Saya baru saja menemukan sebuah diskusi tentang keamanan AI, yang benar-benar membuat saya berhenti dan membacanya berulang kali. Bukan masalah lama di mana model langsung gagal, tetapi lebih kepada yang lebih licik, semuanya tampak baik-baik saja, demo berjalan lancar, online stabil, lalu suatu hari ia secara diam-diam menyimpang sedikit, dan Anda sama sekali tidak dapat menangkap dari hari mana itu mulai terkontaminasi. Inilah yang membuat Data Poisoning benar-benar menakutkan.
Akhir-akhir ini Inference Labs terus menekankan drift, saya sebelumnya sering melewatkan kata ini, sampai saya membaca konten dari grup TruthTensor mereka, baru saya sadar sepenuhnya. Dengan prompt yang sama, data yang sama, dalam jangka pendek semuanya terlihat normal, tetapi begitu kita memperpanjang waktu, perilaku model perlahan-lahan berubah. Bukan karena parameter yang rusak, tetapi dunia itu sendiri berubah, dan model mengikuti perubahan tersebut. Anda mengevaluasi model kemarin, tetapi setelah diluncurkan, Anda menghadapi dunia hari ini, sementara risikonya tersembunyi di hari esok.
Jadi saya ingin membahas Data Poisoning, tetapi tidak ingin memulai dari metode serangan, saya ingin membahas satu masalah yang lebih realistis, mengingat dunia nyata sudah pasti akan mengalir, mengapa keamanan tetap bersifat sekali jalan? Menjalani satu putaran tim merah, mengeluarkan satu laporan, menyimpannya dalam arsip, lalu mengumumkan aman? Sejujurnya, saya semakin tidak percaya pada proses semacam ini.
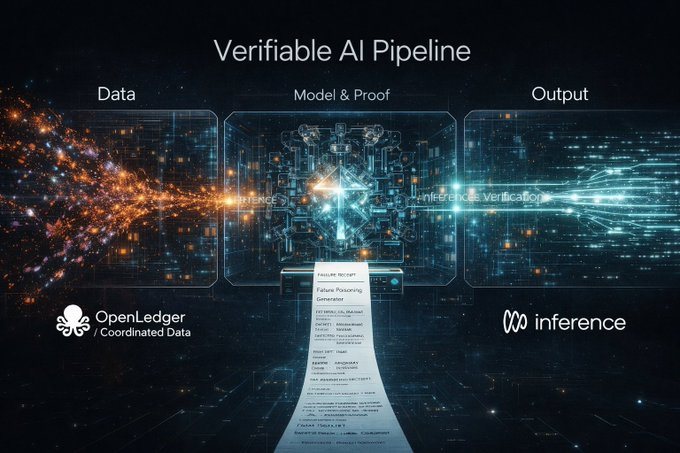
Kejadian ini tepat bertabrakan dengan jalur hari ini dari @inference_labs. Mereka berkolaborasi dengan mitra baru @OpenledgerHQ, menempatkan koordinasi data pelatihan dan pengambilan yang dapat dipercaya pada hulu, sementara Inference Labs bertanggung jawab atas lapisan verifikasi model dan inferensi. Dari data ke model hingga hasil inferensi, untuk pertama kalinya dipecah menjadi satu jalur yang sepenuhnya dapat diaudit. Langkah ini sebenarnya jauh lebih penting daripada hanya mengatur parameter model agar lebih kuat.
Justru karena ada lapisan data ini, makna tim merah menjadi benar-benar lengkap. Banyak orang berbicara tentang Data Poisoning dengan asumsi hanya menyerang model, tetapi di dunia nyata, yang pertama kali terkontaminasi sering kali adalah data. Jika data hulu dapat dilacak, inferensi tengah dapat diverifikasi, target serangan tim merah menjadi seluruh saluran, dan batas keamanan dianggap tertutup.
Ditambah dengan DSperse, sistem ini benar-benar dapat diterapkan. Ini bukan tentang menghantam seluruh model besar, tetapi membagi verifikasi menjadi bagian-bagian, seperti memeriksa suku cadang mobil satu per satu, bukan langsung menabrak mobil utuh ke dinding. Ini sangat penting bagi tim merah, karena Data Poisoning sering kali bukan tentang merobek model, tetapi diam-diam memutar setir sedikit di beberapa bagian.
Saya selalu merasa sangat aneh bahwa laporan tim merah sekarang pada dasarnya hanya menceritakan kisah. Sebuah PDF, beberapa deskripsi, beberapa tangkapan layar, pada akhirnya tetap membuat orang percaya kepada Anda. Tapi Inference Labs sudah menjadikan proses inferensi sebagai bukti yang dapat diverifikasi, data hulu juga bergerak ke arah yang dapat diverifikasi, lalu mengapa bukti serangan masih terjebak pada tahap narasi? Ini benar-benar terputus.
Jadi saya memberi ide ini nama yang sangat sederhana tetapi berguna, Failure Receipt, struk kegagalan. Tanpa struk, keamanan lebih mirip rumor, tidak seperti penemuan ilmiah.
Menurut saya, satu struk kegagalan yang memenuhi syarat sebenarnya sangat sederhana, yaitu membuat orang lain dapat mereproduksi kegagalan yang Anda katakan, menunjukkan sidik jari komitmen model, hash komitmen input, status dunia drift saat pemicu, kategori spesifik dari kegagalan, dan akhirnya memberikan satu perintah untuk bisa dijalankan. Kegagalan yang tidak dapat dijalankan, saya sangat sulit untuk menganggapnya sebagai kerentanan.
Jika Inference Labs benar-benar ingin menjadikan kompetisi tim merah sebagai mekanisme yang terhubung, proses yang paling ingin saya lihat sebenarnya sangat langsung, pertama-tama mengajukan hash dari struk kegagalan, sekaligus mengesampingkan sejumlah uang, setelah periode jendela berakhir, sample dan skrip reproduksi dipublikasikan, validator jaringan menggunakan DSperse untuk menjalankan ulang secara tersegmentasi, berhasil baru diselesaikan, gagal langsung membakar deposit. Ini terdengar tidak lembut, tetapi paling efektif untuk mencegah penyalahgunaan.
Tentu saja, pasti ada jebakan kerentanan sampah yang akan merajalela, pencurian sampel akan terjadi, publikasi terlalu dini akan membuat penyerang belajar lebih cepat. Oleh karena itu, commit-reveal dan pengungkapan tertunda sangat penting, pertama-tama buktikan adanya jalur yang dapat direproduksi, detailnya nanti dirilis, memberi waktu untuk perbaikan.
Saya sangat berharap fungsi reward dapat ditambahkan satu indikator yang menunjukkan apakah kegagalan ini ada hubungannya dengan drift. Di lingkungan statis, sebenarnya banyak kerentanan yang dapat direproduksi sembarangan, tetapi yang dapat dipicu secara stabil dalam dunia yang mengalir, itulah yang benar-benar langka. Evaluasi dinamis TruthTensor terhubung ke seluruh saluran yang dapat dipercaya, sebenarnya sudah mengisyaratkan bahwa keamanan AI di masa depan bukanlah pertahanan titik tunggal, tetapi adalah jalur pertempuran yang berkelanjutan.
@inference_labs jika kalian benar-benar ingin mendorong kompetisi tim merah ke arah mekanisme, dalam saluran data OpenLedger ini, kalian mengelola model dan inferensi yang dapat diverifikasi, bagian mana yang akan kalian standardisasi terlebih dahulu?
A. Format kegagalan
B. Kurva reward
C. Mekanisme pengungkapan dan penundaan publik
D. Lingkungan reproduksi drift (drift harness)
Secara pribadi, saya paling condong ke D. Tidak ada dunia yang dapat direproduksi secara seragam oleh semua orang, seindah apa pun strukturnya, hanya dapat mereproduksi emosi.
Jika Anda merasa ide struk kegagalan ini berguna, cukup balas dengan satu huruf, saya ingin melihat apa yang menurut semua orang kurang dalam saluran AI yang dapat diverifikasi ini.