I. Pendahuluan | Lompatan Lapisan Model Crypto AI
Data, model, dan komputasi adalah tiga elemen inti dari infrastruktur AI, menyerupai bahan bakar (data), mesin (model), dan energi (komputasi) yang tidak dapat dipisahkan. Seperti halnya jalur evolusi infrastruktur industri AI tradisional, bidang Crypto AI juga mengalami tahap yang serupa. Awal tahun 2024, pasar sempat didominasi oleh proyek GPU terdesentralisasi (Akash, Render, io.net, dll), yang secara umum menekankan logika pertumbuhan yang kasar dengan 'menggabungkan komputasi'. Namun, memasuki tahun 2025, fokus industri secara bertahap bergeser ke lapisan model dan data, menandakan bahwa Crypto AI sedang bertransisi dari kompetisi sumber daya dasar ke pembangunan lapisan menengah yang lebih berkelanjutan dan bernilai aplikasi.
Model besar umum (LLM) vs model khusus (SLM)
Model bahasa besar (LLM) tradisional sangat tergantung pada dataset besar dan arsitektur terdistribusi yang kompleks, dengan skala parameter mencapai 70B hingga 500B, biaya pelatihan sekali dapat mencapai jutaan dolar. SLM (Specialized Language Model) sebagai paradigma fine-tuning ringan untuk model dasar yang dapat digunakan kembali, biasanya didasarkan pada model open-source seperti LLaMA, Mistral, DeepSeek, dan menggabungkan sedikit data profesional berkualitas tinggi serta teknologi seperti LoRA, untuk dengan cepat membangun model ahli yang memiliki pengetahuan spesifik bidang, secara signifikan mengurangi biaya pelatihan dan ambang teknis.
Perlu dicatat bahwa, SLM tidak akan diintegrasikan ke dalam bobot LLM, tetapi beroperasi melalui arsitektur Agent, sistem plugin untuk routing dinamis, hot-plug modul LoRA, RAG (Retrieval-Augmented Generation), dan metode lain. Arsitektur ini mempertahankan kemampuan jangkauan luas dari LLM, sekaligus meningkatkan kinerja spesialis melalui modul fine-tuning, membentuk sistem cerdas yang sangat fleksibel dan komposit.
Crypto AI dalam nilai dan batasan di tingkat model
Proyek Crypto AI pada dasarnya sulit untuk langsung meningkatkan kemampuan inti model bahasa besar (LLM), penyebab utamanya adalah
Tingkat teknis terlalu tinggi: Skala data, sumber daya komputasi, dan kemampuan teknik yang dibutuhkan untuk melatih Foundation Model sangat besar, saat ini hanya perusahaan teknologi besar di Amerika Serikat (OpenAI, dll.) dan China (DeepSeek, dll.) yang memiliki kemampuan tersebut.
Keterbatasan ekosistem open-source: Meskipun model dasar arus utama seperti LLaMA dan Mixtral telah dibuka, kunci untuk mendorong terobosan model masih terfokus pada lembaga penelitian dan sistem teknik tertutup, ruang partisipasi proyek di lapisan model inti terbatas.
Namun, di atas model dasar open-source, proyek Crypto AI masih dapat memperpanjang nilai melalui fine-tuning model bahasa khusus (SLM), dan menggabungkan verifikasi dan mekanisme insentif Web3. Sebagai “lapisan antarmuka” dalam rantai industri AI, hal ini terwujud dalam dua arah inti:
Lapisan verifikasi yang dapat dipercaya: Mencatat jalur generasi model, kontribusi data, dan penggunaan di rantai, meningkatkan keterlacakan dan ketahanan AI output terhadap perubahan.
Mekanisme insentif: Memanfaatkan token asli, untuk memberikan insentif terhadap pengunggahan data, pemanggilan model, pelaksanaan agen (Agent), dan lain-lain, membangun siklus positif dalam pelatihan dan layanan model.
Klasifikasi jenis model AI dan analisis kecocokan blockchain

Dapat dilihat, titik jatuh yang layak untuk proyek Crypto AI berbasis model terletak pada fine-tuning ringan SLM kecil, akses data rantai dari arsitektur RAG dan verifikasi, serta penerapan lokal dan insentif model Edge. Menggabungkan verifikasi dan mekanisme token blockchain, Crypto dapat memberikan nilai unik untuk skenario model dengan sumber daya menengah dan rendah, membentuk nilai diferensiasi di “lapisan antarmuka” AI.
Blockchain AI yang berbasis data dan model dapat mencatat sumber kontribusi dari setiap data dan model secara jelas dan tidak dapat diubah di rantai, secara signifikan meningkatkan kredibilitas data dan keterlacakan pelatihan model. Selain itu, melalui mekanisme kontrak pintar, ketika data atau model dipanggil, secara otomatis memicu distribusi imbalan, mengubah perilaku AI menjadi nilai tokenisasi yang terukur dan dapat diperdagangkan, membangun sistem insentif yang berkelanjutan. Selain itu, pengguna komunitas juga dapat memberikan penilaian terhadap kinerja model, berpartisipasi dalam penyusunan dan iterasi aturan, memperbaiki struktur tata kelola terdesentralisasi.
Dua, ringkasan proyek | Visi rantai AI OpenLedger
@OpenLedger adalah salah satu dari sedikit proyek AI blockchain yang fokus pada mekanisme insentif data dan model di pasar saat ini. Ini pertama kali mengusulkan konsep “AI yang Dapat Dibayar”, bertujuan untuk membangun lingkungan operasi AI yang adil, transparan, dan dapat disusun, untuk mendorong kontributor data, pengembang model, dan pembangun aplikasi AI berkolaborasi di satu platform, dan mendapatkan keuntungan di rantai berdasarkan kontribusi nyata.
@OpenLedger menyediakan rantai penuh dari “penyediaan data” hingga “penerapan model” hingga “pembagian keuntungan pemanggilan”, modul intinya mencakup:
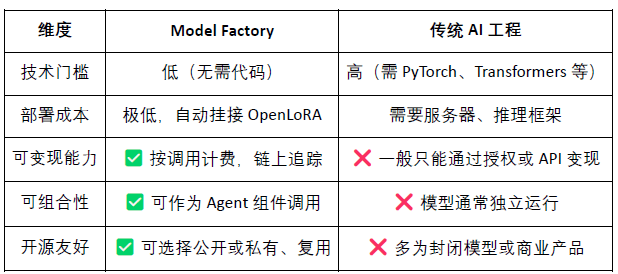
Pabrik Model: Tanpa pemrograman, dapat menggunakan LoRA untuk pelatihan dan penerapan model kustom berdasarkan LLM open-source;
OpenLoRA: Mendukung co-existence ribuan model, memuat dinamis sesuai permintaan, secara signifikan mengurangi biaya penerapan;
PoA (Proof of Attribution): Mewujudkan pengukuran kontribusi dan distribusi imbalan melalui catatan pemanggilan di rantai;
Datanets: Jaringan data terstruktur yang mengarah pada skenario vertikal, dibangun dan divalidasi oleh komunitas;
Platform usulan model (Model Proposal Platform): Pasar model yang dapat disusun, dapat dipanggil, dan dapat dibayar di rantai.
Melalui modul-modul di atas, @OpenLedger telah membangun infrastruktur ekonomi “agen cerdas” yang didorong oleh data dan model yang dapat disusun, mendorong rantai nilai AI ke dalam bentuk di rantai.
Dalam hal adopsi teknologi blockchain, @OpenLedger menggunakan OP Stack + EigenDA sebagai dasar, membangun lingkungan operasi data dan kontrak yang berkinerja tinggi, biaya rendah, dan dapat diverifikasi untuk model AI.
Dibangun di atas OP Stack: Berdasarkan tumpukan teknologi Optimism, mendukung throughput tinggi dan eksekusi biaya rendah;
Transaksi diselesaikan di jaringan utama Ethereum: Memastikan keamanan transaksi dan integritas aset;
Kompatibel dengan EVM: Memudahkan pengembang untuk dengan cepat menerapkan dan memperluas berdasarkan Solidity;
EigenDA menyediakan dukungan ketersediaan data: Secara signifikan mengurangi biaya penyimpanan, menjamin verifikasi data.
Berbeda dengan NEAR yang lebih berfokus pada lapisan dasar, dengan penekanan pada kedaulatan data dan arsitektur “AI Agents on BOS”, @OpenLedger lebih fokus pada pembangunan rantai khusus AI yang berorientasi pada insentif data dan model, berkomitmen untuk memastikan bahwa pengembangan dan pemanggilan model di rantai dapat mewujudkan nilai yang dapat dilacak, dapat disusun, dan berkelanjutan. Ini adalah infrastruktur dasar insentif model di dunia Web3, menggabungkan hosting model ala HuggingFace, penagihan penggunaan ala Stripe, dan antarmuka komposisi di rantai ala Infura, mendorong jalur penerapan “model sebagai aset”.
三、Komponen inti dan arsitektur teknologi OpenLedger
3.1 Pabrik Model, pabrik model tanpa kode
ModelFactory adalah @OpenLedger platform fine-tuning model bahasa besar (LLM) di bawah ekosistem tersebut. Berbeda dengan kerangka fine-tuning tradisional, ModelFactory menyediakan antarmuka grafis murni, tanpa perlu alat baris perintah atau integrasi API. Pengguna dapat melakukan fine-tuning model berdasarkan dataset yang telah disetujui dan diperiksa di @OpenLedger . Ini mewujudkan alur kerja terintegrasi untuk otorisasi data, pelatihan model, dan penerapan, dengan proses inti meliputi:
Kontrol akses data: Pengguna mengajukan permintaan data, penyedia meninjau dan menyetujui, data otomatis terintegrasi ke dalam antarmuka pelatihan model.
Pemilihan dan konfigurasi model: Mendukung LLM arus utama (seperti LLaMA, Mistral), melalui GUI mengkonfigurasi hyperparameters.
Fine-tuning ringan: Dilengkapi dengan mesin LoRA / QLoRA, secara real-time menampilkan kemajuan pelatihan.
Evaluasi dan penerapan model: Dilengkapi dengan alat evaluasi, mendukung ekspor untuk penerapan atau panggilan berbagi ekosistem.
Antarmuka verifikasi interaktif: Menyediakan antarmuka berbasis chat, memudahkan pengujian kemampuan tanya jawab model secara langsung.
Pelacakan sumber RAG: Jawaban dilengkapi dengan referensi sumber, meningkatkan kepercayaan dan keterverifikasian.
Arsitektur sistem Model Factory mencakup enam modul, meliputi otentikasi identitas, hak data, fine-tuning model, evaluasi penerapan, dan pelacakan RAG, membangun platform layanan model yang terintegrasi, aman, terkontrol, interaktif waktu nyata, dan dapat dimonetisasi secara berkelanjutan.
Daftar kemampuan model bahasa besar yang didukung oleh ModelFactory saat ini adalah sebagai berikut:
Seri LLaMA: Ekosistem terluas, komunitas aktif, kinerja umum yang kuat, adalah salah satu model dasar open-source yang paling umum saat ini.
Mistral: Struktur efisien, kinerja inferensi sangat baik, cocok untuk penerapan yang fleksibel dan sumber daya yang terbatas.
Qwen: Produk dari Alibaba, kinerja dalam tugas bahasa Mandarin sangat baik, kemampuan komprehensif yang kuat, cocok untuk pengembang domestik pilihan pertama.
ChatGLM: Efek percakapan dalam bahasa Mandarin sangat baik, cocok untuk layanan pelanggan vertikal dan skenario lokal.
Deepseek: Unggul dalam pengembangan kode dan penalaran matematis, cocok untuk alat bantu pengembangan cerdas.
Gemma: Model ringan yang diluncurkan oleh Google, dengan struktur yang jelas, mudah untuk cepat memahami dan bereksperimen.
Falcon: Pernah menjadi tolok ukur kinerja, cocok untuk penelitian dasar atau pengujian perbandingan, tetapi tingkat aktivitas komunitas telah menurun.
BLOOM: Dukungan multi-bahasa yang kuat, tetapi kinerja inferensi agak lemah, cocok untuk penelitian yang mencakup berbagai bahasa.
GPT-2: Model klasik awal, hanya cocok untuk tujuan pengajaran dan verifikasi, tidak disarankan untuk penggunaan penerapan nyata.
Meskipun @OpenLedger kombinasi model tidak mencakup model MoE berkinerja tinggi terbaru atau model multimodal, strateginya tidak ketinggalan zaman, melainkan merupakan konfigurasi “pragmatis lebih diutamakan” yang dibuat berdasarkan batasan realitas penerapan di rantai (biaya inferensi, penyesuaian RAG, kompatibilitas LoRA, lingkungan EVM).
Model Factory sebagai alat tanpa kode, semua model sudah memiliki mekanisme pembuktian kontribusi, memastikan hak kontributor data dan pengembang model, memiliki keuntungan ambang rendah, dapat dimonetisasi, dan dapat disusun, dibandingkan dengan alat pengembangan model tradisional:
Untuk pengembang: Menyediakan jalur lengkap untuk inkubasi model, distribusi, dan pendapatan;
Untuk platform: Membentuk sirkulasi aset model dan ekosistem kombinasi;
Untuk pengguna: Dapat menggunakan model atau Agen seperti memanggil API.
3.2 OpenLoRA, aset rantai untuk model fine-tuning
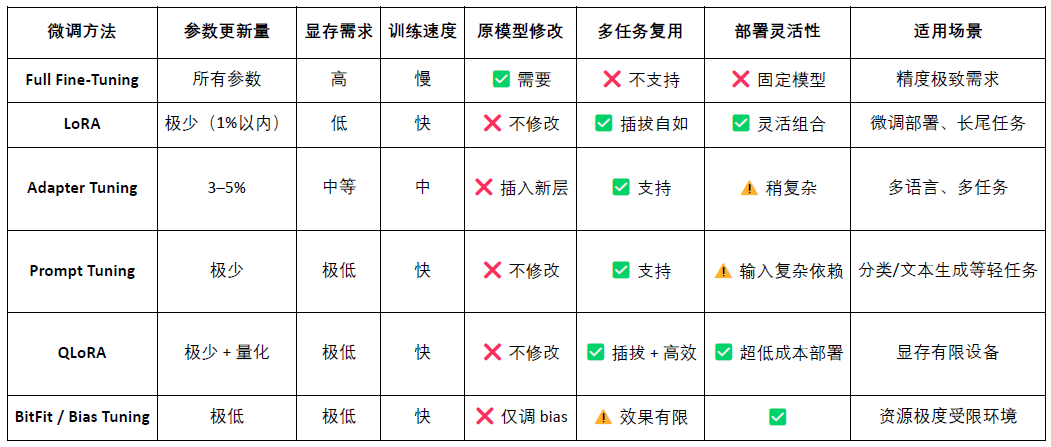
LoRA (Low-Rank Adaptation) adalah metode fine-tuning parameter yang efisien, dengan cara menyisipkan “matriks peringkat rendah” dalam model besar yang telah dilatih sebelumnya untuk mempelajari tugas baru, tanpa mengubah parameter model asli, sehingga secara signifikan mengurangi biaya pelatihan dan kebutuhan penyimpanan. Model bahasa besar tradisional (seperti LLaMA, GPT-3) biasanya memiliki puluhan miliar hingga ratusan miliar parameter. Untuk menggunakannya dalam tugas tertentu (seperti pertanyaan hukum, konsultasi medis), perlu dilakukan fine-tuning. Strategi inti LoRA adalah: “membekukan parameter model besar asli, hanya melatih matriks parameter baru yang disisipkan.”, yang parameter efisien, pelatihan cepat, dan penerapan fleksibel, merupakan metode fine-tuning yang paling sesuai untuk penerapan dan pemanggilan model Web3 saat ini.
OpenLoRA adalah @OpenLedger yang dibangun sebagai kerangka inferensi ringan yang dirancang untuk penerapan dan berbagi sumber daya multi-model. Tujuan inti adalah untuk menyelesaikan masalah umum dalam penerapan model AI saat ini, seperti biaya tinggi, penggunaan yang rendah, dan pemborosan sumber daya GPU, mendorong pelaksanaan “AI yang dapat dibayar” (Payable AI).
Komponen inti arsitektur sistem OpenLoRA, berdasarkan desain modular, mencakup penyimpanan model, eksekusi inferensi, routing permintaan, dan langkah kunci lainnya, mewujudkan kemampuan penerapan dan pemanggilan multi-model yang efisien dan biaya rendah:
Modul penyimpanan Adapter LoRA (LoRA Adapters Storage): Adapter LoRA yang telah fine-tuning disimpan di @OpenLedger , memungkinkan pemuatan sesuai permintaan, menghindari semua model dimuat sebelumnya ke memori, menghemat sumber daya.
Lapisan hosting model dan penggabungan dinamis (Model Hosting & Adapter Merging Layer): Semua model fine-tuning berbagi model besar dasar (base model), saat inferensi adapter LoRA digabungkan secara dinamis, mendukung inferensi gabungan beberapa adapter (ensemble), meningkatkan kinerja.
Mesin inferensi (Inference Engine): Mengintegrasikan teknologi optimisasi CUDA seperti Flash-Attention, Paged-Attention, dan SGMV.
Modul routing permintaan dan keluaran aliran (Request Router & Token Streaming): Menurut model yang dibutuhkan dalam permintaan, secara dinamis meroute ke adapter yang benar, meningkatkan generasi aliran tingkat token melalui optimasi inti.
Proses inferensi OpenLoRA termasuk dalam kategori layanan model “umum yang matang” secara teknis, sebagai berikut:
Pemuatan model dasar: Sistem memuat model besar dasar seperti LLaMA 3, Mistral, dan lainnya ke dalam memori GPU.
Pencarian dinamis LoRA: Setelah menerima permintaan, mengunduh adapter LoRA yang ditentukan secara dinamis dari Hugging Face, Predibase, atau direktori lokal.
Aktivasi penggabungan adapter: Dengan mengoptimalkan inti, menggabungkan adapter dengan model dasar secara real-time, mendukung inferensi gabungan dari beberapa adapter.
Eksekusi inferensi dan keluaran aliran: Model yang telah digabung mulai menghasilkan respons, menggunakan keluaran aliran tingkat token untuk mengurangi latensi, menggabungkan kuantisasi untuk menjamin efisiensi dan akurasi.
Akhir inferensi dan pelepasan sumber daya: Setelah inferensi selesai, adapter secara otomatis di-unload, melepaskan sumber daya memori. Memastikan dapat berputar secara efisien di satu GPU dan melayani ribuan model fine-tuning, mendukung putaran model yang efisien.
OpenLoRA melalui serangkaian teknik optimasi dasar, secara signifikan meningkatkan efisiensi penerapan dan inferensi multi-model. Intinya mencakup pemuatan adapter LoRA dinamis (JIT loading), secara efektif mengurangi penggunaan memori; paralel tensor (Tensor Parallelism) dan perhatian yang dipaged (Paged Attention) untuk mencapai pemrosesan teks panjang dan konversi tinggi; mendukung penggabungan multi-model (Multi-Adapter Merging) untuk eksekusi penggabungan LoRA (ensemble); sekaligus, melalui perhatian kilat (Flash Attention), pengoptimalan CUDA yang telah dikompilasi sebelumnya dan teknologi kuantisasi FP8/INT8, lebih lanjut meningkatkan kecepatan inferensi dan mengurangi latensi. Optimasi ini memungkinkan OpenLoRA untuk secara efisien melayani ribuan model fine-tuning dalam lingkungan single card, dengan kinerja, skalabilitas, dan penggunaan sumber daya yang seimbang.
OpenLoRA bukan hanya kerangka inferensi LoRA yang efisien, tetapi juga mengintegrasikan proses inferensi model dengan mekanisme insentif Web3 secara mendalam, bertujuan untuk mengubah model LoRA menjadi aset Web3 yang dapat dipanggil, dapat disusun, dan dapat dibagi.
Model sebagai Aset (Model-as-Asset): OpenLoRA tidak hanya menerapkan model, tetapi memberikan setiap model fine-tuning identitas di rantai (Model ID), dan mengaitkan perilaku pemanggilannya dengan insentif ekonomi, mewujudkan “pemanggilan sama dengan pembagian keuntungan”.
Penggabungan dinamis multi-LoRA + kepemilikan insentif: Mendukung pemanggilan gabungan dinamis dari beberapa adapter LoRA, memungkinkan kombinasi model yang berbeda untuk membentuk layanan Agen baru, sementara sistem dapat secara akurat membagi keuntungan berdasarkan jumlah pemanggilan untuk setiap adapter berdasarkan mekanisme PoA (Proof of Attribution).
Mendukung inferensi berbagi multi-tenant untuk model ekor panjang: Melalui pemuatan dinamis dan mekanisme pelepasan memori, OpenLoRA dapat melayani ribuan model LoRA dalam lingkungan single card, sangat cocok untuk model kecil, asisten AI personal, dan skenario pemanggilan frekuensi rendah lainnya di Web3.

Selain itu, @OpenLedger merilis pandangan masa depan terhadap metrik kinerja OpenLoRA, dibandingkan dengan penerapan model parameter penuh tradisional, penggunaan memori secara signifikan berkurang menjadi 8–12GB; waktu pergantian model secara teoritis dapat kurang dari 100ms; throughput dapat mencapai 2000+ tokens/detik; kontrol latensi di 20–50ms. Secara keseluruhan, metrik kinerja ini secara teknis dapat dicapai, tetapi lebih mendekati “kinerja batas atas”, dalam lingkungan produksi nyata, kinerja mungkin terpengaruh oleh perangkat keras, kebijakan penjadwalan, dan kompleksitas skenario, harus dianggap sebagai “batas ideal” bukan “stabil sehari-hari”.
3.3 Datanets (jaringan data), dari kedaulatan data ke kecerdasan data
Data berkualitas tinggi, khusus untuk bidang, menjadi elemen kunci dalam membangun model berkinerja tinggi. Datanets adalah infrastruktur @OpenLedger “data sebagai aset”, digunakan untuk mengumpulkan dan mengelola dataset khusus bidang, untuk agregasi, verifikasi, dan distribusi data tertentu dalam jaringan terdesentralisasi, menyediakan sumber data berkualitas tinggi untuk pelatihan dan fine-tuning model AI. Setiap Datanet berfungsi seperti gudang data terstruktur, di mana kontributor mengunggah data dan memastikan data dapat dilacak dan dapat dipercaya melalui mekanisme kepemilikan di rantai, dengan insentif dan kontrol akses yang transparan, Datanets mewujudkan kolaborasi komunitas dan penggunaan data yang dapat dipercaya yang diperlukan untuk pelatihan model.
Dibandingkan dengan proyek seperti Vana yang fokus pada kedaulatan data, @OpenLedger tidak hanya mencakup “pengumpulan data”, tetapi juga memperluas nilai data untuk pelatihan model dan pemanggilan di rantai melalui tiga modul utama: Datanets (pengumpulan dan penandaan data kolaboratif), Model Factory (alat pelatihan model yang mendukung fine-tuning tanpa kode), OpenLoRA (adapter model yang dapat dilacak dan disusun). Vana menekankan “siapa yang memiliki data”, sedangkan @OpenLedger lebih menekankan “bagaimana data dilatih, dipanggil, dan mendapatkan imbalan”, masing-masing menempati posisi kunci dalam perlindungan kedaulatan data dan jalur monetisasi data dalam ekosistem AI Web3.
3.4 Proof of Attribution (kontribusi pembuktian): Merombak lapisan insentif distribusi keuntungan
Proof of Attribution (PoA) adalah @OpenLedger mekanisme inti untuk merealisasikan kepemilikan data dan distribusi insentif, melalui pencatatan terenkripsi di rantai, menghubungkan setiap data pelatihan dengan keluaran model dalam cara yang dapat diverifikasi, memastikan kontributor mendapatkan imbalan yang layak dalam pemanggilan model, alur proses kepemilikan data dan insentif adalah sebagai berikut:
Pengiriman data: Pengguna mengunggah dataset terstruktur yang khusus untuk bidang, dan mencatat hak atasnya di rantai.
Evaluasi dampak: Sistem mengevaluasi nilai berdasarkan karakteristik data dan reputasi kontributor, pada setiap inferensi.
Validasi pelatihan: Catatan log pelatihan mencatat penggunaan aktual setiap data, memastikan kontribusi dapat diverifikasi.
Distribusi insentif: Berdasarkan pengaruh data, memberikan penghargaan Token yang terkait dengan efek kepada kontributor.
Tata kelola kualitas: Menghukum data yang berkualitas rendah, berlebihan, atau berniat jahat, memastikan kualitas pelatihan model.
Dibandingkan dengan jaringan insentif umum berbasis blockchain yang menggabungkan mekanisme penilaian dari arsitektur subnet Bittensor, @OpenLedger lebih fokus pada penangkapan nilai dan mekanisme pembagian keuntungan di tingkat model. PoA bukan hanya alat distribusi insentif, tetapi juga kerangka kerja untuk transparansi, pelacakan sumber, dan kepemilikan multi-tahap: Ini mencatat seluruh proses pengunggahan data, pemanggilan model, dan pelaksanaan agen di rantai, mewujudkan jalur nilai yang dapat diverifikasi dari ujung ke ujung. Mekanisme ini memungkinkan setiap pemanggilan model dapat ditelusuri kembali ke kontributor data dan pengembang model, sehingga mewujudkan “konsensus nilai” yang sebenarnya dan “pendapatan yang dapat diperoleh” dalam sistem AI di rantai.
RAG (Retrieval-Augmented Generation) adalah arsitektur AI yang menggabungkan sistem pencarian dan model generatif, bertujuan untuk menyelesaikan masalah “penutupan pengetahuan” dan “rekaan” model bahasa tradisional, dengan memperkenalkan basis pengetahuan eksternal untuk meningkatkan kemampuan generasi model, sehingga keluaran menjadi lebih nyata, dapat dijelaskan, dan dapat diverifikasi. RAG Attribution adalah @OpenLedger mekanisme kepemilikan data dan insentif yang dibangun dalam skenario Retrieval-Augmented Generation, memastikan konten keluaran model dapat dilacak dan diverifikasi, kontributor dapat diberi insentif, akhirnya mewujudkan keandalan generasi dan transparansi data, prosesnya mencakup:
Pertanyaan pengguna → Mencari data: AI menerima pertanyaan dan mencari konten terkait dari indeks data @OpenLedger .
Data dipanggil dan menghasilkan jawaban: Konten yang ditemukan digunakan untuk menghasilkan jawaban model dan mencatat perilaku pemanggilan di rantai.
Kontributor mendapatkan imbalan: Setelah data digunakan, kontributornya mendapatkan insentif yang dihitung berdasarkan jumlah dan relevansi.
Hasil yang dihasilkan disertai referensi: Keluaran model dilengkapi dengan tautan sumber data asli, mewujudkan pertanyaan yang transparan dan konten yang dapat diverifikasi.

@OpenLedger RAG Attribution memungkinkan setiap jawaban AI dapat dilacak kembali ke sumber data yang nyata, kontributor mendapatkan insentif berdasarkan frekuensi rujukan, mewujudkan “pengetahuan memiliki sumber, pemanggilan dapat direalisasikan”. Mekanisme ini tidak hanya meningkatkan transparansi keluaran model, tetapi juga membangun siklus insentif yang berkelanjutan untuk kontribusi data berkualitas tinggi, merupakan infrastruktur dasar untuk mendorong AI yang dapat dipercaya dan aset data.
Empat, kemajuan proyek OpenLedger dan kolaborasi ekosistem
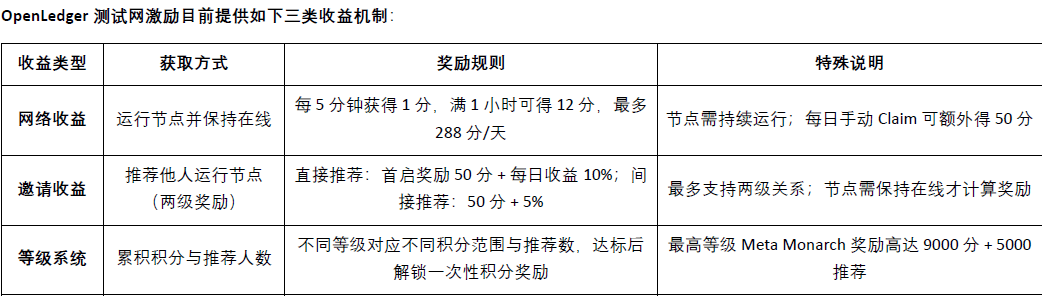
Saat ini@OpenLedger telah diluncurkan di testnet, lapisan kecerdasan data (Data Intelligence Layer) adalah @OpenLedger fase pertama dari testnet, bertujuan untuk membangun gudang data internet yang didorong oleh node komunitas. Data ini telah dipilih, ditingkatkan, dikategorikan, dan diproses secara terstruktur, akhirnya membentuk kecerdasan tambahan yang cocok untuk model bahasa besar (LLM), digunakan untuk membangun @OpenLedger model AI di bidang. Anggota komunitas dapat menjalankan node perangkat tepi, berpartisipasi dalam pengumpulan dan pemrosesan data, node akan menggunakan sumber daya komputasi lokal untuk melaksanakan tugas terkait data, peserta mendapatkan poin berdasarkan tingkat aktivitas dan penyelesaian tugas. Poin ini nantinya akan dikonversi menjadi token OPEN, dengan rasio penukaran yang akan diumumkan sebelum acara penciptaan token (TGE).
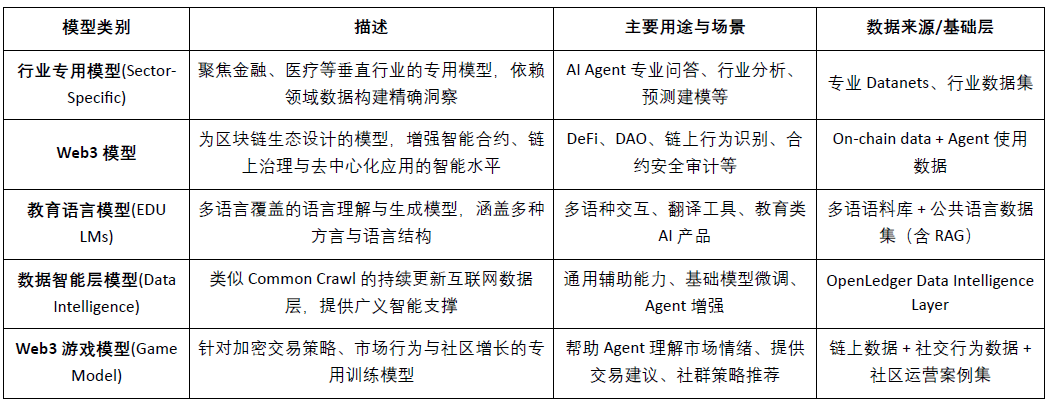
Testnet Epoch 2 menekankan peluncuran mekanisme jaringan data Datanets, fase ini hanya terbatas untuk pengguna yang terdaftar, harus menyelesaikan penilaian awal untuk membuka tugas. Tugas mencakup verifikasi data, klasifikasi, dll., setelah selesai, poin diberikan berdasarkan akurasi dan kesulitan, dan papan peringkat mendorong kontribusi berkualitas tinggi, saat ini situs resmi menyediakan model data yang dapat diikutsertakan sebagai berikut:
Namun @OpenLedger memiliki perencanaan peta jalan yang lebih jangka panjang, dari pengumpulan data, pembangunan model, menuju ekosistem Agen, secara bertahap mewujudkan “data sebagai aset, model sebagai layanan, Agen sebagai entitas cerdas” untuk ekonomi AI terdesentralisasi yang lengkap.
Fase 1 · Lapisan kecerdasan data (Data Intelligence Layer): Komunitas mengumpulkan dan memproses data internet melalui operasi node tepi, membangun lapisan dasar kecerdasan data yang berkualitas tinggi dan terus diperbarui.
Fase 2 · Kontribusi data komunitas (Community Contributions): Komunitas berpartisipasi dalam verifikasi dan umpan balik data, secara bersama-sama membangun dataset emas (Golden Dataset) yang dapat dipercaya, menyediakan input berkualitas untuk pelatihan model.
Fase 3 · Pembangunan model dan deklarasi kepemilikan (Build Models & Claim): Berdasarkan data emas, pengguna dapat melatih model khusus dan mengklaim kepemilikannya, mewujudkan aset model dan pelepasan nilai yang dapat disusun.
Fase 4 · Pembuatan agen (Build Agents): Berdasarkan model yang telah diterbitkan, komunitas dapat membuat agen cerdas yang dipersonalisasi (Agents), mewujudkan penerapan multi-skenario dan evolusi kolaboratif yang berkelanjutan.
@OpenLedger memiliki mitra ekosistem yang mencakup komputasi, infrastruktur, alat, dan aplikasi AI. Mitra mereka termasuk Aethir, Ionet, 0G, dan platform komputasi terdesentralisasi lainnya, AltLayer, Etherfi, serta AVS di EigenLayer menyediakan dukungan untuk perluasan dan penyelesaian dasar; alat seperti Ambios, Kernel, Web3Auth, Intract menyediakan kemampuan integrasi pengembangan dan otentikasi; dalam model AI dan agen, @OpenLedger bekerja sama dengan proyek Giza, Gaib, Exabits, FractionAI, Mira, NetMind untuk memajukan penerapan model dan implementasi agen, membangun ekosistem AI Web3 yang terbuka, dapat disusun, dan berkelanjutan.
Dalam setahun terakhir, #OpenLedger telah mengadakan serangkaian KTT DeAI bertema Crypto AI selama Token2049 Singapore, Devcon Thailand, Consensus Hong Kong, dan ETH Denver, mengundang banyak proyek inti dan pemimpin teknologi di bidang AI terdesentralisasi. Sebagai salah satu dari sedikit infrastruktur yang dapat secara berkelanjutan merencanakan acara industri berkualitas tinggi, #OpenLedger melalui DeAI Summit telah memperkuat pengakuan mereknya dan reputasi profesional di komunitas pengembang dan ekosistem startup AI Web3, meletakkan dasar industri yang baik untuk perluasan ekosistem dan penerapan teknologi di masa depan.
Lima, pendanaan dan latar belakang tim
@OpenLedger telah menyelesaikan pendanaan putaran benih sebesar 11,2 juta dolar AS pada Juli 2024, dengan investor termasuk Polychain Capital, Borderless Capital, Finality Capital, Hashkey, dan sejumlah investor malaikat terkenal, seperti Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda), dan Trevor. Dana tersebut akan digunakan terutama untuk mendorong pembangunan jaringan AI Chain @OpenLedger , mekanisme insentif model, lapisan dasar data, dan aplikasi ekosistem Agent secara menyeluruh.

@OpenLedger didirikan oleh Ram Kumar, yang merupakan kontributor inti dari #OpenLedger , sekaligus seorang pengusaha yang tinggal di San Francisco, dengan dasar teknis yang kuat di bidang AI/ML dan teknologi blockchain. Dia membawa kombinasi wawasan pasar, keahlian teknis, dan kepemimpinan strategis ke proyek. Ram pernah memimpin sebuah perusahaan R&D blockchain dan AI/ML, dengan pendapatan tahunan lebih dari 35 juta dolar, dan memainkan peran penting dalam mendorong kolaborasi kunci, termasuk proyek joint venture strategis yang dicapai dengan anak perusahaan Walmart. Dia fokus pada pembangunan ekosistem dan kolaborasi dengan leverage tinggi, berkomitmen untuk mempercepat penerapan praktis di berbagai industri.
Enam, desain model ekonomi token dan tata kelola
$OPEN adalah token fungsional inti dari ekosistem @OpenLedger , memberdayakan tata kelola jaringan, operasi transaksi, distribusi insentif, dan operasi AI Agent, menjadi dasar ekonomi untuk membangun model AI dan data yang dapat beredar secara berkelanjutan di rantai. Saat ini, ekonomi token yang diumumkan secara resmi masih dalam tahap desain awal, dengan detail yang belum sepenuhnya jelas, tetapi dengan proyek yang segera memasuki fase penciptaan token (TGE), pertumbuhan komunitas, aktivasi developer, dan eksperimen skenario aplikasi sedang terus dipercepat di Asia, Eropa, dan Timur Tengah.
Tata kelola dan keputusan: Pemegang Open dapat berpartisipasi dalam pemungutan suara untuk pendanaan model, manajemen Agen, peningkatan protokol, dan penggunaan dana.
Pembayaran bahan bakar dan biaya transaksi: Sebagai token gas asli dari jaringan @OpenLedger , mendukung mekanisme tarif yang disesuaikan untuk AI.
Insentif dan penghargaan kepemilikan: Pengembang yang memberikan data, model, atau layanan berkualitas tinggi dapat memperoleh pembagian Open berdasarkan dampak penggunaan.
Kemampuan jembatan lintas rantai: Open mendukung jembatan L2 ↔ L1 (Ethereum), meningkatkan ketersediaan model dan Agen di berbagai rantai.
Mekanisme staking AI Agent: Operasi AI Agent memerlukan staking $OPEN , kinerja yang buruk akan mengurangi staking, mendorong output layanan yang efisien dan dapat dipercaya.
Berbeda dengan banyak protokol tata kelola token yang terkait dengan pengaruh dan jumlah token yang dipegang, @OpenLedger memperkenalkan mekanisme tata kelola yang berbasis pada nilai kontribusi. Bobot suara terkait dengan nilai yang diciptakan secara nyata, bukan hanya bobot modal, mengutamakan kontributor yang terlibat dalam pembangunan, pengoptimalan, dan penggunaan model dan dataset. Desain arsitektur ini membantu mewujudkan keberlanjutan jangka panjang dalam tata kelola, mencegah perilaku spekulatif mendominasi keputusan, benar-benar sesuai dengan visi ekonomi AI terdesentralisasi yang “transparan, adil, dan didorong oleh komunitas”.
Tujuh, pasar data, model, dan insentif serta perbandingan pesaing
@OpenLedger sebagai infrastruktur insentif untuk model “AI yang dapat dibayar” (Payable AI), bertujuan untuk memberikan jalur monetisasi yang dapat diverifikasi, dapat dimiliki, dan berkelanjutan untuk kontributor data dan pengembang model. Ini mengelilingi penerapan di rantai, insentif pemanggilan, dan mekanisme kombinasi agen, membangun sistem modul dengan karakteristik yang berbeda, menjadikannya unik di jalur Crypto AI saat ini. Meskipun belum ada proyek yang sepenuhnya tumpang tindih dalam arsitektur keseluruhan, dalam dimensi kunci seperti insentif protokol, ekonomi model, dan kepastian data, OpenLedger menunjukkan kesamaan yang tinggi dan potensi kolaborasi dengan beberapa proyek representatif.
Lapisan insentif protokol: OpenLedger vs. Bittensor
Bittensor adalah jaringan AI terdesentralisasi yang paling representatif saat ini, membangun sistem kolaborasi multi-peran yang didorong oleh subnet (Subnet) dan mekanisme penilaian, dengan token $TAO mendorong model, data, dan node peringkat lainnya. Sebaliknya,@OpenLedger Fokus pada penerapan di rantai dan pembagian keuntungan dari pemanggilan model, menekankan arsitektur ringan dan mekanisme kolaborasi Agen. Meskipun logika insentif keduanya tumpang tindih, tetapi perbedaan jelas dalam lapisan tujuan dan kompleksitas sistem: Bittensor berfokus pada jaringan dasar kemampuan AI yang umum,@OpenLedger berfungsi sebagai platform untuk menghubungkan nilai di lapisan aplikasi AI.
Kepemilikan model dan insentif pemanggilan: OpenLedger vs. Sentient
Konsep “OML (Open, Monetizable, Loyal) AI” yang diajukan oleh Sentient memiliki kesamaan dalam kepastian model dan kepemilikan komunitas dengan @OpenLedger Beberapa pemikiran serupa, menekankan identifikasi kepemilikan dan pelacakan pendapatan melalui Model Fingerprinting. Perbedaannya adalah, Sentient lebih fokus pada tahap pelatihan dan generasi model, sedangkan @OpenLedger Fokus pada penerapan, pemanggilan, dan mekanisme pembagian keuntungan model di rantai, keduanya masing-masing berada di hulu dan hilir rantai nilai AI, memiliki sifat saling melengkapi.
Platform hosting model dan inferensi yang dapat dipercaya: OpenLedger vs. OpenGradient
OpenGradient berfokus pada pembangunan kerangka pelaksanaan inferensi yang aman berbasis TEE dan zkML, menyediakan layanan hosting model dan inferensi terdesentralisasi, berfokus pada lingkungan operasi yang dapat dipercaya di level dasar. Sebaliknya,@OpenLedger lebih menekankan jalur penangkapan nilai setelah penerapan di rantai, membangun siklus lengkap “pelatihan—penerapan—pemanggilan—pembagian keuntungan” sekitar Model Factory, OpenLoRA, PoA, dan Datanets. Keduanya berada pada siklus hidup model yang berbeda: OpenGradient lebih fokus pada keandalan operasi, OpenLedger lebih fokus pada insentif keuntungan dan kombinasi ekosistem, dengan ruang saling melengkapi yang tinggi.
Model crowdsourcing dan insentif evaluasi: OpenLedger vs. CrunchDAO
CrunchDAO berfokus pada mekanisme kompetisi terdesentralisasi untuk model prediksi keuangan, mendorong komunitas untuk mengirimkan model dan mendapatkan imbalan berdasarkan kinerja, cocok untuk skenario vertikal tertentu. Sebaliknya,@OpenLedger Menyediakan pasar model yang dapat disusun dan kerangka penyebaran yang terpadu, dengan lebih banyak kegunaan yang lebih luas dan kemampuan monetisasi asli di rantai, cocok untuk pengembangan berbagai jenis agen cerdas. Keduanya saling melengkapi dalam logika insentif model, dengan potensi kolaborasi.
Platform model ringan yang didorong oleh komunitas: OpenLedger vs. Assisterr
Assisterr dibangun di atas Solana, mendorong komunitas untuk membuat model bahasa kecil (SLM), dan meningkatkan frekuensi penggunaan melalui alat tanpa kode dan mekanisme insentif $sASRR. Sebaliknya,@OpenLedger lebih menekankan jalur penelusuran dan pembagian keuntungan tertutup antara data-model-pemanggilan, memanfaatkan PoA untuk mewujudkan pembagian insentif yang terperinci. Assisterr lebih cocok untuk komunitas kolaborasi model dengan ambang batas rendah,@OpenLedger berkomitmen untuk membangun infrastruktur model yang dapat digunakan kembali dan dapat disusun.
Pabrik Model: OpenLedger vs. Pond
Pond dan @OpenLedger juga menyediakan modul “Model Factory”, tetapi orientasi dan layanan mereka sangat berbeda. Pond berfokus pada pemodelan perilaku berbasis jaringan saraf grafis (GNN) di rantai, terutama ditujukan untuk peneliti algoritma dan ilmuwan data, dan mendorong pengembangan model melalui mekanisme kompetisi, Pond lebih condong ke kompetisi model; OpenLedger berfokus pada fine-tuning model bahasa (seperti LLaMA, Mistral), melayani pengembang dan pengguna non-teknis, menekankan pengalaman tanpa kode dan mekanisme pembagian keuntungan otomatis di rantai, membangun ekosistem insentif model AI yang berbasis data, OpenLedger lebih condong ke kolaborasi data.
Jalur inferensi yang dapat dipercaya: OpenLedger vs. Bagel
Bagel meluncurkan kerangka ZKLoRA, memanfaatkan model fine-tuning LoRA dan teknologi zero-knowledge proof (ZKP), untuk mewujudkan verifikasi enkripsi dari proses inferensi off-chain, memastikan eksekusi inferensi yang benar. Sementara itu,@OpenLedger mendukung penerapan dan pemanggilan dinamis model fine-tuning LoRA melalui OpenLoRA, sekaligus menyelesaikan masalah verifikasi inferensi dari sudut pandang yang berbeda —— dengan melampirkan bukti kepemilikan (Proof of Attribution, PoA) pada setiap keluaran model, melacak sumber data yang menjadi dasar inferensi dan pengaruhnya. Ini tidak hanya meningkatkan transparansi tetapi juga memberikan insentif kepada kontributor data berkualitas tinggi, dan memperkuat keterjelasan dan kredibilitas proses inferensi. Singkatnya, Bagel berfokus pada verifikasi kebenaran hasil kalkulasi, sementara @OpenLedger melalui mekanisme kepemilikan mewujudkan pelacakan tanggung jawab dan keterjelasan dalam proses inferensi.
Jalur kolaborasi sisi data: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien dan FractionAI menyediakan layanan penandaan data terdesentralisasi, Vana dan Irys berfokus pada kedaulatan data dan mekanisme kepemilikan.@OpenLedger melalui modul Datanets + PoA, mewujudkan pelacakan penggunaan data berkualitas tinggi dan distribusi insentif di rantai. Yang pertama dapat berfungsi sebagai suplai data hulu,@OpenLedger sebagai pusat distribusi nilai dan pemanggilan, ketiga memiliki kolaborasi yang baik dalam rantai nilai data, bukan hubungan kompetitif.
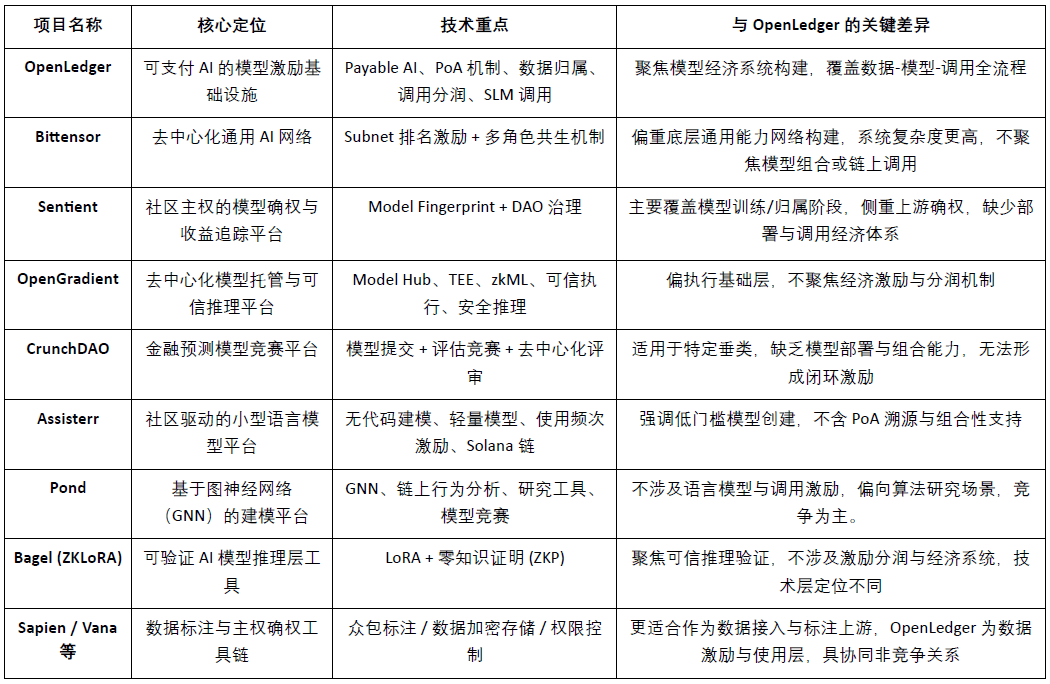
Secara keseluruhan, @OpenLedger berada di posisi lapisan tengah “aset model di rantai dan insentif pemanggilan” dalam ekosistem Crypto AI saat ini, dapat terhubung ke atas ke jaringan pelatihan dan platform data, serta melayani lapisan Agen dan aplikasi akhir di bawah, menjadi protokol jembatan kunci yang menghubungkan penyediaan nilai model dan pemanggilan di lapangan.
Delapan, kesimpulan | Dari data ke model, jalan monetisasi rantai AI
#OpenLedger berkomitmen untuk menciptakan infrastruktur “model sebagai aset” di dunia Web3, dengan membangun siklus lengkap dari penerapan di rantai, insentif pemanggilan, konfirmasi kepemilikan, dan kombinasi agen, untuk pertama kalinya membawa model AI ke dalam sistem ekonomi yang benar-benar dapat dilacak, dapat dimonetisasi, dan dapat berkolaborasi. Di sekitar Model Factory, OpenLoRA, PoA, dan Datanets, sistem teknologinya memberikan alat pelatihan dengan ambang rendah bagi pengembang, memberikan jaminan kepemilikan imbalan bagi kontributor data, dan menyediakan mekanisme pemanggilan dan pembagian keuntungan model yang dapat disusun bagi pihak aplikasi, secara menyeluruh mengaktifkan sumber daya “data” dan “model” yang sering diabaikan di kedua ujung rantai nilai AI.
#OpenLedger lebih menyerupai gabungan HuggingFace + Stripe + Infura di dunia Web3, menyediakan hosting model, penagihan pemanggilan, dan antarmuka API yang dapat disusun di rantai. Dengan percepatan tren aset data, otonomi model, dan modularitas agen, OpenLedger diharapkan menjadi pusat penting di bawah model “AI yang dapat dibayar”.