30/10/2025 HEMI Article #25
Le réseau HEMI ne se concentre pas seulement sur le débit ou la sécurité, mais gère également la latence au niveau des millisecondes, car même un léger retard dans de nombreux cas d'utilisation sensibles à DeFi et au règlement peut avoir de grandes conséquences financières. Cet article expliquera comment les budgets de latence dans HEMI sont divisés en différentes étapes, pourquoi ils sont importants et quels conseils pratiques il existe pour les développeurs et les producteurs de produits.

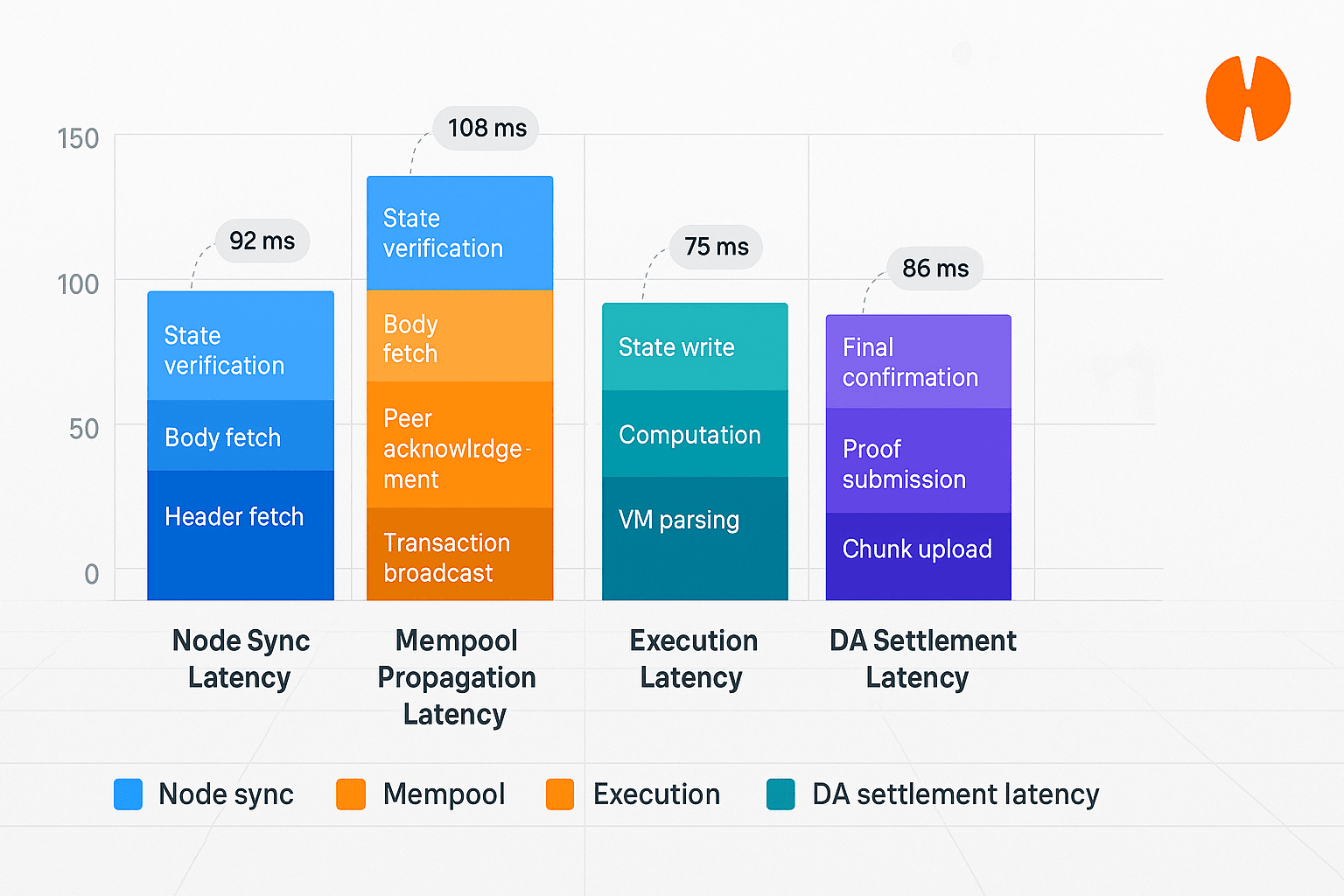
Aperçu des étapes de latence :
$HEMI Quatre étapes de latence majeures jouent un rôle clé dans l'architecture : la latence de synchronisation des nœuds, c'est-à-dire le temps nécessaire pour qu'un nouveau nœud ou un nœud synchronisé atteigne la pleine situation du réseau ; la latence de propagation de mempool, c'est-à-dire à quelle vitesse une transaction soumise se propage dans le mempool du réseau ; la latence d'exécution, c'est-à-dire le temps nécessaire pour exécuter la logique de contrat intelligent ou la transaction ; et la latence de disponibilité des données, c'est-à-dire combien de temps les données de la transaction restent disponibles et vérifiables. La combinaison de ces étapes constitue le chemin de latence complet qui doit être systématiquement surveillé et optimisé.
Pourquoi les budgets de latence comptent :
Un léger retard a un impact direct sur l'expérience utilisateur, un retour d'information rapide et des temps d'attente réduits augmentent la fiabilité de l'application. Dans des scénarios commerciaux, si la latence d'exécution et la latence DA restent faibles, cela donne un avantage concurrentiel au réseau pour les stratégies d'arbitrage et sensibles à la latence. En matière de sécurité, la latence ne peut pas être ignorée ; une latence DA ou de synchronisation de nœud prolongée peut entraîner un risque de réorganisation rare mais grave ou un état incohérent. Par conséquent, des modèles de risque pratiques ne peuvent être établis qu'en identifiant la latence au niveau des millisecondes.
Principales informations et considérations architecturales :
@Hemi Le design de latence fonctionne sur le principe de pipeline, en rassemblant le latence-stack des différents composants pour en déduire la latence totale prévue. Les développeurs doivent comprendre quel type d'application est sensible à quelle étape ; par exemple, dans les paiements instantanés ou l'appariement de commandes, la latence de mempool et d'exécution est primordiale, tandis que dans les règlements de grande valeur, la latence DA et de synchronisation des nœuds devient également décisive. Le suivi de la latence dans des visuels comme des barres empilées aide à identifier les goulets d'étranglement et des cibles SLA peuvent être définies.
Suggestions pratiques axées sur les développeurs :
Créez une carte de latence pour votre dApp où les mesures estimées et réelles sont enregistrées pour chaque étape ; incluez des tests de régression de latence dans CI afin de montrer les tendances à chaque commit. Mettez en place une surveillance du réseau et une observabilité qui rapportent le traçage de bout en bout, les latences p95/p99 et le temps de propagation de mempool. Adoptez des stratégies telles que le mise en file d'attente prioritaire, le réglage de la propagation de mempool et le regroupement d'exécution lorsque nécessaire pour aider à rester dans les chemins critiques. Enfin, effectuez des tests de divers scénarios de latence dans des simulations locales et de réseau limité afin de détecter les cas extrêmes à l'avance.
KPI et métriques à suivre :
Incluez les principales métriques : latence de bout en bout (en millisecondes), latence de mempool à exécution, temps d'exécution par tx, temps de règlement DA et latence de synchronisation des nœuds. Enregistrez régulièrement les valeurs p50, p95 et p99 de ces KPI et créez des alertes lorsque les seuils sont dépassés. Il sera également utile de garder à l'esprit des KPI orientés vers les affaires tels que les règlements échoués par heure et le temps moyen de récupération.
Conclusion :
Les budgets de latence ne sont plus une question technique ; ils sont déterminants pour le produit, en particulier pour les réseaux où les millisecondes comptent. HEMI a clairement mappé les étapes Node, Mempool, Execution et DA pour indiquer que le design de performance est une responsabilité collective. Si vous construisez sur HEMI ou évaluez le réseau, donnez la priorité à la gestion de la latence dans votre architecture et vos normes QA.
Restez connecté avec IncomeCrypto pour plus d'informations sur ce projet.


@Hemi $HEMI #Hemi #HEMINetwork #BlockchainPerformance #CryptoLatency