A friend once told me, “Decentralization is easy when everything is public.”
And that line has been stuck in my head, because it explains why most “decentralized storage” narratives feel incomplete.
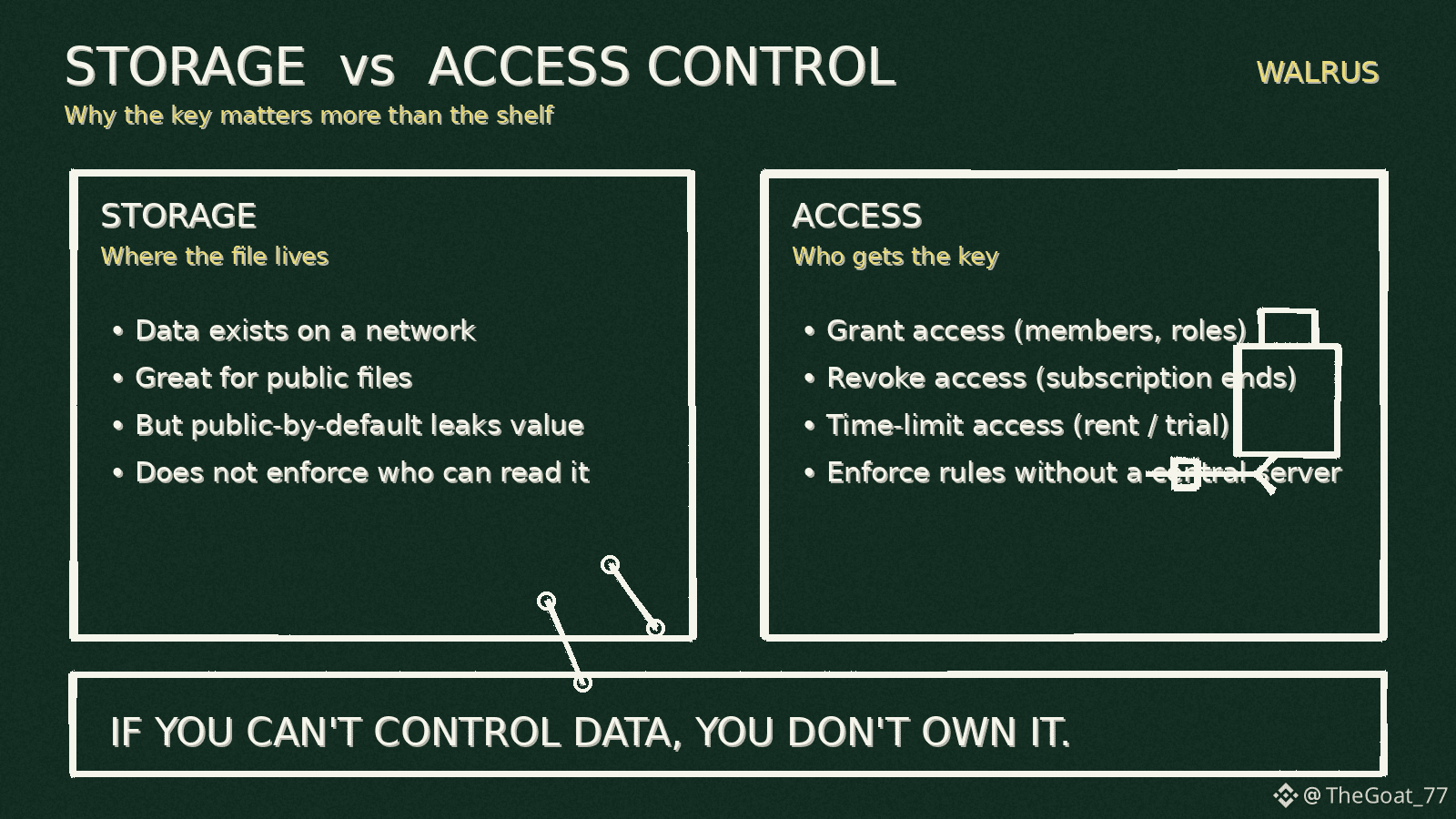
If your data is meant to be public, storage is the main problem.
If your data is meant to be valuable, storage is not the main problem.
Access is.
Most people don’t fail in Web3 because they can’t store data.
They fail because they can’t answer one basic question:
“Who is allowed to read this, and how do I enforce it without a centralized server?”
That’s why the moment I started looking at Walrus differently was when I stopped focusing on “storage” and started focusing on the missing layer most posts ignore: access control, the thing that decides whether a product can exist outside of experiments.
▰▰▰
Let me explain this in the simplest real-world terms.
Public chains made “transparency” sound like a moral victory.
But in actual products, transparency is not always a virtue. It’s often a liability.
If you are building any of these, you cannot be “public by default”: premium creator content, paid research, private AI datasets, business documents, user data, enterprise workflows, even basic membership communities.
Here is the uncomfortable truth:
Without permissioning, decentralization stays a hobby.
Because every serious team eventually hits the same wall.
They either store data publicly and lose control,
or they keep it private on centralized servers and lose the Web3 promise.
There is no third option unless your data layer supports access control that feels native, not hacked together.
▰▰▰
So I started breaking the problem down like a chalkboard in my head.
(1) Storage answers “Where is the file?”
Access control answers “Who gets the key?”
Most people only solve the first.
And then they act surprised when the second destroys their product.
Think about a paid creator video.
If it’s stored somewhere decentralized but anyone can fetch it, you didn’t build a business model. You built a leak.
Think about an AI dataset.
If it’s stored publicly, you didn’t build an AI pipeline. You built free training data for everyone else.
Think about a community.
If “members only” content can be copied by anyone, your membership has no meaning.
So the question isn’t “Can I store it?”
The real question is “Can I control it?”

▰▰▰
(2) The market is full of “encrypt it bro” advice, but that’s not enough.
Encryption without a usable access layer is like putting your house behind a gate… and then leaving the key under the mat.
Real access control must handle: granting access, revoking access, time-limited access, role-based access, and access based on conditions like payments or ownership.
That last one matters more than people realize.
Because Web3 products don’t run on static permissions.
They run on conditions.
If payment is confirmed, unlock content.
If subscription ends, lock it again.
If the user transfers ownership, access moves.
If a collaborator is removed, access stops.
This is exactly where “decentralized storage” narratives die, because most storage systems were not built with this product logic in mind.
▰▰▰
(3) Here’s the part I think most people are underestimating.
Access control is not just a privacy feature.
It’s a market unlock.
The moment you can enforce permissions cleanly, you unlock entire categories: creator monetization that doesn’t rely on centralized platforms, AI data markets that don’t require blind trust, enterprise adoption that isn’t forced to compromise, and consumer apps that actually respect privacy expectations.
And this is why I call it a “serious layer” problem.
Because builders do not adopt infrastructure to feel ideological.
They adopt it because it makes their product possible.
If the access layer is weak, the product stays centralized.
Every time.
▰▰▰
(4) Why I see this as a Walrus angle, not just a generic point.
When I look at Walrus, I’m not interested in the usual promo lines.
I’m interested in whether the infrastructure is being designed to support “real product behavior.”
Real product behavior means: data is large, data is active, data is frequently accessed, and sometimes data must be controlled.
If a network aims to serve data reliably but ignores permissions, it’s incomplete.
If it aims to be used by apps but can’t support access logic, it stays niche.
So I treat the access layer as a signal of maturity.
Because the future isn’t “everything public.”
The future is “public when it should be, private when it must be.”
That middle zone is where adoption lives.
▰▰▰
Now I’ll be fair, because this is where people start overhyping.
Access control is not magic.
It doesn’t guarantee adoption by itself.
Execution still decides everything: reliability, developer experience, latency, cost predictability, and whether builders can ship without fighting the tool.
But if you remove access control from the equation, you remove mainstream use cases.
That’s why I rate it so highly.
In fact, I’d say something even more direct:
The biggest reason Web3 data hasn’t gone mainstream is not storage. It’s control.
And control is exactly what creators and AI teams care about when money is involved.
You can’t build a serious economy on “trust me, don’t download it.”
You need enforcement.
▰▰▰
So my takeaway is simple.
If decentralized data is going to matter beyond narratives, it has to behave like real infrastructure: usable, enforceable, predictable, and compatible with how products actually work.
Storage is the first chapter.
Access control is the chapter that decides whether the book ends early or becomes a series.
Small question for you, and I want a real answer:
Do you think access control will be the feature that finally pushes decentralized data into mainstream products, or will most teams still default to centralized convenience?