Walrus rara vez aparece cuando una aplicación colapsa, pero casi siempre está presente el mismo problema: los datos dejan de ser confiables antes de que el mercado se dé cuenta. La mayoría de proyectos cripto no muere por un exploit espectacular ni por una caída brutal del token. Mueren de forma mucho más aburrida. Empiezan a fallar en cosas pequeñas: estados que no se recuperan, archivos incompletos, historiales corruptos, indexadores que se descuadran, nodos que responden lento, backups que no existen. Los usuarios no ven un “hack”. Ven una app que poco a poco deja de ser usable.
En Web2, este tipo de fallos se llama “incidente operativo”. En Web3 suele llamarse simplemente “mala suerte”. Pero es estructural.
La mayoría de arquitecturas descentralizadas se diseñan alrededor del consenso y las transacciones, no alrededor del ciclo completo de vida de los datos. Se asume que almacenar es trivial, que replicar es suficiente, que alguien más se encargará de la disponibilidad real dentro de cinco años. Esa suposición funciona en demos. No funciona en producción.
Una aplicación real no solo escribe datos. Los reescribe, los valida, los reconstruye, los consulta bajo carga, los recupera después de errores parciales. Ese flujo es constante e invisible. Y cuando se rompe, no genera titulares, pero mata productos. Aquí es donde Walrus se vuelve relevante, no como “otra red de storage”, sino como una capa diseñada específicamente para ese tipo de desgaste silencioso.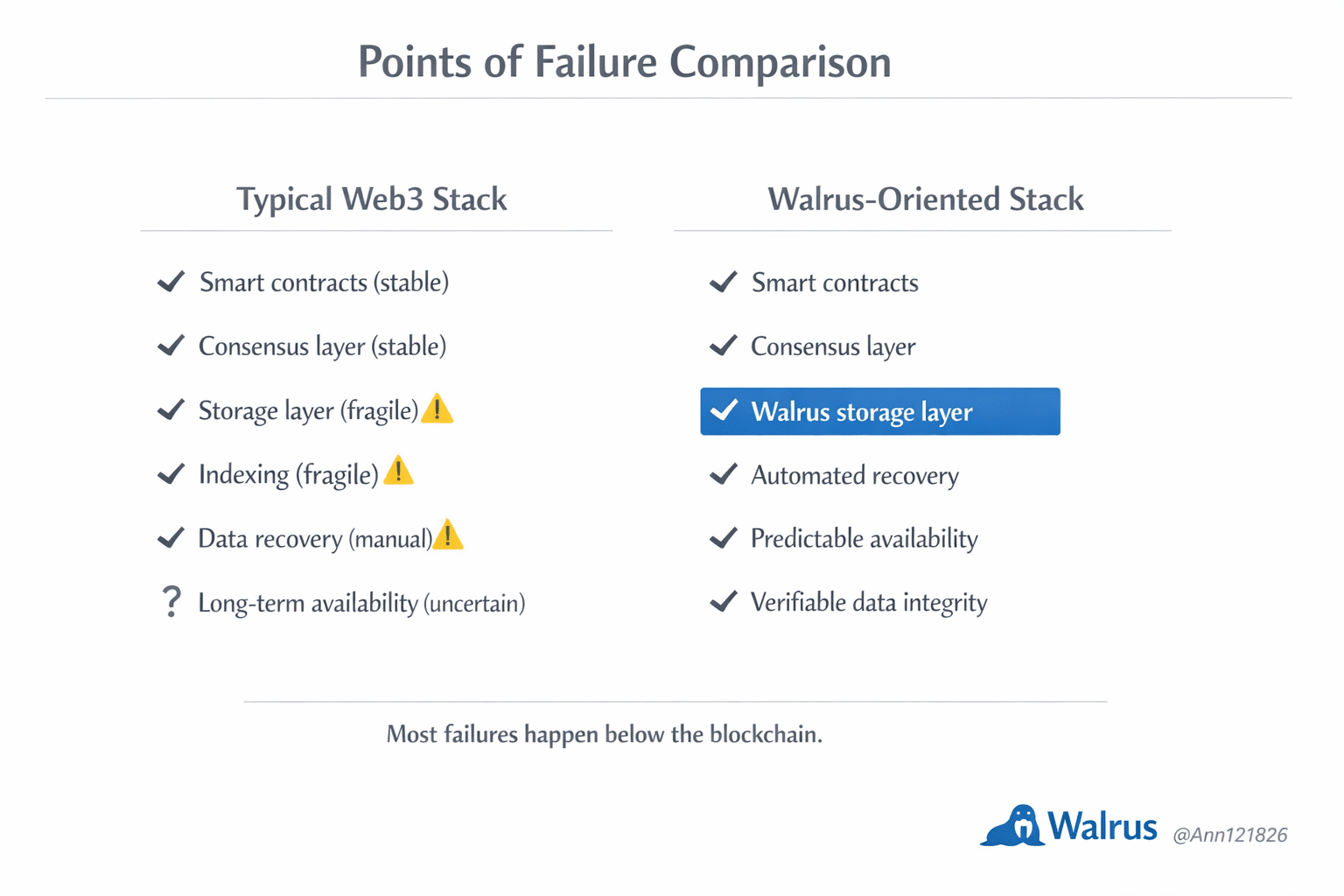
El problema no es que otras soluciones no funcionen. Es que no están pensadas para fallar bien. Cuando un nodo desaparece, cuando parte de los fragmentos se pierde, cuando la red se congestiona, el sistema debería degradarse de forma controlada. En la práctica, muchas aplicaciones simplemente se rompen.
Walrus ataca ese punto específico: convierte la disponibilidad de datos en una propiedad primaria del sistema, no en un efecto colateral. La codificación por borrado, la reconstrucción automática y el diseño orientado a recuperación hacen que el fallo de componentes individuales no se traduzca inmediatamente en fallo del producto. Eso no suena glamoroso. Pero es exactamente lo que diferencia una demo técnica de una infraestructura usable durante años.
Hay una ilusión común en cripto: creer que la descentralización por sí sola garantiza resiliencia. En realidad, solo distribuye los puntos de fallo. Si no hay una arquitectura explícita para gestionar pérdida parcial, latencia y degradación, el sistema se vuelve frágil a gran escala. Y la fragilidad no aparece en el whitepaper. Aparece cuando hay tráfico real.
Otro detalle que casi nunca se discute es el efecto acumulativo del volumen. Cada día una aplicación escribe más datos. Logs, estados intermedios, snapshots, pruebas, historiales de usuario. Ese volumen no se borra cuando baja el precio del token. Se queda.
Con el tiempo, el sistema de almacenamiento se convierte en la parte más crítica del stack, incluso más que el propio contrato inteligente.
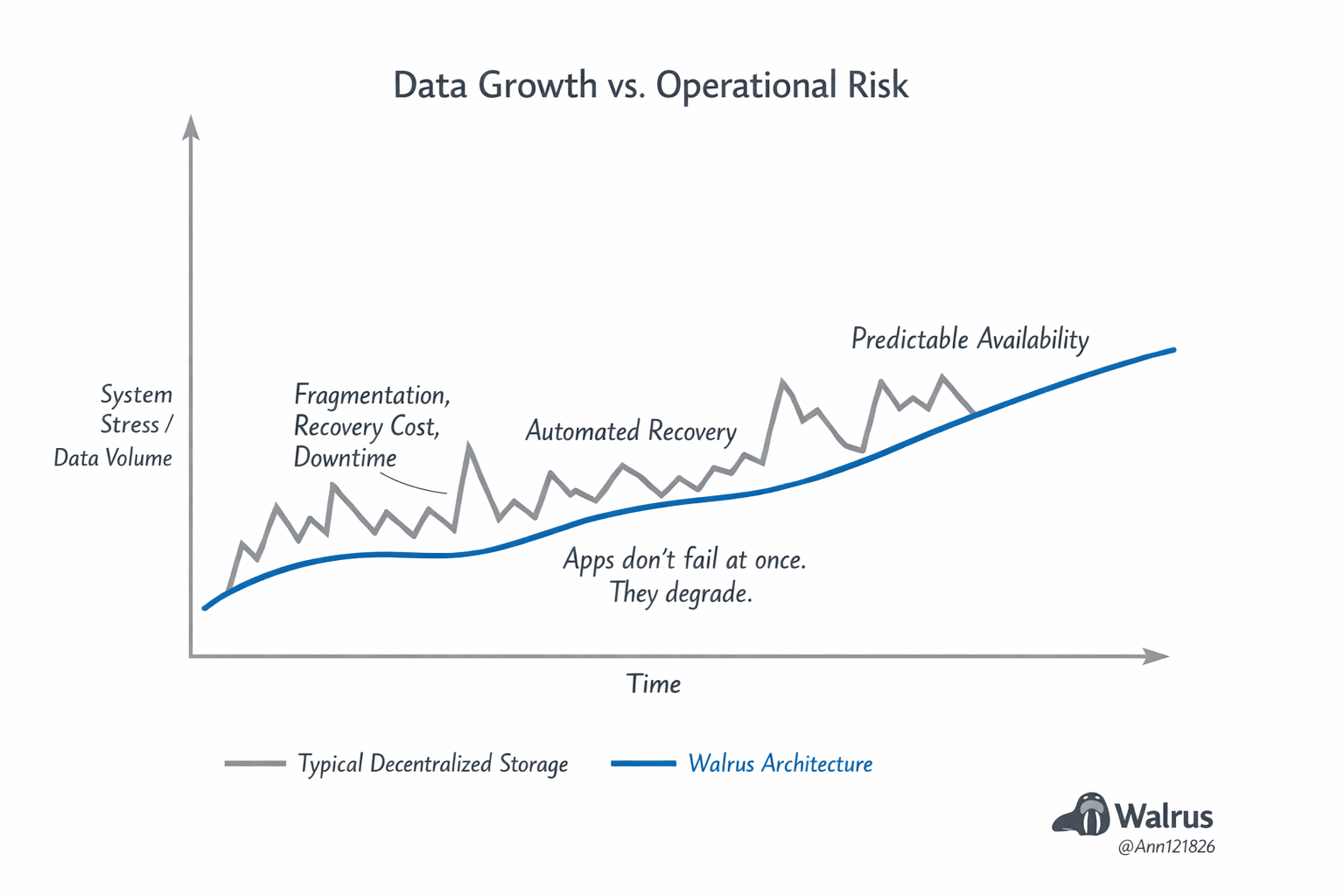
Cuando se mira desde este ángulo, la pregunta importante deja de ser “¿qué tan descentralizado es?” y pasa a ser “¿qué tan recuperable es?”. Una red que no puede reconstruir datos de forma confiable no es infraestructura, es una demo persistente.
Esto también explica por qué muchas aplicaciones aparentemente “sólidas” desaparecen sin drama. No colapsan. Simplemente se vuelven lentas, inconsistentes, caras de operar, difíciles de mantener. Los desarrolladores se cansan. Los usuarios migran. El repositorio queda quieto. Desde fuera parece abandono. Desde dentro fue erosión técnica.
Walrus intenta posicionarse justo en ese punto invisible del ciclo: antes del colapso, antes del abandono, cuando todavía hay producto, pero la complejidad operativa empieza a superar al equipo. No promete eliminar los fallos. Promete que los fallos no destruyan el sistema.
Eso cambia el tipo de proyectos que pueden construirse encima. Cuando los desarrolladores saben que los datos no son una deuda técnica creciente sino una capa estable, se atreven a diseñar aplicaciones más grandes, con horizontes más largos, con usuarios reales.
La supervivencia en Web3 no depende solo de comunidad, marketing o tokenomics. Depende de algo mucho menos visible: si el sistema sigue funcionando cuando nadie está mirando. Ahí es donde se decide qué protocolos se convierten en infraestructura y cuáles quedan como experimentos interesantes. Walrus apuesta a ese nivel de diseño. No al que genera hype, sino al que evita funerales silenciosos.

