一开始我真没觉得 Walrus 有多炸裂。
不是那种一看白皮书就“卧槽这要改写世界”的项目,反而更像一杯温水,第一口没啥感觉,但越喝越不对劲。最近一段时间,我老是忍不住反复琢磨它,琢磨到最后,反而开始怀疑自己以前对“存储”这件事是不是太敷衍了。
以前我对存储的理解特别简单:
文件嘛,不就是找个地方放着?云盘也好,IPFS 也好,反正能用就行。至于“是不是我的”,说实话,从来没认真想过。直到 Walrus 出现,我才第一次意识到一个被忽略很久的问题——数据怎么存,才真的算是属于自己?
我第一次注意到 Walrus,其实是逛 Sui 生态的时候。
Sui 本身就挺有意思的,并行执行、对象模型这些设计,让链跑起来特别顺。那种感觉很直观:不堵、不卡、不拖泥带水。
但问题也马上暴露出来了。
链跑得再快,如果只能装一些小额状态、零碎数据,那终究是“轻应用”的天下。现实里的世界可不是这样,图片、视频、模型、AI 数据集,一个比一个大,动不动几百 MB,甚至 GB 级。传统链上要么根本放不下,要么成本高到离谱。
Walrus 就是在这个缝隙里出现的。
它不想当“万能存储”,而是专门盯着一个点:大文件的去中心化存储。而且不是那种“存完就不管”的冷存,而是能和链上逻辑真正打通的那种。
我开始认真研究它的机制,是因为它的存储方式挺反直觉的。
很多人对去中心化存储的第一反应都是:
多复制几份,撒到不同节点,越多越安全。
Walrus 偏偏不这么干。
它用的是一种叫 Red Stuff 的编码方案,简单说就是把文件切碎,再加冗余,但不是一维地加,而是用二维方式来做。这样一来,就算一部分节点掉线,数据依然能恢复,而且修复速度还很快。
最关键的是,这种方式不用存一堆完整副本。
最终算下来,存储开销大概是文件大小的五倍左右。放在去中心化存储里,这已经相当克制了。比起全量复制,省了太多;比起那种只在少数节点存的方案,又稳得多。
我挺喜欢这种取舍的。
不是极端安全,也不是极端省钱,而是在成本和韧性之间找了个很舒服的位置。
慢慢地,我开始意识到,Walrus 的安全感不是喊出来的,而是堆出来的。
现在它已经有上百个独立运营的节点,分布得很散。
数据被切碎、打散、编码之后,想删几乎不可能,想改更难。没有哪个节点能单方面决定一份数据的生死。
这让我想起以前用中心化云盘的经历。
账号异常、风控误判、甚至只是产品策略调整,一夜之间,文件没了。那种感觉特别无力——明明是你的东西,但你连申诉的资格都不一定有。
而在 Walrus 上,数据一旦上链,就安安静静地躺在那里。
没有客服,没有人工审核,也没有“系统原因”。
那一刻你才会意识到,“属于自己”这四个字,原来是有技术含量的。
但真正让我对 Walrus 产生长期兴趣的,其实不是“能存”,而是“能玩”。
很多存储协议,本质上只解决一件事:
把数据放好,然后取出来。
Walrus 不满足于此。
它把存储本身,变成了可以被智能合约直接管理的对象。存储容量是 token 化的,访问权限是可编程的,逻辑是可以组合的。
这一下,想象空间就被打开了。
你可以设定:
只有满足某个链上条件的地址,才能读取某个文件;
某个 NFT 的元数据,会随着事件自动更新;
甚至直接搞一个完全链上的数据市场,谁能看、谁能用,全由合约说了算。
这已经不是“存储”,而是“数据基础设施”。
后来我看到一些实际落地的案例,才真正意识到这条路有多重要。
比如 Humanity Protocol,把几百万用户的生物识别凭证,从 IPFS 迁到了 Walrus 上。
掌纹、身份信息这种东西,本来就是又重要又敏感,既不能乱公开,又不能靠中心化服务器。
Walrus 提供的,是一种很微妙的平衡:
数据在链上、可验证、不可篡改,但隐私仍然能被保护。
再比如 Chainbase,把几百 TB 的链上原始数据存进 Walrus,直接给 AI 模型调用。
这件事让我印象特别深。因为它意味着,数据不只是“存着”,而是真的能被机器直接用来计算、训练、推理。
这才像是 AI 时代该有的数据形态。
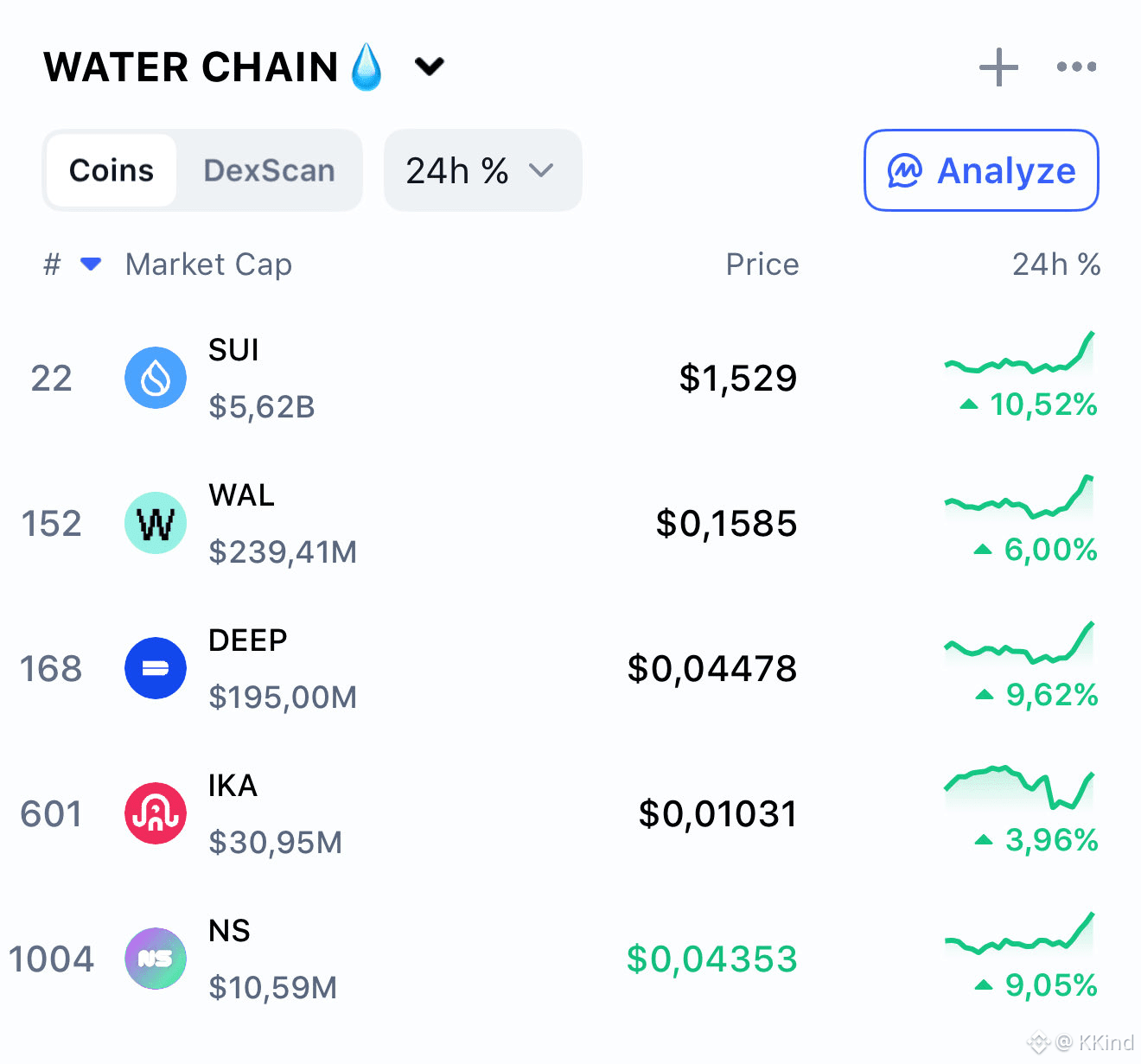
说到这里,就不得不提 $WAL。
很多人第一眼看 $WAL,只会想到治理、投机这些老一套。
但真正理解之后,会发现它在整个系统里的位置非常关键。
用户用 wal预付存储费用,协议再把这部分费用,按时间慢慢分配给节点和质押者。
这里最巧妙的一点是:存储成本锚定的是法币水平,而不是 wal的币价。
也就是说,不管 wal涨跌,用户存数据的成本是相对稳定的。
不会出现“币价暴涨,结果连存文件都存不起”的尴尬局面。
我自己算过账,在目前的补贴阶段,实际成本低得离谱,几乎就是在鼓励大家提前用。
从持有者的角度看,这套机制也挺顺的。
你可以把 wal质押出去,支持节点运行,顺便赚取奖励;
节点必须在 Sui 链上,通过 PoA 机制证明自己真的在老老实实存数据;
一旦作恶,就会被惩罚。
于是就形成了一个挺漂亮的闭环:
用户付费 → 节点存储 → 协议补贴 → 更多用户进来 → 整个飞轮越转越快。
整个过程,几乎不需要人为干预。
把 Walrus 和其他存储项目放在一起看,它的路线其实很清晰。
Filecoin 走的是矿工挖矿那一套,专业化程度高,门槛也高;
Arweave 主打“一次付费永久存”,理念很浪漫,但日常使用并不友好;
Walrus 则选择了一条中间路线:不极端、不喊口号,专注成本、性能和可编程性。
再加上 Sui 本身的并行执行能力,Walrus 的读写体验真的很顺。
那种感觉不像是在“等区块确认”,更像是在用一个反应很快的分布式系统。
有时候我会想,在 AI 时代,真正稀缺的东西是什么。
不是算力,也不是模型结构,而是高质量、可用、可信的数据。
而数据一旦重要,就一定会遇到三个问题:
谁来存?谁能用?谁来负责?
Walrus 试图回答的,正是这三个问题。
它让开发者更容易存大文件,让 AI 项目直接调用链上数据,也让普通人不用再把自己的创作交给中心化平台“托管”。
从这个角度看,它并不是在做一个“小而美”的工具,而是在补 Web3 一块非常基础的短板。
当然,现实也得说清楚。
Walrus 还很早。
主网上线时间不长,生态还在慢慢长,很多东西都在试水阶段。节点在增加,集成项目在冒头,补贴策略也在不断调整。
它不是那种一夜爆发型的项目。
但反而正是这种节奏,让人心里比较踏实。
币圈见过太多声势浩大、然后迅速消失的东西了。
能安静做基础设施的,往往才是真的打算走远。
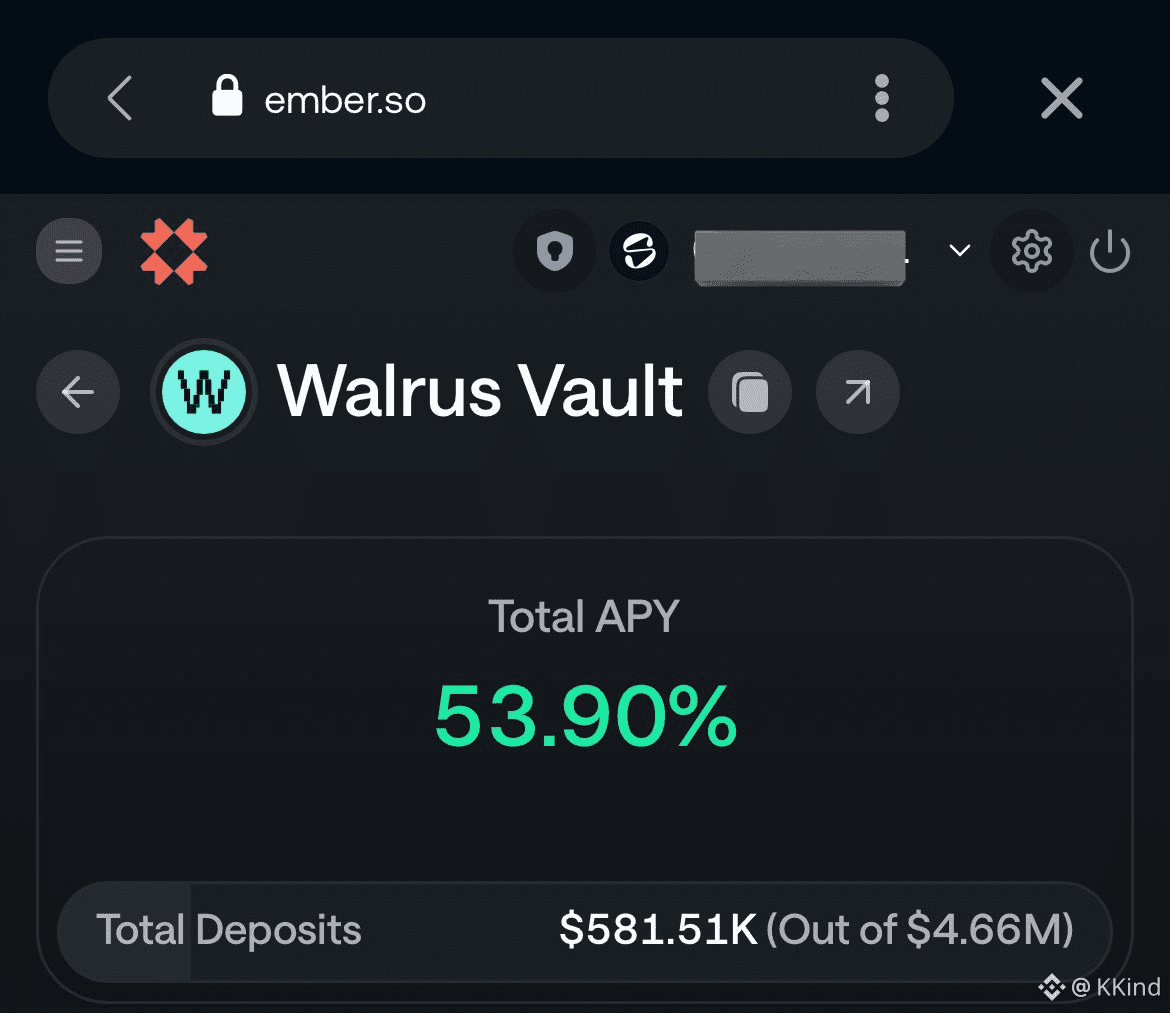
我自己也买了一些 $WAL,顺手在测试网存过文件。
操作比我想象中简单得多,速度也确实快。
当 blob ID 出现在链上的那一刻,我突然有种很奇妙的感觉:
这份数据,没有人能单方面删掉它了。
它就这么存在着。
写到这里才发现,自己已经说了这么多。
可能是因为最近确实一直在想这些事。
去中心化存储,听起来很技术、很硬核,但落到现实里,其实就是多了一点安心,多了一点掌控感。
尤其是在 AI 到处跑、数据越来越值钱的时代,这种掌控感,会变得越来越重要。
Walrus 至少让我觉得,这个未来不一定非要走向更集中的方向。
慢慢来吧。
反正我已经在路上了。