1. Wprowadzenie | Zmiana w Modelu-Warstwie w Crypto AI
Dane, modele i obliczenia stanowią trzy podstawowe filary infrastruktury AI — porównywalne do paliwa (dane), silnika (model) i energii (obliczenia) — wszystkie niezbędne. Podobnie jak rozwój infrastruktury w tradycyjnej branży AI, sektor Crypto AI przeszedł podobną trajektorię. Na początku 2024 roku rynek był zdominowany przez zdecentralizowane projekty GPU (takie jak Akash, Render i io.net), charakteryzujące się modelem wzrostu opartym na zasobach, skoncentrowanym na surowej mocy obliczeniowej. Jednak do 2025 roku uwaga branży stopniowo przesunęła się w stronę warstw modelu i danych, co oznaczało przejście od konkurencji w zakresie infrastruktury niskiego poziomu do bardziej zrównoważonego, aplikacyjnego rozwoju warstwy środkowej.
Ogólne modele LLM vs. specjalistyczne SLM
Tradycyjne duże modele językowe (LLMs) w dużej mierze opierają się na ogromnych zbiorach danych i złożonych infrastrukturach treningowych, z rozmiarami parametrów często wahającymi się od 70B do 500B, a pojedyncze sesje treningowe kosztują miliony dolarów. W przeciwieństwie do tego, wyspecjalizowane modele językowe (SLMs) przyjmują lekką paradygmat dostosowywania, który wykorzystuje otwarte modele bazowe, takie jak LLaMA, Mistral lub DeepSeek, i łączy je z małymi, wysokiej jakości zbiorami danych specyficznych dla domeny oraz narzędziami takimi jak LoRA, aby szybko budować modele eksperckie przy znacznie obniżonych kosztach i złożoności.
Co ważne, SLM-y nie są integrowane z powrotem do wag LLM, lecz działają równolegle z LLM poprzez mechanizmy takie jak orkiestracja oparta na agentach, routowanie wtyczek, wymienialne adaptery LoRA i systemy RAG (Generacja Wzbogacona Wyszukiwaniem). Ta modularna architektura zachowuje szerokie pokrycie LLM, jednocześnie poprawiając wydajność w wyspecjalizowanych domenach — umożliwiając wysoce elastyczny, kompozycyjny system AI.
Rola i ograniczenia Crypto AI na poziomie modelu
Projekty Crypto AI z natury mają trudności z bezpośrednim zwiększaniem podstawowych możliwości LLM. Dzieje się tak z powodu:
Wysokie bariery techniczne: Szkolenie modeli podstawowych wymaga masywnych zbiorów danych, mocy obliczeniowej i ekspertyzy inżynieryjnej — możliwości te obecnie posiadają tylko duzi gracze technologiczni w USA (np. OpenAI) i Chinach (np. DeepSeek).
Ograniczenia ekosystemu open-source: Chociaż modele takie jak LLaMA i Mixtral są otwarte, krytyczne przełomy nadal opierają się na instytucjach badawczych poza łańcuchem i zastrzeżonych rurach inżynieryjnych. Projekty on-chain mają ograniczony wpływ na rdzeniu modelu.
Niemniej jednak, Crypto AI może wciąż tworzyć wartość poprzez dostosowywanie SLM-ów na podstawie otwartych modeli bazowych i wykorzystywanie prymitywów Web3, takich jak weryfikowalność i oparte na tokenach zachęty. Pozycjonowane jako "warstwa interfejsu" stosu AI, projekty Crypto AI zazwyczaj przyczyniają się w dwóch głównych obszarach:
Warstwa weryfikacji godności: Rejestrowanie ścieżek generowania modeli, wkładów danych i rekordów użytkowania w łańcuchu zwiększa śledzenie i odporność na manipulacje wynikami AI.
Mechanizmy zachęt: Rodzime tokeny są używane do nagradzania przesyłania danych, wywołań modeli i wykonania agentów — budując pozytywną pętlę zwrotną dla szkolenia i użytkowania modeli.
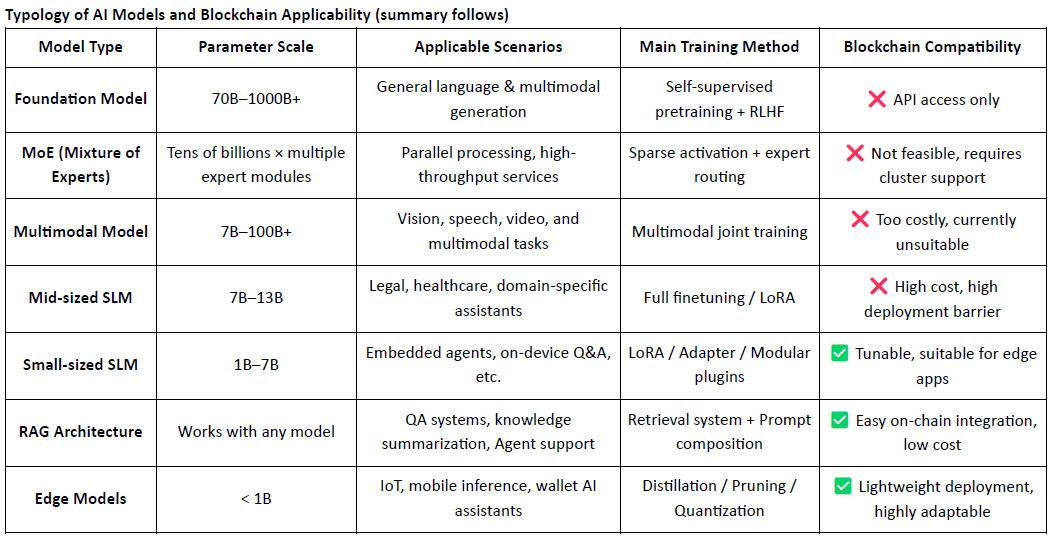
Wykonalne zastosowania projektów Crypto AI skoncentrowanych na modelach są głównie skoncentrowane w trzech obszarach: lekkie dostosowywanie małych SLM-ów, integracja danych on-chain i weryfikacja poprzez architektury RAG oraz lokalne wdrażanie i motywowanie modeli brzegowych. Łącząc weryfikowalność blockchaina z opartymi na tokenach mechanizmami zachęt, Crypto może oferować unikalną wartość w tych scenariuszach modeli o średnich i niskich zasobach, tworząc różnicę w "warstwie interfejsu" stosu AI.
Blockchain AI skoncentrowany na danych i modelach umożliwia przejrzyste, niezmienne zapisy on-chain każdej wkładu do danych i modeli, znacznie zwiększając wiarygodność danych i śledzenie szkolenia modelu. Dzięki mechanizmom inteligentnych kontraktów może automatycznie uruchamiać dystrybucję nagród, gdy dane lub modele są wykorzystywane, przekształcając aktywność AI w mierzalną i wymienną tokenizowaną wartość — tworząc w ten sposób zrównoważony system zachęt. Dodatkowo członkowie społeczności mogą uczestniczyć w zdecentralizowanym zarządzaniu, głosując na wydajność modeli i przyczyniając się do ustalania zasad i iteracji za pomocą tokenów.
2. Przegląd projektu | Wizja OpenLedger dla łańcucha AI
@OpenLedger jest jednym z nielicznych projektów AI blockchain w obecnym rynku, które koncentruje się szczególnie na mechanizmach zachęt dla danych i modeli. Jest pionierem koncepcji "Płatnego AI", mając na celu zbudowanie sprawiedliwego, przejrzystego i kompozycyjnego środowiska wykonawczego AI, które motywuje wkłady danych, deweloperów modeli i budowniczych aplikacji AI do współpracy na jednej platformie — i zarabiania nagród on-chain w oparciu o faktyczne wkłady.
@OpenLedger oferuje kompletny system end-to-end — od "wniosku danych" do "wdrożenia modelu" do "dzielenia przychodów na podstawie użytkowania." Jego moduły podstawowe obejmują:
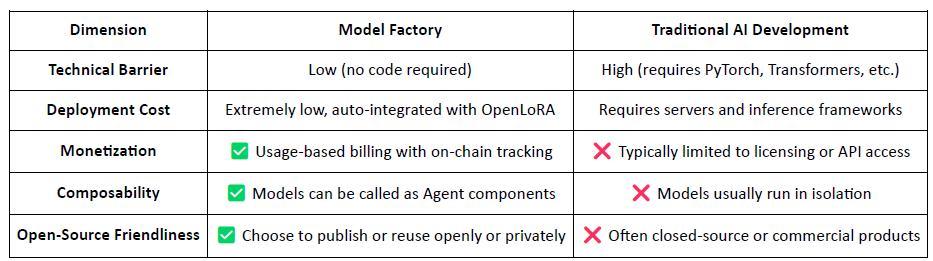
Model Factory: Dostosowywanie bez kodu i wdrażanie niestandardowych modeli przy użyciu otwartych LLM z LoRA;
OpenLoRA: Wspiera współistnienie tysięcy modeli, ładowanych dynamicznie na żądanie w celu obniżenia kosztów wdrożenia;
PoA (Proof of Attribution): Śledzi wykorzystanie on-chain, aby sprawiedliwie przydzielać nagrody na podstawie wkładu;
Datanets: Strukturalne, wspólnotowe sieci danych dostosowane do pionowych domen;
Platforma propozycji modeli: Kompozycyjny, wywoływalny i płatny rynek modeli on-chain.
Razem te moduły tworzą infrastrukturę modeli napędzaną danymi i kompozycyjną — kładąc fundamenty dla gospodarki agentów on-chain.
Po stronie blockchaina, @OpenLedger zbudowane na OP Stack + EigenDA, zapewnia środowisko o wysokiej wydajności, niskich kosztach i weryfikowalne do uruchamiania modeli AI i smart kontraktów:
Zbudowane na OP Stack: Wykorzystuje stos technologiczny Optimism do osiągnięcia wysokiej wydajności i niskich opłat;
Rozliczenie na głównym łańcuchu Ethereum: Zapewnia bezpieczeństwo transakcji i integralność aktywów;
Kompatybilny z EVM: Umożliwia szybkie wdrażanie i skalowalność dla programistów Solidity;
Dostępność danych zasilana przez EigenDA: Redukuje koszty przechowywania, zapewniając jednocześnie weryfikowalny dostęp do danych.
W porównaniu do ogólnych łańcuchów AI, takich jak NEAR — które koncentrują się na infrastrukturze podstawowej, suwerenności danych i frameworku "AI Agents on BOS" — @OpenLedger jest bardziej wyspecjalizowany, mając na celu zbudowanie łańcucha dedykowanego AI skoncentrowanego na danych i zachętach na poziomie modeli. Dąży do uczynienia rozwoju modeli i wywoływania na łańcuchu weryfikowalnymi, kompozycyjnymi i zrównoważonymi pod względem monetyzacji. Jako warstwa zachęt skoncentrowana na modelach w ekosystemie Web3, OpenLedger łączy hosting modeli w stylu HuggingFace, rozliczenia oparte na użytkowaniu w stylu Stripe i kompozycję na łańcuchu w stylu Infura, aby rozwijać wizję "modelu jako aktywa."
3. Kluczowe komponenty i architektura techniczna OpenLedger
3.1 Fabryka modeli bez kodu
ModelFactory to zintegrowana platforma dostosowywania dla dużych modeli językowych (LLMs) @OpenLedger . W przeciwieństwie do tradycyjnych frameworków dostosowywania, oferuje w pełni graficzny interfejs bez kodu, eliminując potrzebę narzędzi wiersza poleceń lub integracji API. Użytkownicy mogą dostosowywać modele przy użyciu zbiorów danych, które zostały uprawnione i zweryfikowane przez @OpenLedger , umożliwiając ciągły przepływ pracy obejmujący autoryzację danych, szkolenie modeli i wdrożenie.
Kluczowe kroki w przepływie pracy obejmują:
Kontrola dostępu do danych: Użytkownicy żądają dostępu do zbiorów danych; po zatwierdzeniu przez dostawców danych zbiory danych są automatycznie połączone z interfejsem treningowym.
Wybór modeli & konfiguracja: Wybierz spośród wiodących LLM (np. LLaMA, Mistral) i skonfiguruj hiperparametry za pomocą GUI.
Lekka adaptacja: Wbudowane wsparcie dla LoRA / QLoRA umożliwia efektywne szkolenie z bieżącym śledzeniem postępów.
Ocena & wdrożenie: Zintegrowane narzędzia pozwalają użytkownikom oceniać wydajność i eksportować modele do wdrożenia lub ponownego użycia w ekosystemie.
Interaktywne interfejsy testowe: Interfejs oparty na czacie pozwala użytkownikom testować dostosowany model bezpośrednio w scenariuszach Q&A.
Przypisanie RAG: Wygenerowane wyniki wzbogacone o źródła zawierają cytaty źródłowe, aby zwiększyć zaufanie i weryfikowalność.
Architektura ModelFactory składa się z sześciu kluczowych modułów, obejmujących weryfikację tożsamości, zarządzanie uprawnieniami do danych, dostosowywanie modeli, ocenę, wdrożenie i śledzenie oparte na RAG, dostarczając bezpieczną, interaktywną i monetyzowalną platformę usług modeli.
Poniżej znajduje się krótki przegląd dużych modeli językowych, które są obecnie wspierane przez ModelFactory:
Seria LLaMA: Jeden z najczęściej przyjmowanych modeli bazowych typu open-source, znany z silnej wydajności ogólnej i żywej społeczności.
Mistral: Wydajna architektura z doskonałą wydajnością wnioskowania, idealna do elastycznego wdrażania w środowiskach o ograniczonych zasobach.
Qwen: Opracowane przez Alibabę, doskonale radzi sobie w zadaniach związanych z językiem chińskim i oferuje silne ogólne możliwości — optymalny wybór dla programistów w Chinach.
ChatGLM: Znany z doskonałej wydajności konwersacyjnej w chińskim, dobrze nadający się do pionowych usług klienta i lokalnych aplikacji.
Deepseek: Doskonale radzi sobie w generowaniu kodu i rozumowaniu matematycznym, co czyni go idealnym asystentem inteligentnego rozwoju.
Gemma: Lekki model wydany przez Google, charakteryzujący się prostą strukturą i łatwością użycia — odpowiedni do szybkiego prototypowania i eksperymentów.
Falcon: Kiedyś punkt odniesienia wydajności, teraz bardziej odpowiedni do badań podstawowych lub testowania porównawczego, chociaż aktywność w społeczności zmniejszyła się.
BLOOM: Oferuje silne wsparcie wielojęzyczne, ale relatywnie słabszą wydajność wnioskowania, co czyni go bardziej odpowiednim do badań dotyczących pokrycia językowego.
GPT-2: Klasyczny wczesny model, obecnie głównie użyteczny do celów edukacyjnych i testowych — wdrożenie w produkcji nie jest zalecane.
Podczas gdy @OpenLedger linia modeli OpenLedger nie obejmuje jeszcze najnowszych modeli MoE o wysokiej wydajności ani architektur multimodalnych, ten wybór nie jest przestarzały. Zamiast tego odzwierciedla strategię "pragmatyzmu przede wszystkim", opartą na realiach wdrożenia on-chain — uwzględniając koszty wnioskowania, kompatybilność RAG, integrację LoRA i ograniczenia środowiska EVM.
Model Factory: Narzędzie bez kodu z wbudowanym przypisaniem wkładów
Jako narzędzie bez kodu, Model Factory integruje wbudowany mechanizm Dowodu Przypisania w wszystkich modelach, aby zapewnić prawa wkładów danych i deweloperów modeli. Oferuje niskie bariery wejścia, rodzimą ścieżkę monetyzacji i kompozycyjność, odróżniając się od tradycyjnych przepływów pracy AI.
Dla deweloperów: Oferuje kompletną linię produkcyjną od tworzenia modeli i dystrybucji do generowania przychodów.
Dla platformy: Umożliwia płynny, kompozycyjny ekosystem dla aktywów modeli.
Dla użytkowników: Modele i agenci mogą być wywoływani i komponowani jak API.
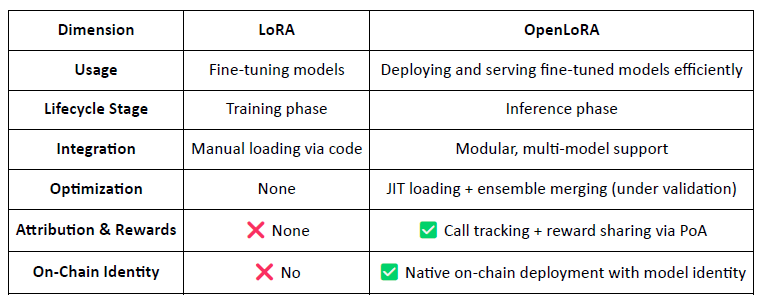
3.2 OpenLoRA, aktywacja aktywów on-chain modeli dostosowanych
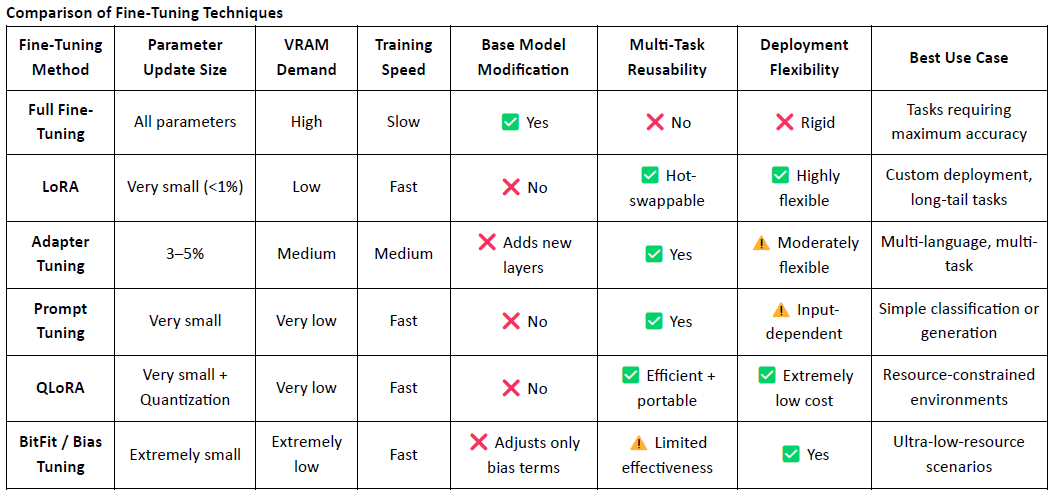
LoRA (Adaptacja Niskiej Rangi) to efektywna technika dostosowywania, która działa poprzez wprowadzenie trenowanych macierzy niskiej rangi do wstępnie wytrenowanego dużego modelu bez zmiany wag oryginalnego modelu, znacząco zmniejszając zarówno koszty treningu, jak i wymagania dotyczące przechowywania.
Tradycyjne duże modele językowe (LLMs), takie jak LLaMA czy GPT-3, często zawierają miliardy — a nawet setki miliardów — parametrów. Aby dostosować te modele do określonych zadań (np. Q&A prawne, konsultacje medyczne), wymaga się dostosowania. Kluczową ideą LoRA jest zamrożenie oryginalnych parametrów modelu i trenowanie tylko nowo dodanych macierzy, co czyni to wysoce efektywnym i łatwym do wdrożenia.
LoRA stał się głównym podejściem do dostosowywania modeli dla wdrożenia i kompozycji natywnych modeli Web3 z powodu swojej lekkiej natury i elastycznej architektury.
OpenLoRA to lekkie ramy wnioskowania opracowane przez @OpenLedger specjalnie do wdrażania wielu modeli i udostępniania zasobów GPU. Jego głównym celem jest rozwiązanie problemów wysokich kosztów wdrożenia, niskiej użyteczności modeli i nieefektywnego wykorzystania GPU — czyniąc wizję "Płatnego AI" praktycznie wykonalną.
Modularna architektura dla skalowalnego serwowania modeli
OpenLoRA składa się z kilku modułowych komponentów, które razem umożliwiają skalowalne, opłacalne serwowanie modeli:
Przechowywanie adapterów LoRA: Dostosowane adaptery LoRA są hostowane na @OpenLedger i ładowane na żądanie. To unika wstępnego ładowania wszystkich modeli do pamięci GPU i oszczędza zasoby.
Hosting modeli & Warstwa łączenia adapterów: Wszystkie adaptery dzielą wspólny model bazowy. Podczas wnioskowania adaptery są dynamicznie łączone, wspierając zespołowe wnioskowanie wieloma adapterami dla zwiększonej wydajności.
Silnik wnioskowania: Wprowadza optymalizacje na poziomie CUDA, w tym szybką uwagę, paginowaną uwagę i SGMV w celu poprawy wydajności.
Router żądań & Streamowanie tokenów: Dynamicznie kieruje żądania wnioskowania do odpowiedniego adaptera i streamuje tokeny za pomocą zoptymalizowanych jąder.
Przepływ pracy wnioskowania end-to-end
Proces wnioskowania podąża dojrzałą i praktyczną ścieżką:
Inicjalizacja modelu bazowego: Modele bazowe, takie jak LLaMA 3 lub Mistral, są ładowane do pamięci GPU.
Dynamiczne ładowanie adapterów: Na żądanie, określone adaptery LoRA są pobierane z Hugging Face, Predibase lub lokalnego przechowywania.
Merging & Aktywacja: Adaptery są łączone z modelem bazowym w czasie rzeczywistym, wspierając wykonanie zespołowe.
Wykonanie wnioskowania & Streamowanie tokenów: Połączony model generuje wyjście z poziomem streamingu tokenów, wspieranym przez kwantyzację zarówno dla prędkości, jak i efektywności pamięci.
Zwolnienie zasobów: Adaptery są odładowywane po wykonaniu, uwalniając pamięć i umożliwiając efektywną rotację tysięcy dostosowanych modeli na pojedynczym GPU.
Kluczowe optymalizacje
OpenLoRA osiąga wyższą wydajność poprzez:
Ładowanie adapterów JIT (Just-In-Time) w celu minimalizacji zużycia pamięci.
Tensorowa równoległość i paginowana uwaga w celu obsługi dłuższych sekwencji i współbieżnego wykonania.
Merging Adapterów dla kompozycyjnej fuzji modeli.
Szybka uwaga, wstępnie skompilowane jądra CUDA i kwantyzacja FP8/INT8 dla szybszego, o niższej latencji wnioskowania.
Te optymalizacje umożliwiają wysokowydajne, niskokosztowe wnioskowanie z wieloma modelami nawet w środowiskach z pojedynczym GPU — szczególnie dobrze nadają się do modeli długiego ogona, niszowych agentów i wysoce spersonalizowanej AI.
OpenLoRA: Przekształcanie modeli LoRA w aktywa Web3
W przeciwieństwie do tradycyjnych frameworków LoRA skoncentrowanych na dostosowywaniu, OpenLoRA przekształca serwowanie modeli w natywną warstwę monetyzacyjną Web3, czyniąc każdy model:
Identyfikowalne on-chain (poprzez ID modelu)
Ekonomicznie motywowane poprzez użytkowanie
Kompozycyjne w agentach AI
Rozdzielane nagrody za pomocą mechanizmu PoA
To umożliwia traktowanie każdego modelu jako aktywa:
Prognoza wydajności
Dodatkowo, @OpenLedger wydał przyszłe benchmarki wydajności dla OpenLoRA. W porównaniu do tradycyjnych wdrożeń modeli z pełnymi parametrami, zużycie pamięci GPU jest znacznie zmniejszone do 8–12 GB, czas przełączania modeli teoretycznie nie przekracza 100 ms, wydajność może osiągnąć ponad 2000 tokenów na sekundę, a opóźnienie utrzymuje się w granicach 20–50 ms.
Chociaż te liczby są technicznie osiągalne, powinny być rozumiane jako prognozy górne, a nie gwarantowana wydajność dzienna. W rzeczywistych środowiskach produkcyjnych rzeczywiste wyniki mogą się różnić w zależności od konfiguracji sprzętowych, strategii harmonogramowania i złożoności zadań.
3.3 Datanets: Od własności danych do inteligencji danych
Wysokiej jakości, specyficzne dla domeny dane stały się kluczowym aktywem do budowy modeli o wysokiej wydajności. Datanets służą jako @OpenLedger podstawowa infrastruktura dla "danych jako aktywa", umożliwiając zbieranie, walidację i dystrybucję uporządkowanych zbiorów danych w ramach zdecentralizowanych sieci. Każdy Datanet działa jako magazyn danych specyficzny dla domeny, w którym wkłady przesyłają dane, które są weryfikowane i przypisane w łańcuchu. Dzięki przejrzystym uprawnieniom i zachętom, Datanets umożliwiają zaufane, społeczne kuratowanie danych do szkolenia i dostosowywania modeli.
W przeciwieństwie do projektów takich jak Vana, które koncentrują się głównie na własności danych, @OpenLedger wykracza poza zbieranie danych, przekształcając dane w inteligencję. Dzięki swoim trzem zintegrowanym komponentom — Datanets (współpracujące, przypisane zbiory danych), Fabryka modeli (narzędzia do dostosowywania bez kodu) i OpenLoRA (śledzone, kompozycyjne adaptery modeli) — OpenLedger rozszerza wartość danych w pełnym cyklu szkolenia modeli i użytkowania on-chain. Gdzie Vana podkreśla "kto posiada dane", OpenLedger koncentruje się na "jak dane są szkolone, wywoływane i nagradzane", pozycjonując te dwa jako komplementarne filary w stosie AI Web3: jeden dla zapewnienia własności, drugi dla umożliwienia monetyzacji.
3.4 Dowód przypisania: Pr redefiniowanie warstwy zachęt dla dystrybucji wartości
Dowód przypisania (PoA) jest @OpenLedger głównym mechanizmem OpenLedger do łączenia wkładów z nagrodami. Kryptycznie rejestruje każdy wkład danych i wywołanie modelu w łańcuchu, zapewniając, że wkłady otrzymują sprawiedliwą rekompensatę, gdy ich wkłady generują wartość. Proces przebiega następująco:
Przesyłanie danych: Użytkownicy przesyłają uporządkowane, specyficzne dla domeny zbiory danych i rejestrują je w łańcuchu w celu przypisania.
Ocena wpływu: System ocenia znaczenie szkolenia każdego zbioru danych na poziomie każdego wnioskowania, biorąc pod uwagę jakość treści i reputację wkładu.
Weryfikacja szkolenia: Dzienniki śledzą, które zbiory danych były faktycznie używane w szkoleniu modelu, umożliwiając weryfikowalne dowody wkładu.
Dystrybucja nagród: Wkłady są nagradzane w tokenach na podstawie skuteczności danych i ich wpływu na wyniki modelu.
Zarządzanie jakością: Niskiej jakości, spamowe lub złośliwe dane są karane, aby utrzymać integralność szkolenia.
W porównaniu do architektury zachęt opartych na sieciach Bittensor i reputacji, która szeroko nagradza obliczenia, dane i funkcje rankingowe, @OpenLedger koncentruje się na realizacji wartości na poziomie modelu. PoA nie jest tylko mechanizmem nagród — jest to wieloetapowa struktura przypisania dla przejrzystości, pochodzenia i rekompensaty w całym cyklu życia: od danych do modeli do agentów. Przekształca każde wywołanie modelu w śledzone, nagradzane zdarzenie, zakotwiczając weryfikowalny ślad wartości, który dostosowuje zachęty w całym łańcuchu aktywów AI.
Przypisanie Generacji Wzbogaconej Wyszukiwaniem (RAG)
RAG (Generacja Wzbogacona Wyszukiwaniem) to architektura AI, która poprawia wyniki modeli językowych poprzez pobieranie zewnętrznej wiedzy — rozwiązując problem halucynacji lub nieaktualnych informacji. @OpenLedger wprowadza przypisanie RAG, aby zapewnić, że wszelkie pobrane treści używane w generacji modelu są śledzone, weryfikowalne i nagradzane.
Przepływ pracy przypisania RAG:
Zapytanie użytkownika → Pobieranie danych: AI pobiera odpowiednie dane z indeksowanych zbiorów danych @OpenLedger (Datanets).
Generowanie odpowiedzi z śledzonym użyciem: Pobierane treści są używane w odpowiedzi modelu i rejestrowane w łańcuchu.
Nagrody dla wkładów: Wkłady danych są nagradzane w zależności od funduszy i znaczenia pobrania.
Przejrzyste cytaty: Wyniki modeli zawierają linki do oryginalnych źródeł danych, co zwiększa zaufanie i weryfikowalność.
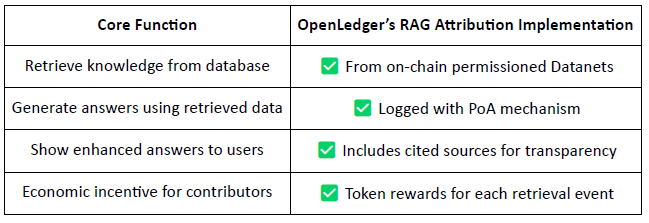
W istocie, @OpenLedger 's przypisanie RAG zapewnia, że każda odpowiedź AI jest śledzona do zweryfikowanego źródła danych, a wkłady są nagradzane na podstawie częstotliwości użytkowania, co umożliwia zrównoważoną pętlę zachęt. Ten system nie tylko zwiększa przejrzystość wyników, ale także kładzie fundamenty pod weryfikowalną, monetyzowalną i zaufaną infrastrukturę AI.
4. Postępy projektu i współpraca w ekosystemie
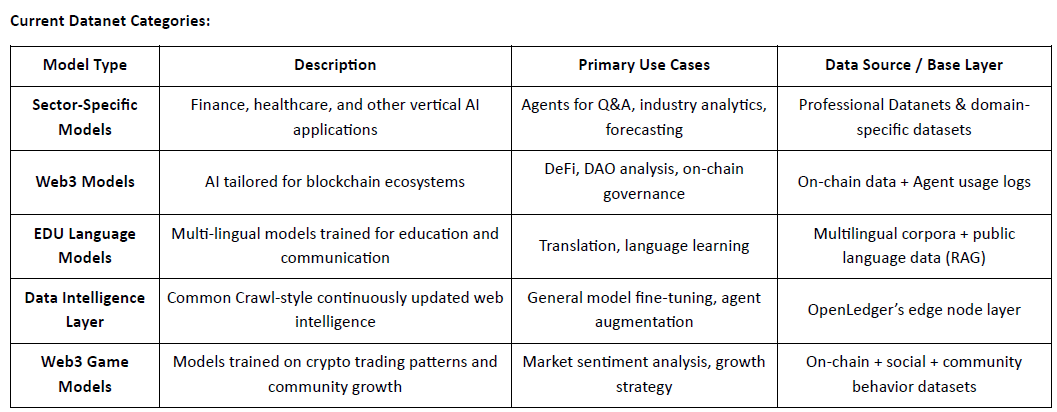
@OpenLedger oficjalnie uruchomiło swój testnet, a pierwsza faza koncentruje się na Warstwie Inteligencji Danych — repozytorium danych internetowych wspieranym przez społeczność. Ta warstwa agreguje, wzbogaca, klasyfikuje i strukturalizuje surowe dane w gotową do modelu inteligencję odpowiednią do szkolenia specjalistycznych LLM na @OpenLedger . Członkowie społeczności mogą uruchamiać węzły brzegowe na swoich osobistych urządzeniach, aby zbierać i przetwarzać dane. W zamian uczestnicy zdobywają punkty na podstawie czasu pracy i wkładów w zadania. Punkty te będą później wymieniane na $OPEN tokeny, a mechanizm konwersji zostanie ogłoszony przed wydarzeniem generacji tokenów (TGE).

Epoka 2: Wdrożenie Datanets
Druga faza testnetu wprowadza Datanets, system wkładów tylko dla białej listy. Uczestnicy muszą przejść wstępną ocenę, aby uzyskać dostęp do zadań takich jak walidacja danych, klasyfikacja lub adnotacja. Nagrody są przyznawane na podstawie dokładności, poziomu trudności i rankingu w tabeli liderów.
Mapa drogowa: W kierunku zdecentralizowanej gospodarki AI
@OpenLedger ma na celu zamknięcie pętli od pozyskiwania danych do wdrożenia agenta, tworząc pełnostackowy zdecentralizowany łańcuch wartości AI:
Faza 1: Warstwa Inteligencji Danych
Węzły społeczności zbierają i przetwarzają dane internetowe w czasie rzeczywistym do uporządkowanego przechowywania.Faza 2: Wkłady społeczności
Społeczność przyczynia się do walidacji i opinii, tworząc "Złoty Zbiór Danych" do szkolenia modeli.Faza 3: Buduj modele & przejmij
Użytkownicy dostosowują i przejmują własność specjalistycznych modeli, umożliwiając monetyzację i kompozycję.Faza 4: Buduj agentów
Modele mogą być przekształcane w inteligentne agentów on-chain, wdrażane w różnych scenariuszach i zastosowaniach.
Partnerzy ekosystemu: @OpenLedger współpracuje z wiodącymi graczami w obszarze obliczeń, infrastruktury, narzędzi i aplikacji AI:
Obliczenia & Hosting: Aethir, Ionet, 0G
Infrastruktura Rollup: AltLayer, Etherfi, EigenLayer AVS
Narzędzia & Interoperacyjność: Ambios, Kernel, Web3Auth, Intract
Agenci AI & Budowniczowie modeli: Giza, Gaib, Exabits, FractionAI, Mira, NetMind
Zasięg marki poprzez globalne szczyty: W ciągu ostatniego roku @OpenLedger zorganizowało szczyty DeAI na głównych wydarzeniach Web3, w tym Token2049 Singapur, Devcon Tajlandia, Consensus Hongkong i ETH Denver. Te spotkania zgromadziły najlepszych prelegentów i projekty w dziedzinie zdecentralizowanej AI. Jako jeden z nielicznych zespołów na poziomie infrastruktury, które konsekwentnie organizują wydarzenia branżowe wysokiej jakości, @OpenLedger znacznie zwiększyło swoją widoczność i wartość marki w społeczności deweloperów oraz szerszym ekosystemie Crypto AI — kładąc solidne podstawy dla przyszłej aktywności i efektów sieciowych.
5. Finansowanie i tło zespołu
@OpenLedger zakończone w lipcu 2024 roku rundą seedową o wartości 11,2 miliona dolarów, wspierane przez Polychain Capital, Borderless Capital, Finality Capital, Hashkey oraz czołowych aniołów, w tym Sreerama Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda), Trevora. Środki te będą głównie wykorzystane na rozwój sieci AI, w tym mechanizmów motywacyjnych modeli, infrastruktury danych i szerszego wdrożenia ekosystemu aplikacji agentów.@OpenLedger 's sieci AI, w tym mechanizmów motywacyjnych modeli, infrastruktury danych i szerszego wdrożenia ekosystemu aplikacji agentów.
@OpenLedger Openledger został założony przez Ram Kumara, głównego współpracownika @OpenLedger OpenLedger, który jest przedsiębiorcą z siedzibą w San Francisco z solidnymi podstawami w technologii AI/ML i blockchain. Przynosi połączenie wglądu rynkowego, wiedzy technicznej i strategicznego przywództwa do projektu. Ram wcześniej współprowadził firmę zajmującą się badaniami i rozwojem blockchain i AI/ML z rocznymi przychodami przekraczającymi 35 milionów dolarów i odegrał kluczową rolę w rozwoju partnerstw o wysokim wpływie, w tym strategicznego joint venture z filią Walmarku. Jego praca koncentruje się na rozwoju ekosystemu i budowaniu sojuszy, które napędzają rzeczywistą adopcję w różnych branżach.
6. Tokenomika i zarządzanie
$OPEN jest rodzinnym tokenem użytkowym ekosystemu @OpenLedger . Stanowi podstawę zarządzania platformą, przetwarzania transakcji, dystrybucji zachęt i operacji agentów AI — tworząc podstawę ekonomiczną dla zrównoważonej, on-chain cyrkulacji modeli AI i aktywów danych. Chociaż ramy tokenomiki pozostają na wczesnym etapie i są przedmiotem udoskonalenia, @OpenLedger zbliża się do wydarzenia generacji tokenów (TGE) w miarę rosnącej aktywności w Azji, Europie i na Bliskim Wschodzie.
Kluczowe użyteczności $OPEN obejmują:
Zarządzanie & podejmowanie decyzji:
Posiadacze OPEN mogą głosować w kluczowych kwestiach, takich jak finansowanie modeli, zarządzanie agentami, aktualizacje protokołów i alokacja skarbu.Token gazowy & płatności za opłaty: OPEN pełni rolę rodzimy token gazowy dla @OpenLedger L2, umożliwiając natywne modele opłat gazowych i redukując zależność od ETH.
Zachęty oparte na przypisaniu:
Deweloperzy dostarczający wysokiej jakości zbiory danych, modele lub usługi agentów są nagradzani w OPEN na podstawie faktycznego użytkowania i wpływu.Mosty między łańcuchami:
OPEN wspiera interoperacyjność między @OpenLedger L2 a Ethereum L1, zwiększając przenośność i kompozycyjność modeli i agentów.Staking dla agentów AI:
Obsługa agenta AI wymaga stakowania OPEN. Agentów osiągających słabe wyniki lub złośliwych grozi obcięcie, co motywuje do świadczenia wysokiej jakości i niezawodnych usług.
W przeciwieństwie do wielu modeli zarządzania, które ściśle wiążą wpływ z posiadaniem tokenów, @OpenLedger wprowadza system zarządzania oparty na zasługach, w którym moc głosów jest powiązana z tworzeniem wartości. Ten projekt priorytetuje wkłady, które aktywnie budują, doskonalą lub wykorzystują modele i zbiory danych, a nie pasywnych posiadaczy kapitału. Dzięki temu @OpenLedger zapewnia długoterminową zrównoważoność i broni przed spekulacyjną kontrolą — pozostając zgodnym z wizją przejrzystej, sprawiedliwej i wspólnotowej gospodarki AI.
7. Krajobraz rynkowy i analiza konkurencji
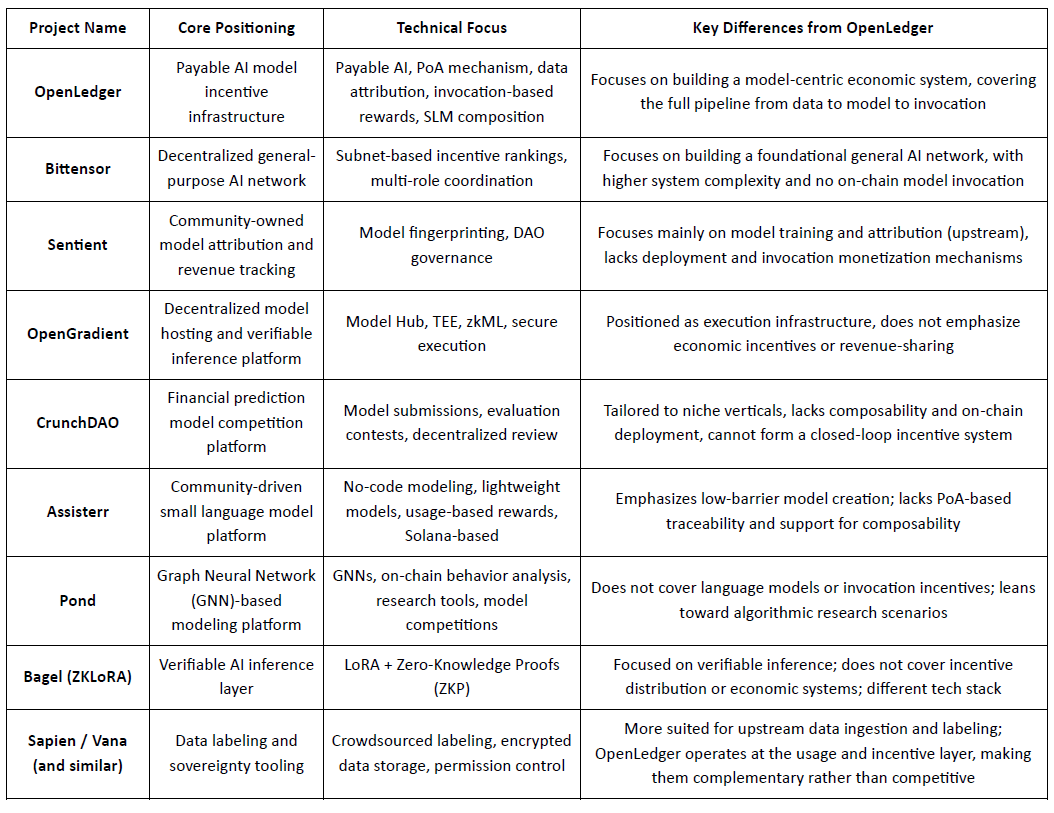
@OpenLedger , pozycjonowane jako infrastruktura zachęt dla "Płatnego AI", ma na celu zapewnienie weryfikowalnych, przypisywalnych i zrównoważonych ścieżek realizacji wartości zarówno dla wkładów danych, jak i deweloperów modeli. Koncentrując się na wdrożeniu on-chain, zachętach opartych na użytkowaniu i kompozycji modułowych agentów, zbudowało wyraźną architekturę systemu, która wyróżnia się w sektorze Crypto AI. Pomimo braku istniejących projektów, które w pełni replikują ramy end-to-end @OpenLedger , pokazuje silną porównywalność i potencjalną synergię z kilkoma reprezentatywnymi protokołami w obszarach takich jak mechanizmy zachęt, monetyzacja modeli i przypisanie danych.
Warstwa zachęt: OpenLedger vs. Bittensor
Bittensor jest jedną z najbardziej reprezentatywnych zdecentralizowanych sieci AI, działającą w oparciu o współpracujący system wieloroli napędzany przez subnets i ocenę reputacji, z jego tokenem $TAO motywującym uczestnictwo modeli, danych i węzłów rankingowych. W przeciwieństwie do tego, @OpenLedger koncentruje się na dzieleniu się przychodami poprzez wdrożenie on-chain i wywoływanie modeli, kładąc nacisk na lekką infrastrukturę i koordynację agentów. Chociaż oba mają wspólne podstawy w logice zachęt, różnią się złożonością systemu i warstwą ekosystemu: Bittensor dąży do bycia podstawową warstwą dla zgeneralizowanej zdolności AI, podczas gdy @OpenLedger służy jako warstwa realizacji wartości na poziomie aplikacji.
Własność modelu & zachęty do wywoływania: OpenLedger vs. Sentient
Sentient wprowadza koncepcję "OML (Open, Monetizable, Loyal) AI", podkreślając modele należące do społeczności z unikalną tożsamością i śledzeniem dochodów poprzez Fingerprinting Modeli. Chociaż oba projekty opowiadają się za uznaniem wkładów, Sentient koncentruje się bardziej na etapie szkolenia i tworzenia modeli, podczas gdy @OpenLedger koncentruje się na wdrożeniu, wywołaniu i dzieleniu się przychodami. To sprawia, że oba są komplementarne na różnych etapach łańcucha wartości AI — Sentient w górę, @OpenLedger w dół.
Hosting modeli & Weryfikowalne wykonanie: OpenLedger vs. OpenGradient
OpenGradient koncentruje się na budowaniu bezpiecznej infrastruktury wnioskowania przy użyciu TEE i zkML, oferując zdecentralizowany hosting modeli i zaufane wykonanie. @OpenLedger z kolei jest zbudowane wokół cyklu monetyzacji po wdrożeniu, łącząc Model Factory, OpenLoRA, PoA i Datanets w kompletną pętlę "szkolenie — wdrożenie — wywołanie — zarobek". Oba działają na różnych warstwach cyklu życia modelu — OpenGradient na integralności wykonania, @OpenLedger na ekonomicznej motywacji i kompozycji — z wyraźnym potencjałem synergi.
Modele z crowdsourcingu & Ocena: OpenLedger vs. CrunchDAO
CrunchDAO koncentruje się na zdecentralizowanych konkursach predykcyjnych w finansach, nagradzając społeczności na podstawie złożonej wydajności modelu. Chociaż dobrze wpisuje się w aplikacje pionowe, brakuje mu możliwości kompozycji modeli i wdrożenia on-chain. @OpenLedger oferuje zjednoczoną ramę wdrożeniową i kompozycyjną fabrykę modeli, z szerszym zastosowaniem i rodzimymi mechanizmami monetyzacji — czyniąc oba platformy komplementarnymi w swoich strukturach zachęt.
Modele lekkie napędzane przez społeczność: OpenLedger vs. Assisterr
Assisterr, zbudowany na Solanie, zachęca do tworzenia małych modeli językowych (SLMs) poprzez narzędzia bez kodu i system nagród oparty na $sASRR. W przeciwieństwie do tego, @OpenLedger kładzie większy nacisk na śledzenie przypisania i pętle przychodów w różnych warstwach danych, modeli i wywołań, wykorzystując swój mechanizm PoA do dokładnej dystrybucji zachęt. Assisterr lepiej nadaje się do współpracy społecznościowej o niskiej barierze, podczas gdy @OpenLedger koncentruje się na infrastrukturze modeli nadających się do ponownego użycia i kompozycji.
Fabryka modeli: OpenLedger vs. Pond
Chociaż zarówno @OpenLedger , jak i Pond oferują moduły "Fabryka modeli", ich docelowi użytkownicy i filozofie projektowania znacząco się różnią. Pond koncentruje się na modelowaniu opartym na sieciach neuronowych grafowych (GNN) w celu analizy zachowania on-chain, kierując się do naukowców danych i badaczy algorytmów poprzez model rozwoju oparty na rywalizacji. W przeciwieństwie do tego, OpenLedger oferuje lekkie narzędzia do dostosowywania oparte na modelach językowych (np. LLaMA, Mistral), zaprojektowane dla programistów i użytkowników nietechnicznych z interfejsem bez kodu. Kładzie nacisk na automatyczne przepływy zachęt on-chain i współpracę w integracji danych z modelami, dążąc do zbudowania sieci wartości AI napędzanej danymi.
Weryfikowalna ścieżka wnioskowania: OpenLedger vs. Bagel
Bagel wprowadza ZKLoRA, ramy dla kryptograficznie weryfikowalnego wnioskowania z wykorzystaniem modeli dostosowanych do LoRA i dowodów zerowej wiedzy (ZKP), aby zapewnić poprawność wykonania poza łańcuchem. W międzyczasie, @OpenLedger wykorzystuje dostosowywanie LoRA z OpenLoRA, aby umożliwić skalowalne wdrożenie i dynamiczne wywoływanie modeli. @OpenLedger również zajmuje się weryfikowalnym wnioskowaniem z innej perspektywy — poprzez przypisanie dowodu przypisania do każdego wyniku modelu, wyjaśniając, które dane przyczyniły się do wnioskowania i w jaki sposób. To zwiększa przejrzystość, nagradza najlepszych wkładów danych i buduje zaufanie w proces podejmowania decyzji. Podczas gdy Bagel koncentruje się na integralności obliczeń, OpenLedger wprowadza odpowiedzialność i wyjaśnialność poprzez przypisanie.
Ścieżka współpracy z danymi: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien i FractionAI koncentrują się na zdecentralizowanym etykietowaniu danych, podczas gdy Vana i Irys specjalizują się w własności danych i suwerenności. @OpenLedger , poprzez swoje moduły Datanets + PoA, śledzi wykorzystanie danych wysokiej jakości i odpowiednio rozdziela zachęty on-chain. Te platformy służą różnym warstwom łańcucha wartości danych — etykietowanie i zarządzanie prawami w górę, monetyzacja i przypisanie w dół — czyniąc je naturalnie współpracującymi, a nie konkurencyjnymi.
Podsumowując, OpenLedger zajmuje pozycję w warstwie średniej w obecnym ekosystemie Crypto AI jako protokół łączący aktywa modeli on-chain i oparte na zachętach wywoływanie. Łączy sieci szkoleniowe i platformy danych w górę z warstwami agentów i aplikacjami końcowymi w dół — stając się krytyczną infrastrukturą, która łączy podaż wartości modeli z rzeczywistym wykorzystaniem.
8. Wnioski | Od danych do modeli — niech AI również zarabia
@OpenLedger ma na celu zbudowanie infrastruktury "modelu jako aktywa" dla świata Web3. Tworząc pełnopętlową pętlę wdrożenia w łańcuchu, zachęt do użytkowania, przypisania własności i kompozycji agentów, wprowadza modele AI do naprawdę śledzonego, monetyzowalnego i współpracy gospodarczego systemu po raz pierwszy.
Jego stos technologiczny — składający się z Model Factory, OpenLoRA, PoA i Datanets — zapewnia:
narzędzia szkoleniowe o niskiej barierze dla programistów,
sprawiedliwe przypisanie przychodów dla wkładów danych,
kompozycyjne mechanizmy wywoływania modeli i dzielenia się nagrodami dla aplikacji.
To kompleksowo aktywuje długo pomijane końce łańcucha wartości AI: dane i modele.
Zamiast być tylko kolejną wersją Web3 HuggingFace, @OpenLedger bardziej przypomina hybrydę HuggingFace + Stripe + Infura, oferując hosting modeli, rozliczenia oparte na użytkowaniu i programowalny dostęp do API on-chain. W miarę jak trendy w zakresie aktywów danych, autonomii modeli i modularizacji agentów przyspieszają, OpenLedger jest dobrze przygotowane, aby stać się centralnym łańcuchem AI w paradygmacie "Płatny AI".

