
Everyone keeps comparing simple "encode and share" approaches to Walrus like they're equivalent solutions. They're not. One has a hidden scalability trap that destroys performance at real scale. Let's talk about why O(n|blob|) dispersal costs kill naive approaches.
The Encode & Share Illusion
Here's what makes encode-and-share sound simple: take your blob, apply erasure coding, send shards to n validators. Done. One round of computation, one round of network traffic, problem solved.
Except it's not solved. That one-time dispersal cost is O(n|blob|)—linear in both the number of validators and the size of the blob. For a 1GB blob going to 1,000 validators, you're moving 1TB across the network in initial dispersal alone.
Then validators rotate. Blobs need to be re-dispersed. New validators join and need historical data. The one-time cost becomes a recurring cost, and suddenly you've identified the fundamental scaling bottleneck.
Most projects using encode-and-share pretend this cost is acceptable. Walrus recognized it as a design flaw.
Why O(n|blob|) Kills at Scale
Let's do real math. Assume:
10,000 active validators
Average blob size: 100MB
One dispersal event per blob
Validators rotate at 20% per epoch
One dispersal costs 1TB of network traffic (10,000 × 100MB). If you're ingesting 1GB of new blobs per block and have 10 blocks per second, that's 10GB per second of new dispersal traffic. At 10% weekly validator rotation, you're re-dispersing historical data constantly.
Your network traffic becomes dominated by dispersal overhead instead of serving users.
Now scale to what Ethereum or Solana actually processes: terabytes per day of data. The dispersal overhead becomes prohibitive. Projects hit a ceiling where they can't ingest new data because they're too busy re-dispersing old data.

Static Approaches Versus Dynamic
Static systems try to escape this by pre-assigning validators. "Here are your custodian nodes for this epoch. You send data directly to them." This reduces dispersal cost to O(k|blob|) where k is the committee size, not the full network.
But static assignment creates different problems. What happens when your custodian nodes go offline? What if the committee is Byzantine and coordinating against you? Static approaches trade dispersal efficiency for custodian concentration.
Walrus takes a different path.
Walrus's Dispersal-Aware Design
@Walrus 🦭/acc doesn't pretend dispersal cost away. It designs the entire system around minimizing and batching dispersal overhead.
First, data is dispersed to a small custodian committee, not the entire network. That's O(k|blob|) instead of O(n|blob|). Dispersal cost scales with committee size, not validator count.
Second, Walrus uses a gossip protocol for broader distribution rather than direct dispersal. Shards propagate through the network efficiently using existing peer-to-peer topology. This leverages network bandwidth that would be used anyway instead of creating new dispersal traffic.
Third, static committees mean data is dispersed once per epoch, not constantly re-dispersed as validators rotate. The per-epoch cost is amortized across the entire epoch of data ingestion.
The Committee Size Trade-Off
Here's where design maturity shows: Walrus doesn't use one committee size for all blobs. Committee size scales with blob importance and size. Critical data gets larger committees (higher Byzantine safety). Smaller, less critical blobs use smaller committees (lower overhead).
Encode-and-share systems either choose one size and accept suboptimal trade-offs for all blobs, or they add complexity managing variable-size committees. Walrus's design naturally accommodates both.
Network Bandwidth Reality
Encode-and-share projects measure success by "we can ingest X MB per second!" They don't mention the hidden Y MB per second of re-dispersal overhead they're paying constantly.
Walrus measures total network utilization. Dispersal overhead plus serve traffic plus rebalancing. When you optimize for the total system cost instead of ignoring dispersal, your architecture looks different.
Why This Matters for Production Validators
A validator joining the network needs to catch up on historical data. With encode-and-share, that's every shard of every blob ever ingested—O(n|blob|) bandwidth per validator onboarding.
With Walrus static committees, new validators query their assigned blobs directly from the committee. Bandwidth is O(k|blob|) not O(n|blob|). Onboarding becomes practical instead of prohibitive.
Similarly, when a validator needs to sync state or verify data, Walrus's design makes verification efficient. Encode-and-share forces you to re-request and re-verify shards that were dispersed months ago.
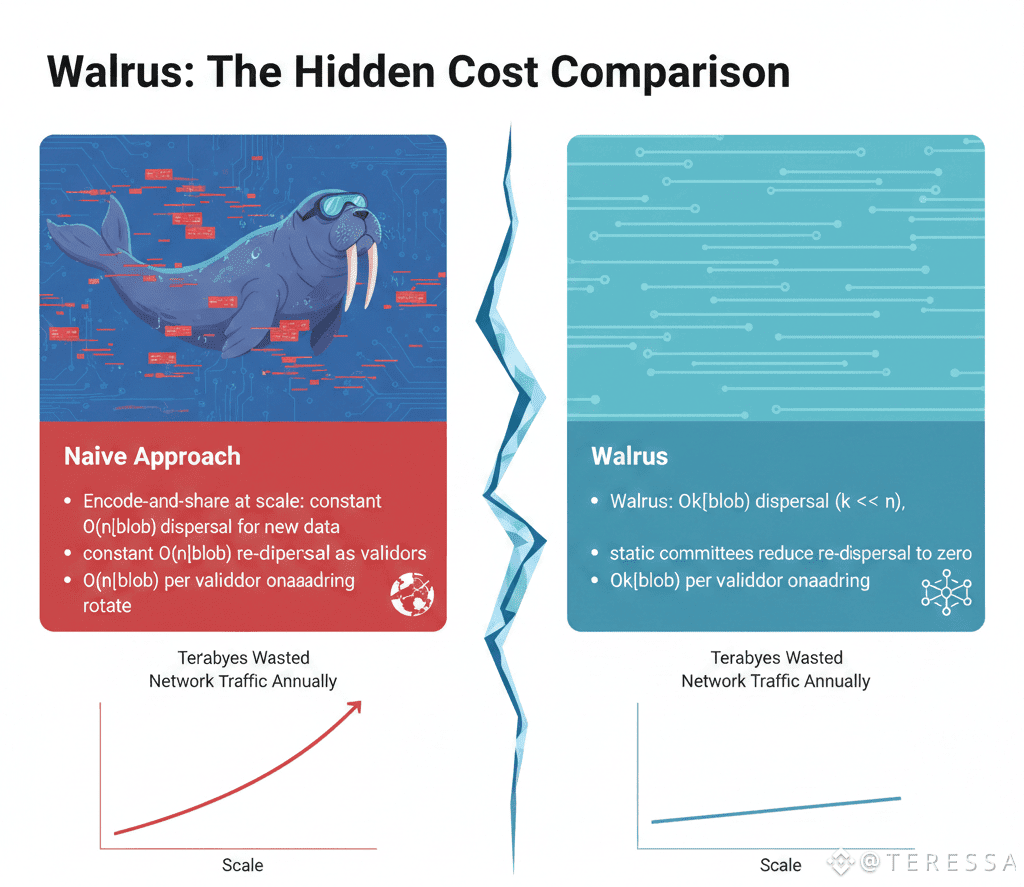
The Hidden Cost Comparison
Encode-and-share at scale: constant O(n|blob|) dispersal for new data, constant O(n|blob|) re-dispersal as validators rotate, O(n|blob|) per validator onboarding.
Walrus: O(k|blob|) dispersal (k << n), static committees reduce re-dispersal to zero, O(k|blob|) per validator onboarding.
The difference compounds. At Ethereum scale, that's terabytes of wasted network traffic annually with naive approaches.
Walrus shows why naive encode-and-share approaches fail at scale. O(n|blob|) dispersal overhead becomes the bottleneck that kills throughput and makes validator onboarding impossible. Walrus solves this through custodian committees, static assignment, and gossip-based propagation. You get erasure coding's fault tolerance without the dispersal trap. For infrastructure handling real data scale, this isn't optional. Walrus makes the difference between theoretical possibility and practical viability.

