
🧠 A Simple Question That Broke Web3 Storage
Let’s start with a question that sounds innocent…
but quietly destroys most decentralized storage designs.
👉 Why does storing 1 GB of data often require 10–25 GB of actual storage?
That question is the replication trap.
Most decentralized storage networks solve availability by copying data again… and again… and again.
It works — but at a brutal cost.
Storage becomes:
❌ Expensive
❌ Inefficient
❌ Hard to scale
❌ Fragile under churn
And worst of all:
the more decentralized the network becomes, the worse the problem gets.
This is where Walrus Protocol enters — not as “another storage project,” but as a mathematical correction to how decentralized storage has been done so far.
This article explains why Walrus exists, what exactly it fixes, and how it escapes the replication trap without breaking decentralization — using ideas most people never see explained properly.
All technical grounding is taken directly from the Walrus whitepaper
🪤 The Replication Trap (Why Old Models Don’t Scale)
📦 What Replication Really Means
In classic decentralized storage systems, availability is achieved by copying the same file across many nodes.
Example:
Want “extreme safety”?
Store 25 copies of the same file.
That gives “12 nines” of durability — but also:
💾 25× storage overhead
🌐 Massive bandwidth usage
💸 Huge long-term cost
Sounds fine… until the network grows.
📉 Decentralization Makes Replication Worse
Here’s the paradox:
• More nodes = more decentralization
• More nodes = higher replication needed
• Higher replication = exploding cost
This is why:
Many networks cap node counts
Others rely on hidden centralization
Some quietly accept inefficiency as “the price of security”
Walrus refuses that compromise.
🔬 Why Reed-Solomon Encoding Wasn’t Enough
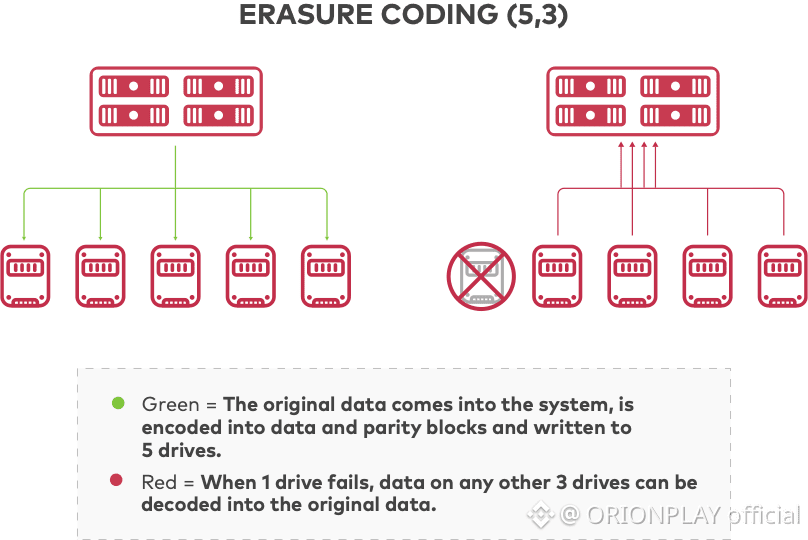
Some systems tried to escape replication using Reed-Solomon (RS) erasure coding.
RS encoding:
Splits data into fragments
Allows recovery from a subset
Reduces storage overhead (≈3× instead of 25×)
So why isn’t that enough?
⚠️ Two Big Problems with RS Encoding
Recovery is expensive
When a node disappears, rebuilding its data requires downloading the entire file.Churn kills efficiency
In open networks, nodes leave often.
Each exit triggers huge recovery traffic.
Result:
RS saves space
RS bleeds bandwidth
RS struggles at scale
Walrus needed something else.
🟥 Red Stuff: The Breakthrough Walrus Is Built On
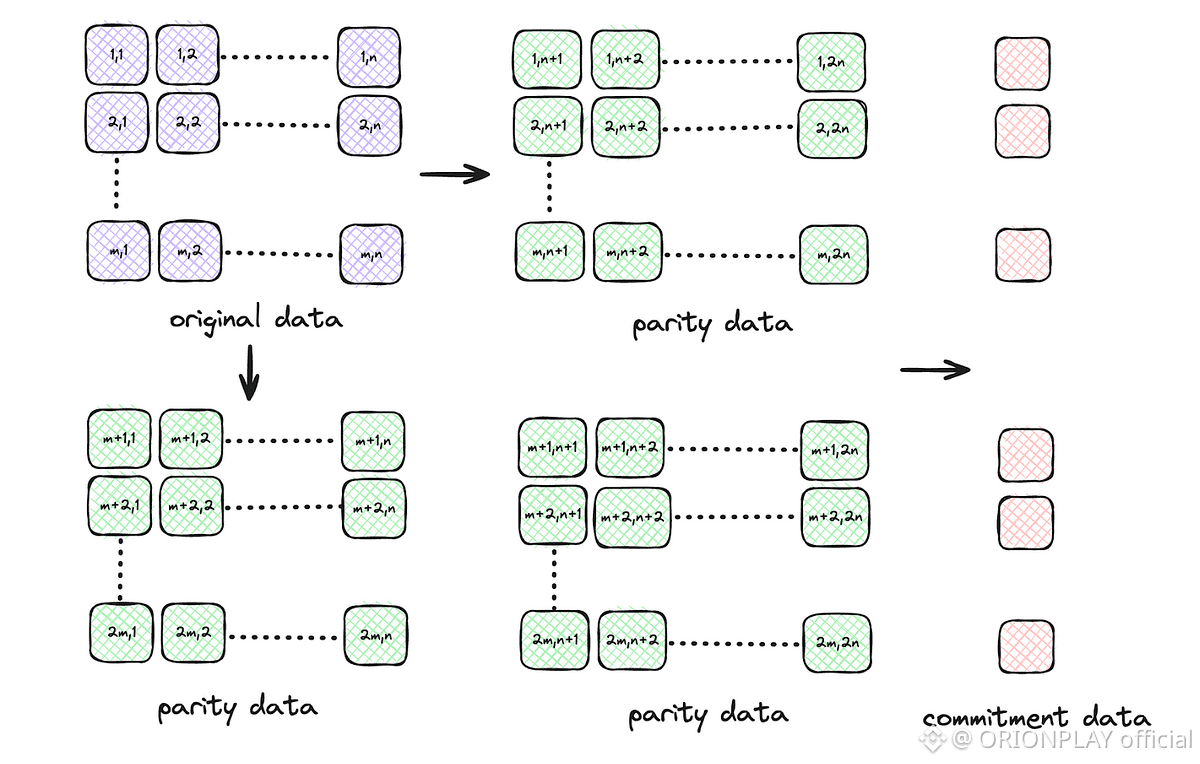
Walrus introduces a new encoding system called Red Stuff.
This is not marketing fluff.
It’s a new category of erasure coding.
🧩 The Core Idea (Explained Simply)
Instead of slicing data in one dimension, Walrus slices it in two dimensions.
Think of your data like a spreadsheet:
Col 1Col 2Col 3Row 1DataDataDataRow 2DataDataDataRow 3DataDataData
Now:
Rows are encoded
Columns are encoded
Every node stores one row + one column
This creates:
Primary slivers
Secondary slivers
Together, they allow recovery even when parts disappear.
⚡ Why Red Stuff Is Faster
Unlike Reed-Solomon, Red Stuff:
Uses fountain codes
Relies mostly on XOR operations
Avoids heavy polynomial math
Result:
Encoding large files in one pass
Much lower CPU cost
Practical for very large blobs
🔁 Recovery Without Downloading Everything (The Killer Feature)
Here’s the magic.
Traditional Recovery:
“A node is gone?
Download the entire file again.”
Walrus Recovery:
“Only the missing pieces are rebuilt.”
Bandwidth cost becomes:
O(|blob| / n)
instead ofO(|blob|)
This is what allows:
Constant churn
Permissionless nodes
Long-lived storage without bandwidth collapse
This single property is why Walrus can scale without punishing growth
🧠 Byzantine Reality: When Nodes Lie
Most explanations stop here — but Walrus goes further.
The Real Problem:
What if:
Nodes lie?
Writers upload inconsistent data?
Some storage providers cheat?
Walrus is built for Byzantine environments by default.
🛡️ Commitments Everywhere
Every sliver:
Has a cryptographic commitment
Is verified independently
Is tied back to a single blob commitment
Readers:
Reconstruct the blob
Re-encode it
Re-check commitments
If anything doesn’t match:
👉 The read fails safely
No silent corruption. No “trust me” nodes.
🔗 Why Walrus Uses a Blockchain (But Doesn’t Become One)
Walrus uses a blockchain only as a control plane, not as a data layer.
What the chain does:
Registers blobs
Manages epochs
Enforces commitments
Handles incentives
What it does NOT do:
Store blob data
Replicate large files
Slow down reads
This separation is crucial — and rarely explained well.
📍 Point of Availability (PoA): A Quiet Innovation
Walrus introduces the Point of Availability.
PoA means:
Enough nodes have proven storage
The blob is now officially “live”
The writer can safely disappear
From that moment:
Readers are guaranteed recovery
Nodes are obligated to store data
Incentives and penalties apply
This turns storage into a verifiable service, not a promise
😄 A Quick Analogy (Because Brains Like Stories)
Imagine storing a movie:
Old systems:
🎥 Make 25 full DVDs
📦 Store each in a different city
Walrus:
🎥 Cut the movie into puzzle pieces
🧩 Spread rows and columns everywhere
🦭 Lose some cities? Still watch the movie
Same safety.
Far less waste.
🧠 Why This Matters More Than It Sounds
Walrus isn’t just “cheaper storage.”
It enables:
🧠 AI dataset provenance
🖼️ NFT data integrity
🧾 Rollup data availability
🌍 Civic & public-interest data
🧪 Scientific reproducibility
Anywhere data must survive distrust, Walrus fits naturally.

