Le point de départ de cet article est simple : expliquer ma compréhension de la méthodologie du Pyth Network de manière claire et réutilisable ; tout en le replaçant dans le contexte plus large de l'industrie des données de marché et des applications institutionnelles. Au cours des dernières années, j'ai suivi l'évolution des oracles et la commercialisation des données, formant progressivement un jugement simple mais utile : ce qui est vraiment important dans la chaîne d'approvisionnement des données, ce n'est pas le « décentralisé » décoratif, mais la production fiable et la livraison vérifiable. Lorsque l'offre et la demande peuvent se rencontrer directement sur la chaîne, de manière vérifiable, la valeur est plus facilement capturée de manière stable.
Pour moi, Pyth n'est pas "un autre composant de prix", mais une chaîne de production de données de prix qui va de la production à la distribution multi-chaînes. Le modèle traditionnel ressemble davantage à un "messager d'informations", relayé par des agrégateurs, des scrapeurs et des nœuds intermédiaires ; les retards, l'incertitude et l'irrévocabilité deviennent souvent un terreau pour les risques systémiques. Pyth adopte un modèle de données de première main, permettant aux bourses, aux teneurs de marché et aux fournisseurs de données professionnels de publier directement sur la chaîne avec des signatures ; puis, via Pythnet, agréger, vérifier et calculer les intervalles de confiance, et distribuer aux applications comme les prêts, les options, les actifs synthétiques et les indices sous forme d'abonnement à la demande. Je résume ce chemin par : ne pas agir comme un porte-voix, mais construire une "chaîne de production de prix vérifiable".
I. Plafond de secteur et besoins réels.
La valeur de l'industrie des données de marché provient des deux extrémités : d'une part, la qualité et la rapidité de la source, d'autre part, la disponibilité et la sensibilité aux coûts des consommateurs. Dans la finance traditionnelle, la distribution de données et les prix en temps réel sont des catégories payantes stables à long terme ; migrer vers le monde crypto, la demande n'a pas changé, mais les exigences en matière de "vérifiabilité" et de "programmabilité" sont plus élevées. Les stratégies de prêts et de liquidations nécessitent des mises à jour à faible latence et stables ; la tarification des options dépend d'une estimation raisonnable de la volatilité ; les actifs synthétiques exigent une cohérence de tarification dans un environnement de forte volatilité. Ces besoins fondamentaux ont généré une demande continue pour des prix de haute qualité, et c'est ma motivation fondamentale pour continuer à investir dans la recherche et la création. La vision de Pyth, en partant de DeFi, est de se diriger vers des services de données de marché plus vastes ; je crois que c'est un chemin "difficile mais correct".
II. Décomposition opérationnelle des produits et de l'architecture.
J'ai l'habitude de décomposer tout produit de données en cinq étapes : production brute, publication fiable, agrégation et vérification, distribution et règlement, retour et optimisation. Dans Pyth, la production brute provient des bourses de première ligne, des teneurs de marché et des fournisseurs de données professionnels ; ils se connectent à la chaîne en tant qu'"éditeurs", chaque message portant une signature source, ce qui est une condition préalable à la traçabilité. La publication fiable repose sur Pythnet, qui effectue le dé-duplication, le nettoyage, l'alignement des horodatages et calcule les intervalles de confiance à partir de données sources multiples. Après agrégation et vérification, les mises à jour de prix sont distribuées aux applications sur différentes chaînes via des canaux inter-chaînes ; le mécanisme "d'abonnement et de demande" permet à l'utilisateur de décider de la fréquence de déclenchement selon ses préférences de coût et de rapidité, réduisant ainsi les transactions inutiles et le bruit sur la chaîne. Ce design place les indicateurs "vitesse" et "robustesse", qui semblent opposés, sous un même objectif d'ingénierie. D'après mon expérience pratique, tant que les développeurs clarifient la structure des champs des objets de prix, la précision temporelle et l'intervalle de confiance, ils peuvent intégrer sans heurts.
Le schéma structurel ci-dessous montre les points clés et les points vérifiables des données de la source à l'application, facilitant la communication des détails de mise en œuvre et des limites avec l'équipe.
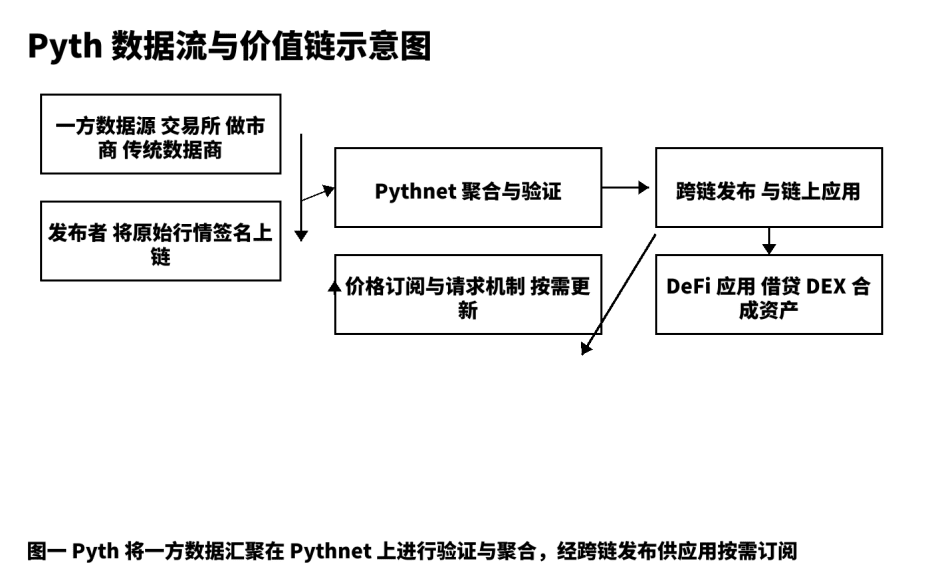
III. Comparaison en cinq dimensions et choix de stratégie.
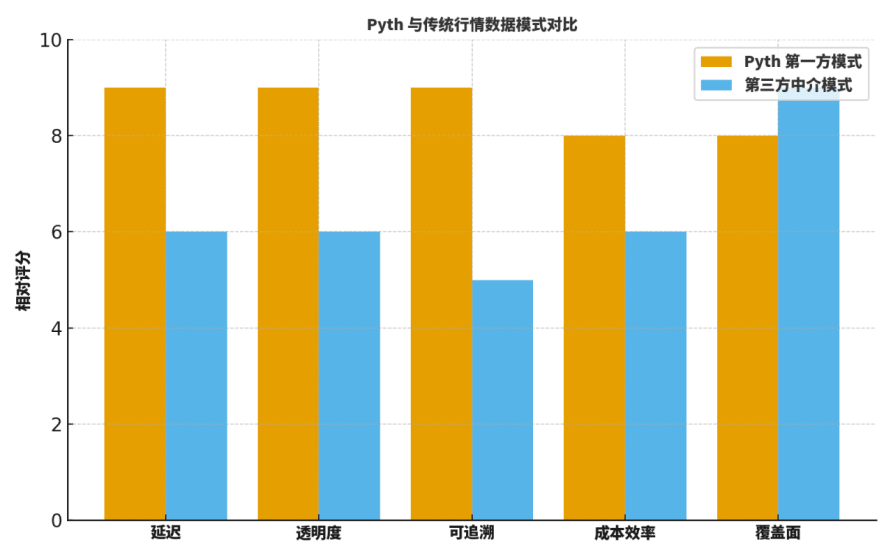
Beaucoup de camarades se demandent : quelle est la différence entre Pyth et les "oracles d'intermédiation" traditionnels ou les anciens fournisseurs de données ? Je compare généralement sur cinq dimensions : latence, transparence, traçabilité, efficacité des coûts, couverture.
D'une part, en termes de latence, l'envoi direct de première main réduit nettement les étapes intermédiaires, se traduisant par des mises à jour plus rapides ;
D'autre part, en termes de transparence et de traçabilité, la signature source et le processus d'agrégation vérifiable offrent une visibilité granulaire ;
Troisièmement, en termes d'efficacité des coûts, cela supprime de nombreux coûts liés à la collecte externe et à la retransmission multi-niveaux ;
Quatrièmement, en termes de couverture, les géants traditionnels ont encore un avantage en matière de distribution historique et régionale ;
Cinquièmement, en termes de collaboration en ingénierie, l'abonnement "à la demande" de Pyth est propice à un couplage avec les paramètres de risque et le système d'alerte.
Ainsi, la stratégie n'est pas "one-size-fits-all", mais consiste à privilégier Pyth dans des scénarios clés : prêts, liquidation, options, actifs synthétiques et autres secteurs, c'est ce que je valorise le plus dans le choix.
Pour aider les lecteurs à établir une intuition, je fournis un graphique de "notation relative" ; ce n'est pas une conclusion absolue, mais c'est très adapté comme point de départ pour la discussion et le modèle de révision.
IV. La "deuxième phase" dans la feuille de route : abonnements de données de niveau institutionnel.
Dans la création de contenu et la pratique de conseil, je divise la route de Pyth en deux phases interconnectées :
Première phase, établir des normes de prix dans des scénarios à grande vitesse DeFi, l'essentiel étant la qualité et la vitesse ;
Deuxième phase, se tourner vers la productisation des abonnements de données de niveau institutionnel, y compris : les accords de niveau de service (SLA) pour les niveaux de latence, les journaux d'audit, les systèmes d'étiquetage des anomalies axés sur la gestion des risques, la facturation modulaire et les interfaces de réconciliation, etc.
Cette étape étend la capacité d'ingénierie en capacité de service : elle relie les signaux de prix aux capacités organisationnelles telles que la régulation, la conformité et la gestion des risques ; elle relie également les revenus durables à la gouvernance du réseau. Je m'inquiète particulièrement de savoir si un modèle de service répétable peut fonctionner, par exemple :
(1) Fournir des plans d'abonnement avec plusieurs niveaux de latence et de fréquence de mise à jour ;
(2) La source, la signature, l'horodatage et la liste des éditeurs participant à chaque mise à jour de prix peuvent être exportés et laissés en trace ;
(3) Les étiquettes d'anomalies axées sur la gestion des risques peuvent être rejouées, révisées et liées aux événements de risque.
Ces détails déterminent si l'institution est prête à migrer et jusqu'à quel point elle est prête à payer.
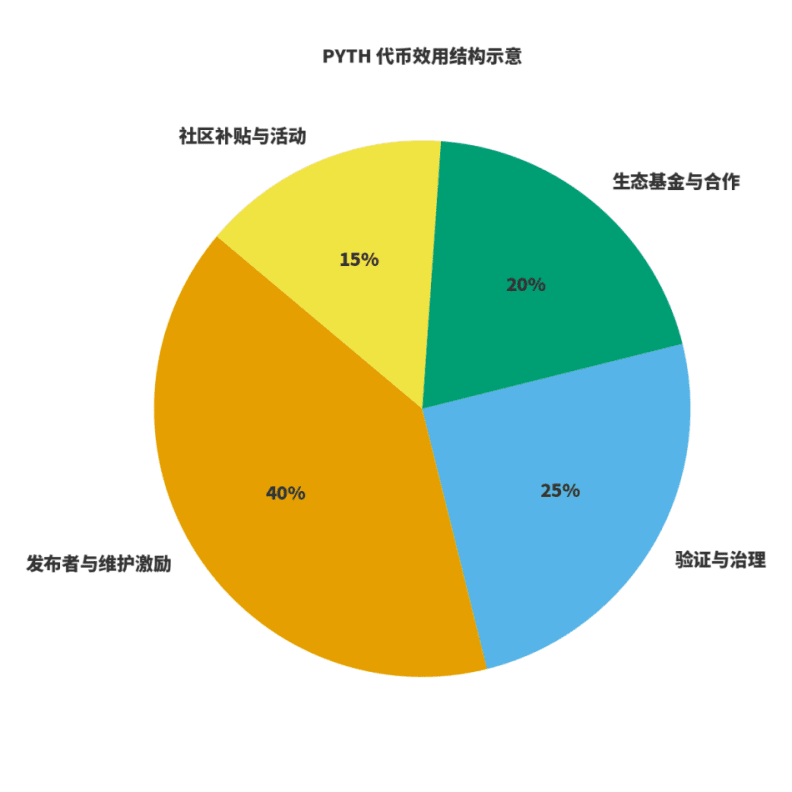
V. Utilité des jetons et boucle économique.
Pour juger de la santé d'un réseau, il faut examiner deux choses : d'une part, les revenus sont-ils liés à la création de valeur ? D'autre part, les incitations sont-elles liées à la qualité à long terme ? Pour $PYTH , je l'interprète comme un triple rôle : le carburant pour la production et la maintenance des données ; le poids pour la gouvernance et la vérification ; le levier pour l'expansion de l'écosystème. Les éditeurs et les mainteneurs participent par le biais d'incitations en jetons prévisibles ; les revenus du réseau proviennent des abonnements et de l'utilisation des données, qui sont répartis par la gouvernance entre maintenance, incitations et expansion de l'écosystème. J'ai dessiné un schéma d'"allocation d'utilité", les proportions spécifiques étant ajustées au fur et à mesure de l'évolution de la gouvernance, mais le principe reste le même : la publication et la maintenance ont un poids plus important ; la gouvernance et la vérification garantissent la stabilité ; l'écosystème et la communauté sont responsables de l'extension et de la rupture des cercles.
VI. Liste de mise en œuvre axée sur les institutions.
En combinant mon expérience de liaison passée, j'ai élaboré une liste directement exploitable :
Premièrement, clarifier le domaine des données et les frontières des services : quels sont les prix de base, quels sont les services à valeur ajoutée ;
Deuxièmement, aligner les accords de niveau de service : y compris les délais de mise à jour, la stabilité, le traitement des anomalies, la stratégie d'alerte et le plan de continuité ;
Troisièmement, fournir des pipelines de journaux vérifiables : enregistrer la source de chaque mise à jour de prix, les changements d'intervalle de confiance et les étiquettes d'anomalies ;
Quatrièmement, intégrer les cadres internes de gestion des risques et de backtesting : connecter le flux de prix aux systèmes de replay, tester la stabilité des stratégies sous différents seuils et fenêtres ;
Cinquièmement, normaliser la facturation et la réconciliation : les institutions se soucient davantage des délais de facturation prévisibles et des détails de réconciliation clairs.
Dans cette liste, l'avantage évident de Pyth est la vérifiabilité de "source à agrégation", ce qui peut considérablement réduire le cycle d'évaluation de la conformité et de la gestion des risques.
VII. Carte des risques et conception antifragile.
Je divise les risques en trois catégories : publication d'anomalies à la source, synchronisation inter-chaînes anormale, amplification des retards dans des conditions de marché extrêmes. Les mesures d'atténuation correspondantes doivent être "institutionnalisées" dans l'ingénierie. Mes pratiques courantes incluent : abonnements multiples avec vérification des seuils ; réduction automatique de l'effet de levier liée à l'intervalle de confiance ; protection contre le glissement et le temps pondéré sur le côté des contrats de trading ; ainsi que des exercices de marché extrêmes par trimestre, accompagnés d'un script de replay unifié et d'un modèle de révision. Ces pratiques d'ingénierie disciplinées, combinées aux journaux vérifiables de Pyth, peuvent considérablement améliorer la capacité de résilience du système.
VIII. Suggestions narratives pour les créateurs de contenu et les développeurs.
J'ai toujours souligné : la valeur du créateur est de traduire la valeur complexe de l'ingénierie dans un langage que les lecteurs et les utilisateurs peuvent "comprendre et utiliser". Si je devais parler de Pyth, je suggérerais de commencer par "le changement de paradigme", plutôt que de rester dans "la lutte des oracles". Parler de la façon dont il aligne l'offre et la demande de manière vérifiable sur la chaîne ; parler de la façon dont il réduit le risque de queue grâce à des intervalles de confiance et à des processus d'agrégation visualisés ; parler de la façon dont il connecte la capacité de service et la boucle commerciale via des abonnements de niveau institutionnel. Cela est plus convaincant que de simplement énumérer des indicateurs.
IX. Les indicateurs que je suivrai au cours de l'année prochaine.
Premièrement, la largeur et la profondeur de l'accès à l'écosystème : couverture des quatre catégories de projets de tête : prêts, actifs synthétiques, options, indices ;
Deuxièmement, l'avancement de la productisation des abonnements institutionnels : les niveaux de latence, les accords de niveau de service, les journaux d'audit sont-ils itérés à temps ;
Troisièmement, la transparence des revenus et de leur répartition : y a-t-il un cadre de données vérifiables pouvant être rendu public ;
Quatrièmement, les progrès de la conformité dans différentes juridictions : y compris la conformité à l'exportation de données et la conformité aux services financiers.
Ces indicateurs influenceront directement mes choix de sujets et de rythme du contenu, et affecteront également mon jugement sur l'intervalle d'évaluation à long terme de PYTH.
X. Guide d'introduction pour les développeurs : de zéro à un.
Pour aider les partenaires qui commencent, je propose un ensemble de "trois étapes" exécutables.
Première étape, compléter un appel d'abonnement de prix dans l'environnement de test ; comprendre la structure des prix, la précision temporelle et les champs d'intervalle de confiance ;
Deuxième étape, intégrer la "stratégie d'abonnement et de demande" dans le contrat ou le robot de trading, comparer les différences de rendement entre différents seuils et différentes fenêtres à l'aide d'un système de backtesting ;
Troisième étape, établir un monitoring d'alerte ; définir des seuils d'alerte selon les indicateurs de gestion des risques et inclure les étiquettes d'anomalies dans les rejouements et les révisions.
Lorsque vous complétez ces trois étapes, vous n'utilisez pas seulement Pyth, mais vous intégrez également le concept de "données vérifiables" dans le code.
XI. Comparaison sectorielle et espace de collaboration.
Je ne préconise pas une pensée de somme nulle de "l'un diminue, l'autre augmente". Dans des scénarios où la couverture est plus large mais les exigences de timeliness ne sont pas si strictes, les fournisseurs de données traditionnels ont encore un avantage ; tandis que dans des scénarios hautement sensibles à la latence et à la vérifiabilité, le modèle de première main de Pyth a plus de chances de succès. À l'avenir, j'espère que les développeurs pourront combiner des flux de données de différentes sources de manière modulaire, en faisant un compromis dynamique entre coût et performance selon des fonctions cibles.
@Pyth Network #PythRoadmap $PYTH