Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Niniejszy niezależny raport badawczy jest wspierany przez IOSG Ventures, a proces badawczy i pisania był inspirowany raportem o uczeniu wzmacniającym autorstwa Sama Lehmana (Pantera Capital), dziękujemy Benowi Fieldingowi (Gensyn.ai), Gao Yuan (Gradient), Samuelowi Dare i Erfanowi Miahi (Covenant AI), Shashankowi Yadav (Fraction AI), Chao Wangowi za cenne sugestie dotyczące tego dokumentu. Dokument ten dąży do obiektywnej i dokładnej treści, część poglądów wiąże się z subiektywnymi ocenami, co nieuchronnie może prowadzić do odchyleń, prosimy czytelników o zrozumienie.
Sztuczna inteligencja przechodzi od statystycznego uczenia, opartego głównie na "dopasowywaniu wzorców", do systemu umiejętności skoncentrowanego na "strukturalnym wnioskowaniu", a znaczenie post-treningu szybko rośnie. Pojawienie się DeepSeek-R1 oznacza paradigmowy zwrot w uczeniu wzmacniającym w erze dużych modeli, powstaje konsensus branżowy: wstępne uczenie buduje uniwersalną podstawę modeli, a uczenie wzmacniające nie jest już tylko narzędziem do dostosowywania wartości, ale udowodniono, że może systematycznie poprawić jakość łańcucha wnioskowania i zdolność do podejmowania złożonych decyzji, stopniowo ewoluując w technologiczną ścieżkę ciągłego podnoszenia poziomu inteligencji.
W międzyczasie, Web3 przekształca relacje produkcyjne AI za pomocą zdecentralizowanej sieci obliczeniowej i systemu nagród kryptograficznych, podczas gdy uczenie ze wzmocnieniem wymaga strukturalnie rolloutów, sygnałów nagród i weryfikowalnego szkolenia, co naturalnie współgra z współpracą mocy obliczeniowej blockchain, podziałem nagród i weryfikowalnym wykonaniem. Niniejszy raport systematycznie analizuje paradygmaty szkolenia AI i zasady technologii uczenia ze wzmocnieniem, dowodząc strukturalnych zalet uczenia ze wzmocnieniem × Web3 oraz analizując projekty takie jak Prime Intellect, Gensyn, Nous Research, Gradient, Grail i Fraction AI.
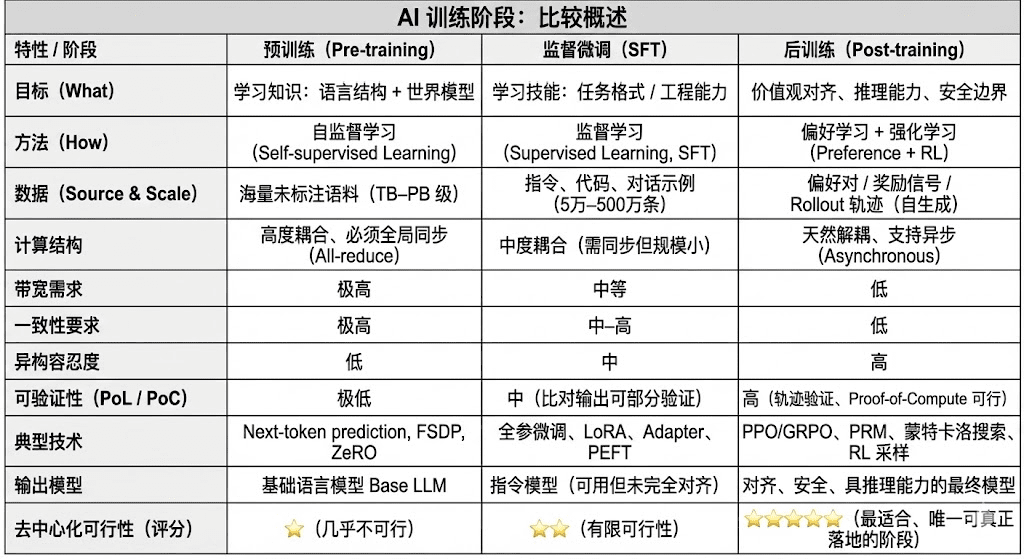
Pierwsza. Trzy etapy szkolenia AI: wstępne szkolenie, drobne dostosowanie instrukcji i dostosowanie po szkoleniu
Nowoczesne modele językowe (LLM) w cyklu życia treningu są zazwyczaj podzielone na trzy podstawowe etapy: wstępne szkolenie (Pre-training), nadzorowane dostosowanie (SFT) i szkolenie po (Post-training/RL). Te etapy pełnią odpowiednio funkcje „budowanie modelu świata - wprowadzenie zdolności do zadań - kształtowanie wnioskowania i wartości”, a ich struktura obliczeniowa, wymagania danych i trudności w weryfikacji decydują o stopniu dopasowania do decentralizacji.
Wstępne szkolenie (Pre-training) polega na budowaniu statystycznej struktury językowej modelu i międzymodalnego modelu świata poprzez uczenie się samodzielne na dużą skalę, co jest fundamentem zdolności LLM. Ten etap wymaga szkolenia na trylionach danych w sposób globalny, polegając na tysiącach lub dziesiątkach tysięcy jednorodnych klastrów H100, co zajmuje aż 80-95% kosztów, jest ekstremalnie wrażliwe na przepustowość i prawa autorskie danych, dlatego musi odbywać się w silnie scentralizowanym środowisku.
Dostosowanie (Supervised Fine-tuning) służy do wprowadzenia zdolności do zadań i formatów instrukcji, ilość danych jest mała, a koszt wynosi około 5-15%, dostosowanie może odbywać się zarówno w trybie pełnego treningu, jak i poprzez parametry efektywne metodą (PEFT), gdzie LoRA, Q-LoRA i Adapter są głównymi rozwiązaniami w przemyśle. Jednak nadal wymaga synchronizacji gradientów, co ogranicza jego potencjał do decentralizacji.
Szkolenie po (Post-training) składa się z wielu iteracyjnych podfaz, które decydują o zdolności wnioskowania modelu, wartościach i granicach bezpieczeństwa, a jego metody obejmują zarówno systemy uczenia ze wzmocnieniem (RLHF, RLAIF, GRPO), jak i metody optymalizacji preferencji bez RL (DPO) oraz modele nagród za proces (PRM). Na tym etapie ilość danych i koszty są niższe (5-10%), głównie koncentrują się na rolloutach i aktualizacjach strategii; naturalnie wspiera to asynchroniczne i rozproszone wykonanie, węzły nie muszą posiadać pełnych wag, łącząc weryfikowalne obliczenia i zachęty łańcuchowe, można stworzyć otwartą, zdecentralizowaną sieć szkoleniową, co czyni ją najbardziej odpowiednią do Web3.
Druga. Panorama technologii uczenia ze wzmocnieniem: architektura, ramy i aplikacje
2.1 Architektura systemu uczenia ze wzmocnieniem i kluczowe elementy
Uczenie ze wzmocnieniem (Reinforcement Learning, RL) napędza model do samodzielnego doskonalenia zdolności decyzyjnych poprzez „interakcje ze środowiskiem - zwroty nagród - aktualizacje strategii”, a jego podstawowa struktura może być postrzegana jako sprzężenie zwrotne złożone z stanu, akcji, nagród i strategii. Pełny system RL zazwyczaj zawiera trzy rodzaje komponentów: Policy (sieć strategii), Rollout (próbkowanie doświadczeń) i Learner (aktualizator strategii). Interakcje strategii z otoczeniem generują trajektorie, a Learner aktualizuje strategię na podstawie sygnałów nagród, co prowadzi do ciągłego iteracyjnego i optymalizowanego procesu uczenia się:
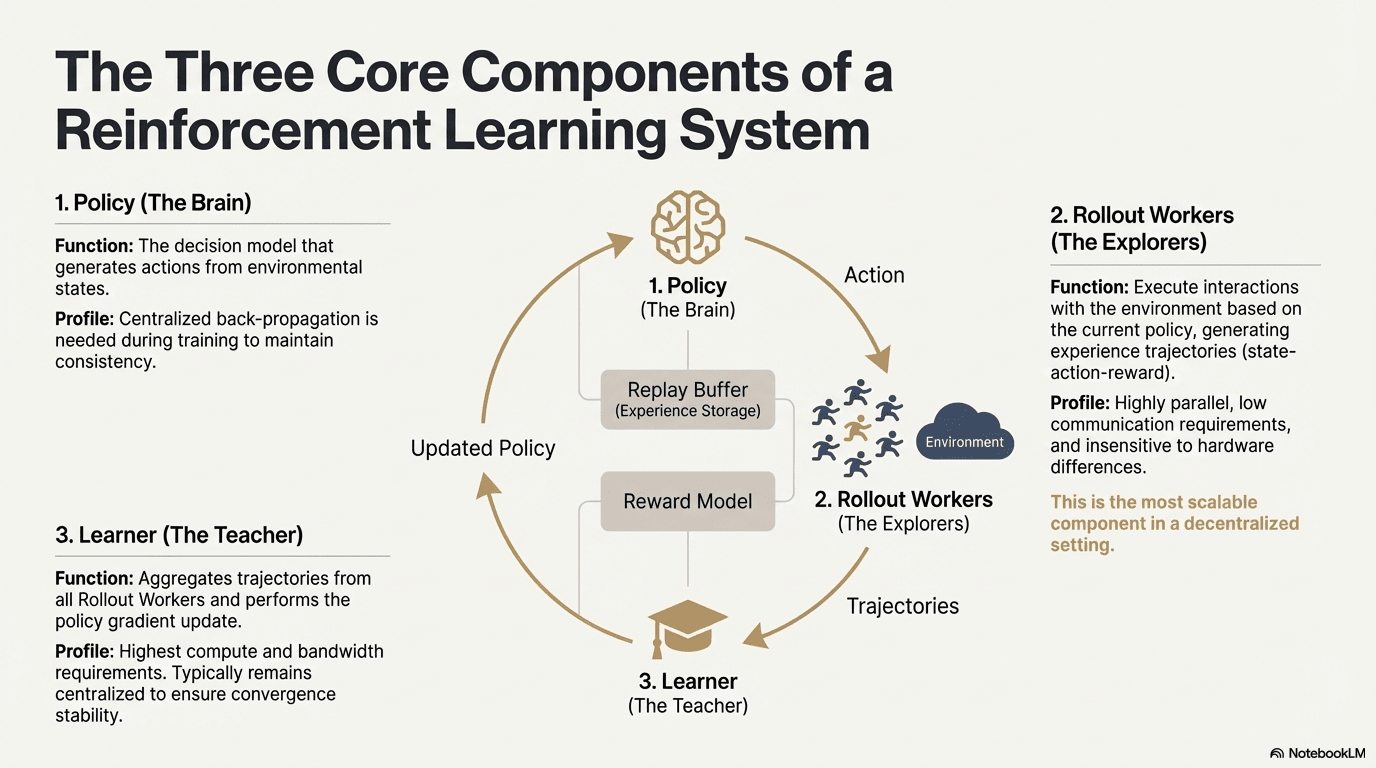
Sieć strategii (Policy): generuje akcje na podstawie stanu środowiska, jest rdzeniem decyzyjnym systemu. W czasie treningu wymaga centralnej propagacji wstecznej, aby utrzymać spójność; podczas wnioskowania może być rozdzielana do różnych węzłów, aby działać równolegle.
Próbkowanie doświadczeń (Rollout): węzły wykonują interakcje ze środowiskiem zgodnie z strategią, generując ścieżki stanu-akcji-nagrody. Proces ten jest wysoce równoległy, o bardzo niskiej komunikacji i jest mało wrażliwy na różnice sprzętowe, co czyni go najbardziej odpowiednim do rozszerzenia w zdecentralizowanej strukturze.
Uczący (Learner): agreguje wszystkie trajektorie Rollout i wykonuje aktualizację gradientu strategii, jest jedynym modułem, który wymaga najwyższej mocy obliczeniowej i przepustowości, dlatego zazwyczaj pozostaje w zcentralizowanym lub półzcentralizowanym wdrożeniu, aby zapewnić stabilność konwergencji.
2.2 Ramy etapu uczenia ze wzmocnieniem (RLHF → RLAIF → PRM → GRPO)
Uczenie ze wzmocnieniem można podzielić na pięć etapów, a cały proces jest opisany poniżej:
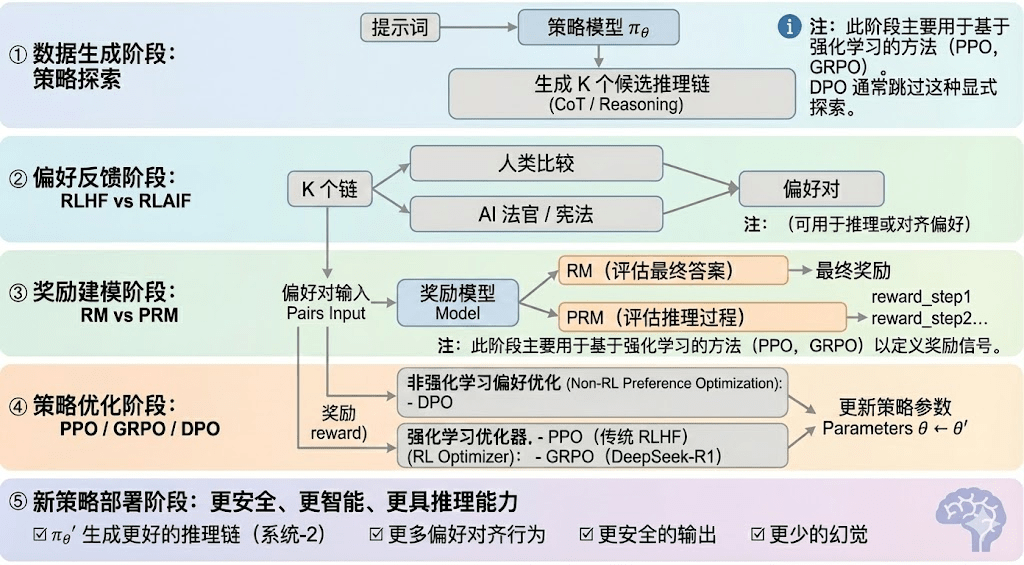
Faza generowania danych (Policy Exploration): w warunkach zadanych przez wskazówki wejściowe, model strategii πθ generuje wiele potencjalnych łańcuchów wnioskowania lub kompletnych trajektorii, które stanowią podstawę próbkowania preferencji i modelowania nagród. Określa to zakres eksploracji strategii.
Faza zwrotów preferencyjnych (RLHF / RLAIF):
RLHF (Reinforcement Learning from Human Feedback) poprzez wiele potencjalnych odpowiedzi, oznaczanie preferencji przez ludzi, szkolenie modelu nagród (RM) i optymalizację strategii za pomocą PPO, sprawia, że wyjścia modelu są bardziej zgodne z wartościami ludzkimi, co jest kluczowym krokiem w przejściu z GPT-3.5 do GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) wykorzystuje AI Judge lub reguły konstytucyjne do zastąpienia oznaczania przez ludzi, automatyzując pozyskiwanie preferencji, co znacznie obniża koszty i pozwala na skalowanie, stało się to głównym paradygmatem dostosowywania w takich firmach jak Anthropic, OpenAI, DeepSeek.
Faza modelowania nagród (Reward Modeling): preferencje wpływają na model nagród, ucząc model, jak mapować wyjście na nagrody. RM uczy model „co jest poprawną odpowiedzią”, PRM uczy model „jak przeprowadzić poprawne wnioskowanie”.
RM (Model Nagrody) służy do oceny jakości odpowiedzi, przyznając punkty wyłącznie dla wyjścia:
Model nagrody za proces PRM (Process Reward Model) nie ocenia tylko końcowej odpowiedzi, lecz punktuje każdy krok wnioskowania, każdy token i każdy segment logiczny, a także jest kluczową technologią OpenAI o1 i DeepSeek-R1, zasadniczo „uczy model, jak myśleć”.
Faza weryfikacji nagród (RLVR / Reward Verifiability): wprowadza „weryfikowalne ograniczenia” w procesie generowania i użytkowania sygnałów nagród, aby nagrody pochodziły z możliwych do powtórzenia reguł, faktów lub konsensusu, co zmniejsza ryzyko oszustw i odchyleń, a także poprawia audytowalność i skalowalność w otwartych środowiskach.
Faza optymalizacji strategii (Policy Optimization): aktualizuje parametry strategii θ na podstawie sygnałów dostarczonych przez model nagród, aby uzyskać silniejszą zdolność wnioskowania, większe bezpieczeństwo i bardziej stabilne wzorce zachowań strategii πθ′. Główne metody optymalizacji obejmują:
PPO (Proximal Policy Optimization): tradycyjny optymalizator RLHF, znany z stabilności, jednak w złożonych zadaniach wnioskowania często boryka się z wolnym konwergowaniem i niedostateczną stabilnością.
GRPO (Group Relative Policy Optimization): kluczowa innowacja DeepSeek-R1, modelująca rozkład przewagi w grupie potencjalnych odpowiedzi w celu oszacowania wartości oczekiwanej, a nie tylko prostego sortowania. Ta metoda zachowuje informacje o zakresie nagród, lepiej nadaje się do optymalizacji łańcucha wnioskowania, a proces szkolenia jest bardziej stabilny, co czyni ją ważnym ramieniem optymalizacji uczenia ze wzmocnieniem w scenariuszach głębokiego wnioskowania po PPO.
DPO (Direct Preference Optimization): metoda dostosowywania po, która nie wykorzystuje uczenia ze wzmocnieniem: nie generuje trajektorii, nie buduje modelu nagród, ale bezpośrednio optymalizuje na podstawie preferencji, co jest tańsze i stabilniejsze, przez co jest szeroko stosowane w otwartych modelach takich jak Llama, Gemma, ale nie zwiększa zdolności wnioskowania.
Faza wdrożenia nowej strategii (New Policy Deployment): po optymalizacji model wykazuje: większą zdolność generowania łańcuchów wnioskowania (System-2 Reasoning), bardziej zgodne z zachowaniami preferencjami ludzi lub AI, niższą częstotliwość iluzji oraz wyższe bezpieczeństwo. Model w ciągłej iteracji nieustannie uczy się preferencji, optymalizuje proces, poprawia jakość decyzji, tworząc cykl zamknięty.

2.3 Pięć głównych kategorii zastosowania uczenia ze wzmocnieniem w przemyśle
Uczenie ze wzmocnieniem (Reinforcement Learning) ewoluowało z wczesnej inteligencji opartej na grach w autonomiczny rdzeń decyzyjny w wielu branżach, a jego zastosowania można sklasyfikować w pięciu głównych kategoriach w zależności od stopnia dojrzałości technologicznej i poziomu realizacji przemysłowej, co prowadziło do kluczowych przełomów w każdym kierunku.
System gier i strategii (Game & Strategy): jest to jeden z pierwszych kierunków, w którym RL został zweryfikowany, w środowiskach „idealnych informacji + wyraźnych nagród” takich jak AlphaGo, AlphaZero, AlphaStar, OpenAI Five, RL wykazał zdolność do podejmowania decyzji porównywalnej, a nawet przewyższającej ekspertów ludzkich, co stało się podstawą nowoczesnych algorytmów RL.
Robotyka i inteligencja cielesna (Embodied AI): RL poprzez ciągłe sterowanie, modelowanie dynamiki i interakcje z otoczeniem, umożliwia robotom uczenie się kontroli, sterowania ruchem i realizacji zadań międzymodalnych (takich jak RT-2, RT-X), szybko przechodząc do przemysłowego zastosowania jako kluczowa technologia w rzeczywistym świecie dla robotyki.
Cyfrowe wnioskowanie (Digital Reasoning / LLM System-2): RL + PRM prowadzi duże modele od „imitacji językowej” do „strukturalnego wnioskowania”, a rezultaty obejmują DeepSeek-R1, OpenAI o1/o3, Anthropic Claude i AlphaGeometry, a ich istotą jest optymalizacja nagród na poziomie łańcucha wnioskowania, a nie tylko ocena końcowych odpowiedzi.
Zautomatyzowane odkrywanie naukowe i optymalizacja matematyczna (Scientific Discovery): RL znajduje optymalne struktury lub strategie w warunkach bez oznaczeń, złożonych nagród i ogromnej przestrzeni wyszukiwania i już zrealizował takie przełomy jak AlphaTensor, AlphaDev, Fusion RL, demonstrując zdolność eksploracyjną przekraczającą ludzką intuicję.
Systemy podejmowania decyzji ekonomicznych i handlowych (Economic Decision-making & Trading): RL jest wykorzystywane do optymalizacji strategii, kontroli ryzyka o wysokiej wymiarowości i generowania adaptacyjnych systemów handlowych, w porównaniu do tradycyjnych modeli ilościowych, lepiej radzi sobie w niepewnych warunkach, co czyni je ważnym elementem inteligentnych finansów.
Trzy. Naturalne dopasowanie uczenia ze wzmocnieniem i Web3
Wysoka zgodność uczenia się ze wzmocnieniem (RL) z Web3 wynika z faktu, że obie są w istocie „systemami napędzanymi przez zachęty”. RL polega na optymalizacji strategii w oparciu o sygnały nagród, blockchain koordynuje zachowania uczestników za pomocą ekonomicznych zachęt, co naturalnie harmonizuje obie na poziomie mechanizmów. Kluczowe wymagania RL - masowe, heterogeniczne rollouty, podział nagród i weryfikacja autentyczności - to strukturalne zalety Web3.
Rozdzielenie wnioskowania i treningu: proces treningowy uczenia ze wzmocnieniem można wyraźnie podzielić na dwa etapy:
Rollout (próbkowanie eksploracyjne): model generuje dużą ilość danych na podstawie bieżącej strategii, zadania są obliczeniowo intensywne, ale komunikacja jest rzadka. Nie wymaga częstej komunikacji między węzłami, co czyni je odpowiednim do równoległego generowania na globalnych, konsumpcyjnych GPU.
Aktualizacja (aktualizacja parametrów): aktualizuje wagi modelu na podstawie zebranych danych, wymaga wysokiej przepustowości zcentralizowanego węzła.
„Rozdzielenie wnioskowania i treningu” naturalnie wpisuje się w zdecentralizowaną strukturę heterogeniczną mocy obliczeniowej: Rollout może być zlecany otwartej sieci, a poprzez mechanizm tokenów rozliczany na podstawie wkładu, podczas gdy aktualizacje modeli pozostają scentralizowane, aby zapewnić stabilność.
Weryfikowalność (Verifiability): ZK i Proof-of-Learning dostarczają środków do weryfikacji, czy węzeł rzeczywiście wykonał wnioskowanie, rozwiązując problem uczciwości w otwartych sieciach. W zadaniach deterministycznych, takich jak kody, rozumowanie matematyczne, weryfikatorzy muszą jedynie sprawdzić odpowiedzi, aby potwierdzić nakład pracy, co znacznie zwiększa wiarygodność zdecentralizowanych systemów RL.
Warstwa zachęt, oparta na mechanizmie produkcji zwrotów tokenowych: mechanizm tokenów Web3 może bezpośrednio nagradzać uczestników wkładu w preferencje RLHF/RLAIF, co sprawia, że generowanie danych preferencyjnych ma przejrzystą, rozliczalną i nie wymagającą zezwolenia strukturę zachęt; stawki i redukcja (Staking/Slashing) dodatkowo ograniczają jakość zwrotów, tworząc bardziej efektywny i zharmonizowany rynek zwrotów niż tradycyjne tłumaczenie.
Potencjał wieloagentowego uczenia ze wzmocnieniem (MARL): blockchain w istocie stanowi publiczne, przejrzyste i nieprzerwanie ewoluujące środowisko wieloagentowe, w którym konta, umowy i agenci nieustannie dostosowują strategie w odpowiedzi na zachęty, co czyni go naturalnie wbudowanym w możliwość budowania dużych eksperymentów MARL. Chociaż wciąż w początkowej fazie, jego cechy jawności stanu, weryfikowalności wykonania i programowalnych zachęt stanowią zasadnicze przewagi dla przyszłego rozwoju MARL.
Cztery. Analiza klasycznych projektów Web3 + uczenie ze wzmocnieniem
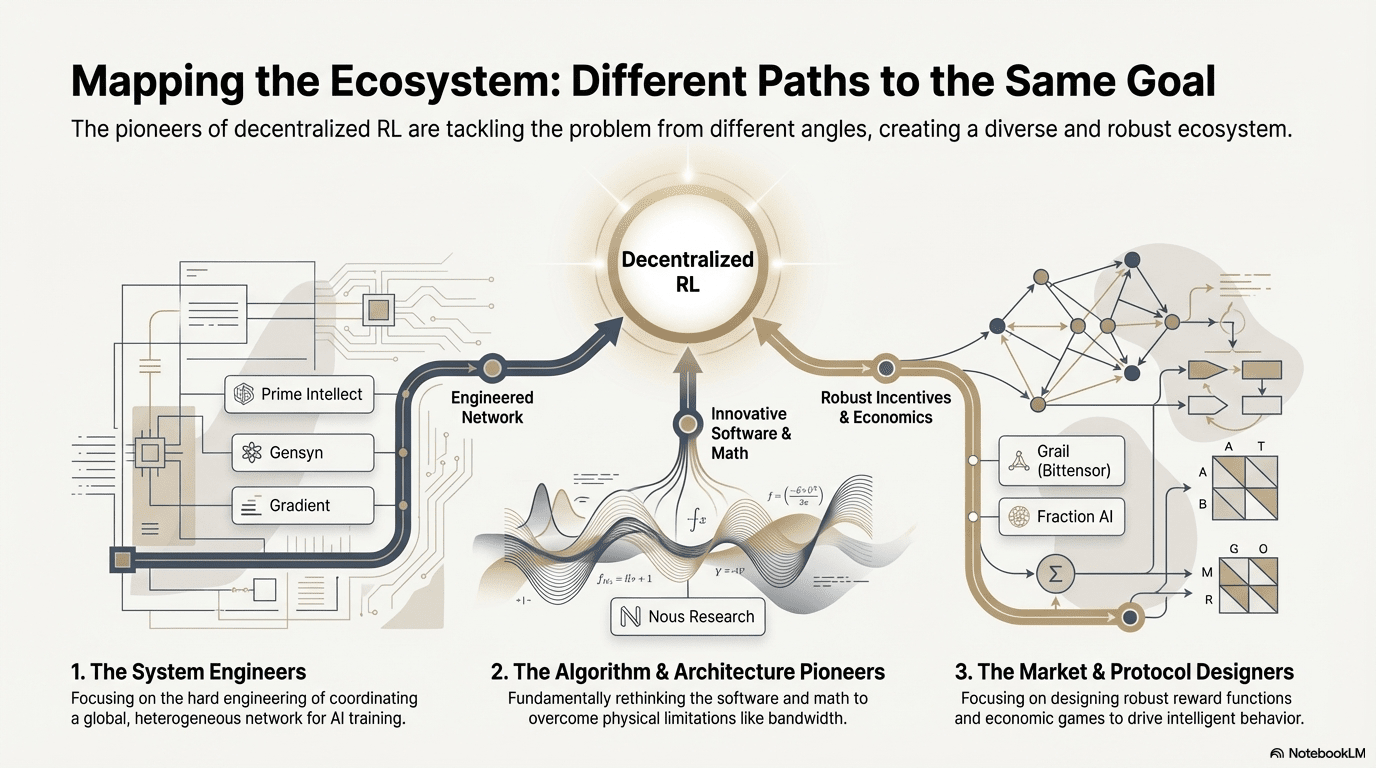
Na podstawie powyższej ramy teoretycznej dokonamy krótkiej analizy najbardziej reprezentatywnych projektów w obecnym ekosystemie:
Prime Intellect: asynchroniczny paradygmat uczenia ze wzmocnieniem prime-rl
Prime Intellect dąży do stworzenia globalnego otwartego rynku mocy obliczeniowej, obniżając progi szkoleniowe, promując współpracujące zdecentralizowane szkolenie oraz rozwijając pełen stos technologiczny superinteligencji open-source. Jego system obejmuje: Prime Compute (jednolite środowisko chmurowe/rozproszone), rodzinę modeli INTELLECT (10B-100B+), centrum otwartego środowiska uczenia ze wzmocnieniem (Environments Hub) oraz silnik danych syntetycznych na dużą skalę (SYNTHETIC-1/2).
Kluczowe komponenty infrastruktury Prime Intellect, ramy prime-rl są zaprojektowane specjalnie dla asynchronicznych rozproszonych środowisk ściśle związanych z uczeniem ze wzmocnieniem, a pozostałe to protokół komunikacyjny OpenDiLoCo, który przełamuje wąskie gardła przepustowości, oraz mechanizmy weryfikacyjne TopLoc, które zapewniają integralność obliczeń.
Przegląd kluczowych komponentów infrastruktury Prime Intellect

Kamień węgielny technologii: ramy asynchronicznego uczenia ze wzmocnieniem prime-rl
prime-rl jest głównym silnikiem szkoleniowym Prime Intellect, zaprojektowanym specjalnie dla dużych, asynchronicznych, zdecentralizowanych środowisk, osiągającym wysoką przepustowość wnioskowania i stabilne aktualizacje dzięki pełnemu rozdzieleniu Aktora i Uczącego. Wykonawcy (Rollout Worker) i Uczący (Trainer) nie są już synchronizowani, węzły mogą dowolnie dołączać lub opuszczać, wystarczy, że nieustannie pobierają najnowszą strategię i przesyłają wygenerowane dane.
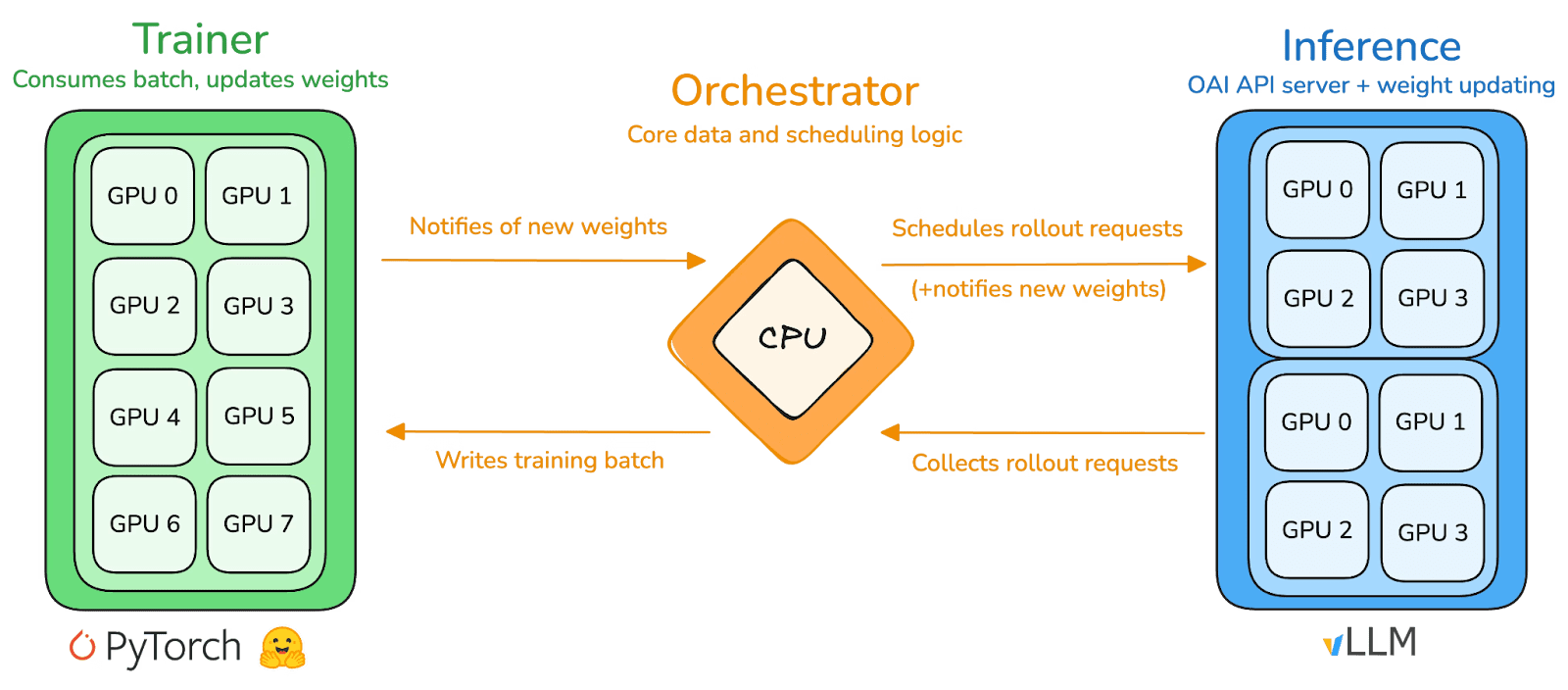
Wykonawcy Aktorzy (Rollout Workers): odpowiedzialni za wnioskowanie modeli i generowanie danych. Prime Intellect innowacyjnie integruje silnik wnioskowania vLLM na końcu aktora. Technologia PagedAttention vLLM i zdolności ciągłego przetwarzania (Continuous Batching) pozwalają Aktorowi generować trajektorie wnioskowania z ekstremalnie wysoką przepustowością.
Uczący Learner (Trener): odpowiedzialny za optymalizację strategii. Learner asynchronicznie pobiera dane z współdzielonego bufora doświadczeń (Experience Buffer) do aktualizacji gradientów, nie czekając na zakończenie wszystkich Aktorów dla bieżącej partii.
Koordynator (Orchestrator): odpowiedzialny za harmonogramowanie przepływu wag modelu i danych.
Kluczowe innowacje prime-rl:
Całkowita asynchroniczność (True Asynchrony): prime-rl porzuca tradycyjną synchronizację PPO, nie czekając na wolne węzły, bez konieczności wyrównywania partii, co pozwala na dowolną liczbę i wydajność GPU na stałe dołączać, co stanowi podstawę wykonalności zdecentralizowanego RL.
Głębokie zintegrowanie FSDP2 i MoE: poprzez podział parametrów FSDP2 i aktywację MoE w sposób oszczędny, prime-rl pozwala na skuteczne szkolenie modeli o setkach miliardów parametrów w rozproszonym środowisku, przy czym Aktor uruchamia tylko aktywnych ekspertów, znacznie obniżając pamięć i koszty wnioskowania.
GRPO+ (Group Relative Policy Optimization): GRPO eliminuje sieć Krytyka, znacznie redukując obciążenia obliczeniowe i pamięciowe, naturalnie dostosowując się do środowisk asynchronicznych, a GRPO+ prime-rl dodatkowo zapewnia stabilizację w warunkach wysokich opóźnień, co zapewnia niezawodną konwergencję.
Rodzina modeli INTELLECT: znak dojrzałości technologii RL w zdecentralizowanej sieci
INTELLECT-1 (10B, październik 2024) po raz pierwszy dowodzi, że OpenDiLoCo może efektywnie trenować w zróżnicowanej sieci obejmującej trzy kontynenty (komunikacja wynosi <2%, wykorzystanie mocy obliczeniowej 98%), przełamując fizyczne ograniczenia w treningu międzyregionowym.
INTELLECT-2 (32B, kwiecień 2025) jako pierwszy model RL bez zezwolenia, weryfikuje stabilność konwergencji prime-rl i GRPO+ w warunkach opóźnień wieloetapowych i asynchronicznych, umożliwiając zdecentralizowane RL z globalnym otwartym dostępem do mocy obliczeniowej.
INTELLECT-3 (106B MoE, listopad 2025) wykorzystuje rzadką architekturę, aktywując jedynie 12B parametrów, trenując na 512×H200 i osiągając flagową wydajność wnioskowania (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9% itd.), a ogólne osiągi zbliżają się lub nawet przewyższają znacznie większe scentralizowane modele zamknięte.
Prime Intellect zbudował również kilka wspierających infrastruktury: OpenDiLoCo poprzez komunikację o niskiej gęstości czasowej i różnice wag kwantyzacji zmniejsza ilość komunikacji w szkoleniu między regionami setki razy, co pozwala INTELLECT-1 utrzymać 98% wykorzystania w sieci rozciągającej się na trzy kontynenty; TopLoc + Weryfikatory tworzą zdecentralizowaną wiarygodną warstwę wykonawczą, aktywując weryfikację odcisków palców i piaskownic, aby zapewnić autentyczność danych wnioskowania i nagród; silnik danych SYNTHETIC produkuje duże ilości wysokiej jakości łańcuchów wnioskowania, a dzięki równoległemu przetwarzaniu pozwala modelowi 671B działać efektywnie na klastrach GPU konsumpcyjnych. Te komponenty stanowią kluczową infrastrukturę inżynieryjną dla generowania, weryfikacji i przetwarzania danych w zdecentralizowanym RL. Seria INTELLECT dowiodła, że ten stos technologiczny może produkować dojrzałe modele światowej klasy, co oznacza, że system szkolenia zdecentralizowanego przeszedł z etapu koncepcyjnego do etapu praktycznego.
Gensyn: rdzeń RL Swarm i SAPO
Celem Gensyn jest połączenie globalnie niewykorzystanej mocy obliczeniowej w otwartą, bez zaufania, nieskończoną infrastrukturę szkoleniową AI. Jej kluczowe elementy obejmują warstwę wykonawczą standardyzacji między urządzeniami, sieć koordynacji peer-to-peer oraz system weryfikacji zadań bez zaufania, a także automatyczne przydzielanie zadań i nagród za pomocą inteligentnych kontraktów. W związku z cechami uczenia ze wzmocnieniem, Gensyn wprowadza mechanizmy rdzenne takie jak RL Swarm, SAPO i SkipPipe, które odseparowują generowanie, ocenę i aktualizację, wykorzystując „swoje” globalne heterogeniczne GPU w celu osiągnięcia zbiorowej ewolucji. Ostatecznym rezultatem nie jest tylko moc obliczeniowa, lecz weryfikowalna inteligencja (Verifiable Intelligence).
Zastosowanie uczenia ze wzmocnieniem w stosie Gensyn

RL Swarm: zdecentralizowany silnik współpracy w uczeniu ze wzmocnieniem
RL Swarm pokazuje nowy model współpracy. Nie jest to tylko proste rozdzielanie zadań, lecz zdecentralizowany cykl „generowanie - ocenianie - aktualizowanie”, który imituje proces uczenia się społeczeństwa ludzkiego, nieskończona pętla:
Rozwiązywacze (wykonawcy): odpowiedzialni za lokalne wnioskowanie modeli i generowanie Rolloutów, różnorodność węzłów nie stanowi problemu. Gensyn integruje lokalnie silnik wnioskowania o wysokiej przepustowości (np. CodeZero), co pozwala na generowanie pełnych trajektorii, a nie tylko odpowiedzi.
Proponenci (twórcy zadań): dynamicznie generują zadania (problemy matematyczne, problemy kodowe itp.), wspierając różnorodność zadań oraz dostosowywanie trudności w stylu Curriculum Learning.
Oceniacze (ewaluatorzy): korzystają z zamrożonego „modelu sędziego” lub reguł do oceniania lokalnych Rolloutów, generując lokalne sygnały nagród. Proces oceny może być audytowany, co zmniejsza możliwości oszustwa.
Trzy elementy tworzą strukturę organizacyjną RL P2P, która może osiągnąć masowe współprace w uczeniu się bez centralizacji.
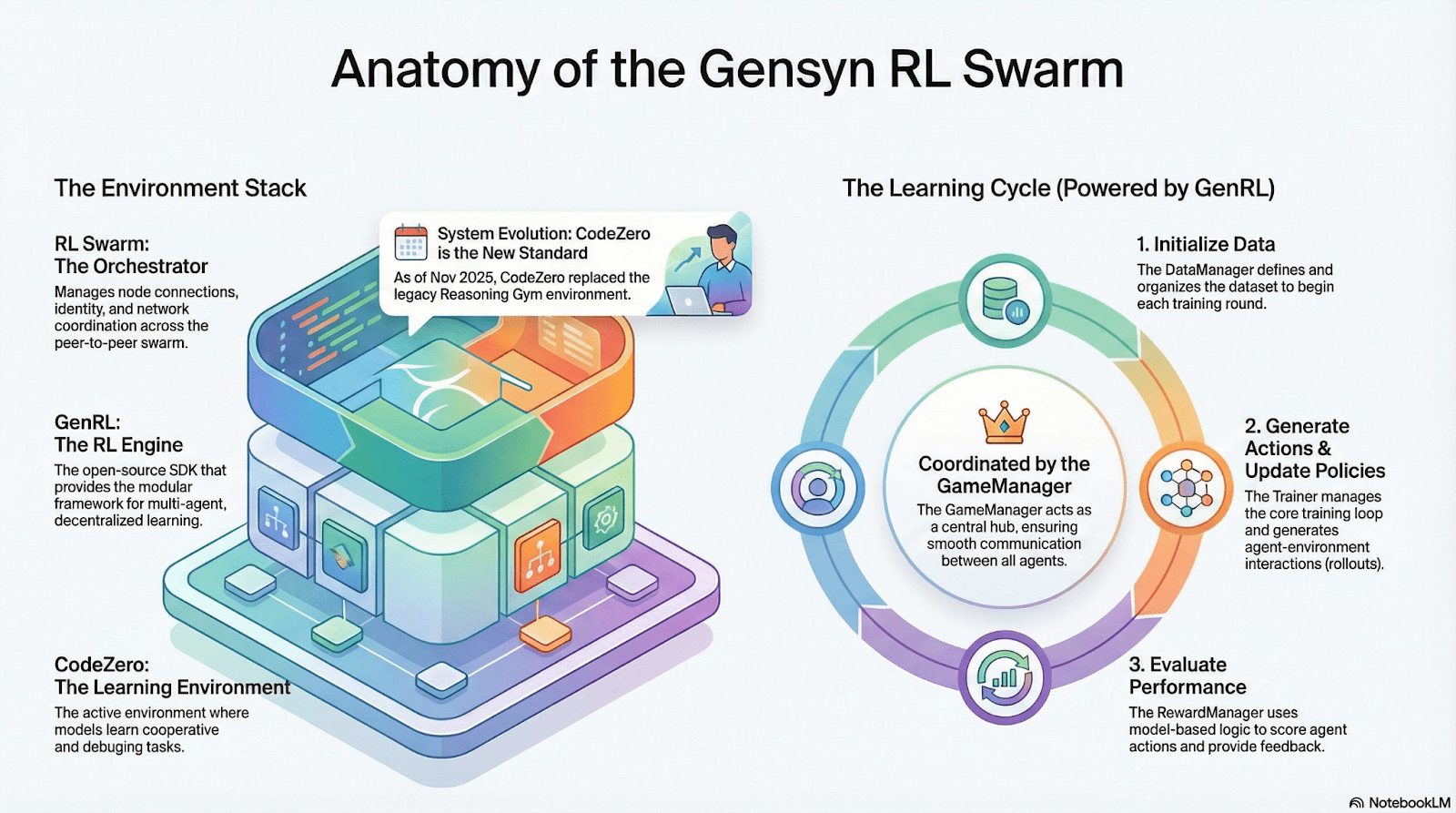
SAPO: algorytm optymalizacji strategii zaprojektowany dla zdecentralizowanej struktury: SAPO (Swarm Sampling Policy Optimization) koncentruje się na „dzieleniu się Rolloutem i filtrowaniu próbek sygnałów bez gradientu, a nie dzieleniu się gradientami”, poprzez masowe zdecentralizowane pobieranie Rolloutów oraz traktowanie odebranych Rolloutów jako lokalnie wygenerowanych, aby utrzymać stabilną konwergencję w środowisku bez centralnej koordynacji z wyraźnymi opóźnieniami węzłów. W porównaniu z PPO, które polega na sieci Krytyka i ma wysokie koszty obliczeniowe, lub GRPO opartym na estymacji przewagi wewnątrz grupy, SAPO przy niskiej przepustowości pozwala nawet konsumpcyjnym GPU efektywnie uczestniczyć w masowej optymalizacji uczenia ze wzmocnieniem.
Dzięki RL Swarm i SAPO, Gensyn udowodnił, że uczenie ze wzmocnieniem (zwłaszcza w etapie szkolenia po) naturalnie pasuje do zdecentralizowanej architektury - ponieważ bardziej polega na masowych, zróżnicowanych eksploracjach (Rollout), a nie synchronizacji parametrów o wysokiej częstotliwości. Połączenie PoL i systemu weryfikacji Verde, Gensyn dostarcza alternatywną ścieżkę do szkolenia modeli o bilionowych parametrach, która nie zależy od jednego technologicznego giganta: sieć superinteligencji, samowystarczająca, składająca się z milionów heterogenicznych GPU na całym świecie.
Nous Research: weryfikowalne środowisko uczenia ze wzmocnieniem Atropos
Nous Research buduje zestaw zdecentralizowanej, samowystarczalnej infrastruktury poznawczej. Jej kluczowe komponenty - Hermes, Atropos, DisTrO, Psyche i World Sim - są zorganizowane w ciągły, zamknięty system inteligentnej ewolucji. W odróżnieniu od tradycyjnego liniowego procesu „wstępnego szkolenia - szkolenia po - wnioskowania”, Nous wykorzystuje techniki uczenia ze wzmocnieniem takie jak DPO, GRPO, odrzucanie próbek, aby zjednoczyć generowanie danych, weryfikację, uczenie się i wnioskowanie w ciągłą pętlę sprzężenia zwrotnego, tworząc zamknięty ekosystem AI o ciągłej samodoskonaleniu.
Przegląd komponentów Nous Research

Warstwa modelu: ewolucja Hermesa i zdolności wnioskowania
Seria Hermes jest głównym interfejsem modelu Nous Research dla użytkowników, a jej ewolucja jasno pokazuje ścieżkę branży od tradycyjnego dostosowywania SFT/DPO do wnioskowania w uczeniu ze wzmocnieniem (Reasoning RL):
Hermes 1–3: dostosowanie instrukcji i wczesne zdolności agentów: Hermes 1–3 wykorzystując niskokosztowe DPO osiągnął solidne dostosowanie instrukcji, a w Hermes 3 z pomocą syntetycznych danych oraz wprowadzonej po raz pierwszy mechanizmu weryfikacji Atropos.
Hermes 4 / DeepHermes: zapisuje łańcuch myślowy w wagach, aby podnieść wydajność matematyczną i kodową poprzez Test-Time Scaling, opierając się na „odrzucaniu próbek + weryfikacji Atropos”, tworząc dane wnioskowe o wysokiej czystości.
DeepHermes dodatkowo przyjmuje GRPO zamiast PPO, które było trudne do wprowadzenia w rozproszonej formie, umożliwiając uruchomienie RL wnioskowania w zdecentralizowanej sieci GPU Psyche, co stanowi fundament inżynieryjny dla skalowalności otwartego wnioskowania RL.
Atropos: Weryfikowalne nagrody napędzające środowisko uczenia się ze wzmocnieniem
Atropos jest prawdziwym węzłem łączącym w systemie RL Nous. Opakowuje wskazówki, wywołania narzędzi, wykonanie kodu i interakcje wieloetapowe w ustandaryzowane środowisko RL, które może bezpośrednio weryfikować, czy wyjście jest poprawne, dostarczając tym samym deterministyczne sygnały nagród, które zastępują kosztowne i nieprzeskalowalne oznaczanie przez ludzi. Co ważniejsze, w zdecentralizowanej sieci szkoleniowej Psyche, Atropos pełni rolę „sędziego”, służąc do weryfikacji, czy węzły rzeczywiście podnoszą strategię, wspierając audytowalny Proof-of-Learning, co zasadniczo rozwiązuje problem wiarygodności nagród w rozproszonym RL.
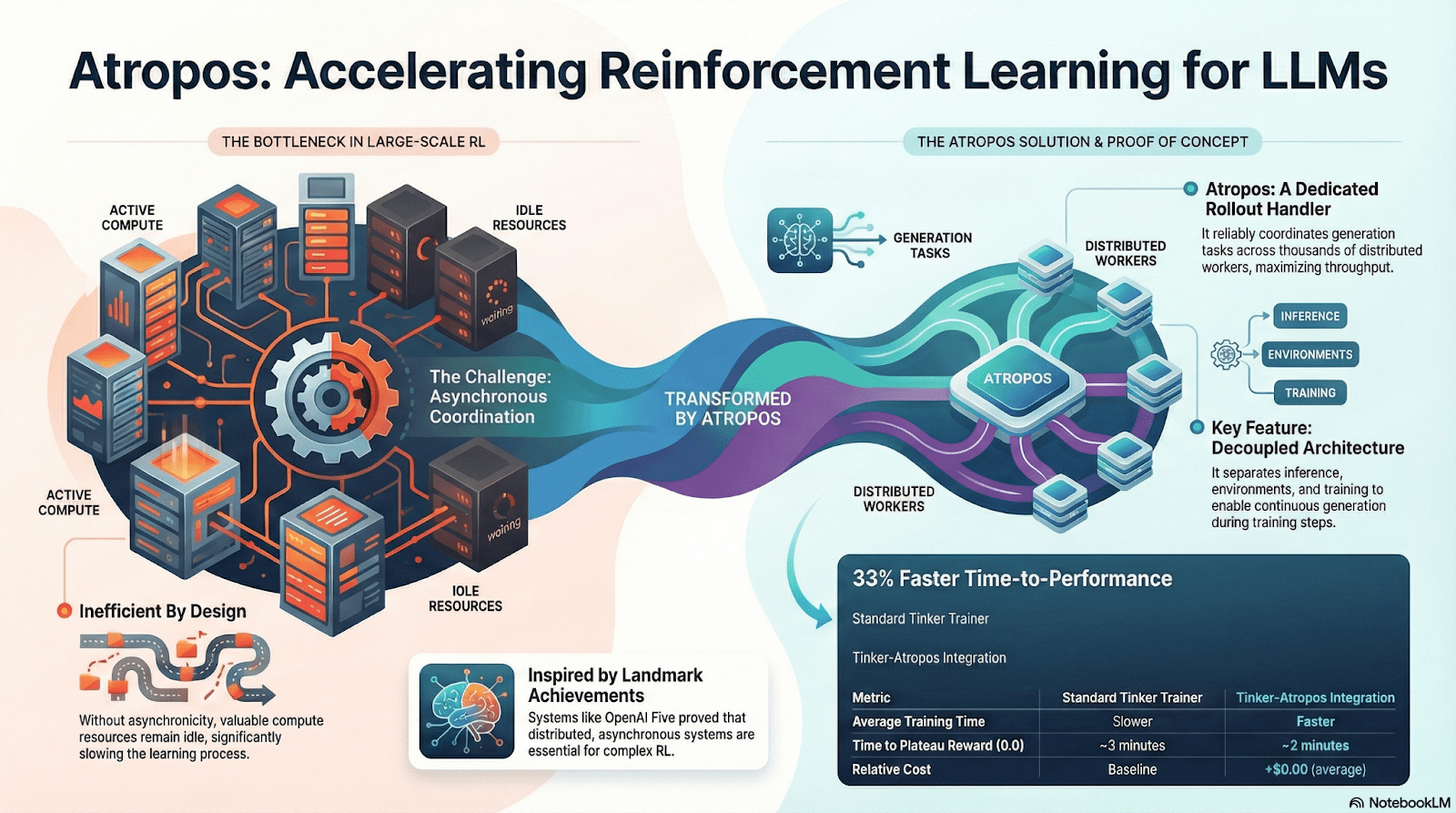
DisTrO i Psyche: warstwa optymalizatorów dla zdecentralizowanego uczenia ze wzmocnieniem
Tradycyjne treningi RLF (RLHF/RLAIF) polegają na scentralizowanych klastrach o wysokiej przepustowości, co stanowi kluczową barierę, której nie można skopiować w otwartych źródłach. DisTrO redukuje koszty komunikacji RL o kilka rzędów wielkości poprzez rozdzielanie momentów i kompresję gradientów, co pozwala na szkolenie w warunkach internetu; Psyche wdraża ten mechanizm treningowy w sieci łańcuchowej, umożliwiając węzłom lokalne wnioskowanie, weryfikację, ocenę nagród i aktualizację wag, tworząc pełne zamknięcie RL.
W systemie Nous, Atropos weryfikuje łańcuchy myślowe; DisTrO kompresuje komunikację szkoleniową; Psyche uruchamia cykl RL; World Sim zapewnia złożone środowisko; Forge zbiera rzeczywiste wnioskowanie; Hermes zapisuje wszystkie nauki jako wagi. Uczenie ze wzmocnieniem to nie tylko etap szkolenia, lecz kluczowy protokół łączący dane, środowisko, modele i infrastrukturę w architekturze Nous, sprawiając, że Hermes staje się systemem żywym, który może się nieustannie doskonalić w otwartej sieci obliczeniowej.
Sieć gradientowa: struktura uczenia ze wzmocnieniem Echo
Główna wizja Gradient Network polega na przekształceniu paradygmatu obliczeniowego AI poprzez „otwarty stos inteligencji” (Open Intelligence Stack). Stos technologiczny Gradient składa się z grupy kluczowych protokołów, które mogą ewoluować niezależnie, a jednocześnie współpracować. Jego struktura obejmuje od dołu komunikację, aż po inteligentną współpracę, w tym: Parallax (rozproszone wnioskowanie), Echo (zdecentralizowane szkolenie RL), Lattica (sieć P2P), SEDM / Massgen / Symphony / CUAHarm (pamięć, współpraca, bezpieczeństwo), VeriLLM (wiarygodna weryfikacja), Mirage (wysokiej wierności symulacja), co razem tworzy ciągłą ewolucję zdecentralizowanej infrastruktury inteligencji.

Echo - architektura szkoleniowa uczenia ze wzmocnieniem
Echo to framework uczenia ze wzmocnieniem Gradient, którego kluczowa koncepcja projektowa polega na rozdzieleniu ścieżek treningowych, wnioskowania i danych (nagrody) w uczeniu ze wzmocnieniem, co umożliwia niezależną ekspansję i koordynację generowania Rolloutów, optymalizacji strategii i oceny nagród w heterogenicznym środowisku. Współdziała w heterogenicznej sieci składającej się z węzłów wnioskowania i treningu, aby utrzymać stabilność treningu w szerokim heterogenicznym środowisku, skutecznie łagodząc problemy tradycyjnego RLHF / VERL związane z mieszaniem wnioskowania i treningu, które prowadzi do awarii SPMD oraz ograniczeń wykorzystania GPU.
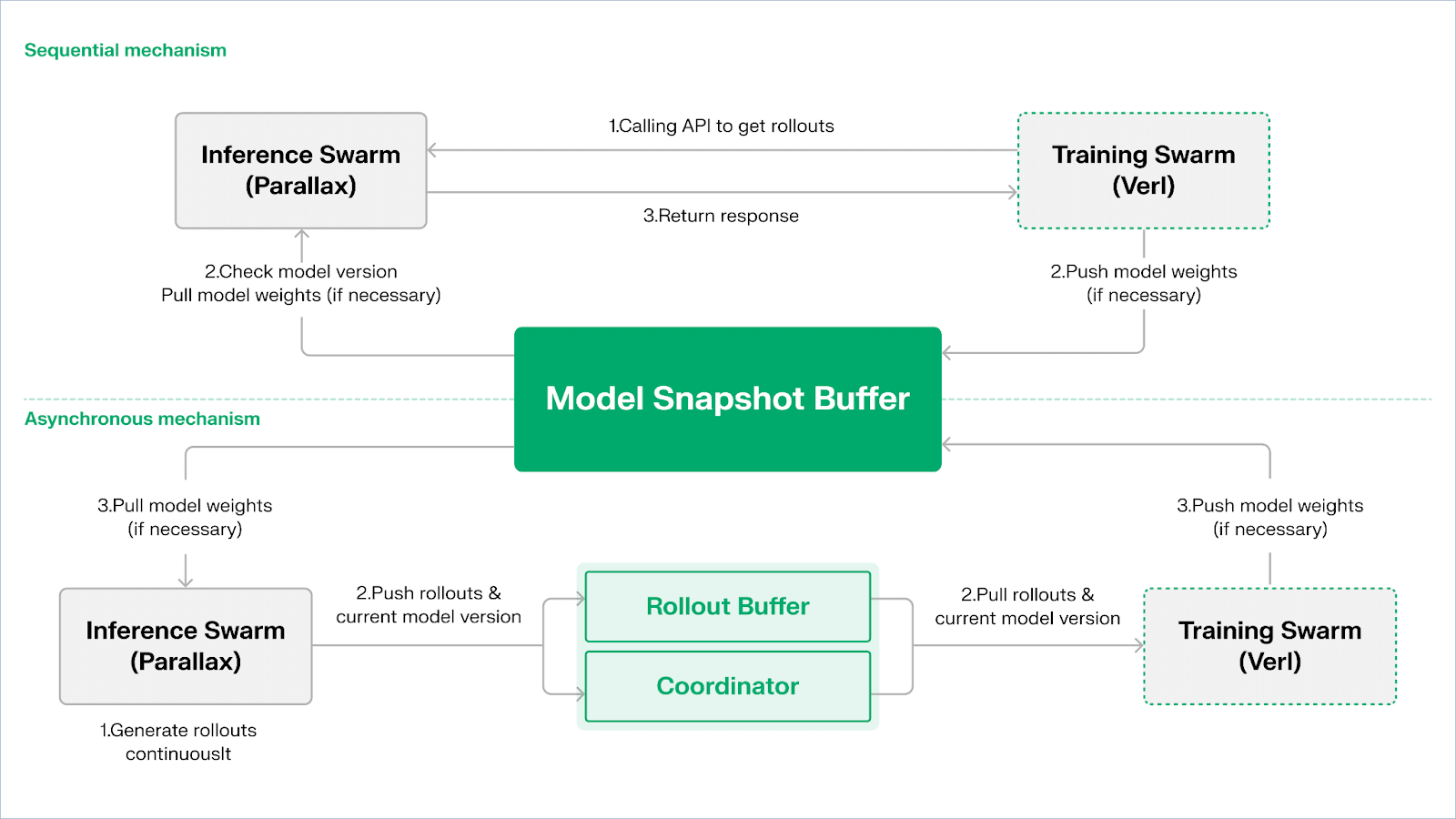
Echo wykorzystuje „dwugruppową architekturę wnioskowania - treningu” w celu maksymalizacji wykorzystania mocy obliczeniowej, obie grupy działają niezależnie, nie blokując się nawzajem:
Maksymalizacja przepustowości próbkowania: grupa wnioskowania Inference Swarm składa się z konsumpcyjnych GPU oraz urządzeń brzegowych, budując wysokoprzepustowy sampler za pomocą Parallax w trybie pipeline-parallel, koncentrując się na generowaniu trajektorii;
Maksymalizacja mocy obliczeniowej gradientu: grupa treningowa Training Swarm składa się z konsumpcyjnych sieci GPU, które mogą działać w zcentralizowanych klastrach lub w wielu miejscach na całym świecie, odpowiedzialna jest za aktualizacje gradientów, synchronizację parametrów i dostosowywanie LoRA, koncentrując się na procesie uczenia.
Aby utrzymać spójność strategii i danych, Echo oferuje dwie klasy lekkich protokołów synchronizacji: sekwencyjny (Sequential) i asynchroniczny (Asynchronous), co zapewnia dwukierunkowe zarządzanie spójnością wag i trajektorii:
Selektywne pobieranie (Pull) tryb | Priorytet dokładności: strona treningowa wymusza na węzłach aktualizację wersji modelu przed pobraniem nowych trajektorii, aby zapewnić świeżość trajektorii, co jest odpowiednie dla zadań, które są bardzo wrażliwe na przestarzałe strategie;
Asynchroniczne pobieranie i wysyłanie (Push-Pull) tryb | Priorytet efektywności: strona wnioskowania nieustannie generuje trajektorie z etykietami wersji, strona treningowa konsumuje według własnego rytmu, koordynator monitoruje odchylenia wersji i wyzwala aktualizację wag, maksymalizując wykorzystanie urządzeń.
Na poziomie podstawowym, Echo opiera się na Parallax (heterogeniczne wnioskowanie w warunkach niskiej przepustowości) oraz lekkich komponentach do rozproszonego treningu (takich jak VERL), polegając na LoRA w celu obniżenia kosztów synchronizacji między węzłami, co pozwala na stabilne działanie uczenia ze wzmocnieniem w globalnej, heterogenicznej sieci.
Grail: uczenie ze wzmocnieniem w ekosystemie Bittensor
Bittensor buduje ogromną, rzadką i niestabilną sieć funkcji nagród za pomocą unikalnego mechanizmu konsensusu Yuma.
Ekosystem Bittensor zawiera Covenant AI, który zbudował pionowo zintegrowaną linię produkcyjną od wstępnego szkolenia do RL po szkoleniu poprzez SN3 Templar, SN39 Basilica i SN81 Grail. W szczególności SN3 Templar jest odpowiedzialny za wstępne szkolenie podstawowego modelu, SN39 Basilica zapewnia rynek rozproszonej mocy obliczeniowej, a SN81 Grail działa jako „weryfikowalna warstwa wnioskowania” w kierunku RL po szkoleniu, realizując kluczowe procesy RLHF/RLAIF od modelu podstawowego do optymalizacji strategii.

Celem GRAIL jest udowodnienie za pomocą kryptografii autentyczności każdej rollout uczenia ze wzmocnieniem oraz powiązanie tożsamości modelu, zapewniając, że RLHF może być bezpiecznie realizowane w środowisku, w którym nie ma zaufania. Protokół ten buduje wiarygodny łańcuch poprzez trzy poziomy mechanizmów:
Generowanie wyzwań deterministycznych: wykorzystując losowy sygnał drand i hasz bloku, tworzy nieprzewidywalne, ale powtarzalne zadania wyzwania (jak SAT, GSM8K), eliminując oszustwa polegające na wstępnym obliczaniu;
Dzięki próbkowaniu indeksów PRF i zobowiązaniom szkiców, weryfikatorzy mogą za niską cenę sprawdzić token-level logprob i łańcuch wnioskowania, potwierdzając, że rollout został wygenerowany przez zadeklarowany model.
Identyfikacja modelu: wiąże proces wnioskowania z podpisem strukturalnym odcisku palca wag modelu oraz rozkładem tokenów, zapewniając, że zastąpienie modelu lub powtórzenie wyników będą natychmiast rozpoznawane. W ten sposób dostarcza podstawy autentyczności dla trajektorii wnioskowania (rollout) w RL.
Na tym mechanizmie podsieć Grail zrealizowała proces weryfikacji po szkoleniu w stylu GRPO: górnicy generują wiele ścieżek wnioskowania dla tego samego pytania, weryfikatorzy oceniają na podstawie poprawności, jakości łańcucha wnioskowania i zgodności SAT, a znormalizowane wyniki zapisują na blockchainie jako wagi TAO. Publiczne eksperymenty wykazały, że ten framework zwiększył dokładność MATH Qwen2.5-1.5B z 12.7% do 47.6%, dowodząc, że może zapobiegać oszustwom i znacznie wzmacniać zdolności modelu. W stosie szkoleniowym Covenant AI, Grail jest fundamentem zaufania i wykonania w zdecentralizowanym RLVR/RLAIF, obecnie jeszcze nie uruchomionym na głównym blockchainie.
Fraction AI: oparte na konkurencji uczenie ze wzmocnieniem RLFC
Architektura Fraction AI wyraźnie koncentruje się na konkurencyjnym uczeniu ze wzmocnieniem (Reinforcement Learning from Competition, RLFC) i grywalizacji etykietowania danych, zastępując statyczne nagrody tradycyjnego RLHF i oznaczanie przez ludzi otwartym, dynamicznym środowiskiem konkurencyjnym. Agenci rywalizują w różnych Spaces, a ich względna ranga oraz oceny AI sędziów wspólnie tworzą nagrody w czasie rzeczywistym, przekształcając proces dostosowywania w ciągły system rywalizacji wieloagentowej.
Kluczowe różnice między tradycyjnym RLHF a RLFC Fraction AI:

Kluczowa wartość RLFC polega na tym, że nagrody pochodzą nie z jednego modelu, lecz z ciągle ewoluujących przeciwników i oceniających, co zapobiega wykorzystywaniu modelu nagród i przez różnorodność strategii zapobiega lokalnej optymalizacji ekosystemu. Struktura Spaces determinuje naturę gry (zero-sum lub positive-sum), promując złożone zachowania w rywalizacji i współpracy.
W architekturze systemu Fraction AI proces treningowy jest podzielony na cztery kluczowe komponenty:
Agenci: lekkie jednostki strategii oparte na otwartych LLM, rozszerzane przez QLoRA z różnicowymi wagami, niskokosztowe aktualizacje;
Przestrzenie: izolowane środowiska domen zadań, agenci płacą za dostęp i zdobywają nagrody w zależności od wyników;
Sędziowie AI: warstwa nagród w czasie rzeczywistym oparta na RLAIF, zapewniająca skalowalną, zdecentralizowaną ocenę;
Proof-of-Learning: wiąże aktualizację strategii z konkretnymi wynikami rywalizacji, zapewniając, że proces szkolenia jest weryfikowalny i odporny na oszustwa.
Istota Fraction AI polega na budowie ewolucyjnego silnika współpracy człowieka i maszyny”. Użytkownicy jako „meta-optymalizatorzy” na poziomie strategii kierują kierunkiem eksploracji za pomocą inżynierii podpowiedzi (Prompt Engineering) i konfiguracji hiperparametrów; podczas gdy agenci w mikro rywalizacji automatycznie generują ogromne ilości danych preferencyjnych (Preference Pairs). Ten model pozwala na osiągnięcie komercyjnego cyklu poprzez „bezzaufany drobny tuning” (Trustless Fine-tuning).
Porównanie architektur projektów Web3 w uczeniu ze wzmocnieniem

Pięć. Podsumowanie i perspektywy: Ścieżki i możliwości uczenia ze wzmocnieniem × Web3
Na podstawie analizy dekonstruującej powyższe projekty na czołowej liście, zaobserwowaliśmy: mimo że punkty wejścia różnych zespołów (algorytmy, inżynieria lub rynek) różnią się, kiedy uczenie ze wzmocnieniem (RL) łączy się z Web3, logika architektury podstawowej konwerguje do wysoce spójnego paradygmatu „odseparowanie-weryfikacja-nagroda”. To nie tylko techniczny zbieg okoliczności, ale także nieuchronny wynik unikalnych właściwości uczenia ze wzmocnieniem w zdecentralizowanej sieci.
Ogólne cechy architektury uczenia ze wzmocnieniem: rozwiązanie kluczowych ograniczeń fizycznych i problemów zaufania
Rozdzielenie fizyczne (Decoupling of Rollouts & Learning) - domyślna topologia obliczeniowa
Komunikacja o niskiej gęstości, możliwa do równoległego wykonania Rollout jest zlecana globalnym konsumpcyjnym GPU, a aktualizacje parametrów o wysokiej przepustowości są skoncentrowane w nielicznych węzłach treningowych, od asynchronicznego aktora-uczącego Prime Intellect po podwójną architekturę Gradient Echo.
Weryfikowalna warstwa zaufania (Verification-Driven Trust) - infrastrukturalna
W środowisku bez zezwolenia, autentyczność obliczeń musi być zapewniona przez projekt matematyczny i mechanizm, co reprezentuje realizację w tym zakresie, w tym PoL Gensyn, TOPLOC Prime Intellect i weryfikację kryptograficzną Grail.
Zamknięta pętla zachęt tokenowych (Tokenized Incentive Loop) - samoregulacja rynku
Dostarczanie mocy obliczeniowej, generowanie danych, weryfikacja kolejek i podział nagród tworzą zamkniętą pętlę, uczestnicząc poprzez napędy nagród, tłumiąc oszustwa, co pozwala sieci na stabilność i nieprzerwaną ewolucję w otwartych środowiskach.
Zróżnicowane ścieżki technologiczne: różne „punkty przełomu” w ramach wspólnej architektury
Mimo że architektura zbliża się do wspólnej, różne projekty wybrały różne techniczne osłony w zależności od swoich genów:
Grupa przełomów algorytmicznych (Nous Research): stara się rozwiązać fundamentalne sprzeczności w rozproszonym szkoleniu (wąskie gardło przepustowości) od podstaw matematycznych. Jej optymalizator DisTrO ma na celu zmniejszenie ilości komunikacji gradientów o tysiące razy, aby domowe łącza szerokopasmowe mogły także obsługiwać trening dużych modeli, co jest „degradacją” ograniczeń fizycznych.
Grupa inżynierii systemów (Prime Intellect, Gensyn, Gradient): koncentruje się na budowaniu następnej generacji „systemów runtime AI”. ShardCast Prime Intellect i Parallax Gradient są zaprojektowane, aby wycisnąć najwyższą wydajność heterogenicznych klastrów w istniejących warunkach sieciowych poprzez ekstremalne środki inżynieryjne.
Grupa gier rynkowych (Bittensor, Fraction AI): koncentruje się na projektowaniu funkcji nagród (Reward Function). Poprzez precyzyjne projektowanie mechanizmów oceniania, prowadzą górników do samodzielnego poszukiwania optymalnych strategii, przyspieszając pojawienie się inteligencji.
Zalety, wyzwania i przyszłość
W paradygmacie integracji uczenia ze wzmocnieniem i Web3, korzyści na poziomie systemowym w pierwszej kolejności objawiają się w przekształceniu struktury kosztów i struktury zarządzania.
Przekształcenie kosztów: wymagania szkolenia po (Post-training) dotyczące próbkowania (Rollout) są nieograniczone, Web3 może wzywać globalną moc obliczeniową o niskich kosztach, co jest przewagą kosztową, której centralne dostawcy chmurowi nie mogą dorównać.
Zgodność suwerenna (Sovereign Alignment): łamie monopol dużych firm na wartości AI (Alignment), społeczności mogą poprzez głosowanie tokenowe decydować, co model „uznaje za dobrą odpowiedź”, co prowadzi do demokratyzacji zarządzania AI.
W międzyczasie, ten system napotyka również na dwa główne ograniczenia strukturalne.
Ściana przepustowości (Bandwidth Wall): mimo innowacji takich jak DisTrO, fizyczne opóźnienia wciąż ograniczają całkowite szkolenie super dużych modeli parametrów (70B+), a obecnie AI Web3 jest bardziej ograniczone do dostosowania i wnioskowania.
Prawo Goodharta (Reward Hacking): w wysoko stymulowanej sieci górnicy łatwo „przeuczą” zasady nagród (oszustwo punktowe) zamiast podnosić prawdziwą inteligencję. Projektowanie odpornych funkcji nagród przeciwko oszustwom to wieczny dylemat.
Złośliwe ataki węzłów z typu byzantyjskiego (BYZANTINE worker): poprzez aktywne manipulowanie sygnałami treningowymi i ich zanieczyszczanie, wpływają na konwergencję modelu. Klucz nie polega na ciągłym projektowaniu funkcji nagród odpornych na oszustwa, lecz na budowaniu mechanizmów posiadających odporność na przeciwdziałanie.
Integracja uczenia ze wzmocnieniem i Web3 w istocie polega na przepisaniu mechanizmów „jak inteligencja jest produkowana, dostosowywana i wartościowana”. Ścieżka ewolucji może być podsumowana jako trzy uzupełniające się kierunki:
Zdecentralizowana sieć szkoleniowa: od górników mocy obliczeniowej do sieci strategii, zlecająca równoległe i weryfikowalne Rollouty globalnym GPU o niskim kosztach, krótko skupiona na rynku weryfikowalnego wnioskowania, w średnim okresie ewoluująca do podsieci uczenia ze wzmocnieniem klastryzowanych według zadań;
Aktywizacja preferencji i nagród: od pracowników oznaczających do aktywów danych. Realizacja aktywacji preferencji i nagród przekształca wysokiej jakości zwroty i Model Nagrody w zasoby danych podlegające zarządzaniu i podziałowi, co przekształca „pracowników oznaczających” w „aktywa danych”.
Ewolucja „małych i pięknych” w wąskich dziedzinach: w wyniku przejrzystości wyników i mierzalności korzyści, w pionowych scenariuszach pojawiają się małe, ale silne dedykowane Agenty RL, takie jak wykonanie strategii DeFi, generowanie kodu, co pozwala na bezpośrednie powiązanie poprawy strategii z przechwytywaniem wartości i przewiduje, że będą one lepsze od ogólnych zamkniętych modeli.
Ogólnie rzecz biorąc, prawdziwa możliwość uczenia ze wzmocnieniem × Web3 nie polega na skopiowaniu zdecentralizowanej wersji OpenAI, lecz na przepisaniu „relacji produkcji inteligencji”: umożliwiając, aby wykonanie szkolenia stało się rynkiem otwartej mocy obliczeniowej, nagrody i preferencje stały się aktywami łańcuchowymi podlegającymi zarządzaniu, a wartość przyniesiona przez inteligencję była ponownie przydzielana nie w platformie, lecz między trenerami, dostosowującymi i użytkownikami.
Zastrzeżenie: Niniejszy artykuł został stworzony z pomocą narzędzi AI ChatGPT-5 i Gemini 3. Autor dołożył wszelkich starań, aby sprawdzić i zapewnić prawdziwość i dokładność informacji, ale nieuchronnie mogą wystąpić niedopatrzenia, za co prosimy o wybaczenie. Należy szczególnie zwrócić uwagę, że w rynku aktywów kryptograficznych powszechnie występują sytuacje, w których podstawy projektów różnią się od cen na rynku wtórnym. Treść artykułu służy jedynie do integracji informacji oraz akademickiej/badawczej wymiany, nie stanowi żadnej porady inwestycyjnej i nie powinna być interpretowana jako rekomendacja kupna lub sprzedaży jakiegokolwiek tokena.


