Web3 apps are built on a quiet assumption that rarely holds in the real world: that infrastructure behaves consistently. It doesn’t. Nodes churn, networks degrade, latency spikes, and the “perfect” architecture diagram becomes irrelevant the moment users arrive at scale. If you want to build something that survives, you don’t design for best-case conditions. You design for failure as a normal state.
Node churn is one of the most under-discussed reasons decentralized storage stories break down. When nodes come and go, it’s not just an availability issue in theory. It becomes a product issue. Retrieval paths change. Responses become inconsistent. Some users get a smooth experience, others hit timeouts and broken content. From their perspective, the application is unreliable. The user doesn’t care whether the data still “exists” somewhere on the network. They care whether it loads now.
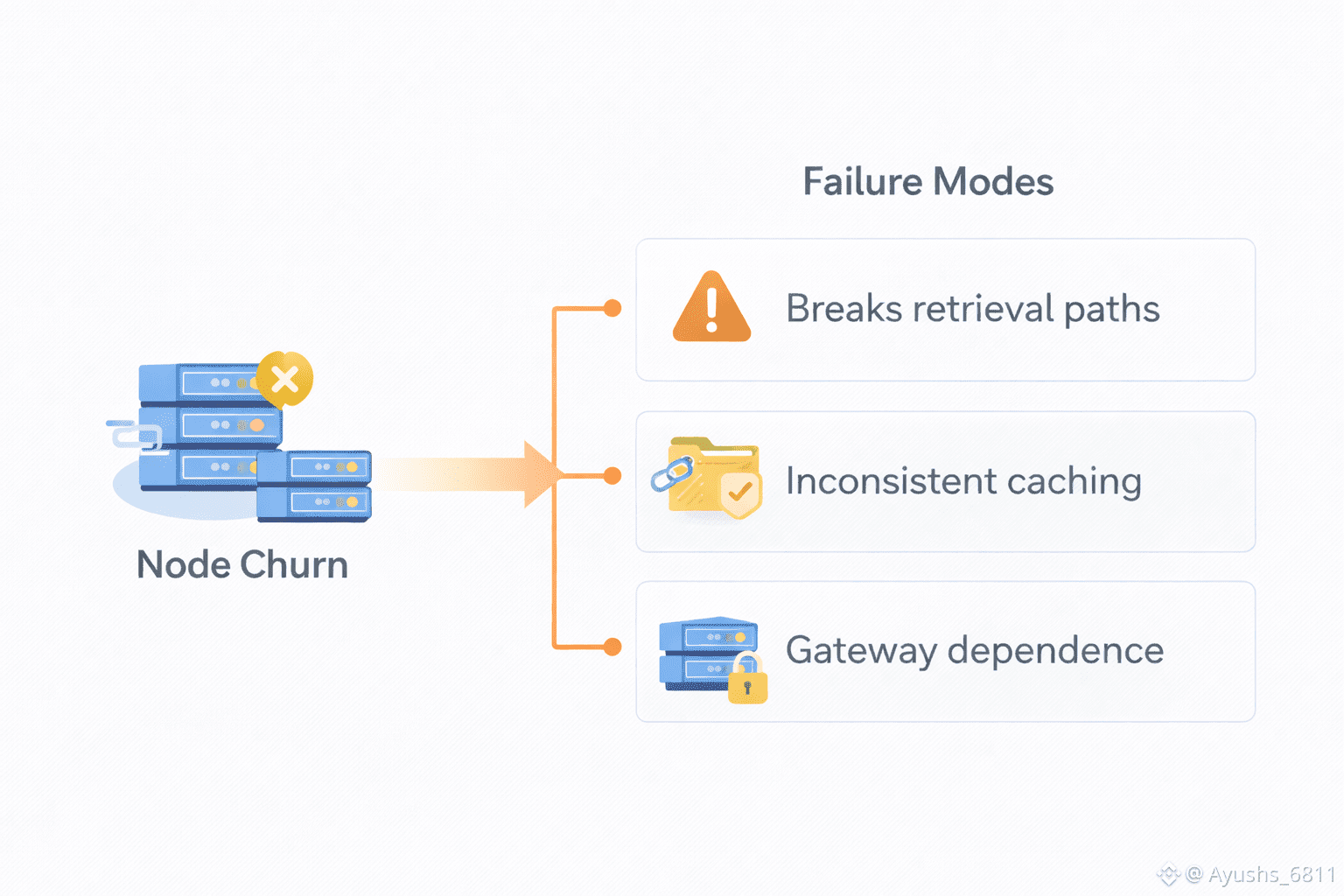
This is why I think the right way to talk about decentralized storage is not “cheaper” or “more distributed.” The right way is anti-fragility: can the system keep working and recover predictably when conditions get messy? Anti-fragile systems aren’t the ones that never fail. They’re the ones that fail gracefully and return to normal fast, without forcing the builder to bolt on centralized emergency exits.
Most teams learn this lesson the hard way. They ship with a decentralized storage layer, then they notice edge cases that become the main case. During a spike, retrieval slows. Under load, inconsistency appears. When a subset of nodes drops, suddenly a chunk of users sees missing content. The natural response is to patch. A fallback gateway here. A caching server there. A private mirror “just in case.” These patches protect the product, but they quietly reintroduce centralization. Not because builders are hypocrites, but because uptime and UX are non-negotiable.
The deeper problem is that many storage decisions are made as if storage is a static service. In decentralized systems, storage is closer to a living organism. Parts of it are always changing. If you want to stay decentralized without sacrificing reliability, your stack has to be designed with that volatility in mind.
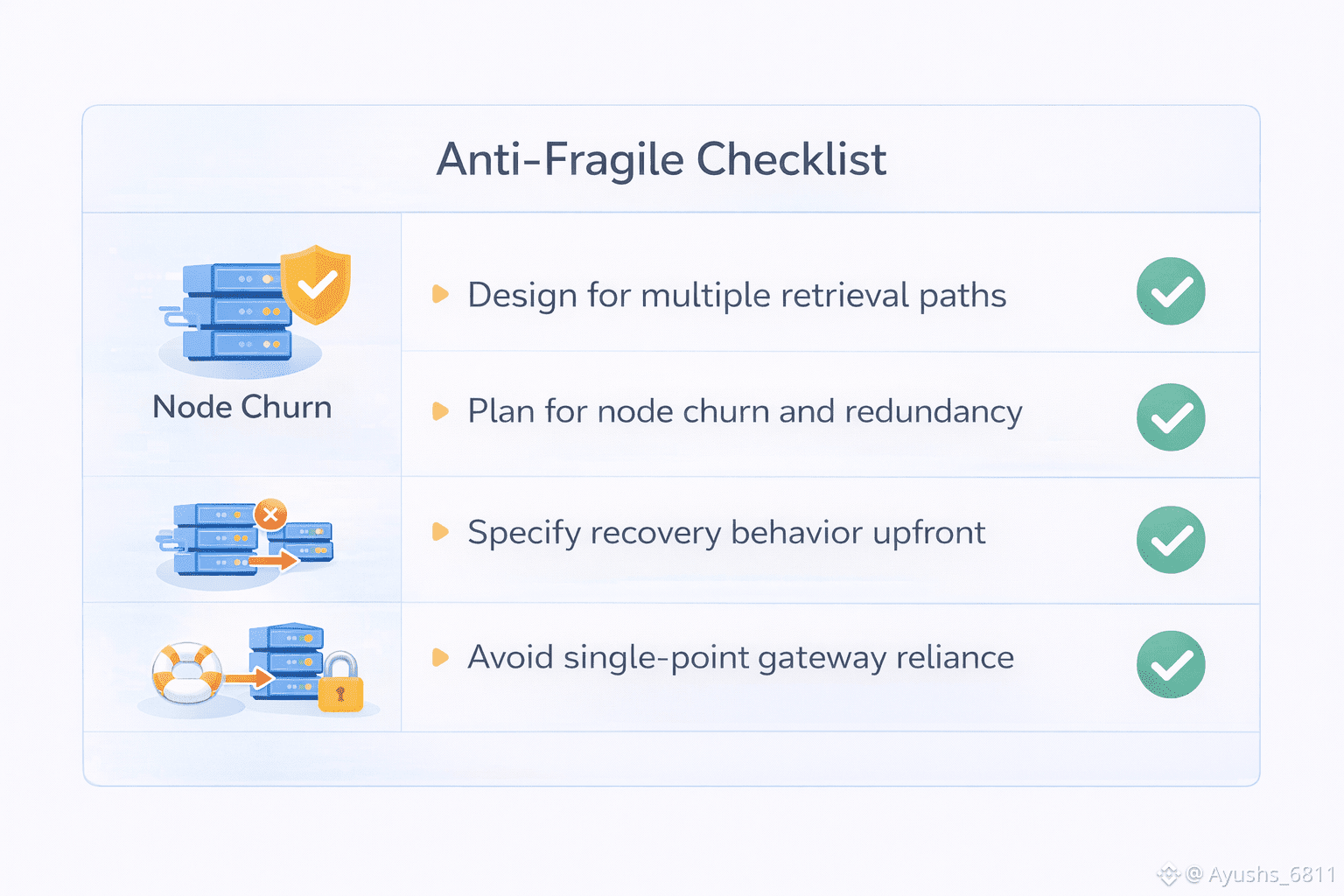
Anti-fragile design starts with accepting two truths. First, node churn is inevitable. Second, your user experience cannot be allowed to fluctuate with it. That means the goal isn’t “avoid churn.” The goal is “make churn irrelevant to users.”
A good way to frame it is to ask: what does your application rely on, at runtime? It relies on predictable retrieval. It relies on stable performance under load. It relies on a recovery story when something breaks. Without these, you end up building a second infrastructure layer to compensate. That compensation layer is where centralization sneaks back in.
This is where Walrus becomes relevant, not as a generic “storage solution,” but as a piece of an anti-fragile stack. The most valuable infrastructure in Web3 is the infrastructure that reduces the number of fragile assumptions developers need to make. If a protocol is designed around availability, redundancy, and recoverability as outcomes, it can help builders avoid the most common pattern: shipping decentralization and then rescuing it with centralized glue.
The point isn’t to claim perfection. The point is direction. Builders don’t need “a storage network.” They need a storage layer that behaves predictably enough that they don’t have to keep firefighting. The more predictable the system’s behavior under churn, the less temptation there is to add emergency gateways. And the fewer emergency gateways you add, the closer your product stays to the decentralization you originally intended.
From a builder’s perspective, the most practical question is simple: if the system is stressed, do you have to intervene manually? If the answer is yes, your design is fragile. If the answer is no, you’re closer to anti-fragility. Reliability isn’t something you “add later.” It’s a design property you either build for upfront or spend months compensating for.
I also think anti-fragility is where the next wave of Web3 infrastructure will be judged. Not by how impressive the architecture sounds, but by how quietly it works. The best infrastructure becomes invisible. It disappears into the product because it doesn’t create emergencies.
So when I evaluate a storage layer, I care less about how it markets decentralization and more about how it behaves when decentralization gets hard. Node churn is not a rare event. It’s the default condition in distributed networks. If Walrus can help make that default condition tolerable — predictable, recoverable, and stable — then it’s not just “storage.” It’s a reliability component that makes real applications easier to ship.
That is the entire point of an anti-fragile stack: you don’t win by avoiding chaos. You win by building systems that don’t fall apart because chaos showed up.


