
AI workloads behave fundamentally differently from traditional transactional systems. They are not defined by a single execution path or uniform resource demand. Instead, they consist of multiple stages data ingestion, memory retrieval, reasoning, model execution, and settlement each with distinct performance and infrastructure requirements. Treating these workloads as a monolithic system creates bottlenecks that limit scalability, reliability, and long-term efficiency. This is why modular architecture is becoming a foundational requirement for AI-native infrastructure.
𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁 𝗕𝗼𝘁𝘁𝗹𝗲𝗻𝗲𝗰𝗸𝘀 𝗔𝗿𝗲 𝗮 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗮𝗹 𝗣𝗿𝗼𝗯𝗹𝗲𝗺
In monolithic architectures, all workloads compete for the same resources. When one component becomes overloaded, the entire system slows down. For AI systems, this is especially problematic. Data preprocessing may be CPU-intensive, inference may require GPUs, and orchestration logic may depend on fast memory access. Scaling everything together to accommodate one bottleneck leads to wasted resources and rising costs.
Modular architecture solves this by separating functions into independently scalable components. Each module can be optimized, upgraded, or scaled based on its actual workload. This allows systems to respond to real demand rather than theoretical peak usage, reducing throughput constraints without over-provisioning.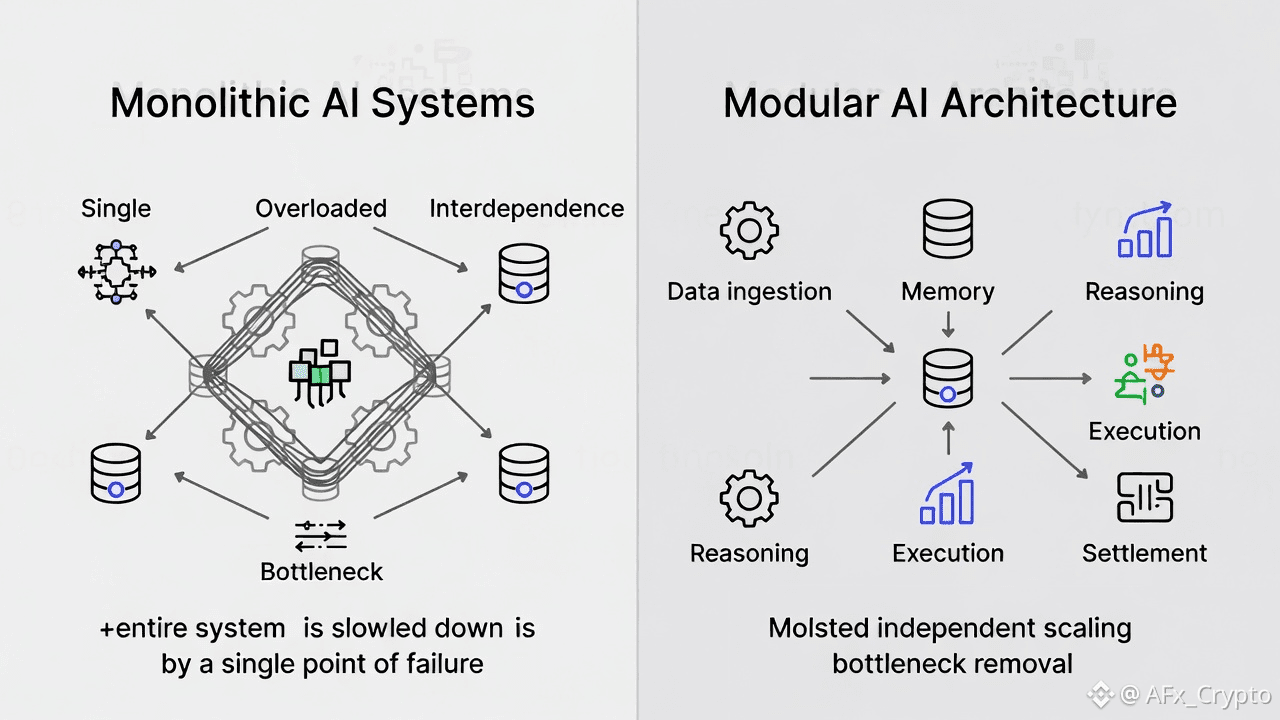
𝗔𝗴𝗶𝗹𝗶𝘁𝘆 𝗮𝗻𝗱 𝗠𝗮𝗶𝗻𝘁𝗮𝗶𝗻𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗶𝗻 𝗔𝗜 𝗦𝘆𝘀𝘁𝗲𝗺𝘀
AI systems are not static. Models evolve, data sources change, and reasoning logic improves over time. In tightly coupled systems, updates introduce risk, as changes in one area can cascade across the entire stack. Modular design introduces clear boundaries between components, enabling teams to update or replace individual modules without disrupting the system as a whole.
This agility is critical for long-term AI deployment. It allows infrastructure to adapt as models improve, regulations change, or usage patterns shift—without forcing full system rewrites or downtime.
𝗖𝗼𝘀𝘁 𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆 𝗮𝗻𝗱 𝗚𝗼𝘃𝗲𝗿𝗻𝗮𝗻𝗰𝗲
Large, monolithic AI systems are expensive to operate and difficult to govern. Modular architectures, by contrast, allow organizations to deploy smaller, purpose-built components that are easier to monitor and control. Costs become more predictable, and resource usage becomes more transparent. This is particularly important for enterprise and regulated environments, where explainability and cost control are non-negotiable requirements.
A modular approach also avoids over-reliance on single massive models. Instead of pushing all intelligence into one system, intelligence is distributed across smaller components that can reason over specific tasks and exchange results through structured interfaces. This improves responsiveness and explainability while lowering operational overhead.
𝗩𝗮𝗻𝗮𝗿’𝘀 𝗦𝗵𝗶𝗳𝘁 𝗕𝗲𝘆𝗼𝗻𝗱 𝗥𝗮𝘄 𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁
Within the Vanar ecosystem, recent development signals a clear move away from measuring performance purely by transaction speed or throughput. Instead, the focus has shifted toward an “Intelligence Layer” centered on memory, context, and coherence over time. This reflects a recognition that AI workloads are constrained less by raw execution speed and more by how effectively systems manage state, reasoning, and long-term context.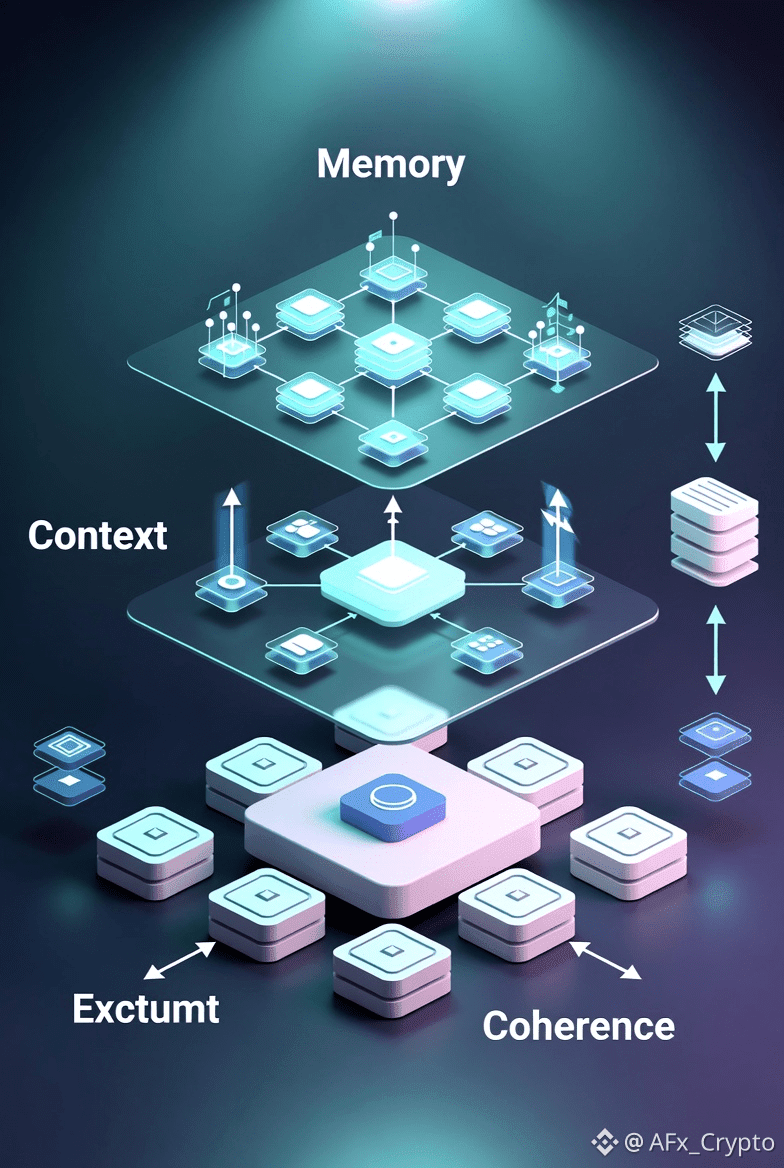
By prioritizing intelligence over raw TPS, Vanar addresses throughput bottlenecks at their root. Efficient memory handling and contextual awareness reduce redundant computation, limit unnecessary data movement, and improve decision quality across AI agents. Rather than processing more transactions indiscriminately, the system processes information more intelligently.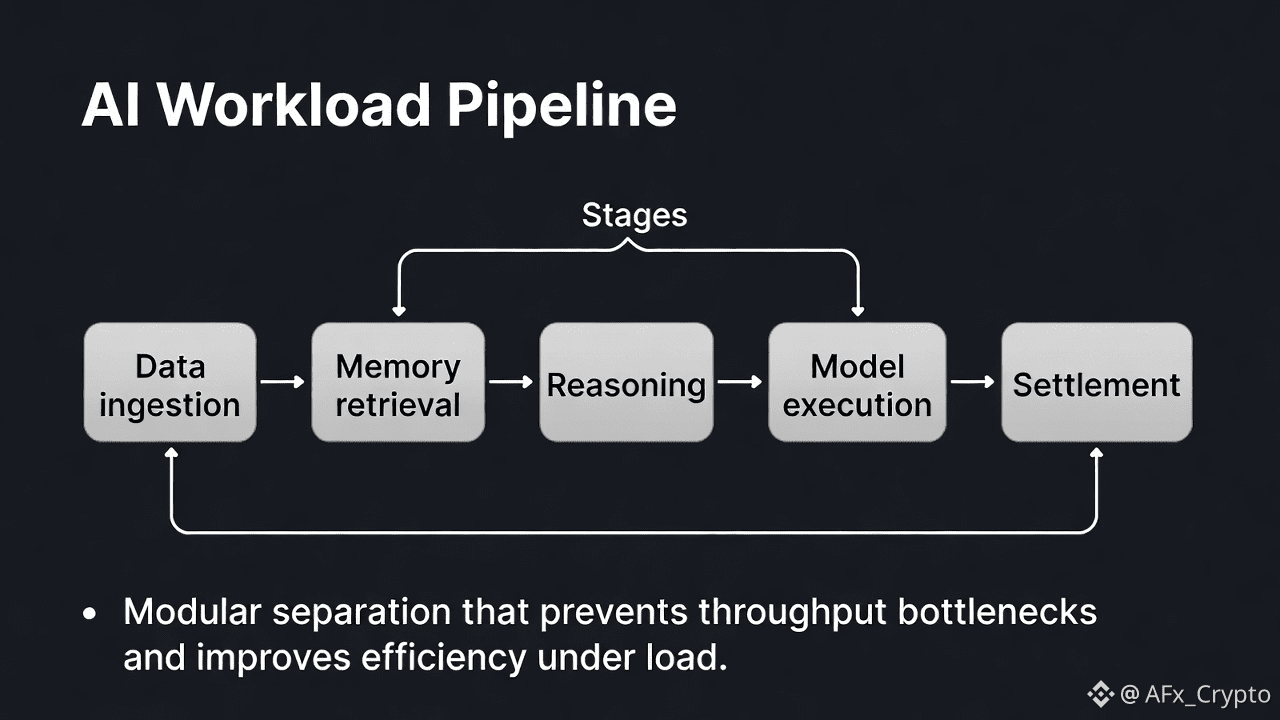
𝗠𝗼𝗱𝘂𝗹𝗮𝗿 𝗗𝗲𝘀𝗶𝗴𝗻 𝗮𝘀 𝗮𝗻 𝗘𝗻𝗮𝗯𝗹𝗲𝗿, 𝗡𝗼𝘁 𝗮 𝗙𝗲𝗮𝘁𝘂𝗿𝗲
Although not always described explicitly, Vanar’s architectural direction aligns with modular principles. Complex AI pipelines require separation between memory, reasoning, execution, and settlement layers. This allows each component to scale independently and prevents localized congestion from degrading overall system performance.
In this context, modularity is not an optimization—it is a prerequisite. Without it, AI infrastructure becomes brittle under real usage, regardless of how fast it appears in benchmarks.
𝗥𝗲𝘁𝗵𝗶𝗻𝗸𝗶𝗻𝗴 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗳𝗼𝗿 𝘁𝗵𝗲 𝗔𝗜 𝗘𝗿𝗮
For AI-native systems, performance is no longer defined by throughput alone. It is defined by sustained intelligence under load: the ability to maintain context, reason accurately, and execute safely as usage scales. Modular architecture enables this by eliminating structural bottlenecks and aligning infrastructure with how AI actually operates.
Vanar’s emphasis on intelligence, memory, and coherence reflects this shift. By addressing throughput challenges at the architectural level rather than chasing raw speed, it positions itself for real AI workloads rather than synthetic performance metrics.
#Vanar #vanar $VANRY @Vanarchain
