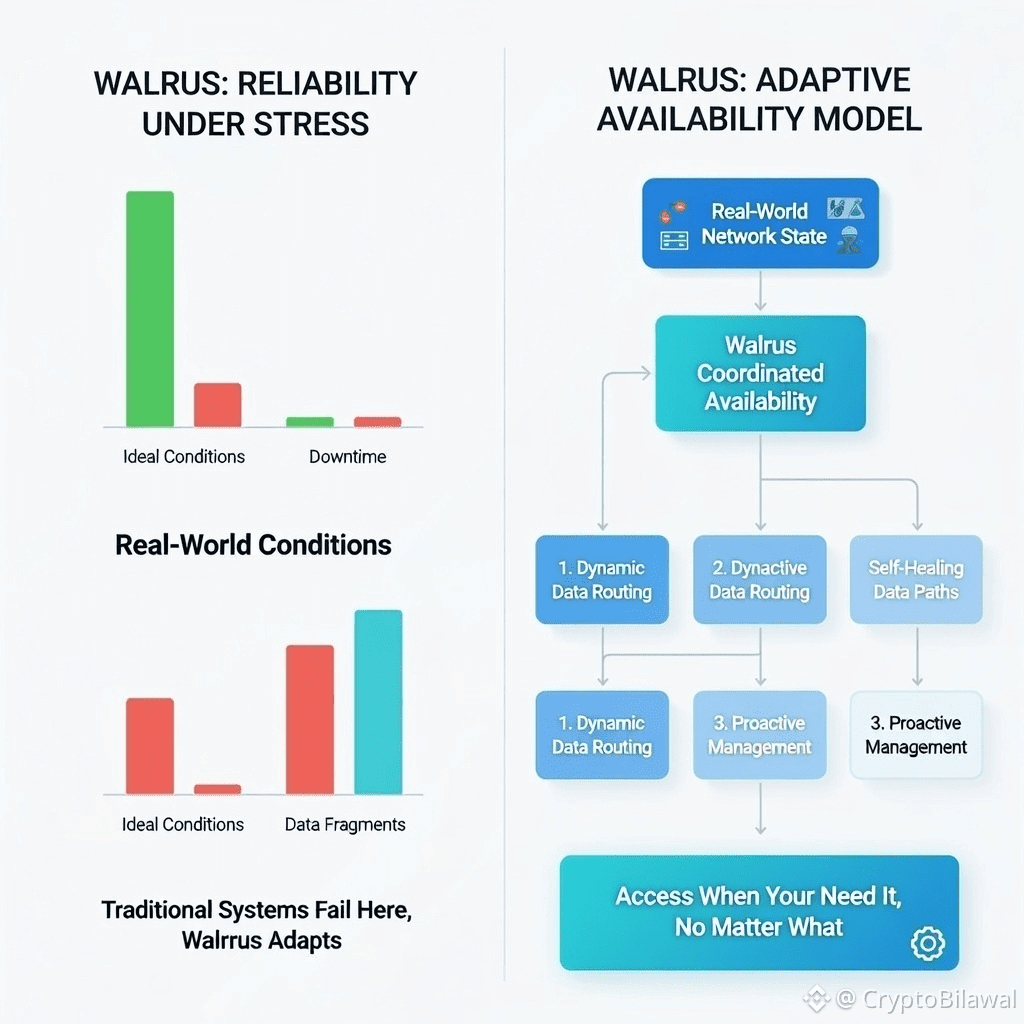
#WALRUS $WAL @Walrus 🦭/acc 1. Reliability Under Stress (Left Side)
This section uses bar charts to compare performance between Ideal Conditions and Real-World Conditions (which often involve downtime and data fragmentation).
The Problem: Traditional systems often see a massive spike in downtime and failure when conditions aren't perfect.
The Walrus Solution: The chart suggests that while other systems fail when data becomes fragmented or nodes go offline, Walrus "adapts." It maintains high availability by effectively managing "Data Fragments" to ensure the information remains accessible.
2. Adaptive Availability Model (Right Side)
This flowchart explains the technical logic behind how Walrus maintains its uptime. It follows a path from the "Real-World Network State" to "Coordinated Availability" through three main pillars:
Dynamic/Dynactive Data Routing: Automatically directing data through the most efficient paths.
Proactive Management: Anticipating potential node failures before they impact the user.
Self-Healing Data Paths: Automatically repairing or rerouting data if a part of the network fails.
Core Value Proposition
The central message is summarized at the bottom: "Access When You Need It, No Matter What." Walrus positions itself as a robust alternative to traditional storage by being "fault-tolerant," meaning it can survive the "messiness" of real-world internet connectivity issue