No todos los problemas en infraestructura son ataques o bugs críticos. Muchos de los momentos más determinantes ocurren cuando algo simplemente deja de funcionar como se esperaba. En esos momentos, la diferencia no está en evitar el fallo, sino en si el sistema responde de forma previsible.
En almacenamiento descentralizado, los fallos no son una excepción. Nodos se desconectan, conexiones se degradan, hardware falla. La pregunta relevante no es si eso va a pasar, sino si el sistema fue diseñado asumiendo que va a pasar.
Walrus parte de una premisa clara: los datos deben poder reconstruirse y verificarse incluso cuando partes de la red no están disponibles. El diseño prioriza que la integridad de los archivos no dependa de un solo nodo ni de una secuencia perfecta de eventos. Esto no elimina los fallos, pero convierte la recuperación en una propiedad del sistema.
Cuando la red es pequeña, los fallos suelen pasar desapercibidos. Pero cuando el uso crece, cada interrupción pone a prueba algo más importante que la disponibilidad: la confianza. Aplicaciones y equipos no necesitan perfección, necesitan previsibilidad.
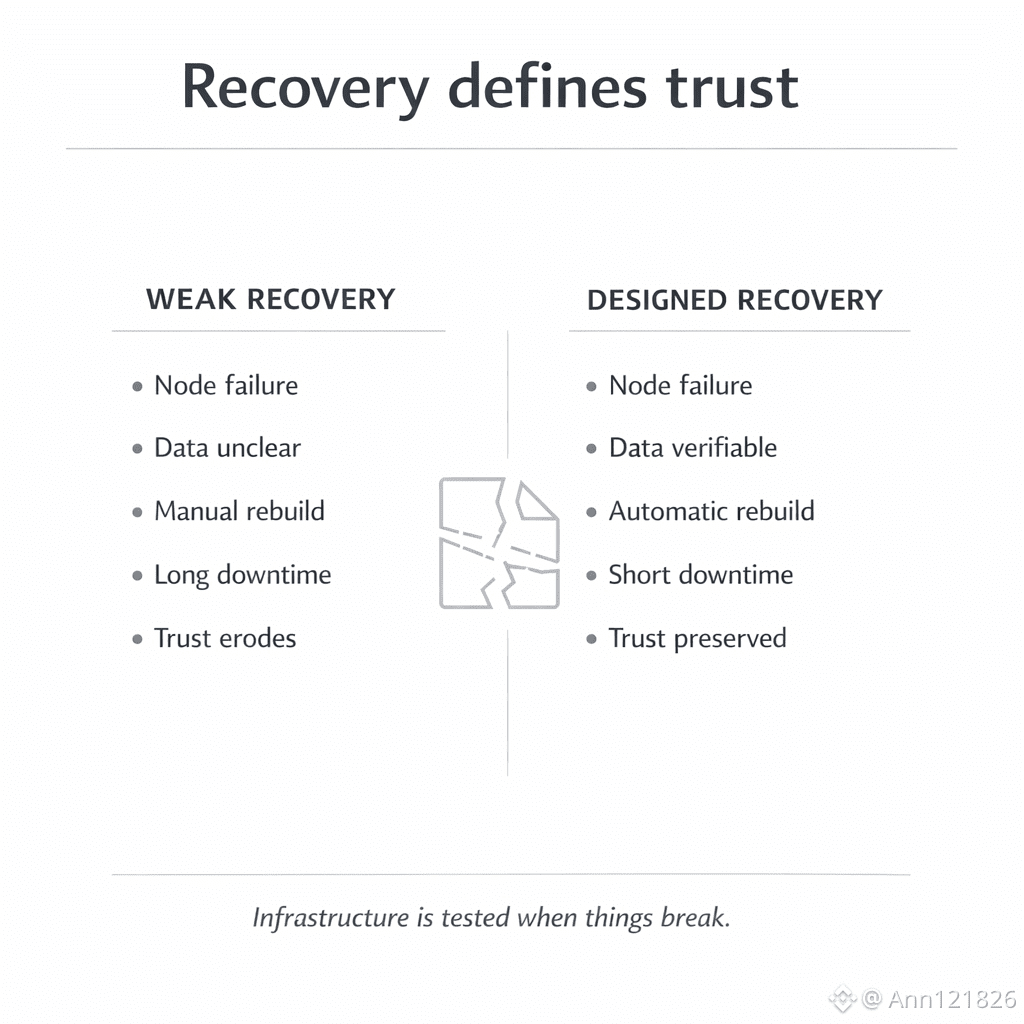
Aquí aparece el primer diferenciador real: el tiempo y la claridad de recuperación. Sistemas diseñados para reconstruirse automáticamente reducen la incertidumbre. Sistemas que dependen de intervención manual trasladan el problema del código a la operación diaria.
La recuperación también tiene un componente económico. Requiere nodos disponibles, coordinación y recursos. Si estos costos no están contemplados desde el diseño, la recuperación se convierte en un evento excepcional en lugar de un proceso normal.
El token $WAL cumple un rol indirecto pero clave: alinear incentivos para que los nodos participen en procesos de verificación y reconstrucción. Cuando esto está bien diseñado, la red no “se cae y vuelve”, simplemente continúa.
Los escenarios son claros. En el escenario positivo, los fallos ocurren pero la recuperación es rápida y casi invisible. En el intermedio, la red funciona pero genera fricción. En el negativo, la falta de previsibilidad erosiona la confianza incluso si los datos siguen existiendo.
La mayoría de las infraestructuras no fracasan por un gran colapso. Fracasan cuando dejan de ser confiables. En infraestructura, la calidad no se mide cuando todo funciona, sino cuando algo falla y nadie entra en pánico.

