I. Introduzione | Salto di livello del modello nell'intelligenza artificiale crittografica
Dati, modelli e potenza di calcolo sono i tre elementi fondamentali dell'infrastruttura di intelligenza artificiale, analogamente al carburante (dati), al motore (modello) e all'energia (potenza di calcolo): tutti elementi indispensabili. Analogamente al percorso di evoluzione infrastrutturale del settore dell'intelligenza artificiale tradizionale, anche il settore della Crypto AI ha attraversato una fase analoga. All'inizio del 2024, il mercato era dominato da progetti GPU decentralizzati (Akash, Render, io.net, ecc.), che generalmente enfatizzavano una logica di crescita approssimativa basata sulla "competizione per la potenza di calcolo". Tuttavia, dopo l'ingresso nel 2025, l'attenzione del settore si è gradualmente spostata verso l'alto, verso i livelli di modello e dati, segnando la transizione della Crypto AI dalla competizione per le risorse sottostanti alla costruzione di un livello intermedio più sostenibile e orientato al valore applicativo.
Modelli generali (LLM) vs modelli specializzati (SLM)
L'addestramento di modelli linguistici di grandi dimensioni (LLM) tradizionali dipende fortemente da set di dati su larga scala e architetture distribuite complesse, con una scala di parametri che varia da 70B a 500B. Il costo di un singolo addestramento può raggiungere milioni di dollari. D'altra parte, SLM (Specialized Language Model) è un paradigma di fine-tuning leggero per modelli di base riutilizzabili, solitamente basato su modelli open source come LLaMA, Mistral, DeepSeek, combinando pochi dati professionali di alta qualità e tecnologie come LoRA per costruire rapidamente modelli di esperti con conoscenze specifiche di dominio, riducendo significativamente i costi di addestramento e le barriere tecnologiche.
È importante notare che gli SLM non verranno integrati nei pesi degli LLM, ma collaboreranno con gli LLM tramite architetture di agenti, sistemi di plugin per instradamento dinamico, hot-swapping di moduli LoRA, e RAG (generazione aumentata da recupero). Questa architettura conserva la capacità di ampia copertura degli LLM, mentre i moduli di fine-tuning migliorano le prestazioni specialistiche, formando un sistema intelligente altamente flessibile e combinato.
Crypto AI nei livelli di valore e confini dei modelli
I progetti Crypto AI, per loro natura, sono difficili da elevare direttamente alle capacità core dei modelli di linguaggio di grandi dimensioni (LLM), la ragione principale è che
Barriere tecnologiche elevate: la scala dei dati, le risorse di calcolo e le capacità ingegneristiche richieste per addestrare un Foundation Model sono enormi. Attualmente, solo i giganti tecnologici degli Stati Uniti (OpenAI, ecc.) e della Cina (DeepSeek, ecc.) possiedono le capacità necessarie.
Limitazioni dell'ecosistema open source: sebbene modelli di base mainstream come LLaMA e Mixtral siano stati resi open source, la vera spinta per il superamento dei modelli rimane concentrata presso istituti di ricerca e sistemi di ingegneria closed-source. Gli spazi di partecipazione dei progetti on-chain a livello di modelli principali sono limitati.
Tuttavia, al di sopra dei modelli di base open source, i progetti Crypto AI possono ancora estendere il valore specializzando i modelli linguistici (SLM) e combinando la verificabilità e i meccanismi di incentivazione di Web3. Come “livello di interfaccia” della catena di valore AI, si concretizza in due direzioni principali:
Livello di verifica affidabile: attraverso la registrazione on-chain del percorso di generazione dei modelli, del contributo dei dati e dell'utilizzo, si migliora la tracciabilità e la resistenza alla manomissione delle uscite AI.
Meccanismo di incentivazione: utilizzando il token nativo per incentivare il caricamento dei dati, le chiamate ai modelli e l'esecuzione degli agenti, costruendo un ciclo positivo per l'addestramento e il servizio dei modelli.
Classificazione dei tipi di modelli AI e analisi dell'idoneità alla blockchain

Pertanto, si può notare che i progetti di tipo Crypto AI si concentrano principalmente sul fine-tuning leggero di SLM di piccole dimensioni, sull'accesso ai dati on-chain e sulla verifica della struttura RAG, nonché sul dispiegamento locale dei modelli Edge e sugli incentivi. Combinando la verificabilità della blockchain e i meccanismi token, Crypto può offrire un valore unico a questi scenari di modelli con risorse medio-basse, formando un valore differenziato per il “livello di interfaccia” AI.
La blockchain AI basata su dati e modelli può registrare chiaramente e in modo immutabile l'origine dei contributi di ciascun dato e modello, migliorando notevolmente l'affidabilità dei dati e la tracciabilità dell'addestramento dei modelli. Inoltre, attraverso meccanismi di smart contract, quando i dati o i modelli vengono chiamati, si attiva automaticamente la distribuzione delle ricompense, trasformando i comportamenti AI in valore tokenizzato misurabile e commerciabile, costruendo un sistema di incentivi sostenibile. Inoltre, gli utenti della comunità possono anche utilizzare token per votare sulla performance dei modelli, partecipare alla definizione delle regole e alle iterazioni, perfezionando l'architettura di governance decentralizzata.
Due, panoramica del progetto | La visione della catena AI di OpenLedger
@OpenLedger è uno dei pochi progetti blockchain AI attualmente sul mercato focalizzati sui meccanismi di attribuzione dei dati e dei modelli. Ha proposto per primo il concetto di “Payable AI”, mirato a costruire un ambiente di operazione AI equo, trasparente e combinabile, incentivando i contributori di dati, gli sviluppatori di modelli e i costruttori di applicazioni AI a collaborare sulla stessa piattaforma e a ottenere guadagni on-chain in base ai contributi reali.
@OpenLedger offre un ciclo chiuso completo che va dalla “fornitura di dati” al “dispiegamento di modelli” fino alla “distribuzione dei profitti”, i cui moduli principali includono:
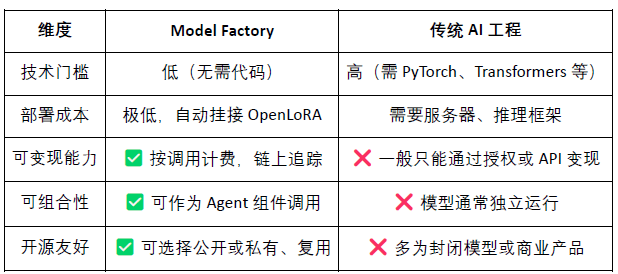
Model Factory: senza programmazione, è possibile utilizzare LoRA per addestrare e distribuire modelli personalizzati basati su LLM open source;
OpenLoRA: supporta la coesistenza di mille modelli, caricandoli dinamicamente secondo necessità, riducendo significativamente i costi di distribuzione;
PoA (Proof of Attribution): realizza la misurazione del contributo e la distribuzione delle ricompense attraverso le registrazioni delle chiamate on-chain;
Datanets: rete di dati strutturati per scenari verticali, costruita e verificata dalla comunità;
Piattaforma di proposta dei modelli (Model Proposal Platform): mercato on-chain di modelli combinabili, chiamabili e pagabili.
Attraverso i moduli sopra, @OpenLedger ha costruito un'infrastruttura economica per agenti “intelligenti” guidata dai dati e combinabile, promuovendo la catena del valore AI verso l'on-chain.
Nel contesto dell'adozione della tecnologia blockchain, @OpenLedger ha costruito un ambiente di esecuzione per dati e contratti ad alte prestazioni, a basso costo e verificabili, basato su OP Stack + EigenDA.
Costruito su OP Stack: basato sullo stack tecnologico di Optimism, supporta un'elevata capacità di elaborazione e un'esecuzione a basso costo;
Liquidazione sulla mainnet di Ethereum: garantisce la sicurezza delle transazioni e l'integrità degli asset;
Compatibile con EVM: facilita agli sviluppatori il dispiegamento e l'espansione rapidi basati su Solidity;
EigenDA fornisce supporto per la disponibilità dei dati: riduce significativamente i costi di archiviazione, garantendo la verificabilità dei dati.
Rispetto a catene AI generali come NEAR, più orientate alle infrastrutture di base e focalizzate sulla sovranità dei dati e sull'architettura “AI Agents on BOS”, @OpenLedger si concentra maggiormente sulla costruzione di catene AI dedicate agli incentivi per dati e modelli, impegnandosi a garantire che lo sviluppo e la chiamata dei modelli possano realizzare un ciclo di valore tracciabile, combinabile e sostenibile on-chain. È un'infrastruttura di incentivazione per modelli nel mondo Web3, combinando hosting di modelli in stile HuggingFace, tariffe di utilizzo in stile Stripe e interfacce composabili on-chain in stile Infura, promuovendo il percorso verso “il modello è un asset”.
Tre, componenti chiave e architettura tecnologica di OpenLedger
3.1 Model Factory, fabbrica di modelli senza codice
ModelFactory è @OpenLedger una piattaforma di fine-tuning per modelli di linguaggio di grandi dimensioni (LLM) nell'ecosistema. A differenza dei tradizionali framework di fine-tuning, ModelFactory offre un'interfaccia puramente grafica, senza necessità di strumenti da riga di comando o integrazione API. Gli utenti possono fine-tunare i modelli basandosi su set di dati autorizzati e verificati completati su @OpenLedger . Ha realizzato un flusso di lavoro integrato per autorizzazione dei dati, addestramento dei modelli e distribuzione, il cui processo chiave include:
Controllo dell'accesso ai dati: gli utenti inviano richieste di dati, i fornitori esaminano e approvano, i dati vengono automaticamente integrati nell'interfaccia di addestramento dei modelli.
Selezione e configurazione del modello: supporta i principali LLM (come LLaMA, Mistral), configurando i parametri tramite GUI.
Fine-tuning leggero: incorpora il motore LoRA / QLoRA, mostrando in tempo reale i progressi dell'addestramento.
Valutazione e distribuzione del modello: strumenti di valutazione integrati, supporta l'esportazione per la distribuzione o la chiamata condivisa nell'ecosistema.
Interfaccia di verifica interattiva: fornisce un'interfaccia di chat, facilitando i test diretti delle capacità di risposta del modello.
Tracciamento dell'origine della generazione RAG: le risposte includono riferimenti alle fonti, aumentando la fiducia e la verificabilità.
L'architettura del sistema Model Factory comprende sei moduli, attraversando autenticazione dell'identità, autorizzazione dei dati, fine-tuning dei modelli, valutazione e distribuzione, e tracciamento RAG, creando una piattaforma di servizi per modelli integrati, sicura e controllabile, interattiva in tempo reale e monetizzabile in modo sostenibile.
La seguente tabella riassume le capacità dei modelli di linguaggio di grandi dimensioni supportati da ModelFactory:
Serie LLaMA: ecosistema più ampio, comunità attiva, prestazioni generali forti, è attualmente uno dei modelli di base open source più mainstream.
Mistral: architettura efficiente, prestazioni di inferenza eccellenti, adatto a scenari di dispiegamento flessibili e risorse limitate.
Qwen: prodotto di Alibaba, ottime prestazioni per compiti in cinese, forte capacità complessiva, adatto come prima scelta per sviluppatori locali.
ChatGLM: effetti di dialogo in cinese eccezionali, adatto a scenari di assistenza clienti verticali e localizzati.
Deepseek: eccelle nella generazione di codice e nel ragionamento matematico, adatto per strumenti di assistenza allo sviluppo intelligente.
Gemma: un modello leggero lanciato da Google, con una struttura chiara, facile da utilizzare e sperimentare rapidamente.
Falcon: un tempo standard di prestazione, adatto per ricerche di base o test comparativi, ma l'attività della comunità è diminuita.
BLOOM: supporta molte lingue, ma le prestazioni di inferenza sono deboli, adatto per ricerche di copertura linguistica.
GPT-2: modello classico e precoce, adatto solo per scopi didattici e di verifica, non consigliato per l'uso pratico.
Sebbene @OpenLedger non includa le più recenti e ad alte prestazioni MoE o modelli multimodali, la sua strategia non è obsoleta ma è una configurazione “pragmatica” fatta in base ai vincoli reali del dispiegamento on-chain (costi di inferenza, adattamento RAG, compatibilità LoRA, ambiente EVM).
Model Factory, come strumento senza codice, ha integrato meccanismi di prova di contributo in tutti i modelli, garantendo i diritti dei contributori di dati e degli sviluppatori di modelli, con vantaggi di bassa barriera, monetizzabilità e combinabilità, rispetto agli strumenti di sviluppo dei modelli tradizionali:
Per gli sviluppatori: offre un percorso completo per incubazione, distribuzione e reddito dei modelli;
Per la piattaforma: forma un'ecosistema di circolazione e combinazione degli asset di modelli;
Per gli utenti: possono combinare e utilizzare i modelli o gli agenti come se stessero chiamando un'API.
3.2 OpenLoRA, assetizzazione dei modelli fine-tunati on-chain
LoRA (Low-Rank Adaptation) è un metodo di fine-tuning parametrico efficiente che apprende nuovi compiti inserendo una “matrice a bassa riga” in un grande modello pre-addestrato, senza modificare i parametri del modello originale, riducendo così drasticamente i costi di addestramento e le esigenze di archiviazione. I modelli di linguaggio di grandi dimensioni tradizionali (come LLaMA, GPT-3) hanno tipicamente decine di miliardi o addirittura centinaia di miliardi di parametri. Per utilizzarli per compiti specifici (come domande legali, consultazioni mediche), è necessario un fine-tuning. La strategia principale di LoRA è: “congelare i parametri del grande modello originale, allenare solo la matrice di nuovi parametri inseriti.”, i suoi parametri sono efficienti, l'addestramento è rapido, e il dispiegamento è flessibile, rendendolo il metodo di fine-tuning più adatto per il dispiegamento e la chiamata combinata di modelli Web3.
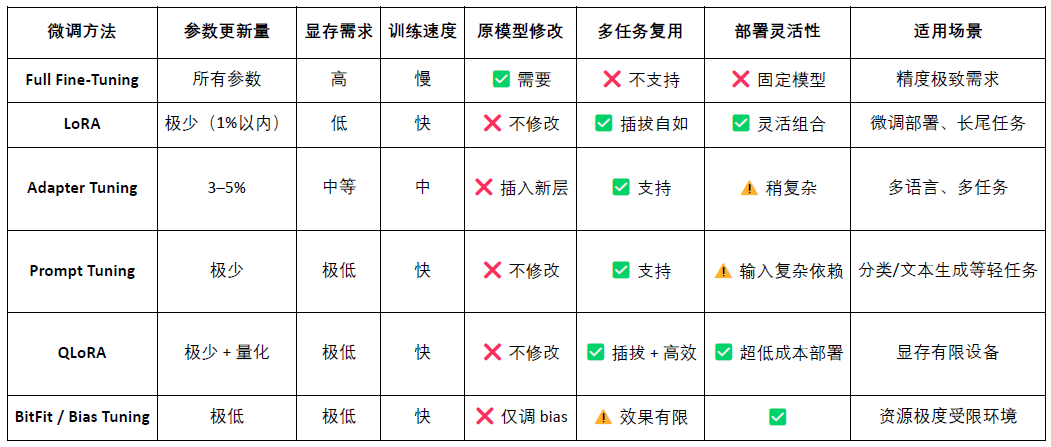
OpenLoRA è @OpenLedger un framework di inferenza leggero progettato appositamente per il dispiegamento di più modelli e la condivisione delle risorse. Il suo obiettivo principale è risolvere i problemi comuni associati al dispiegamento dei modelli AI, come l'alto costo, la bassa riutilizzabilità e lo spreco di risorse GPU, promuovendo l'esecuzione di “AI Pagabile” (Payable AI).
Il sistema architetturale centrale di OpenLoRA è basato su un design modulare, coprendo memorizzazione dei modelli, esecuzione dell'inferenza, instradamento delle richieste e altri passaggi chiave, realizzando capacità di dispiegamento e chiamata di più modelli in modo efficiente e a basso costo:
Modulo di memorizzazione degli adattatori LoRA (LoRA Adapters Storage): gli adattatori LoRA fine-tunati vengono ospitati su @OpenLedger , consentendo il caricamento su richiesta, evitando di pre-caricare tutti i modelli nella memoria e risparmiando risorse.
Strato di hosting dei modelli e fusione dinamica (Model Hosting & Adapter Merging Layer): tutti i modelli fine-tunati condividono il modello di base (base model), durante l'inferenza, gli adattatori LoRA vengono fusi dinamicamente, supportando inferenze congiunte di più adattatori (ensemble) per migliorare le prestazioni.
Motore di inferenza (Inference Engine): integra ottimizzazioni CUDA come Flash-Attention, Paged-Attention e SGMV.
Modulo di instradamento delle richieste e output in streaming (Request Router & Token Streaming): instrada dinamicamente il modello richiesto all'adattatore corretto in base alla richiesta, implementando la generazione in streaming a livello di token attraverso un kernel ottimizzato.
Il processo di inferenza di OpenLoRA appartiene a un servizio di modello “maturo e generico” a livello tecnico, come segue:
Caricamento dei modelli di base: il sistema pre-carica modelli di base come LLaMA 3, Mistral nella memoria GPU.
Recupero dinamico di LoRA: dopo aver ricevuto una richiesta, carica dinamicamente l'adattatore LoRA specificato da Hugging Face, Predibase o una directory locale.
Attivazione della fusione degli adattatori: attraverso l'ottimizzazione del kernel, unisce l'adattatore e il modello di base in tempo reale, supportando inferenze congiunte di più adattatori.
Esecuzione dell'inferenza e output in streaming: il modello fuso inizia a generare risposte, utilizzando output in streaming a livello di token per ridurre la latenza, combinando la quantificazione per garantire efficienza e precisione.
Fine dell'inferenza e rilascio delle risorse: dopo il completamento dell'inferenza, scarica automaticamente l'adattatore e libera le risorse di memoria. Garantisce che possa servire efficientemente migliaia di modelli fine-tunati in una singola GPU, supportando un'efficiente rotazione dei modelli.
OpenLoRA ha significativamente migliorato l'efficienza del dispiegamento e dell'inferenza di più modelli attraverso una serie di tecniche di ottimizzazione di base. Il suo nucleo comprende il caricamento dinamico degli adattatori LoRA (JIT loading), riducendo efficacemente l'occupazione della memoria; parallelismo dei tensori (Tensor Parallelism) e attenzione paginata (Paged Attention) per gestire alte concorrenze e testi lunghi; supporto per la fusione di più modelli (Multi-Adapter Merging) per eseguire inferenza combinata LoRA (ensemble); e infine, attraverso Flash Attention, kernel CUDA precompilati e tecnologie di quantificazione FP8/INT8, ottimizzando ulteriormente le prestazioni di inferenza e riducendo la latenza. Questi ottimizzazioni permettono a OpenLoRA di servire efficientemente migliaia di modelli fine-tunati in un ambiente a singola scheda, bilanciando prestazioni, scalabilità e utilizzo delle risorse.
OpenLoRA non è solo un framework di inferenza LoRA efficiente, ma integra profondamente l'inferenza dei modelli con i meccanismi di incentivazione di Web3, mirato a rendere i modelli LoRA chiamabili, combinabili e distribuiti in modo sostenibile come asset Web3.
Il modello come asset (Model-as-Asset): OpenLoRA non è solo un modello di distribuzione, ma conferisce a ciascun modello fine-tunato un'identità on-chain (Model ID), legando il suo comportamento di chiamata agli incentivi economici, realizzando “chiamata e distribuzione dei profitti”.
Combinazione dinamica di più LoRA + attribuzione dei profitti: supporta chiamate dinamiche di combinazione di più adattatori LoRA, consentendo a diverse combinazioni di modelli di formare nuovi servizi per agenti, mentre il sistema può basarsi sul meccanismo PoA (Proof of Attribution) per distribuire con precisione i profitti per ogni adattatore in base al volume delle chiamate.
Supporto per inferenza “multi-tenant” dei modelli a lungo termine: attraverso meccanismi di caricamento dinamico e rilascio della memoria, OpenLoRA può servire migliaia di modelli LoRA in un ambiente a singola scheda, particolarmente adatto a modelli di nicchia Web3, assistenti AI personalizzati e altri scenari di alta riutilizzabilità e chiamate a bassa frequenza.

Inoltre, @OpenLedger ha pubblicato le sue prospettive future sui parametri di prestazione di OpenLoRA, rispetto ai tradizionali modelli a parametri interi, l'occupazione della memoria è stata ridotta drasticamente a 8-12GB; il tempo teorico di commutazione del modello potrebbe scendere sotto i 100ms; la capacità di elaborazione può raggiungere 2000+ tokens/sec; la latenza è controllata tra 20-50ms. In generale, questi parametri di prestazione sono tecnicamente raggiungibili, ma più vicini a “prestazioni di limite superiore”; nell'ambiente di produzione reale, le prestazioni potrebbero essere influenzate da hardware, strategie di programmazione e complessità scenica, dovrebbero essere considerate come “limite ideale” piuttosto che “stabilità quotidiana”.
3.3 Datanets (rete di dati), dalla sovranità dei dati all'intelligenza dei dati
Dati di alta qualità e specifici del dominio diventano elementi chiave per costruire modelli ad alte prestazioni. Datanets è @OpenLedger un'infrastruttura per “i dati sono asset”, utilizzata per raccogliere e gestire set di dati specifici di dominio, per aggregare, verificare e distribuire dati di dominio specifico attraverso una rete decentralizzata, fornendo fonti di dati di alta qualità per l'addestramento e il fine-tuning dei modelli AI. Ogni Datanet è come un magazzino di dati strutturati, dove i contributori caricano dati e garantiscono la tracciabilità e l'affidabilità dei dati attraverso il meccanismo di attribuzione on-chain. Attraverso meccanismi di incentivazione e controlli sui permessi trasparenti, Datanets realizzano la co-costruzione e l'uso affidabile dei dati necessari per l'addestramento dei modelli.
Rispetto a progetti come Vana, focalizzati sulla sovranità dei dati, @OpenLedger non si limita alla “raccolta dei dati”, ma estende il valore dei dati all'addestramento dei modelli e alle chiamate on-chain attraverso tre moduli principali: Datanets (etichettatura collaborativa e raccolta dati), Model Factory (strumento di addestramento dei modelli che supporta il fine-tuning senza codice) e OpenLoRA (adattatori di modelli tracciabili e combinabili), costruendo un ciclo completo “dai dati all'intelligenza”. Vana enfatizza “chi possiede i dati”, mentre @OpenLedger si concentra su “come i dati vengono addestrati, chiamati e premiati”, occupando posizioni chiave nella garanzia della sovranità dei dati e nei percorsi di monetizzazione dei dati nell'ecosistema AI Web3.
3.4 Proof of Attribution (contributo di prova): rimodellare il livello di incentivo della distribuzione dei profitti
La Proof of Attribution (PoA) è @OpenLedger il meccanismo centrale per realizzare l'attribuzione dei dati e la distribuzione degli incentivi. Attraverso la registrazione crittografica on-chain, stabilisce un'associazione verificabile tra ogni dato di addestramento e l'output del modello, garantendo che i contributori ricevano le giuste ricompense nelle chiamate del modello. La panoramica del processo di attribuzione dei dati e degli incentivi è la seguente:
Sottomissione dei dati: gli utenti caricano set di dati strutturati e specifici del dominio, e si registra l'attribuzione on-chain.
Valutazione dell'impatto: il sistema valuta il valore di ciascun dato in base alle caratteristiche e alla reputazione del contribuente in ogni inferenza.
Verifica dell'addestramento: i log di addestramento registrano l'effettivo utilizzo di ciascun dato, assicurando che i contributi siano verificabili.
Distribuzione degli incentivi: in base all'impatto dei dati, ai contributori vengono assegnati token legati ai risultati.
Governance della qualità: punisce i dati di bassa qualità, ridondanti o malevoli, garantendo la qualità dell'addestramento dei modelli.
Rispetto a una rete di incentivi generali basata su blockchain con meccanismi di valutazione combinati con l'architettura della subnet di Bittensor, @OpenLedger si concentra sui meccanismi di cattura del valore e distribuzione dei profitti a livello di modello. PoA non è solo uno strumento di distribuzione degli incentivi, ma anche un framework per la trasparenza, il tracciamento delle origini e l'attribuzione multi-fase: registra on-chain l'intero processo di caricamento dei dati, delle chiamate ai modelli e dell'esecuzione degli agenti, realizzando un percorso di valore verificabile end-to-end. Questo meccanismo consente a ogni chiamata al modello di essere tracciata fino ai contributori di dati e agli sviluppatori di modelli, realizzando così una vera “consensus di valore” e “profitto ottenibile” nel sistema AI on-chain.
RAG (Retrieval-Augmented Generation) è un'architettura AI che combina sistemi di recupero e modelli generativi, mirata a risolvere i problemi dei modelli linguistici tradizionali come “chiusura della conoscenza” e “creazione di contenuti falsi”. Introducendo biblioteche di conoscenza esterne, migliora la capacità generativa del modello, rendendo le uscite più reali, interpretabili e verificabili. RAG Attribution è @OpenLedger il meccanismo di attribuzione e incentivo che stabilisce contenuti tracciabili e verificabili nel contesto della generazione aumentata da recupero, assicurando che i contributori possano essere incentivati, realizzando infine la credibilità della generazione e la trasparenza dei dati. Il suo processo include:
Domanda dell'utente → Recupero dei dati: l'AI riceve la domanda e recupera contenuti pertinenti dall'indice dei dati @OpenLedger .
I dati vengono chiamati e generano risposte: i contenuti recuperati vengono utilizzati per generare la risposta del modello e viene registrato il comportamento della chiamata on-chain.
I contributori ricevono incentivi: dopo l'uso dei dati, i loro contributori ricevono incentivi calcolati in base all'importo e alla rilevanza.
Il risultato generato viene fornito con riferimenti: l'output del modello include link alla fonte originale dei dati, realizzando domande e risposte trasparenti e contenuti verificabili.

@OpenLedger RAG Attribution consente a ogni risposta AI di essere tracciabile fino a una fonte di dati reale, i contributori ricevono incentivi in base alla frequenza di citazione, realizzando “la conoscenza ha una fonte, le chiamate possono essere monetizzate”. Questo meccanismo non solo migliora la trasparenza delle uscite del modello, ma costruisce anche un ciclo di incentivi sostenibile per i contributi di dati di alta qualità, costituendo un'infrastruttura fondamentale per la promozione di AI affidabile e assetizzazione dei dati.
Quattro, progressi del progetto OpenLedger e cooperazione ecologica
Attualmente@OpenLedger è stato lanciato il testnet, il livello di intelligenza dei dati (Data Intelligence Layer) è @OpenLedger la prima fase del testnet, mirata a costruire un magazzino di dati internet guidato da nodi della comunità. Questi dati vengono filtrati, arricchiti, classificati e strutturati, per formare infine un'intelligenza assistiva per modelli di linguaggio di grandi dimensioni (LLM) utilizzati per costruire @OpenLedger modelli AI di dominio su . I membri della comunità possono eseguire nodi di edge device, partecipando alla raccolta e al trattamento dei dati. I nodi utilizzeranno risorse di calcolo locali per eseguire compiti relativi ai dati, e i partecipanti guadagneranno punti in base al loro livello di attività e al completamento dei compiti. Questi punti saranno convertiti in token OPEN in futuro, e il tasso di cambio specifico sarà annunciato prima dell'evento di generazione dei token (TGE).
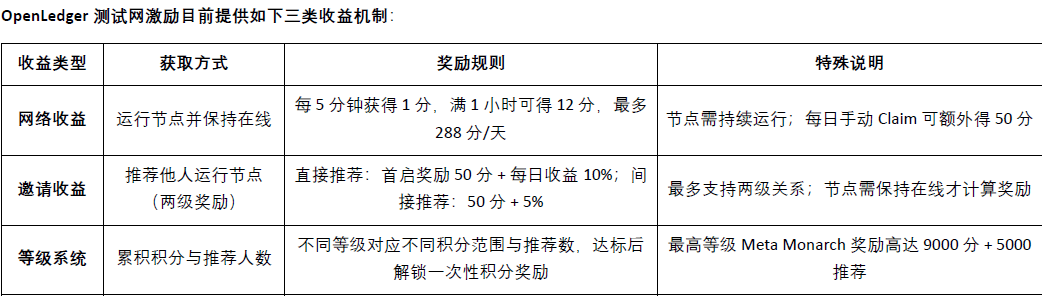
Il testnet della Fase 2 ha lanciato il meccanismo di rete dati Datanets, questa fase è limitata agli utenti della whitelist e richiede una pre-valutazione per sbloccare i compiti. I compiti includono la validazione dei dati, la classificazione, ecc., e al termine, in base alla precisione e alla difficoltà, si ottengono punti, con classifiche che incentivano contributi di alta qualità. I modelli di dati a cui è possibile partecipare sono attualmente forniti sul sito ufficiale:
Tuttavia, @OpenLedger ha una pianificazione della roadmap più a lungo termine, partendo dalla raccolta dei dati e costruendo modelli fino a un ecosistema di agenti, realizzando gradualmente un ciclo economico decentralizzato completo in cui “i dati sono asset, i modelli sono servizi e gli agenti sono intelligenza”.
Fase 1 · Livello di intelligenza dei dati (Data Intelligence Layer): la comunità raccoglie e tratta dati internet attraverso nodi di edge per costruire una base di dati intelligenti di alta qualità e continuamente aggiornati.
Fase 2 · Contributi dei dati della comunità (Community Contributions): la comunità partecipa alla validazione e al feedback dei dati, contribuendo a creare un dataset di oro (Golden Dataset) affidabile, per fornire input di qualità per l'addestramento dei modelli.
Fase 3 · Costruzione dei modelli e dichiarazione di attribuzione (Build Models & Claim): basandosi sui dati d'oro, gli utenti possono addestrare modelli specializzati e rivendicare attributi, realizzando l'assetizzazione dei modelli e il rilascio di valore combinabile.
Fase 4 · Creazione di agenti (Build Agents): basandosi sui modelli pubblicati, la comunità può creare agenti personalizzati, realizzando distribuzioni multi-scenario e un'evoluzione collaborativa continua.
@OpenLedger i partner ecologici coprono potenza di calcolo, infrastruttura, catene di strumenti e applicazioni AI. I suoi partner includono piattaforme di calcolo decentralizzate come Aethir, Ionet, 0G, e AVS su AltLayer, Etherfi e EigenLayer offrono supporto per l'espansione e la regolazione di base; strumenti come Ambios, Kernel, Web3Auth, Intract offrono capacità di autenticazione e integrazione nello sviluppo; nel campo dei modelli AI e degli agenti, @OpenLedger collabora con progetti come Giza, Gaib, Exabits, FractionAI, Mira, NetMind per promuovere il dispiegamento dei modelli e la realizzazione degli agenti, costruendo un ecosistema AI Web3 aperto, combinabile e sostenibile.
Nell'ultimo anno, #OpenLedger ha ospitato consecutivamente il summit DeAI a tema Crypto AI durante Token2049 Singapore, Devcon Thailand, Consensus Hong Kong e ETH Denver, invitando numerosi progetti chiave e leader tecnologici nel campo dell'AI decentralizzata. Come uno dei pochi progetti infrastrutturali in grado di pianificare costantemente eventi di alta qualità nel settore, #OpenLedger ha utilizzato il DeAI Summit per rafforzare efficacemente il proprio riconoscimento del marchio e la reputazione professionale all'interno della comunità degli sviluppatori e dell'ecosistema imprenditoriale AI Web3, ponendo solide basi per l'espansione ecologica e l'attuazione tecnica futura.
Cinque, finanziamenti e background del team
@OpenLedger ha completato un finanziamento di seed di 11,2 milioni di dollari a luglio 2024, con investitori come Polychain Capital, Borderless Capital, Finality Capital, Hashkey e diversi noti investitori angelici, tra cui Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda) e Trevor. I fondi verranno principalmente utilizzati per promuovere la costruzione della rete AI Chain di @OpenLedger , il meccanismo di incentivazione dei modelli, il livello di base dei dati e l'ecosistema delle applicazioni degli agenti.

@OpenLedger è stato fondato da Ram Kumar, un contribuitore chiave di #OpenLedger , ed è un imprenditore residente a San Francisco con una solida base tecnica nei settori AI/ML e blockchain. Porta una combinazione organica di intuizioni di mercato, competenze tecniche e leadership strategica al progetto. Ram ha co-diretto una società di ricerca e sviluppo blockchain e AI/ML, con ricavi annuali superiori a 35 milioni di dollari, svolgendo un ruolo chiave nella promozione di collaborazioni cruciali, inclusa una joint venture strategica con una sussidiaria di Walmart. Si concentra sulla costruzione di ecosistemi e collaborazioni ad alto leverage, mirando ad accelerare l'applicazione pratica nei diversi settori.
Sei, progettazione del modello economico del token e governance
$OPEN è il token funzionale centrale dell'ecosistema @OpenLedger , abilitando la governance della rete, l'esecuzione delle transazioni, la distribuzione degli incentivi e l'operazione degli agenti AI, costituendo la base economica per il flusso sostenibile di modelli AI e dati on-chain. Attualmente, la progettazione dell'economia del token ufficiale è ancora nelle fasi iniziali, e i dettagli non sono completamente definiti, ma con l'approssimarsi dell'evento di generazione dei token (TGE), la crescita della comunità, l'attività degli sviluppatori e gli esperimenti con casi d'uso stanno accelerando in Asia, Europa e Medio Oriente.
Governance e decisioni: i possessori di Open possono partecipare al voto di governance relativo al finanziamento dei modelli, gestione degli agenti, aggiornamenti dei protocolli e utilizzo dei fondi.
Pagamento delle commissioni e delle spese per le transazioni: come token nativo di rete @OpenLedger , supporta un meccanismo di tariffazione personalizzato nativo per AI.
Incentivi e premi di attribuzione: i contributori di dati, modelli o servizi di alta qualità possono ricevere profitti Open in base all'impatto dell'uso.
Capacità di bridging cross-chain: Open supporta il bridging L2 ↔ L1 (Ethereum), migliorando la disponibilità multi-chain di modelli e agenti.
Meccanismo di staking per AI Agent: il funzionamento di AI Agent richiede uno staking di $OPEN e le performance scadenti porteranno a una riduzione dello staking, incentivando un output di servizio efficiente e affidabile.
A differenza di molti protocolli di governance dei token legati a impatti e quantità di token posseduti, @OpenLedger introduce un meccanismo di governance basato sul valore del contributo. Il suo peso di voto è correlato al valore creato effettivamente, piuttosto che a un semplice peso di capitale, dando priorità a coloro che partecipano alla costruzione, ottimizzazione e utilizzo dei modelli e dei set di dati. Questa progettazione dell'architettura aiuta a raggiungere la sostenibilità a lungo termine della governance, prevenendo comportamenti speculativi che dominano le decisioni e allineandosi realmente alla sua visione di economia AI decentralizzata “trasparente, equa e guidata dalla comunità”.
Sette, dati, modelli e paesaggio del mercato degli incentivi e confronto con i concorrenti
@OpenLedger come infrastruttura di incentivazione per modelli AI “pagabili” (Payable AI), si dedica a fornire percorsi di monetizzazione verificabili, attribuibili e sostenibili per i contributori di dati e gli sviluppatori di modelli. Costruisce un sistema modulare con caratteristiche differenziate attorno al dispiegamento on-chain, agli incentivi alle chiamate e ai meccanismi di combinazione degli agenti, rendendosi unico nel panorama attuale dei Crypto AI. Sebbene non esista alcun progetto che si sovrapponga completamente a questo modello architettonico, OpenLedger mostra un'elevata comparabilità e potenziale di collaborazione con vari progetti rappresentativi in termini di incentivi del protocollo, economia dei modelli e attribuzione dei dati.
Livello di incentivazione del protocollo: OpenLedger vs. Bittensor
Bittensor è attualmente la rete AI decentralizzata più rappresentativa, costruendo un sistema di cooperazione multi-ruolo guidato da subnet e meccanismi di valutazione, incentivando i partecipanti come modelli, dati e nodi di ordinamento con il token $TAO. In confronto,@OpenLedger Focalizzandosi sull'attribuzione dei profitti delle chiamate ai modelli on-chain e sul dispiegamento, enfatizza un'architettura leggera e meccanismi di cooperazione tra agenti. Sebbene ci siano sovrapposizioni nella logica di incentivazione dei due, esistono differenze evidenti nei livelli di obiettivi e complessità del sistema: Bittensor si concentra su una rete di base delle capacità AI generali,@OpenLedger si posiziona come piattaforma di supporto al valore per le applicazioni AI.
Attribuzione dei modelli e incentivi alle chiamate: OpenLedger vs. Sentient
Il principio “OML (Open, Monetizable, Loyal) AI” proposto da Sentient riguardo ai diritti sui modelli e alla proprietà della comunità è in linea con @OpenLedger Alcuni pensieri sono simili, accentuando l'identificazione e il tracciamento dei profitti attraverso il Model Fingerprinting. La differenza è che Sentient si concentra maggiormente sulle fasi di addestramento e generazione del modello, mentre @OpenLedger Focalizzandosi sul dispiegamento on-chain dei modelli, sulle chiamate e sui meccanismi di attribuzione dei profitti, i due si trovano rispettivamente a monte e a valle della catena del valore AI, presentando una complementarità naturale.
Piattaforma di hosting modelli e inferenza attendibile: OpenLedger vs. OpenGradient
OpenGradient si concentra sulla costruzione di un framework di esecuzione di inferenza sicura basata su TEE e zkML, fornendo servizi di hosting e inferenza decentralizzati per modelli, focalizzandosi su ambienti di esecuzione affidabili di base. Al contrario,@OpenLedger pone maggiore enfasi sui percorsi di cattura del valore dopo il dispiegamento on-chain, costruendo un ciclo completo “addestramento—distribuzione—chiamata—profitto” attorno a Model Factory, OpenLoRA, PoA e Datanets. Le due si trovano in fasi diverse del ciclo di vita del modello: OpenGradient si concentra sulla fiducia operativa, OpenLedger sull'incentivo al profitto e sulla combinazione ecologica, con un alto potenziale di complementarità.
Modelli crowdsourced e incentivi di valutazione: OpenLedger vs. CrunchDAO
CrunchDAO si concentra su meccanismi di competizione decentralizzati per modelli di previsione finanziaria, incoraggiando la comunità a presentare modelli e a ricevere premi basati sulle prestazioni, adatto per scenari verticali specifici. In confronto,@OpenLedger Fornire un mercato di modelli combinabili e un framework di distribuzione unificato, con una maggiore versatilità e capacità di monetizzazione nativa sulla blockchain, adatto per l'espansione di vari scenari di agenti intelligenti. Entrambi i modelli presentano una logica di incentivazione complementare, con un potenziale di sinergia.
Piattaforma leggera per modelli guidata dalla comunità: OpenLedger vs. Assisterr
Assisterr è costruito su Solana, incoraggiando la comunità a creare modelli di linguaggio di piccole dimensioni (SLM) e aumentando la frequenza d'uso attraverso strumenti senza codice e il meccanismo di incentivazione $sASRR. Rispetto a ciò,@OpenLedger pone maggiore enfasi sulla tracciabilità e sui percorsi di distribuzione dei profitti chiusi tra dati, modelli e chiamate, utilizzando PoA per realizzare una distribuzione degli incentivi a grana fine. Assisterr è più adatto a comunità di collaborazione sui modelli a bassa barriera,@OpenLedger si dedica a costruire un'infrastruttura di modelli riutilizzabili e combinabili.
Fabbrica di modelli: OpenLedger vs. Pond
Pond e @OpenLedger forniscono entrambi il modulo “Model Factory”, ma con differenze significative nella posizione e nei servizi offerti. Pond si concentra sulla modellazione del comportamento on-chain basata su reti neurali grafiche (GNN), principalmente per ricercatori di algoritmi e scienziati dei dati, e promuove lo sviluppo dei modelli attraverso meccanismi di competizione. Pond è più orientato alla competizione dei modelli; OpenLedger, invece, si basa su un fine-tuning del modello linguistico (come LLaMA, Mistral), servendo sviluppatori e utenti non tecnici, enfatizzando l'esperienza senza codice e il meccanismo di distribuzione automatica dei profitti on-chain, costruendo un ecosistema di incentivi per modelli AI guidati dai dati. OpenLedger è più orientato alla cooperazione sui dati.
Percorso di inferenza attendibile: OpenLedger vs. Bagel
Bagel ha lanciato un framework ZKLoRA, utilizzando modelli fine-tunati LoRA e tecnologie di prova a zero conoscenza (ZKP) per garantire la verificabilità crittografica del processo di inferenza off-chain, assicurando la correttezza dell'esecuzione dell'inferenza. Al contrario,@OpenLedger supporta il dispiegamento scalabile e dinamico dei modelli fine-tunati LoRA tramite OpenLoRA, affrontando la questione della verificabilità dell'inferenza da angolazioni diverse — tracciando la provenienza dei dati e il loro impatto attraverso la prova di attribuzione (Proof of Attribution, PoA) per ogni output del modello. Ciò non solo migliora la trasparenza, ma fornisce anche ricompense ai contributori di dati di alta qualità, aumentando l'interpretabilità e l'affidabilità del processo di inferenza. In breve, Bagel si concentra sulla verifica della correttezza dei risultati computazionali, mentre @OpenLedger realizza la tracciabilità e l'interpretabilità del processo di inferenza attraverso meccanismi di attribuzione.
Percorso di collaborazione dal lato dei dati: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien e FractionAI offrono servizi di etichettatura dei dati decentralizzati, mentre Vana e Irys si concentrano sulla sovranità dei dati e sui meccanismi di attribuzione.@OpenLedger attraverso Datanets + moduli PoA, attua il tracciamento dell'uso di dati di alta qualità e la distribuzione degli incentivi on-chain. Il primo può fungere da fornitore di dati a monte,@OpenLedger mentre il secondo funge da centro di distribuzione del valore e delle chiamate, i tre presentano una buona sinergia lungo la catena del valore dei dati, piuttosto che una relazione competitiva.
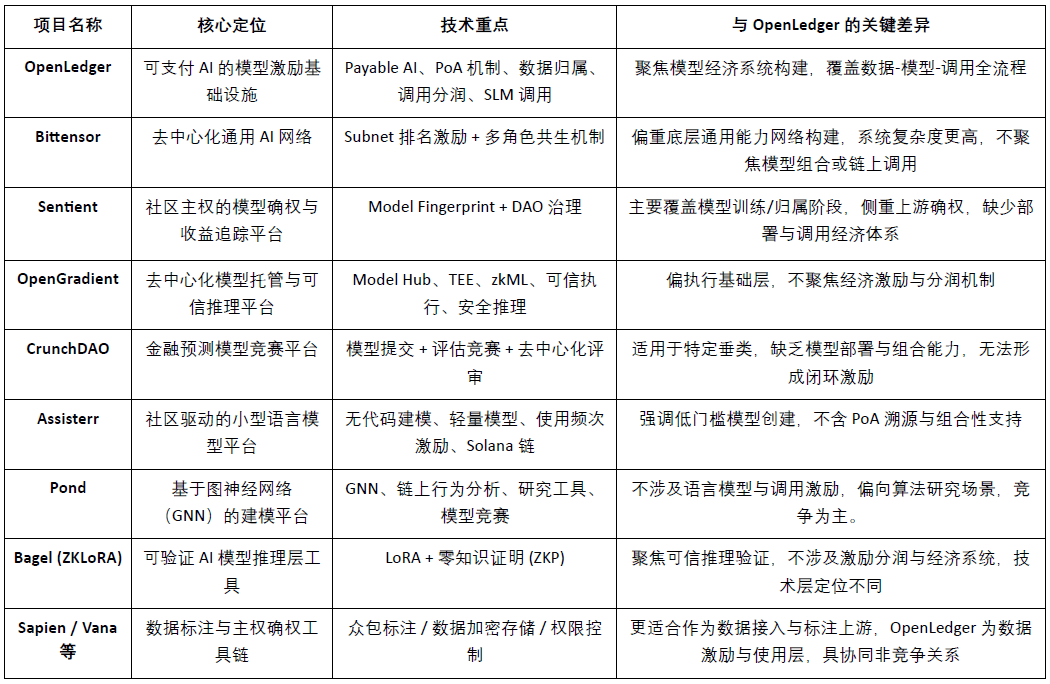
In sintesi, @OpenLedger occupa una posizione intermedia nel quadro attuale dell'ecosistema Crypto AI riguardo “l'assetizzazione e l'incentivazione dei modelli on-chain”, collegandosi sia a reti di addestramento che a piattaforme di dati, servendo anche il livello degli agenti e le applicazioni finali. È un protocollo chiave che connette l'offerta di valore dei modelli alle chiamate pratiche.
Otto, conclusione | Dati e modelli, il percorso della monetizzazione della catena AI
#OpenLedger si impegna a costruire un'infrastruttura in cui “il modello è un asset” nel mondo Web3, creando un ciclo completo di attribuzione on-chain, incentivi per le chiamate e conferma della proprietà, portando per la prima volta i modelli AI in un sistema economico realmente tracciabile, monetizzabile e collaborativo. La sua architettura tecnologica, costruita attorno a Model Factory, OpenLoRA, PoA e Datanets, fornisce agli sviluppatori strumenti di addestramento a bassa barriera, garantisce diritti di profitto per i contributori di dati e offre meccanismi di chiamata e distribuzione dei profitti combinabili per le parti applicative, attivando completamente le risorse a lungo trascurate della catena del valore AI nei “dati” e “modelli”.
#OpenLedger è più simile a una fusione di HuggingFace + Stripe + Infura nel mondo Web3, fornendo hosting dei modelli, fatturazione delle chiamate e interfacce API orchestrabili on-chain. Con l'accelerazione della tokenizzazione dei dati, dell'autonomia dei modelli e della modularizzazione degli agenti, OpenLedger ha il potenziale per diventare un'importante catena AI centrale nel modello “Payable AI”.


