Walrus aparece en un punto de la industria que casi nunca se discute en público: el riesgo operativo real. En Web3 se analizan exploits, tokenomics, gobernanza y descentralización, pero muy pocos equipos calculan qué ocurre cuando los datos dejan de estar disponibles de forma parcial, intermitente o impredecible. No cuando se pierden por completo, sino cuando fallan lo suficiente como para romper productos, procesos internos, integraciones y confianza empresarial. La mayoría de protocolos no muere por un colapso visible, muere por acumulación de pequeños fallos que convierten la operación diaria en algo frágil.
 En empresas tradicionales esto se llama business continuity. En cripto casi nadie lo modela. Una dApp puede seguir “on-chain” y aun así volverse inutilizable si los historiales no cargan, si los estados tardan en recuperarse, si los archivos fallan bajo carga o si la latencia convierte cada interacción en fricción. El resultado no es un tweet anunciando el fracaso. Es soporte saturado, partners que se desconectan, usuarios que reducen actividad y equipos que empiezan a planear migraciones en silencio.
En empresas tradicionales esto se llama business continuity. En cripto casi nadie lo modela. Una dApp puede seguir “on-chain” y aun así volverse inutilizable si los historiales no cargan, si los estados tardan en recuperarse, si los archivos fallan bajo carga o si la latencia convierte cada interacción en fricción. El resultado no es un tweet anunciando el fracaso. Es soporte saturado, partners que se desconectan, usuarios que reducen actividad y equipos que empiezan a planear migraciones en silencio.
Aquí es donde el almacenamiento deja de ser un detalle técnico y se convierte en infraestructura de supervivencia. Walrus se diseña como una capa pensada no solo para guardar datos, sino para mantenerlos disponibles bajo condiciones adversas: nodos que fallan, picos de uso, fragmentación de red, mantenimiento, ataques o simples errores humanos. La combinación de erasure coding, distribución amplia y recuperación determinista apunta a un objetivo simple: que una aplicación pueda fallar en partes sin dejar de funcionar como sistema.
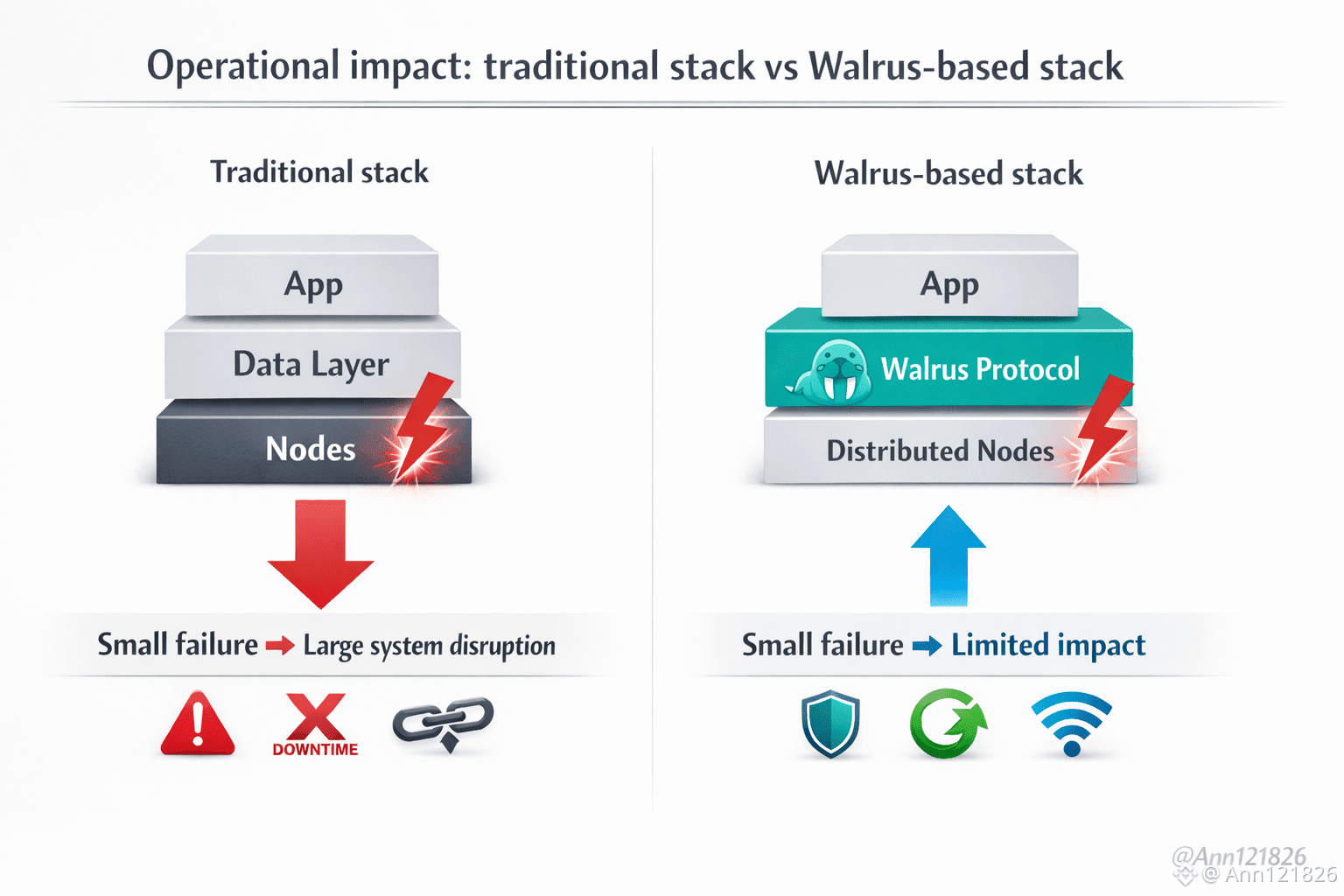
Esto tiene un efecto económico indirecto pero profundo. Cuando una plataforma puede garantizar continuidad, los desarrolladores se atreven a construir procesos críticos encima: historiales financieros, identidades, estados complejos, logs regulatorios, archivos que no se pueden regenerar. Cada una de esas capas aumenta el costo de interrupción y, al mismo tiempo, el valor de la red que las sostiene. No porque el marketing sea mejor, sino porque el riesgo operativo disminuye.
En ese contexto, $WAL no actúa como incentivo decorativo sino como combustible de estabilidad. Cada operación de almacenamiento, cada verificación de disponibilidad y cada recuperación tras un fallo es un evento económico real. No se paga por optimismo, se paga por continuidad. Para una empresa o protocolo serio, eso se parece más a un seguro operativo integrado que a un activo especulativo.
La mayoría de redes cripto vive en un equilibrio frágil: funcionan bien mientras todo sale bien. Pero los sistemas productivos se miden por su comportamiento cuando algo sale mal. Cuando hay congestión. Cuando hay fallos parciales. Cuando hay presión real. Ahí es donde se define si un protocolo es infraestructura o solo una demostración técnica.
Walrus apuesta por esa frontera incómoda. No promete eliminar fallos, promete que los fallos no destruyan el sistema. Y en una industria donde la mayoría diseña para el escenario perfecto, diseñar para el escenario imperfecto es una ventaja estratégica.
Al final, los usuarios no preguntan qué algoritmo se usó para dividir un archivo. Preguntan por qué la app dejó de funcionar un martes cualquiera. La diferencia entre desaparecer lentamente y volverse invisible como infraestructura confiable suele estar ahí. En Web3 se discute mucho cómo crecer rápido. Muy poco cómo seguir funcionando cuando crecer deja de ser el problema.
Ahí es donde Walrus realmente compite.