

Ninguém te chama porque um blob "desapareceu."
Eles te chamam porque o blob está lá e ainda não carrega.
No Walrus, esse é o estado intermediário feio que as equipes odeiam... nem perda, nem interrupção. Um alvo em movimento. Mesmo ID de blob, caminho de serviço diferente, e um usuário que não se importa que a rede esteja em meio a uma rotação na fronteira de época. Eles apenas atualizam novamente. E novamente.
Esta não é a ideia poética da disponibilidade do Walrus. É continuidade enquanto o mapa está mudando sob seus pés.
Os fragmentos estão onde deveriam estar, no papel. A codificação de Erasure do Walrus ainda torna a reconstrução possível, no papel. O lado onchain ainda tem a reivindicação. O registro de prova de disponibilidade pode até estar limpo para a janela que você pagou.
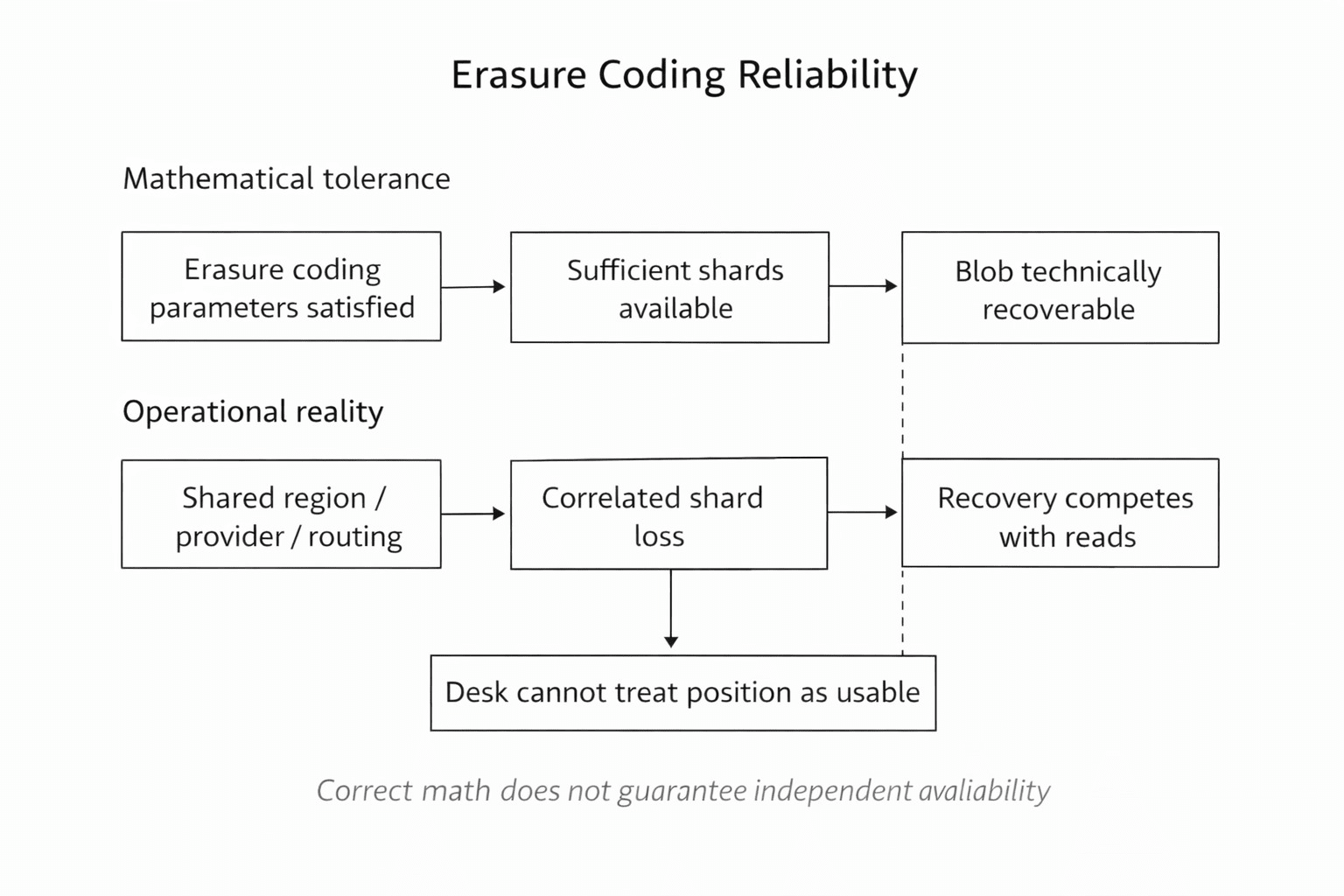
E a busca ainda para. p95 dobra antes que alguém queira dizer isso em voz alta.
Porque o que escorrega primeiro não é os dados. É a transferência. A coordenação que deveria ser entediante.
Alguns nós desaceleram. Alguns pares estão "ativos" mas efetivamente adormecidos. O caminho mais rápido para as peças muda. As atribuições de dever mudam. O trabalho de reparo começa a competir com leituras ao vivo no exato momento em que os usuários aumentam as tentativas porque a interface parece travada.
É quando "mais ou menos bem" começa a te cobrar.
Você pode observar a cascata nos lugares mais entediantes:
Uma carteira tenta novamente porque não recebeu uma resposta a tempo. O frontend tenta novamente porque assume que a solicitação foi perdida. Um edge de CDN tenta novamente porque acha que está ajudando... e agora você está perseguindo fantasmas.
Agora você transformou um caminho levemente degradado em carga. Não é carga maliciosa. Carga de usuário normal. O tipo pelo qual ninguém quer apontar o dedo.
No Walrus, reparos também não são gratuitos. A largura de banda de reparo é largura de banda real. Se a rede está reconstruindo redundância enquanto as leituras atacam os mesmos recursos, alguém tem que escolher o que tem prioridade. Servir através da fronteira ou curar a fronteira primeiro.
As equipes corrigem rapidamente. Claro que sim.
Eles adicionam regras de cache e as chamam de temporárias. Eles pré-buscam blobs "quentes" antes das janelas de churn conhecidas. Eles adicionam silenciosamente um caminho de fallback para que o usuário nunca toque na rota instável novamente.
E aqui está a parte que ninguém escreve na documentação: essas correções não são removidas. Elas se tornam a arquitetura.
Walrus ainda pode ser a rede de segurança. A camada de liquidação para reivindicações. A trilha de auditoria que diz "esta obrigação foi cumprida nesta janela." Mas se o caminho ao vivo continua instável nos momentos exatos em que a responsabilidade está se movendo, os construtores irão contorná-lo sem chamá-lo de filosofia.
Eles vão chamar: "Não estou sendo notificado novamente."
Na próxima semana, "funciona." Ninguém remove o fallback.