@Walrus 🦭/acc is a decentralized storage protocol based on erasure-coding. Anyone can interact with Walrus to store arbitrary data and prove that the data is stored. Like IPFS, Walrus itself is not a blockchain. However, Walrus leverages the Sui network for help with storage node lifecycle management, blob lifecycle management, and the introduction of incentive systems. Sui has achieved exceptionally high scalability compared to other blockchains with its own consensus and smart contracts. However, if Sui were to handle blobs in addition to transaction data, it would be inefficient as all nodes would replicate large volumes of blobs, greatly increasing the replication factor. Therefore, Walrus uses erasure-coding to divide blobs into smaller units called slivers and allocate them to nodes, allowing large volumes of data to be stored in a decentralized protocol with a replication factor of just 4-5. In particular, unlike existing decentralized storage protocols, #Walrus has the advantage of significantly reducing data recovery costs by using an encoding method called Red Stuff. So, what is Red Stuff
1) Encoding:
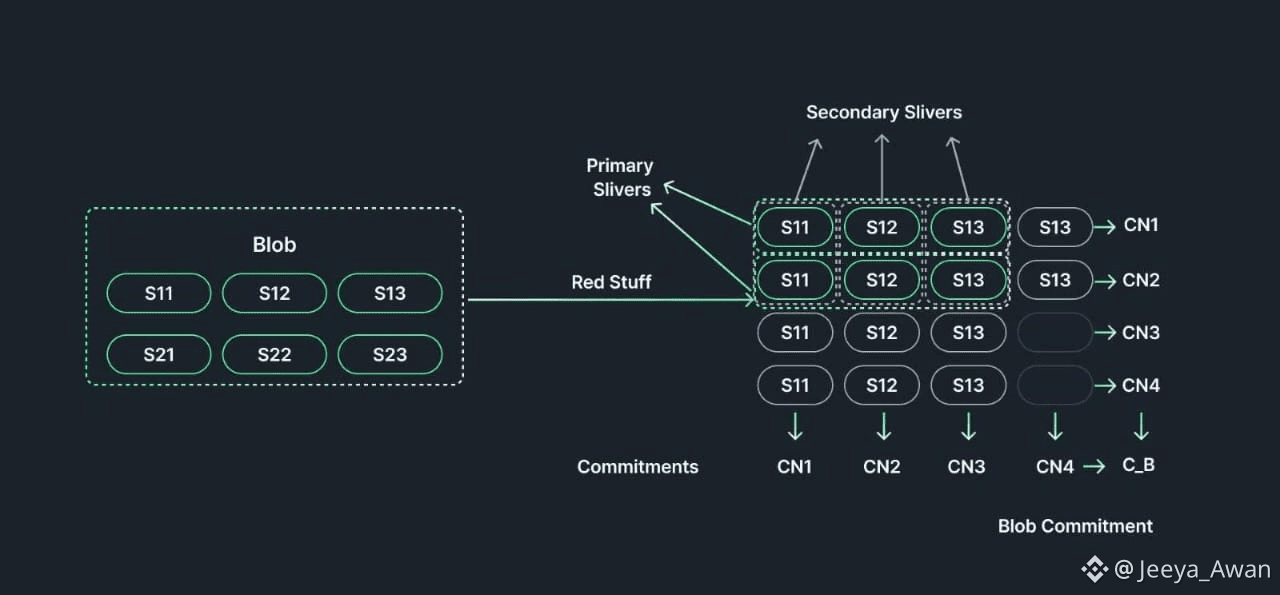
Red Stuff encodes the blob in two dimensions. This is for efficient sliver recovery. In the primary dimension, encoding is similar to RS-encoding, dividing B into f+1 primary slivers. Red Stuff goes a step further, dividing each of the f+1 primary slivers into 2f+1 secondary slivers in the secondary dimension. As a result, B becomes a matrix of (f+1) * (2f+1). Note that the example in the above figure assumes f=1. Based on this two-dimensional matrix, additional repair symbols are generated for both dimensions. Note that a symbol is a smaller unit of data than a sliver. First, the symbols of 2f+1 columns are expanded from f+1 to 3f+1, and then the symbols of f+1 rows are expanded from 2f+1 to 3f+1. The commitment to B can be easily calculated. W calculates commitments for each rows and columns including the additional repair symbols, then combines all these sliver commitments to create the blob commitment.
2) Write:
The process of storing data in the Walrus protocol is similar to protocols using existing RS encoding. W encodes the original data with Red Stuff to generate sliver pairs to send to each node. A sliver pair here refers to a pair of primary and secondary slivers, with a total of 3f+1 sliver pairs generated.
W then propagates 3f+1 sliver pairs and sliver commitments to 3f+1 nodes each. Upon receiving these, nodes verify the slivers through the commitments and send signatures back to W. When W receives 2f+1 signatures, it generates an availability certificate and publishes it on-chain (Sui network). This is because even if f Byzantine nodes sign, there are signatures from f+1 honest nodes, making it possible to recover the original data.
3) Read:
The process of reading data from Walrus is also identical to protocols using existing RS encoding, and only primary slivers need to be used. When R receives f+1 or more valid primary slivers from storage nodes, it can recover B and read the data.
4) Recovery;
The biggest advantage of Red Stuff compared to RS encoding is evident in the data recovery process. Assuming the network is in an asynchronous environment and nodes can freely enter and leave, there may be nodes that don't receive slivers from W. Therefore, these nodes need to communicate with other nodes to recover slivers.
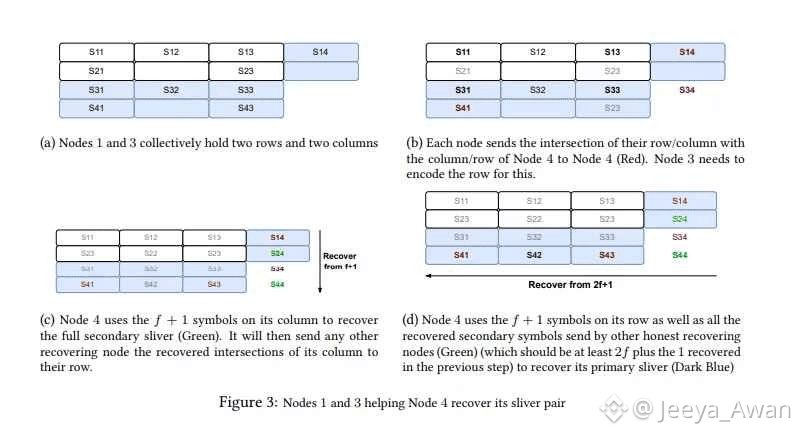
Let's examine how a node that didn't receive slivers recovers data through the above figure (f=1).
a: Assume a situation where Node 1 fully possesses the first sliver pair, Node 3 has the third sliver pair, and Node 4 needs to recover the fourth sliver pair.
b: Nodes 1 and 3 send symbols that overlap with the fourth sliver pair (S14, S34, S41, S43) to Node 4.
c: Since Node 4 now has f+1 or more symbols for the fourth secondary sliver, it can recover the fourth secondary sliver. Extending this logic means that all 2f+1 honest nodes can recover their secondary slivers.
d: The fact that 2f+1 nodes all have secondary slivers means there are 2f+1 symbols in each row, which allows for the recovery of all primary slivers using these 2f+1 symbols. In conclusion, if f+1 or more nodes in the network have slivers, the remaining nodes can communicate with them to recover all slivers.
The size of a symbol is O(B/n^2), and each node needs to download O(n) symbols, so the recovery cost per node is O(B/n). Extending this to the entire network, the cost for all nodes to recover slivers corresponds to O(B). Considering that the cost of recovering data is O(n^2B) in the full replication method and O(nB) in the encode and share method, the Red Stuff method can process this very efficiently at a cost of O(B). In other words, the data recovery cost is constant regardless of the number of nodes (n) participating in the network.
• Walrus Storage Flow:
Red Stuff is one method of encoding data. Now, let's look at the big picture of how data storage occurs in Walrus, including interactions with Red Stuff and the Sui network.
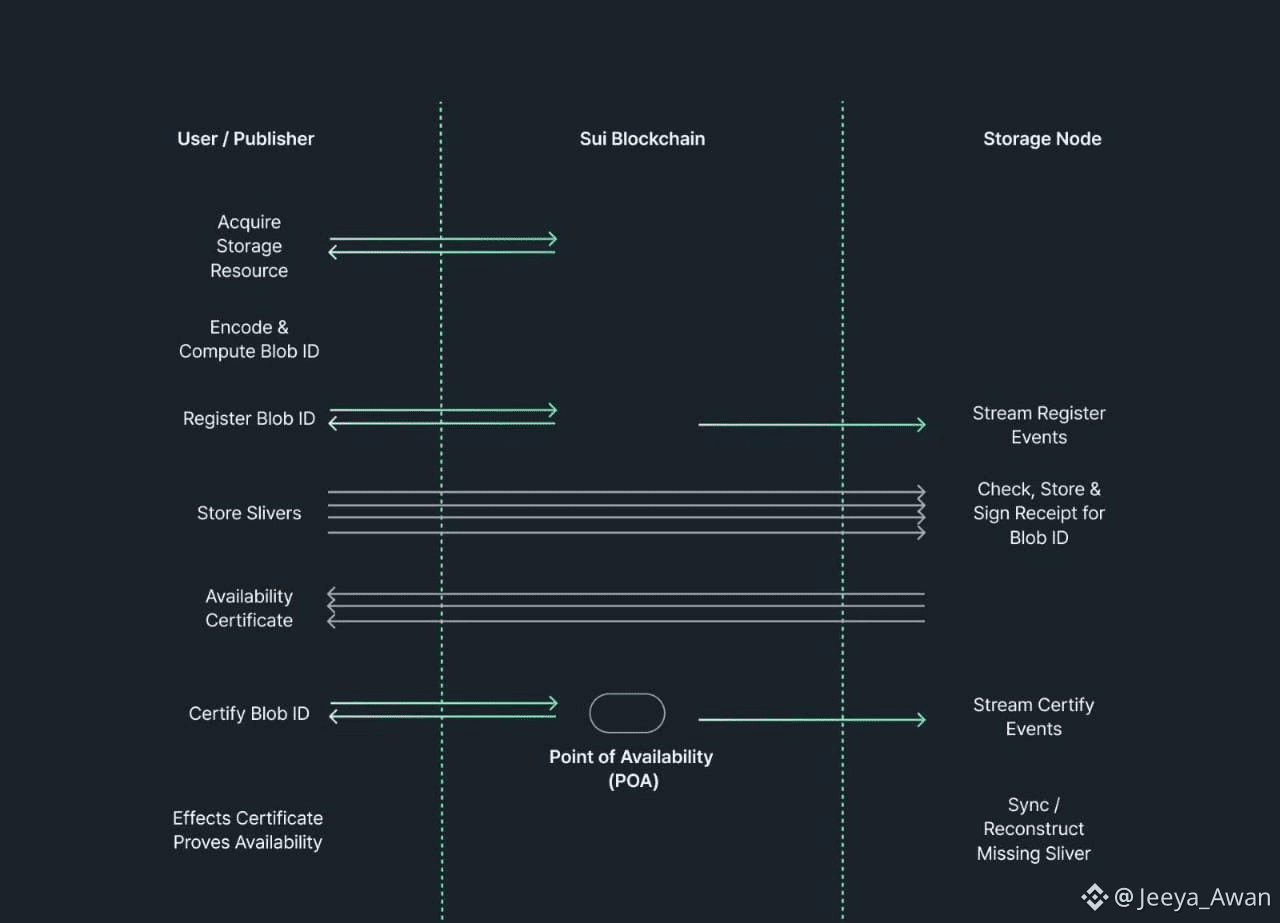
A user wanting to store data in Walrus acquires storage resources. Storage resources can be purchased directly from the Walrus system object smart contract on the Sui network or from a secondary market. Storage resources can be understood as permissions to store data in Walrus, specifying the start epoch, end epoch, and how much capacity can be stored. The user applies Red Stuff encoding to the blob they want to store and computes the blob ID. Subsequent steps can be performed directly or by publishers existing in the network. To register the blob ID with the storage resource, the user updates the storage resource on the Sui network to trigger an event. The user propagates the blob metadata to all storage nodes and distributes each sliver to the respective nodes. Storage nodes receive the slivers and verify whether the metadata matches the blob ID and the slivers match the metadata, and if the user transmitting the sliver has appropriate storage resources. If deemed valid, storage nodes send signatures for the respective slivers to the user. When the user receives 2f+1 or more signatures, they generate an availability certificate and transmit it to the Sui network. From this point, the PoA (point of availability) status is updated on the Sui network, indicating that the blob is available to everyone. If there are storage nodes that haven't received slivers for that blob even after confirming the PoA, they can sync with other storage nodes to recover the slivers. Note that the Walrus protocol has an epoch concept for a certain period, and the set of participating storage nodes changes with each epoch. The amount of data allocated to storage nodes varies according to the delegated WAL tokens each epoch. Also, because participating nodes can change each epoch, there's an inevitable process of transferring slivers every time the epoch changes. Note that in the default case, slivers are transferred from the previous node to the new node directly instead of going through the recovery process. However, if there's too much data and the sliver transfer time becomes longer than the epoch, the epoch may not end. To prevent this, Walrus separates the data storage (write) and retrieval (read) processes into different epochs just before the end of an epoch. In other words, when the epoch changes and the node reconfiguration process begins, the data storage process proceeds in the next epoch from this point, while the data reading process still continues in the current epoch. When 2f+1 or more nodes in the new committee of the next epoch indicate that sliver recovery is fully prepared, the read operations also smoothly transition to the next epoch.

