment les incitations en tokens peuvent amener les gens à coordonner du matériel physique comme des points d'accès sans fil et des disques de stockage ; maintenant, nous appliquons ce même manuel au processus de production numérique le plus précieux au monde : la création d'intelligence artificielle.
I. La Pile DeAI
L'impulsion pour une IA décentralisée découle d'une mission philosophique profonde visant à construire un écosystème d'IA plus ouvert, résilient et équitable. Il s'agit de favoriser l'innovation et de résister à la concentration de pouvoir que nous constatons aujourd'hui. Les partisans contrastent souvent deux façons d'organiser le monde : un "Taxis", qui est un ordre conçu et contrôlé de manière centrale, contre un "Cosmos", un ordre décentralisé et émergent qui se développe à partir d'interactions autonomes.

Une approche centralisée de l'IA pourrait créer une sorte de "complétion automatique pour la vie", où les systèmes d'IA poussent subtilement les actions humaines et, choix par choix, érodent notre capacité à penser par nous-mêmes. La décentralisation est l'antidote proposé. C'est un cadre où l'IA est un outil pour améliorer l'épanouissement humain, pas pour le diriger. En répartissant le contrôle sur les données, les modèles et le calcul, DeAI vise à remettre le pouvoir entre les mains des utilisateurs, des créateurs et des communautés, s'assurant que l'avenir de l'intelligence est quelque chose que nous partageons, pas quelque chose que quelques entreprises possèdent.
II. Déconstruction de la Pile DeAI
Au cœur de l'affaire, vous pouvez décomposer l'IA en trois éléments de base : données, calcul et algorithmes. Le mouvement DeAI vise à reconstruire chacun de ces piliers sur une fondation décentralisée.
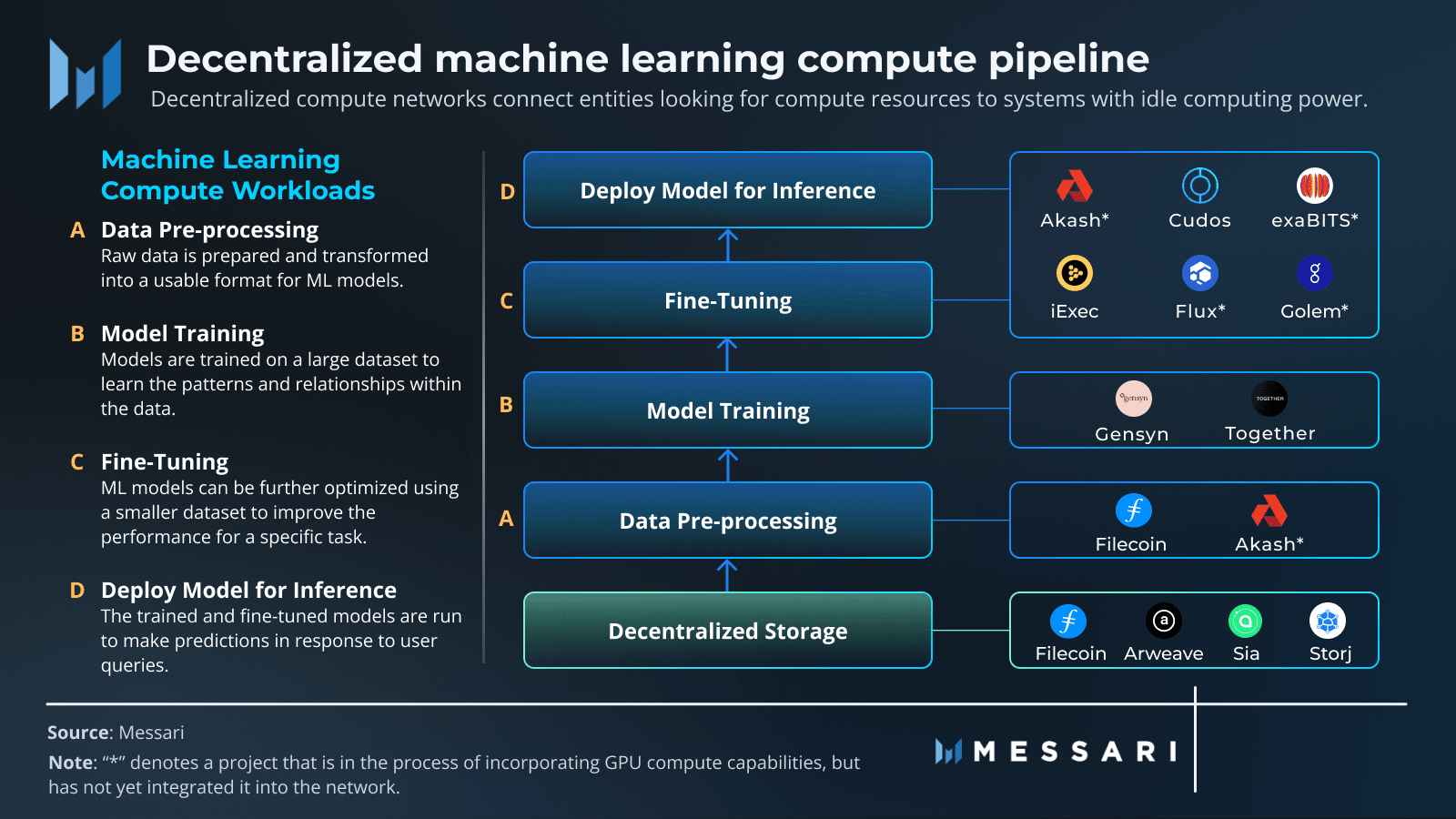
❍ Pilier 1 : Données Décentralisées
Le carburant de toute IA puissante est un ensemble de données massif et varié. Dans l'ancien modèle, ces données sont enfermées dans des systèmes centralisés comme Amazon Web Services ou Google Cloud. Cela crée des points de défaillance uniques, des risques de censure et rend difficile l'accès pour les nouveaux venus. Les réseaux de stockage décentralisés offrent une alternative, proposant un foyer permanent, résistant à la censure et vérifiable pour les données d'entraînement en IA.
Des projets comme Filecoin et Arweave sont des acteurs clés ici. Filecoin utilise un réseau mondial de fournisseurs de stockage, les incitant avec des tokens à stocker des données de manière fiable. Il utilise des preuves cryptographiques astucieuses comme la Preuve de Réplication et la Preuve d'Espace-Temps pour s'assurer que les données sont sûres et disponibles. Arweave a une approche différente : vous payez une fois, et vos données sont stockées pour toujours sur un "permaweb" immuable. En transformant les données en un bien public, ces réseaux créent une base solide et transparente pour le développement de l'IA, garantissant que les ensembles de données utilisés pour l'entraînement sont sécurisés et ouverts à tous.
❍ Pilier 2 : Calcul Décentralisé
Le plus grand obstacle à l'IA en ce moment est d'accéder à des calculs haute performance, en particulier des GPU. DeAI s'attaque à cela de front en créant des protocoles capables de rassembler et de coordonner la puissance de calcul du monde entier, des GPU de qualité grand public dans les foyers aux machines inactives dans les centres de données. Cela transforme la puissance de calcul d'une ressource rare que vous louez à quelques gardiens en une marchandise liquide et mondiale. Des projets comme Prime Intellect, Gensyn et Nous Research construisent les marchés pour cette nouvelle économie de calcul.
❍ Pilier 3 : Algorithmes et Modèles Décentralisés
Obtenir les données et le calcul est une chose. Le véritable travail consiste à coordonner le processus d'entraînement, à s'assurer que le travail est effectué correctement et à amener tout le monde à collaborer dans un environnement où vous ne pouvez pas nécessairement faire confiance à qui que ce soit. C'est là qu'un mélange de technologies Web3 se réunit pour former le cœur opérationnel de DeAI.
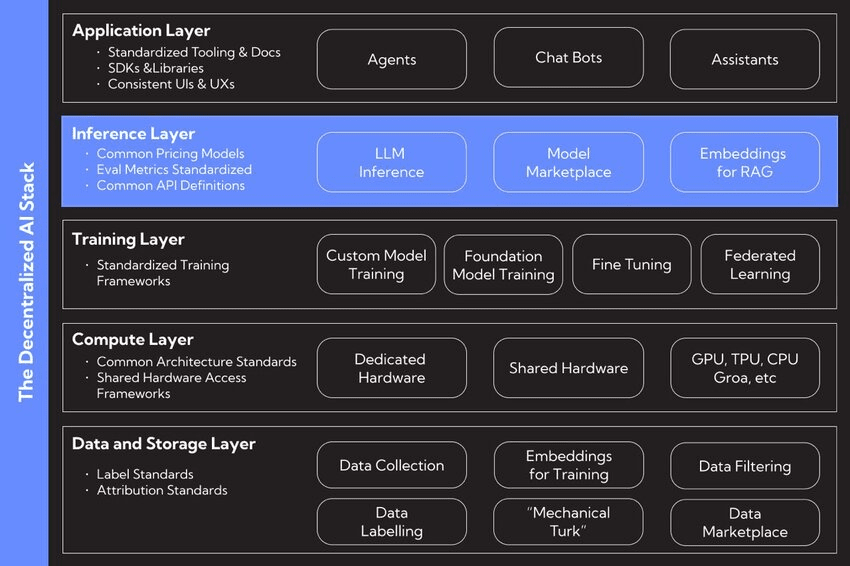
Blockchain et Contrats Intelligents : Pensez à cela comme le manuel de règles inaltérable et transparent. Les blockchains fournissent un grand livre partagé pour suivre qui a fait quoi, et les contrats intelligents appliquent automatiquement les règles et distribuent les récompenses, donc vous n'avez pas besoin d'un intermédiaire.
Apprentissage Fédéré : C'est une technique clé de préservation de la vie privée. Elle permet aux modèles d'IA de s'entraîner sur des données éparpillées à travers différents emplacements sans que les données aient jamais besoin de bouger. Seules les mises à jour du modèle sont partagées, pas vos informations personnelles, ce qui garde les données des utilisateurs privées et sécurisées.
Tokenomics : C'est le moteur économique. Les tokens créent une mini-économie qui récompense les gens pour avoir contribué des choses précieuses, que ce soit des données, de la puissance de calcul ou des améliorations aux modèles d'IA. Cela aligne les incitations de chacun vers l'objectif commun de construire une meilleure IA.
La beauté de cette pile réside dans sa modularité. Un développeur d'IA pourrait extraire un ensemble de données d'Arweave, utiliser le réseau de Gensyn pour une formation vérifiable, puis déployer le modèle fini sur un sous-réseau spécialisé de Bittensor pour gagner de l'argent. Cette interopérabilité transforme les éléments du développement de l'IA en "legos d'intelligence", suscitant un écosystème beaucoup plus dynamique et innovant que n'importe quelle plateforme unique et fermée ne pourrait jamais l'être.
III. Comment Fonctionne la Formation de Modèle Décentralisée
Imaginez que l'objectif est de créer un chef cuisinier d'IA de classe mondiale. L'ancienne façon centralisée consiste à enfermer un apprenti dans une seule cuisine secrète (comme celle de Google) avec un énorme livre de recettes secret. La façon décentralisée, utilisant une technique appelée Apprentissage Fédéré, est plus comme diriger un club de cuisine mondial.
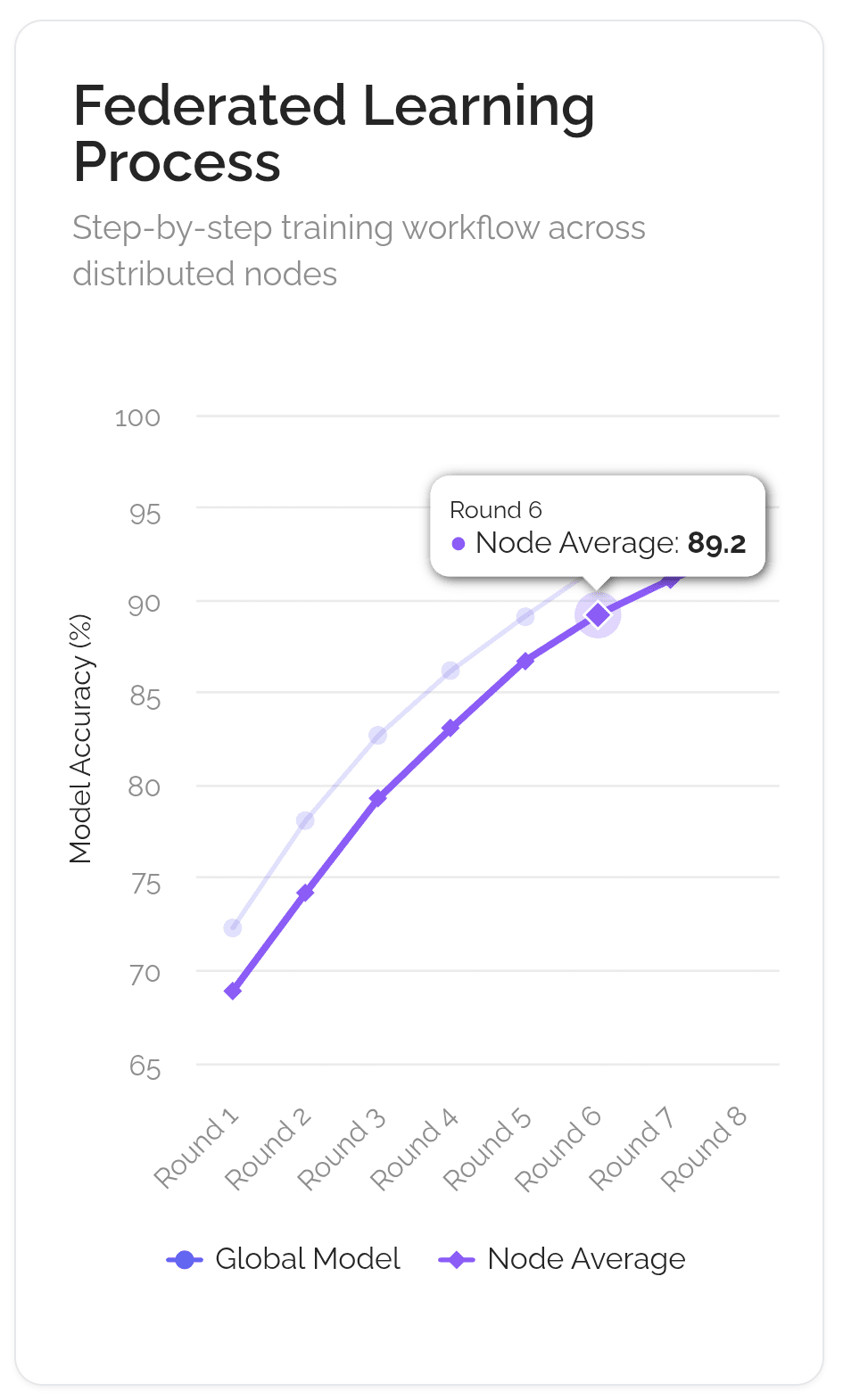
La recette maîtresse (le "modèle global") est envoyée à des milliers de chefs locaux à travers le monde. Chaque chef essaie la recette dans sa propre cuisine, utilisant ses ingrédients et méthodes locaux uniques ("données locales"). Ils ne partagent pas leurs ingrédients secrets ; ils font juste des notes sur la façon d'améliorer la recette ("mises à jour du modèle"). Ces notes sont renvoyées au siège du club. Le club combine ensuite toutes les notes pour créer une nouvelle recette maîtresse améliorée, qui est envoyée pour le prochain tour. Le tout est géré par une charte de club transparente et automatisée (la "blockchain"), qui s'assure que chaque chef qui aide obtient du crédit et est récompensé équitablement ("récompenses en tokens").
❍ Mécanismes Clés
Cette analogie correspond assez étroitement au flux de travail technique qui permet ce type de formation collaborative. C'est une chose complexe, mais cela se résume à quelques mécanismes clés qui rendent tout cela possible.
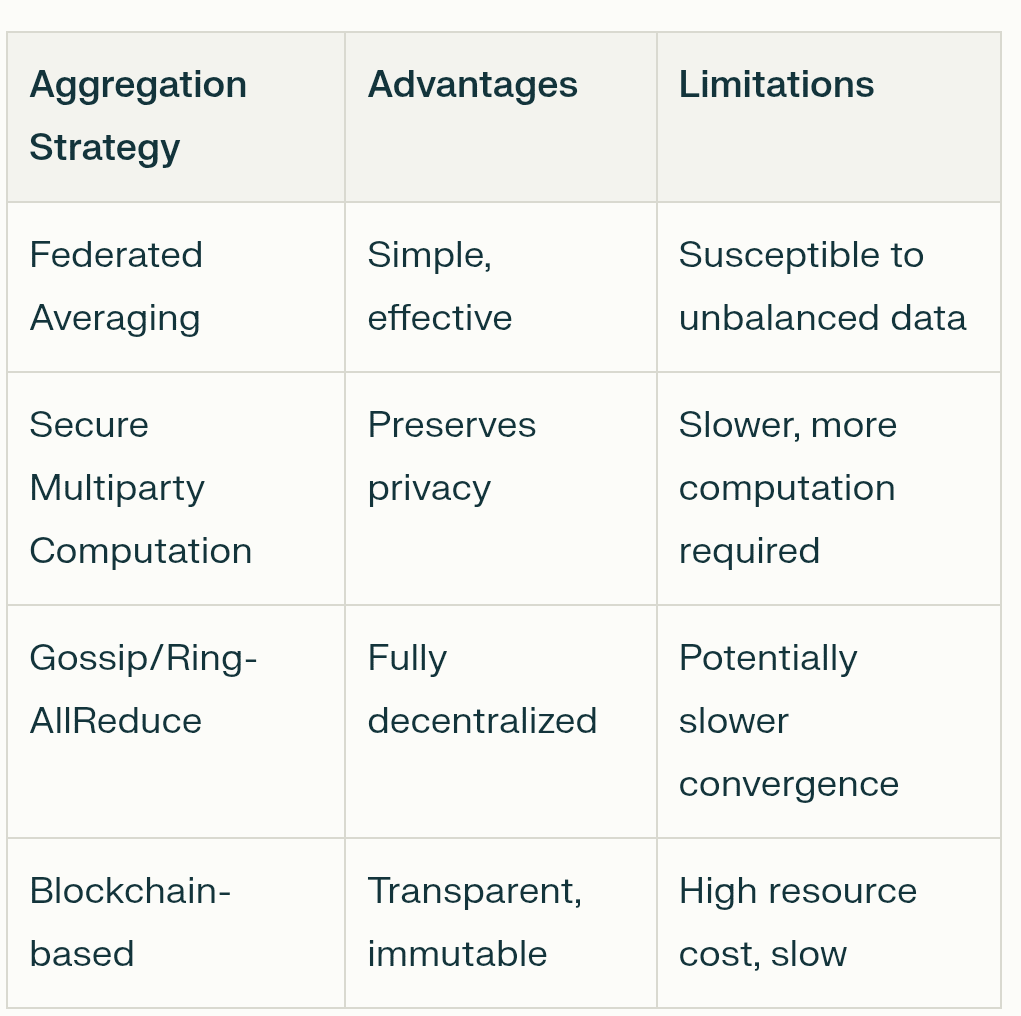
Parallélisme de Données Distribuées : C'est le point de départ. Au lieu qu'un énorme ordinateur traite un ensemble de données massif, l'ensemble de données est divisé en morceaux plus petits et distribué à travers de nombreux ordinateurs différents (nœuds) dans le réseau. Chacun de ces nœuds reçoit une copie complète du modèle d'IA avec lequel travailler. Cela permet une énorme quantité de traitement parallèle, accélérant considérablement les choses. Chaque nœud entraîne sa réplique de modèle sur sa tranche unique de données.
Algorithmes à Faible Communication : Un défi majeur est de garder toutes ces répliques de modèle synchronisées sans obstruer Internet. Si chaque nœud devait constamment diffuser chaque petite mise à jour à tous les autres nœuds, cela serait incroyablement lent et inefficace. C'est là que les algorithmes à faible communication entrent en jeu. Des techniques comme DiLoCo (Communication Faible Distribuée) permettent aux nœuds d'effectuer des centaines d'étapes de formation locales de leur côté avant d'avoir besoin de synchroniser leurs progrès avec le réseau plus large. Des méthodes plus récentes comme NoLoCo (Communication Faible sans réduction) vont encore plus loin, remplaçant d'énormes synchronisations de groupe par une méthode de "ragot" où les nœuds moyennent périodiquement leurs mises à jour avec un seul pair choisi au hasard.
Compression : Pour réduire davantage le fardeau de communication, les réseaux utilisent des techniques de compression. C'est comme zipper un fichier avant de l'envoyer par e-mail. Les mises à jour de modèle, qui ne sont que de grandes listes de nombres, peuvent être compressées pour les rendre plus petites et plus rapides à envoyer. La quantification, par exemple, réduit la précision de ces nombres (par exemple, d'un flottant en 32 bits à un entier en 8 bits), ce qui peut réduire la taille des données par un facteur de quatre ou plus avec un impact minimal sur l'exactitude. L'éclaircissement est une autre méthode qui supprime les connexions non importantes au sein du modèle, le rendant plus petit et plus efficace.
Incitation et Validation : Dans un réseau sans confiance, vous devez vous assurer que tout le monde joue équitablement et est récompensé pour son travail. C'est le travail de la blockchain et de son économie de tokens. Les contrats intelligents agissent comme un séquestre automatisé, détenant et distribuant des récompenses en tokens aux participants qui contribuent des calculs ou des données utiles. Pour prévenir la tricherie, les réseaux utilisent des mécanismes de validation. Cela peut impliquer que des validateurs exécutent de manière aléatoire une petite partie du calcul d'un nœud pour vérifier son exactitude ou utilisent des preuves cryptographiques pour garantir l'intégrité des résultats. Cela crée un système de "Preuve d'Intelligence" où les contributions précieuses sont vérifiables récompensées.
Tolérance aux Pannes : Les réseaux décentralisés sont composés d'ordinateurs peu fiables, distribués globalement. Les nœuds peuvent se déconnecter à tout moment. Le système doit être capable de gérer cela sans que l'ensemble du processus de formation ne plante. C'est là que la tolérance aux pannes entre en jeu. Des cadres comme l'ElasticDeviceMesh de Prime Intellect permettent aux nœuds de rejoindre ou de quitter dynamiquement une session de formation sans provoquer une défaillance à l'échelle du système. Des techniques telles que la vérification asynchrone des points de contrôle sauvegardent régulièrement les progrès du modèle, de sorte que si un nœud échoue, le réseau peut rapidement récupérer l'état enregistré le plus récent au lieu de repartir de zéro.
Ce flux de travail continu et itératif change fondamentalement ce qu'est un modèle d'IA. Ce n'est plus un objet statique créé et possédé par une seule entreprise. Cela devient un système vivant, un état de consensus qui est constamment affiné par un collectif mondial. Le modèle n'est pas un produit ; c'est un protocole, maintenu et sécurisé collectivement par son réseau.
IV. Protocoles de Formation Décentralisés
Le cadre théorique de l'IA décentralisée est maintenant mis en œuvre par un nombre croissant de projets innovants, chacun ayant une stratégie et une approche technique uniques. Ces protocoles créent une arène compétitive où différents modèles de collaboration, de vérification et d'incitation sont testés à grande échelle.
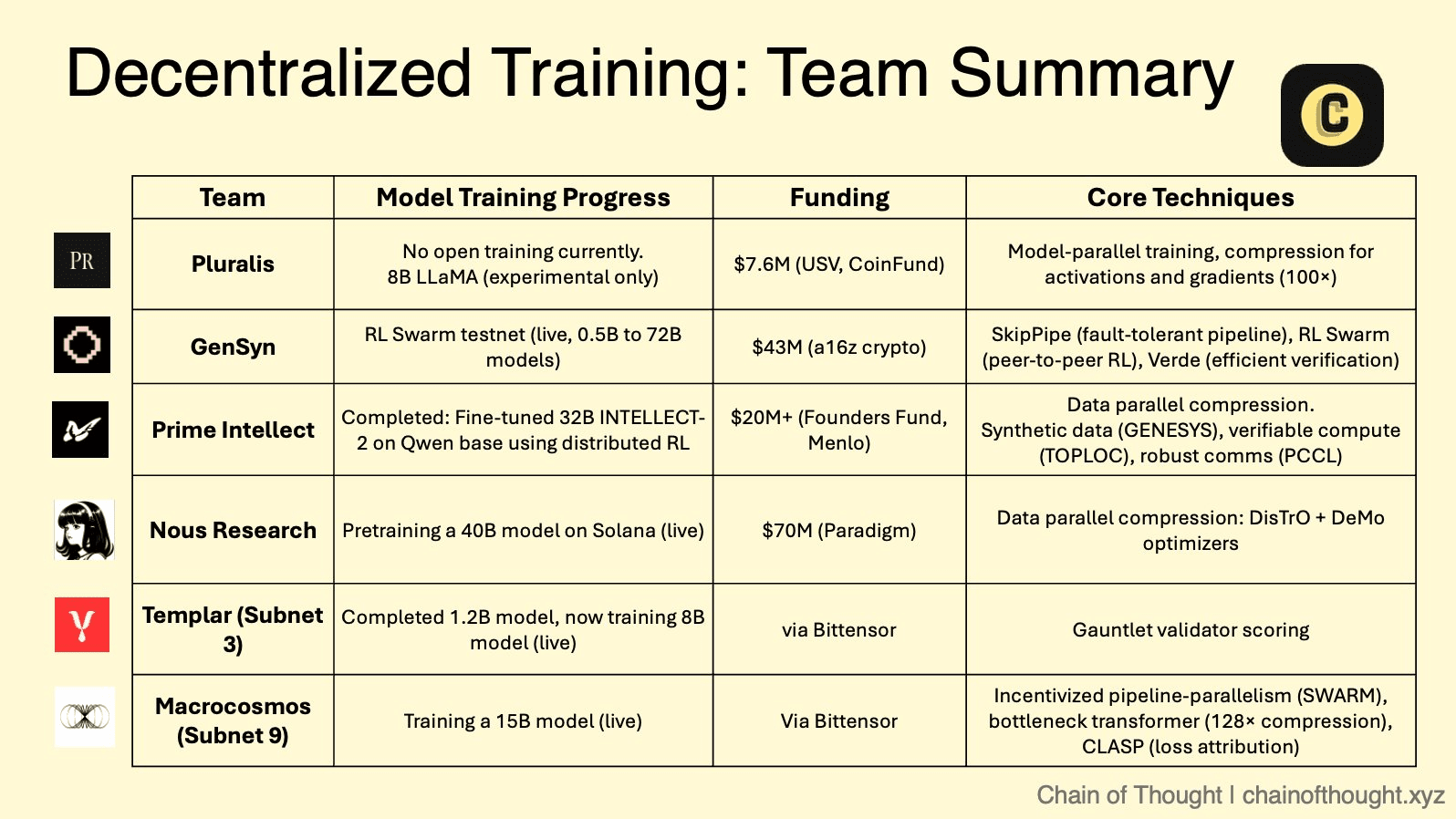
❍ Le Marché Modulaire : Écosystème de Sous-réseaux de Bittensor
Bittensor fonctionne comme un "internet de marchandises numériques", un méta-protocole hébergeant de nombreux "sous-réseaux" spécialisés. Chaque sous-réseau est un marché compétitif, motivé par des incitations, pour une tâche spécifique d'IA, allant de la génération de texte au repliement de protéines. Au sein de cet écosystème, deux sous-réseaux sont particulièrement pertinents pour la formation décentralisée.

Templar (Sous-réseau 3) est axé sur la création d'une plateforme sans autorisation et antifragile pour le pré-entraînement décentralisé. Elle incarne une approche pure et compétitive où les mineurs forment des modèles (actuellement jusqu'à 8 milliards de paramètres, avec une feuille de route vers 70 milliards) et sont récompensés en fonction de leur performance, entraînant une course incessante pour produire la meilleure intelligence possible.

Macrocosmos (Sous-réseau 9) représente une évolution significative avec son IOTA (Architecture de Formation Orchestrée Incitative). IOTA va au-delà de la compétition isolée vers une collaboration orchestrée. Il emploie une architecture en hub et en spoke où un Orchestrateur coordonne la formation parallèle de données et de pipelines à travers un réseau de mineurs. Au lieu que chaque mineur entraîne un modèle entier, ils se voient attribuer des couches spécifiques d'un modèle beaucoup plus grand. Cette division du travail permet à l'ensemble de former des modèles à une échelle bien au-delà de la capacité de tout participant unique. Les validateurs effectuent des "audits d'ombre" pour vérifier le travail, et un système d'incitation granulaire récompense équitablement les contributions, favorisant un environnement collaboratif mais responsable.
❍ La Couche de Calcul Vérifiable : Le Réseau sans Confiance de Gensyn
L'objectif principal de Gensyn est de résoudre l'un des problèmes les plus difficiles dans le domaine : l'apprentissage automatique vérifiable. Son protocole, construit comme un Rollup Ethereum L2 personnalisé, est conçu pour fournir une preuve cryptographique de l'exactitude des calculs d'apprentissage profond effectués sur des nœuds non fiables.
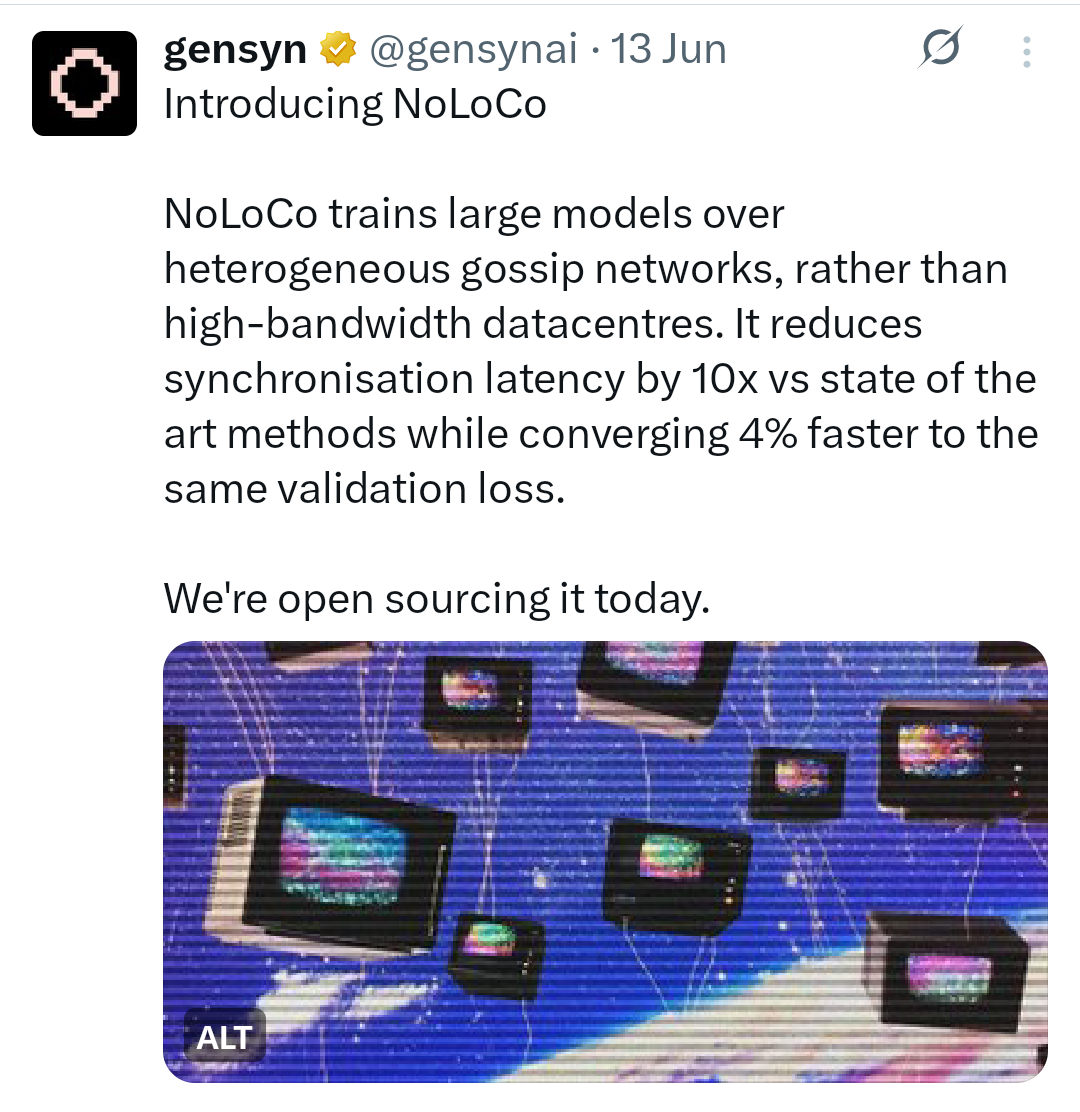
Une innovation clé des recherches de Gensyn est NoLoCo (Communication Faible sans réduction), une méthode d'optimisation novatrice pour l'entraînement distribué. Les méthodes traditionnelles nécessitent une étape de synchronisation globale "all-reduce", qui crée un goulet d'étranglement, surtout sur les réseaux à faible bande passante. NoLoCo élimine complètement cette étape. Au lieu de cela, il utilise un protocole basé sur le ragot où les nœuds moyennent périodiquement leurs poids de modèle avec un seul pair sélectionné au hasard. Cela, combiné à un optimiseur de momentum modifié de Nesterov et à un routage aléatoire des activations, permet au réseau de converger efficacement sans synchronisation globale, le rendant idéal pour l'entraînement sur du matériel hétérogène connecté à Internet. L'application testnet RL Swarm de Gensyn démontre cette pile en action, permettant un apprentissage par renforcement collaboratif dans un cadre décentralisé.
❍ L'Aggrégateur de Calcul Global : Le Cadre Ouvert de Prime Intellect
Prime Intellect construit un protocole pair-à-pair pour agréger des ressources de calcul globales en un marché unifié, créant ainsi efficacement un "Airbnb pour le calcul". Leur cadre PRIME est conçu pour une formation tolérante aux pannes et de haute performance sur un réseau de travailleurs peu fiables et distribués globalement.
Le cadre est construit sur une version adaptée de l'algorithme DiLoCo (Communication Faible Distribuée), qui permet aux nœuds d'effectuer de nombreuses étapes de formation locales avant de nécessiter une synchronisation globale moins fréquente. Prime Intellect a complété cela par des percées d'ingénierie significatives. L'ElasticDeviceMesh permet aux nœuds de rejoindre ou de quitter dynamiquement une session de formation sans faire planter le système. La vérification asynchrone des points de contrôle sur des systèmes de fichiers soutenus par la RAM minimise les temps d'arrêt. Enfin, ils ont développé des noyaux de réduction all-reduce personnalisés en int8, qui réduisent la charge de communication pendant la synchronisation par un facteur de quatre, abaissant considérablement les exigences de bande passante. Cette pile technique robuste leur a permis d'orchestrer avec succès la première formation décentralisée au monde d'un modèle de 10 milliards de paramètres, INTELLECT-1.
❍ Le Collectif Open-Source : L'Approche Axée sur la Communauté de Nous Research
Nous Research fonctionne comme un collectif de recherche en IA décentralisé avec un fort ethos open-source, construisant son infrastructure sur la blockchain Solana pour son haut débit et ses faibles coûts de transaction.
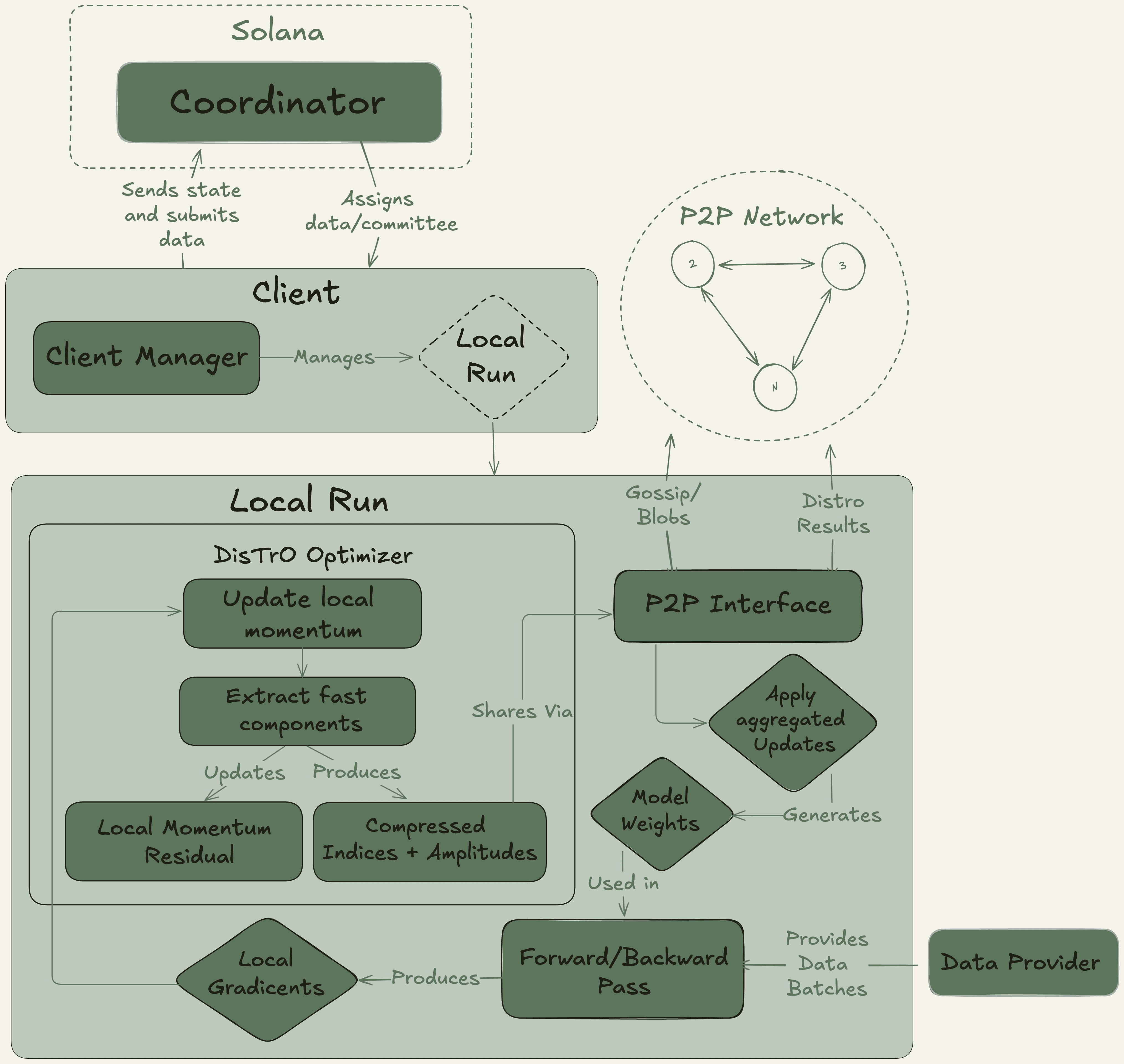
Leur plateforme phare, Nous Psyche, est un réseau de formation décentralisé alimenté par deux technologies clés : DisTrO (Formation Distribuée sur Internet) et son algorithme d'optimisation sous-jacent, DeMo (Optimisation de Momentum Découplée). Développées en collaboration avec un co-fondateur d'OpenAI, ces technologies sont conçues pour une efficacité de bande passante extrême, revendiquant une réduction de 1 000x à 10 000x par rapport aux méthodes conventionnelles. Cette avancée rend possible la participation à l'entraînement de modèles à grande échelle en utilisant des GPU de qualité grand public et des connexions Internet standard, démocratisant radicalement l'accès au développement de l'IA.
❍ L'Avenir Pluraliste : Apprentissage de Protocole de Pluralis AI
Pluralis AI s'attaque à un défi de niveau supérieur : non seulement comment former des modèles, mais comment les aligner avec des valeurs humaines diverses et pluralistes de manière à préserver la vie privée.

Leur cadre PluralLLM introduit une approche basée sur l'apprentissage fédéré pour l'alignement des préférences, une tâche traditionnellement gérée par des méthodes centralisées comme l'apprentissage par renforcement à partir des retours humains (RLHF). Avec PluralLLM, différents groupes d'utilisateurs peuvent collaborativement entraîner un modèle de prédiction des préférences sans jamais partager leurs données de préférences sensibles sous-jacentes. Le cadre utilise la moyennage fédéré pour agréger ces mises à jour de préférences, atteignant une convergence plus rapide et de meilleurs scores d'alignement que les méthodes centralisées tout en préservant à la fois la vie privée et l'équité.
Leur concept global d'Apprentissage de Protocole garantit en outre qu'aucun participant unique ne peut obtenir le modèle complet, résolvant des problèmes critiques de propriété intellectuelle et de confiance inhérents au développement collaboratif de l'IA.
Bien que l'arène d'entraînement d'IA décentralisée possède un avenir prometteur, son chemin vers une adoption généralisée est parsemé de défis significatifs. La complexité technique de la gestion et de la synchronisation des calculs à travers des milliers de nœuds peu fiables reste un obstacle d'ingénierie redoutable. De plus, l'absence de cadres juridiques et réglementaires clairs pour les systèmes autonomes décentralisés et la propriété intellectuelle collectivement détenue crée une incertitude pour les développeurs et les investisseurs.
En fin de compte, pour que ces réseaux atteignent une viabilité à long terme, ils doivent évoluer au-delà de la spéculation et attirer de véritables clients payants pour leurs services de calcul, générant ainsi des revenus durables et pilotés par le protocole. Et nous croyons qu'ils franchiront finalement la route même avant notre spéculation.