

Walrus shows up when a team is already a little nervous about what "data' means in their stack. Not tweets. Not metadata. Real blobs. The kind that make your product feel heavy the moment you stop pretending bandwidth is infinite.
In a call, someone will say it like a verdict... "The data was available".
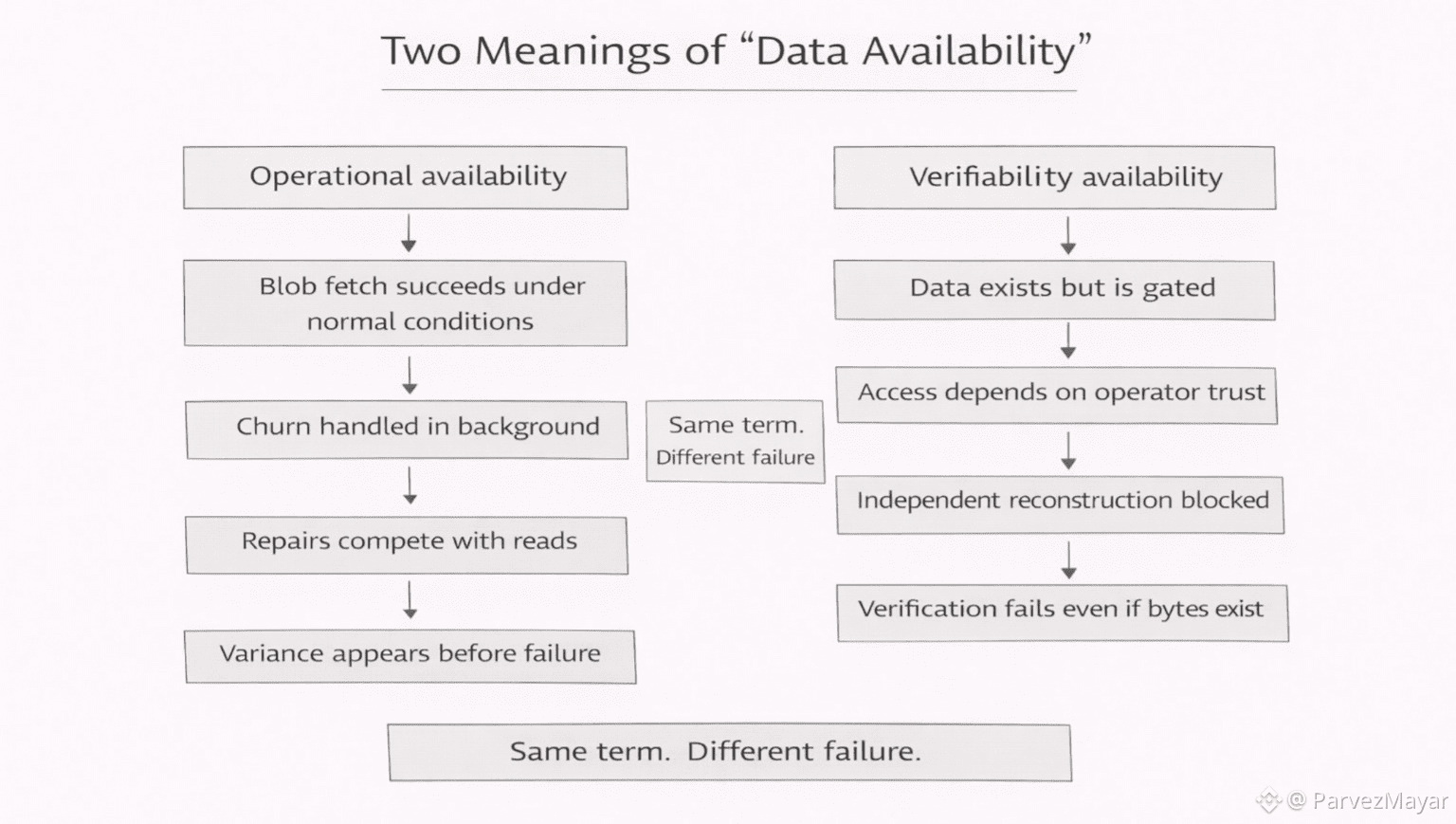
I've learned to treat that sentence like a smoke alarm. It only goes off when someone is trying to collapse two different problems into one comforting word.
Sometimes 'available' just means a user can fetch the blob while the network is being normal and annoying. Pieces drift. Nodes churn. Repair work exists in the background like gravity. If the blob comes back anyway, nobody claps. They just keep shipping. If it comes back inconsistently, nobody writes a manifesto either. They just start adding rails. Caches. Fallbacks. Little escape hatches that become permanent because support doesn’t accept philosophy as a fix.
That is what Walrus Protocol gets judged on. Not "is it decentralized". Whether it stays boring when the system is not in a good mood.
Other times 'available" is about something colder... can anyone verify a rollup's story without asking permission. This isn't about a user waiting for an image to load. The adversary isn't churn. It is withholding. A party deciding the data exists somewhere, but not for you, not now, unless you trust them.
If that is your threat model, slow is annoying but survivable. Hidden is not.
Teams confuse these because both problems wear the same badge. "Data availability". It sounds clean. It’s not. It’s a shortcut word teams use when nobody wants to name the actual failure they’re scared of.
Calm weeks let you get away with that.
Stress doesn't.
When it is a storage incident, the embarrassment is quiet and operational. You don’t 'lose' the blob in a dramatic way. You get the weaker failure first.. variance. Tail latency that fattens. Repairs that compete with reads at the wrong time. A blob that is technically recoverable but starts feeling conditional. The product team does not argue about cryptography. They argue about whether they can launch without babysitting storage.

When it's a verification incident, the embarrassment is uglier. It is not "it loaded late". It’s "can anyone independently reconstruct what happened." If the answer is "not unless we trust the sequencer", you did not have availability in the only sense that mattered. You had a promise.
Walrus does not need to be dragged into that second fight. It't not built to win it. It not built to make large objects survive the first fight... the one where the network keeps moving and users keep clicking anyway.
And DA layers donnot need to pretend they're storage. Publishing bytes for verifiers is not the same job as keeping blobs usable for real applications. One is about not being held hostage. The other is about not turning your support desk into a retry loop.
Mix them up, and you don’t get a dramatic blow-up. You just fail the wrong audit first. #Walrus $WAL @Walrus 🦭/acc

