Nella mentalità comune, si crede che le prestazioni del sistema possano essere semplicemente aumentate aggiungendo più core CPU o aggiornando a server più potenti. Questo è vero per alcune attività di calcolo indipendenti, ma quando si applica alla blockchain, la realtà è molto più complessa
Tuttavia, qual è la verità? Altius chiarirà questo problema

Se il livello di archiviazione non è all'altezza, aggiungere potenza di calcolo non ha senso
Le blockchain non eseguono solo calcoli (compute), ma leggono e scrivono continuamente lo stato (state I/O). Ogni transazione non è solo qualche addizione/sottrazione, ma richiede aggiornamenti dei dati nell'albero trie, nel database chiave-valore e sincronizzazione con altri nodi.
Questo crea un collo di bottiglia: se il sistema di archiviazione non è abbastanza veloce o non può essere parallelizzato, i core aggiuntivi dovranno aspettare i dati invece di elaborare.
Perché bilanciare calcolo e archiviazione è la chiave
Collo di bottiglia di spostamento. Aumentando i core, il throughput di calcolo può aumentare, ma il tempo di I/O (disco, database, aggiornamenti trie) occupa la maggior parte, rendendo il guadagno marginale quasi nullo.
L'efficienza lineare si verifica solo quando tutti i componenti crescono in modo uniforme. Se la larghezza di banda di archiviazione non si espande, il sistema diventa ricco di CPU ma povero di I/O.
Blockchain specifica: ogni transazione deve garantire determinismo e coerenza, quindi la scrittura/lettura dello stato viene ripetuta più volte, non può essere ignorata.
Illustrazione dal mondo delle blockchain attuali
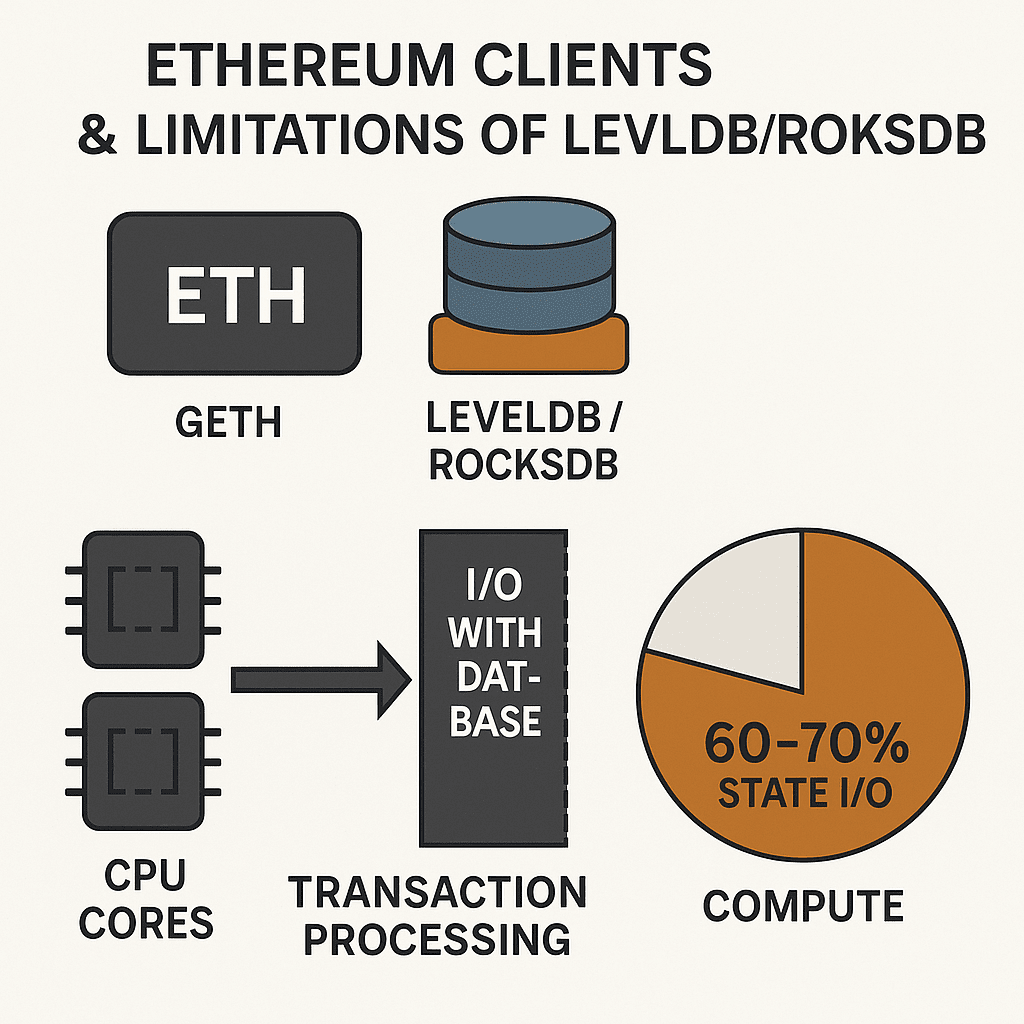
1. Client Ethereum e limiti di LevelDB/RocksDB
Client comuni come Geth o Reth utilizzano spesso LevelDB o RocksDB per gestire lo stato. Si tratta di database chiave-valore generali, non ottimizzati specificamente per le blockchain.
Risultato: anche se raddoppi il numero di core CPU, la velocità di elaborazione delle transazioni non aumenta molto perché gran parte del tempo viene consumato dalle operazioni I/O con il database.
Esempio: in alcuni test, più del 60-70% del ritardo nell'elaborazione delle transazioni deriva dalla lettura/scrittura dei dati di stato, non dal calcolo.
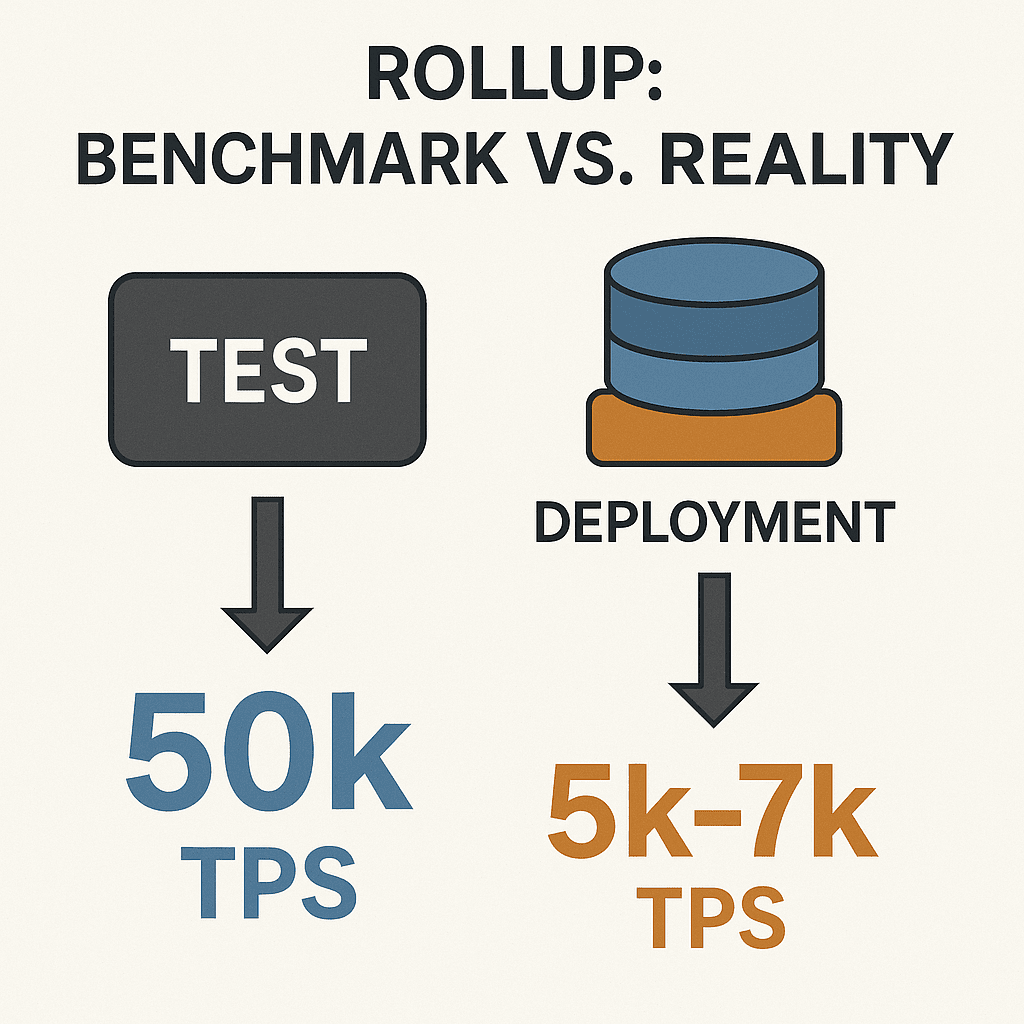
2. Rollup: benchmark impressionanti, prestazioni reali deludenti
Molti progetti rollup pubblicano numeri impressionanti di TPS nei test di calcolo - cioè misurano solo la logica del contratto, senza eseguire l'intero carico di archiviazione.
Tuttavia, quando vengono implementati nella realtà con il database di stato, il TPS diminuisce drasticamente, arrivando a essere anche solo una decima parte.
Esempio immaginario: un rollup potrebbe raggiungere 50k TPS in laboratorio, ma quando elabora transazioni con l'intero albero di stato, scende a 5k-7k TPS. Perché? L'archiviazione non è abbastanza veloce per aggiornare la quantità enorme di dati in tempo reale
3. Server potenti ma prestazioni scarse
Alcune blockchain hanno provato a far funzionare i server estremamente potenti - CPU da 128 core, RAM da diversi terabyte, dischi SSD costosi. Ma le prestazioni effettive non sono migliorate molto.
Il problema è che il database continua a funzionare con un'architettura sequenziale o è limitato dai lock, quindi la larghezza di banda I/O non cresce in proporzione alle risorse hardware.
Risultato: i costi infrastrutturali aumentano vertiginosamente, ma il TPS migliora molto poco. Questo è un esempio vivido che dimostra come molti core non equivalgano a maggiore velocità nel contesto delle blockchain.

Approccio corretto: Scaling = Calcolo + Archiviazione sincronizzati
Parallelizzazione dell'esecuzione a livello di istruzione (Instruction-level Parallelism, SSA).
Motore di archiviazione ottimizzato per carichi di lavoro blockchain (SSMT, stato suddiviso, caching intelligente).
Controllo della concorrenza ottimistico che decide invece di ripetere casualmente, riducendo gli sprechi.
Incentivare gli sviluppatori a scrivere codice adatto al parallelismo per sfruttare al meglio l'infrastruttura.
Conclusione
Aggiungere core non è una soluzione miracolosa. Le prestazioni della blockchain dipendono dal bilanciamento tra calcolo e archiviazione.
Un'architettura corretta deve gestire in parallelo il collo di bottiglia I/O con il calcolo, trasformando l'energia extra in prestazioni reali. È proprio questo il motivo per cui piattaforme come Altius si concentrano su entrambi i fronti: parallelizzazione del calcolo e espansione dell'archiviazione, per ottenere prestazioni reali, non solo benchmark brillanti.
