1. Introducere | Schimbarea Model-Layer în Crypto AI
Datele, modelele și calculul formează cele trei piloni esențiali ai infrastructurii AI—comparabili cu combustibilul (date), motorul (model) și energia (calcul)—toate indispensabile. La fel ca evoluția infrastructurii în industria AI tradițională, sectorul Crypto AI a urmat o traiectorie similară. La începutul anului 2024, piața a fost dominată de proiecte GPU descentralizate (cum ar fi Akash, Render și io.net), caracterizate printr-un model de creștere bazat pe resurse, concentrat pe puterea de calcul brut. Cu toate acestea, până în 2025, atenția industriei s-a mutat treptat către straturile modelului și datelor, marcând o tranziție de la competiția de infrastructură de nivel inferior la dezvoltarea mai sustenabilă, orientată spre aplicații, a straturilor intermediare.
LLM-uri cu scop general vs. SLM-uri specializate
Modelele mari de limbaj tradiționale (LLM-uri) se bazează în mare măsură pe seturi masive de date și infrastructuri complexe de antrenament distribuit, cu dimensiuni de parametru adesea variind de la 70B la 500B, iar sesiuni unice de antrenament costând milioane de dolari. În contrast, Modelele Lingvistice Specializate (SLM-uri) adoptă un paradigme de ajustare fină ușoară care reutilizează modele de bază open-source precum LLaMA, Mistral sau DeepSeek și le combină cu seturi de date specifice domeniului de înaltă calitate și instrumente precum LoRA pentru a construi rapid modele de expert la costuri și complexitate semnificativ reduse.
Este important de menționat că SLM-urile nu sunt integrate înapoi în greutățile LLM-urilor, ci funcționează în tandem cu LLM-urile prin mecanisme precum orchestrarea bazată pe agenți, rutarea plugin-urilor, adaptatoarele LoRA schimbabile pe căldură și sistemele RAG (Generație Augmentată de Recuperare). Această arhitectură modulară păstrează acoperirea largă a LLM-urilor, în timp ce îmbunătățește performanța în domenii specializate—permițând un sistem AI extrem de flexibil și compus.
Rolul și limitele Crypto AI la nivelul modelului
Proiectele Crypto AI, prin natura lor, se confruntă cu dificultăți în a îmbunătăți direct capacitățile de bază ale LLM-urilor. Acest lucru se datorează:
Bariere tehnice ridicate: Antrenarea modelelor fundamentale necesită seturi masive de date, putere de calcul și expertiză în inginerie—capabilități deținute în prezent doar de marii jucători din tehnologie din SUA (de exemplu, OpenAI) și China (de exemplu, DeepSeek).
Limitările ecosistemului open-source: Deși modele precum LLaMA și Mixtral sunt open-source, descoperirile critice depind în continuare de instituții de cercetare off-chain și de procese de inginerie proprietare. Proiectele pe lanț au o influență limitată la nivelul modelului de bază.
Ceea ce se spune, AI-ul Crypto poate încă crea valoare prin ajustarea fină a SLM-urilor pe baza modelelor de bază open-source și prin valorificarea primitivilor Web3 precum verificabilitatea și stimulentele bazate pe tokeni. Poziționat ca "stratul de interfață" al stivei AI, proiectele Crypto AI contribuie în principal în două domenii principale:
Stratificat de verificare de încredere: Înregistrarea pe lanț a căilor de generare a modelului, contribuțiile de date și înregistrările de utilizare îmbunătățesc trasabilitatea și rezistența la manipulare a rezultatelor AI.
Mecanisme de stimulare: Tokenii nativi sunt utilizați pentru a recompensa încărcările de date, apelurile modelului și execuțiile Agentului—construind un ciclu de feedback pozitiv pentru antrenarea și utilizarea modelului.
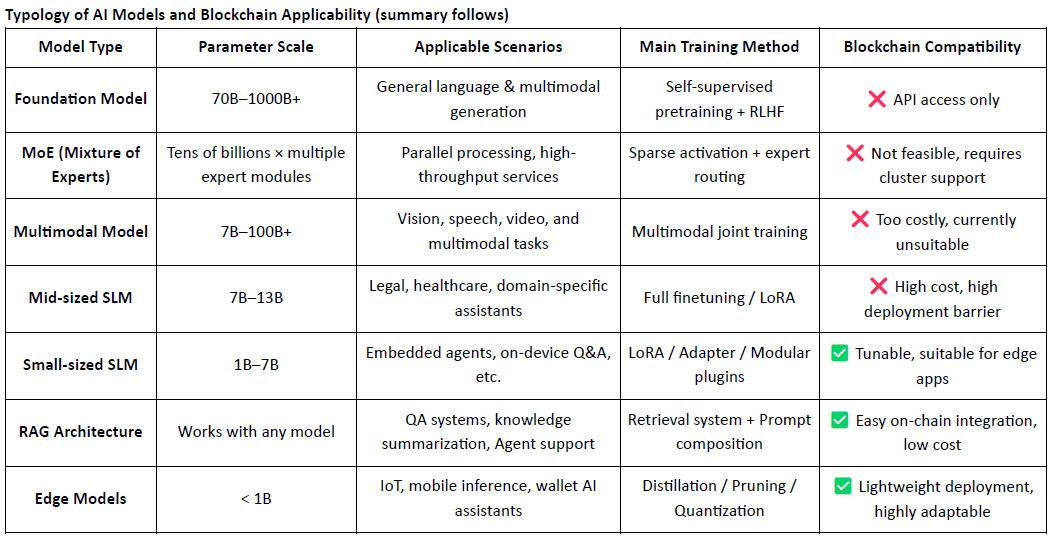
Aplicațiile fezabile ale proiectelor Crypto AI centrate pe model sunt concentrate în principal în trei domenii: ajustarea fină ușoară a SLM-urilor mici, integrarea și verificarea datelor pe lanț prin arhitecturi RAG și desfășurarea locală și stimularea modelului de margine. Prin combinarea verificabilității blockchain-ului cu mecanismele de stimulente bazate pe tokeni, Crypto poate oferi o valoare unică în aceste scenarii de model de resurse medii și reduse, formând un avantaj diferențiat în "stratul de interfață" al stivei AI.
O blockchain AI axată pe date și modele permite înregistrări transparente și imuabile pe lanț pentru fiecare contribuție la date și modele, îmbunătățind semnificativ credibilitatea datelor și trasabilitatea antrenării modelelor. Prin mecanismele contractelor inteligente, poate declanșa automat distribuția recompenselor ori de câte ori datele sau modelele sunt utilizate, convertind activitatea AI în valoare tokenizată măsurabilă și comercializabilă—creând astfel un sistem de stimulare sustenabil. În plus, membrii comunității pot participa la guvernare descentralizată prin voturi asupra performanței modelului și contribuind la stabilirea și iterarea regulilor folosind tokeni.
2. Prezentare generală a proiectului | Viziunea OpenLedger pentru un lanț AI
@OpenLedger este unul dintre puținele proiecte AI pe blockchain din piața actuală care se concentrează în mod specific pe mecanismele de stimulare a datelor și modelului. Este un pionier al conceptului "Payable AI", având ca scop construirea unui mediu de execuție AI echitabil, transparent și compus care stimulează colaborarea contribuabililor de date, dezvoltatorilor de modele și constructorilor de aplicații AI pe o singură platformă—și câștigarea recompenselor pe lanț pe baza contribuțiilor efective.
@OpenLedger oferă un sistem complet de la un capăt la altul—de la "contribuția de date" la "desfășurarea modelului" până la "împărțirea veniturilor bazate pe utilizare." Modulele sale de bază includ:
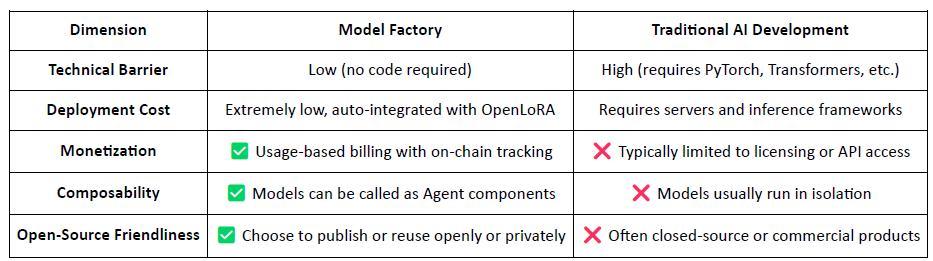
Model Factory: Ajustare fină fără cod și desfășurare de modele personalizate utilizând LLM-uri open-source cu LoRA;
OpenLoRA: Susține coexistența a mii de modele, încărcate dinamic la cerere pentru a reduce costurile de desfășurare;
PoA (Dovada Atribuirii): Urmărește utilizarea pe lanț pentru a aloca corect recompensele pe baza contribuției;
Datanets: Rețele de date structurate, conduse de comunitate, adaptate pentru domenii verticale;
Platforma de Propuneri pentru Modele: O piață de modele pe lanț, compusă, apelabilă și plătibilă.
Împreună, aceste module formează o infrastructură de model compusă și bazată pe date—stabilind fundația pentru o economie a agenților pe lanț.
Pe partea de blockchain, @OpenLedger construit pe OP Stack + EigenDA, oferind un mediu de înaltă performanță, cu costuri reduse și verificabil pentru rularea modelelor AI și contractelor inteligente:
Construit pe OP Stack: Valorifică stiva tehnică Optimism pentru un randament ridicat și costuri reduse;
Așezare pe Ethereum Mainnet: Asigură securitatea tranzacțiilor și integritatea activelor;
Compatibil cu EVM: Permite desfășurarea rapidă și scalabilitatea pentru dezvoltatorii Solidity;
Disponibilitatea datelor alimentată de EigenDA: Reduce costurile de stocare în timp ce asigură accesul verificabil la date.
Comparativ cu lanțurile AI cu scop general precum NEAR—care se concentrează pe infrastructura de bază, suveranitatea datelor și cadrul "AI Agents on BOS"—@OpenLedger este mai specializat, având ca scop construirea unui lanț dedicat AI centrat pe stimularea datelor și a modelului. Își propune să facă dezvoltarea și invocarea modelului pe lanț verificabilă, compusă și sustenabil monetizabilă. Ca un strat de stimulare centrat pe model în ecosistemul Web3, OpenLedger combină găzduirea modelului în stil HuggingFace, facturarea bazată pe utilizare în stil Stripe și compunerea pe lanț în stil Infura pentru a avansa viziunea "model-ca-actif."
3. Componentele principale și arhitectura tehnică a OpenLedger
3.1 Fabrica de Model fără Cod
ModelFactory este platforma de ajustare fină integrată pentru modele de limbaj mari (LLM-uri) a @OpenLedger . Spre deosebire de cadrele tradiționale de ajustare fină, oferă o interfață complet grafică, fără cod, eliminând necesitatea instrumentelor de linie de comandă sau a integrărilor API. Utilizatorii pot ajusta modelele folosind seturi de date care au fost autorizate și validate prin @OpenLedger , permițând un flux de lucru de la un capăt la altul care acoperă autorizarea datelor, antrenarea modelului și desfășurarea.
Pașii cheie în fluxul de lucru includ:
Controlul accesului la date: Utilizatorii solicită acces la seturi de date; odată aprobate de furnizorii de date, seturile de date sunt conectate automat la interfața de antrenament.
Selecția și Configurarea Modelului: Alegeți dintre LLM-uri de vârf (de exemplu, LLaMA, Mistral) și configurați hiperparametrii prin GUI.
Ajustare fină ușoară: Suport încorporat pentru LoRA / QLoRA permite antrenamente eficiente cu urmărirea progresului în timp real.
Evaluare & Desfășurare: Instrumentele integrate permit utilizatorilor să evalueze performanța și să exporte modele pentru desfășurare sau reutilizare în ecosistem.
Interfața de testare interactivă: O interfață UI bazată pe chat permite utilizatorilor să testeze direct modelul ajustat în scenarii Q&A.
Atribuirea RAG: Generările augmentate de recuperare includ citate de sursă pentru a spori încrederea și auditabilitatea.
Arhitectura ModelFactory cuprinde șase module cheie, acoperind verificarea identității, permisiunile de date, ajustarea fină a modelului, evaluarea, desfășurarea și trasabilitatea bazată pe RAG, oferind o platformă de servicii pentru modele sigură, interactivă și monetizabilă.
Următoarele este o prezentare generală a modelelor de limbaj mari actualmente acceptate de ModelFactory:
Seria LLaMA: Unul dintre cele mai adoptate modele de bază open-source, cunoscut pentru performanța sa generală puternică și comunitatea vibrantă.
Mistral: Arhitectură eficientă cu performanță excelentă în inferență, ideală pentru desfășurare flexibilă în medii cu resurse restricționate.
Qwen: Dezvoltat de Alibaba, excelează în sarcinile de limbă chineză și oferă capabilități puternice generale—o alegere optimă pentru dezvoltatori în China.
ChatGLM: Cunoscut pentru performanța sa excelentă în conversațiile în limba chineză, bine adaptat pentru servicii pentru clienți verticale și aplicații localizate.
Deepseek: Excelează în generarea de cod și raționamentul matematic, făcându-l ideal pentru asistenți de dezvoltare inteligenți.
Gemma: Un model ușor lansat de Google, având o structură curată și ușurință în utilizare—potrivit pentru prototipuri rapide și experimente.
Falcon: Odată un standard de performanță, acum mai potrivit pentru cercetări fundamentale sau teste comparative, deși activitatea comunității a scăzut.
BLOOM: Oferă un suport puternic pentru multe limbi, dar o performanță de inferență relativ mai slabă, făcându-l mai potrivit pentru studii de acoperire a limbilor.
GPT-2: Un model clasic timpurie, acum util în principal pentru scopuri de predare și testare—desfășurarea în producție nu este recomandată.
Deși @OpenLedger lineup-ul de modele OpenLedger nu include încă cele mai recente modele de înaltă performanță MoE sau arhitecturi multimodale, această alegere nu este învechită. În schimb, reflectă o strategie "prioritate-practică" bazată pe realitățile desfășurării pe lanț—ținând cont de costurile de inferență, compatibilitatea RAG, integrarea LoRA și constrângerile mediului EVM.
Model Factory: Un Instrument fără Cod cu Atribuire a Contribuției încorporată
Ca un instrument fără cod, Model Factory integrează un mecanism de Dovadă a Atribuirii încorporat în toate modelele pentru a asigura drepturile contribuabililor de date și dezvoltatorilor de modele. Oferă bariere de intrare reduse, căi de monetizare native și compunere, distanțându-se de fluxurile de lucru tradiționale AI.
Pentru dezvoltatori: Oferă un pipeline complet de la crearea și distribuirea modelului până la generarea de venituri.
Pentru platformă: Permite un ecosistem lichid și compus pentru activele modelului.
Pentru utilizatori: Modelele și agenții pot fi apelate și compuse ca API-uri.
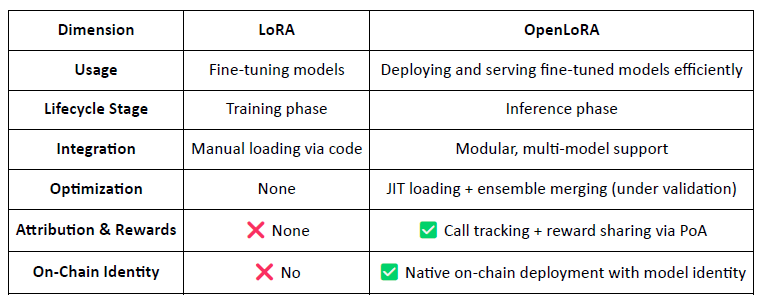
3.2 OpenLoRA, Assetizarea pe lanț a modelurilor ajustate
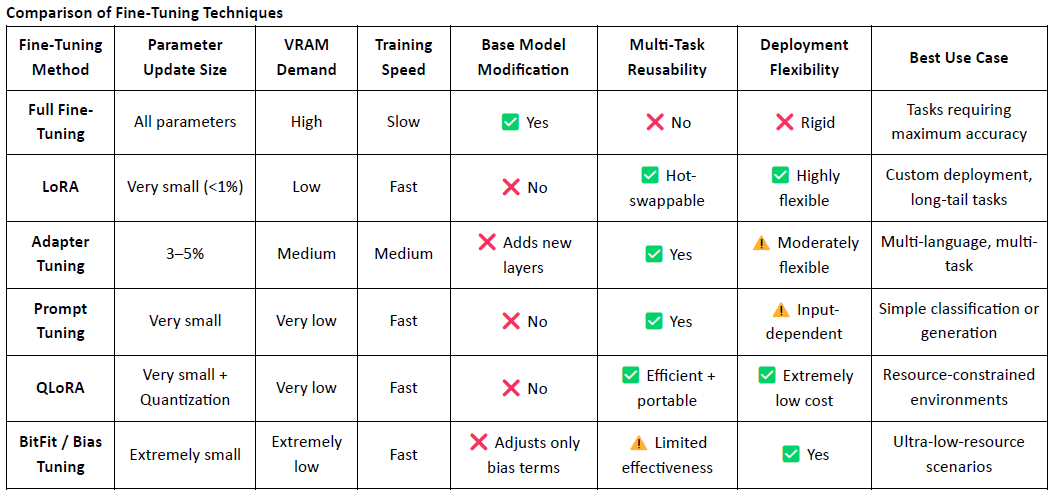
LoRA (Low-Rank Adaptation) este o tehnică eficientă de ajustare fină cu parametrii eficienți. Funcționează prin inserarea matricelor de rang scăzut care sunt antrenabile într-un model mare pre-antrenat fără a altera greutățile modelului original, reducând semnificativ atât costurile de antrenament, cât și cerințele de stocare.
Modelele de limbaj mari tradiționale (LLM-uri), cum ar fi LLaMA sau GPT-3, conțin adesea miliarde—sau chiar sute de miliarde—de parametrii. Pentru a adapta aceste modele la sarcini specifice (de exemplu, Q&A juridic, consultații medicale), este necesară ajustarea fină. Ideea cheie a LoRA este de a îngheța parametrii modelului original și de a antrena doar matricile adăugate recent, făcându-l extrem de eficient și ușor de desfășurat.
LoRA a devenit abordarea principală de ajustare fină pentru desfășurarea și compunerea modelului nativ Web3 datorită naturii sale ușoare și arhitecturii flexibile.
OpenLoRA este un cadru de inferență ușor dezvoltat de @OpenLedger special pentru desfășurarea multi-model și partajarea resurselor GPU. Scopul său principal este de a rezolva provocările costurilor ridicate de desfășurare, reutilizării slabe a modelului și utilizării ineficiente a GPU-ului—făcând viziunea "Payable AI" practic executabilă.
Arhitectură modulară pentru servirea scalabilă a modelului
OpenLoRA este compus din mai multe componente modulare care împreună permit desfășurarea scalabilă și rentabilă a modelului:
Găzduirea adaptatoarelor LoRA: Adaptatoarele LoRA ajustate sunt găzduite pe @OpenLedger și încărcate la cerere. Acest lucru evită încărcarea prealabilă a tuturor modelelor în memoria GPU și economisește resurse.
Găzduirea modelului & Strat de fuzionare a adaptatoarelor: Toate adaptatoarele împărtășesc un model de bază comun. În timpul inferenței, adaptatoarele sunt fuzionate dinamic, susținând inferența multi-adaptor de tip ansamblu pentru o performanță îmbunătățită.
Motorul de inferență: Implementarea optimizărilor la nivel CUDA, inclusiv Flash-Attention, Paged Attention și SGMV pentru a îmbunătăți eficiența.
Router de cereri & Streaming de tokeni: Direcționează dinamic cererile de inferență către adaptorul corespunzător și transmite tokeni folosind kernel-uri optimizate.
Fluxul de lucru de inferență de la un capăt la altul
Procesul de inferență urmează un pipeline matur și practic:
Inițializarea modelului de bază: Modelele de bază, cum ar fi LLaMA 3 sau Mistral sunt încărcate în memoria GPU.
Încărcarea dinamică a adaptatorului: La cerere, adaptatoarele LoRA specificate sunt recuperate din Hugging Face, Predibase sau stocare locală.
Fuzionare & Activare: Adaptatoarele sunt fuzionate în modelul de bază în timp real, susținând execuția de ansamblu.
Execuția inferenței & Streaming de tokeni: Modelul fuzionat generează ieșiri cu streaming la nivel de token, susținută de cuantificare atât pentru viteză, cât și pentru eficiența memoriei.
Eliberarea resurselor: Adaptatoarele sunt descărcate după execuție, eliberând memorie și permițând rotația eficientă a miilor de modele ajustate pe un singur GPU.
Optimizări cheie
OpenLoRA obține performanțe superioare prin:
Încărcarea adaptatorului JIT (Just-In-Time) pentru a minimiza utilizarea memoriei.
Paralelism Tensor și Atenție Paginată pentru gestionarea secvențelor mai lungi și execuția concurentă.
Fuzionarea Multi-Adapter pentru fuzionarea modelului compus.
Flash Attention, kernel-uri CUDA precompilate și cuantificarea FP8/INT8 pentru inferență mai rapidă și cu latență redusă.
Aceste optimizări permit inferențe multi-model de mare capacitate și costuri reduse chiar și în medii cu un singur GPU—în special potrivite pentru modele cu coadă lungă, agenți de nișă și AI extrem de personalizat.
OpenLoRA: Transformarea modelurilor LoRA în active Web3
Spre deosebire de cadrele tradiționale LoRA axate pe ajustarea fină, OpenLoRA transformă desfășurarea modelului într-un strat nativ Web3, monetizabil, făcând fiecare model:
Identificabil pe lanț (prin ID-ul modelului)
Stimulante economic prin utilizare
Componibile în agenți AI
Distribuibile ca recompense prin mecanismul PoA
Aceasta permite ca fiecare model să fie tratat ca un activ:
Previziunea performanței
În plus, @OpenLedger a lansat reperele de performanță viitoare pentru OpenLoRA. Comparativ cu desfășurările tradiționale ale modelului cu parametrii compleți, utilizarea memoriei GPU este semnificativ redusă la 8–12GB, timpul de comutare a modelului este teoretic sub 100ms, randamentul poate ajunge la peste 2.000 de tokeni pe secundă, iar latencia este menținută între 20–50ms.
Deși aceste cifre sunt realizabile din punct de vedere tehnic, ele ar trebui să fie înțelese ca proiecții de limită superioară mai degrabă decât performanțe zilnice garantate. În medii de producție din lumea reală, rezultatele efective pot varia în funcție de configurațiile hardware, strategiile de programare și complexitatea sarcinilor.
3.3 Datanets: De la proprietatea datelor la inteligența datelor
Datele de înaltă calitate, specifice domeniului, au devenit un activ critic pentru construirea de modele de înaltă performanță. Datanets servește ca infrastructura de bază a @OpenLedger pentru "date ca activ", permițând colectarea, validarea și distribuția seturilor de date structurate în rețele descentralizate. Fiecare Datanet acționează ca un depozit de date specific domeniului, unde contribuabilii încarcă date care sunt verificate și atribuite pe lanț. Prin permisiuni și stimulente transparente, Datanets permit curățarea datelor de încredere, conduse de comunitate, pentru antrenarea și ajustarea fină a modelelor.
Spre deosebire de proiecte precum Vana care se concentrează în principal pe proprietatea datelor, @OpenLedger depășește colectarea de date transformând datele în inteligență. Prin cele trei componente integrate—Datanets (seturi de date colaborative, atribuite), Model Factory (instrumente de ajustare fină fără cod) și OpenLoRA (adaptatoare de model trasabile, compuse)—OpenLedger extinde valoarea datelor pe tot parcursul ciclului de antrenare a modelului și utilizarea pe lanț. În timp ce Vana pune accent pe "cine deține datele", OpenLedger se concentrează pe "cum sunt antrenate, invocate și recompensate datele", poziționând cele două ca piloni complementari în stiva AI Web3: unul pentru asigurarea proprietății, celălalt pentru facilitarea monetizării.
3.4 Dovada atribuirii: redefinirea stratului de stimulare pentru distribuția valorii
Dovada Atribuirii (PoA) este @OpenLedger mecanismul de bază al OpenLedger pentru a lega contribuțiile de recompense. Înregistrează criptografic fiecare contribuție de date și invocare a modelului pe lanț, asigurându-se că contribuabilii primesc compensații corecte ori de câte ori contribuțiile lor generează valoare. Procesul decurge astfel:
Trimiterea de date: Utilizatorii încarcă seturi de date structurate, specifice domeniului și le înregistrează pe lanț pentru atribuție.
Evaluarea impactului: Sistemul evaluează relevanța de antrenament a fiecărui set de date la nivelul fiecărei inferențe, ținând cont de calitatea conținutului și de reputația contribuabililor.
Verificarea antrenamentului: Jurnalele urmăresc ce seturi de date au fost folosite efectiv în antrenamentul modelului, permițând dovada contribuției verificabile.
Distribuția recompenselor: Contribuabilii sunt recompensați în tokeni pe baza eficacității și influenței datelor asupra ieșirilor modelului.
Guvernare a calității: Datele de calitate scăzută, spammy sau malițioase sunt penalizate pentru a menține integritatea antrenamentului.
Comparativ cu arhitectura de stimulare bazată pe subrețele și reputație a Bittensor, care stimulează pe scară largă funcțiile de calcul, date și clasificare, @OpenLedger se concentrează pe realizarea valorii la nivelul modelului. PoA nu este doar un mecanism de recompense—este un cadru de atribuire în mai multe etape pentru transparență, proveniență și compensație pe parcursul întregii sale durate de viață: de la date la modele la agenți. Transformă fiecare invocare a modelului într-un eveniment trasabil, recompensabil, ancorând o pistă de valoare verificabilă care aliniază stimulentele pe tot parcursul conductei de active AI.
Generarea augmentată de recuperare (RAG) Atribuția
RAG (Retrieval-Augmented Generation) este o arhitectură AI care îmbunătățește ieșirile modelelor de limbaj prin recuperarea cunoștințelor externe—rezolvând problema informațiilor halucinate sau depășite. @OpenLedger introduce Atribuția RAG pentru a asigura că orice conținut recuperat utilizat în generarea modelului este trasabil, verificabil și recompensat.
Fluxul de lucru al Atribuirii RAG:
Interogarea utilizatorului → Recuperarea datelor: AI-ul recuperează date relevante din seturile de date indexate ale @OpenLedger (Datanets).
Generarea răspunsurilor cu utilizare urmărită: Conținutul recuperat este utilizat în răspunsul modelului și înregistrat pe lanț.
Recompense pentru contribuabili: Contribuabilii de date sunt recompensați pe baza fondului și relevanței recuperării.
Citații transparente: Ieşirile modelului includ linkuri către sursele originale de date, îmbunătățind încrederea și auditabilitatea.
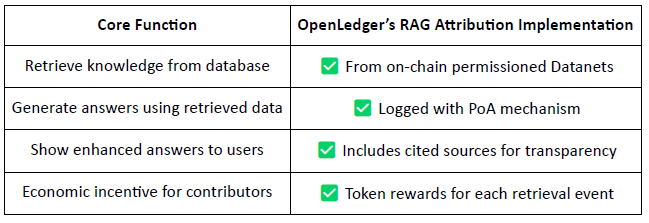
În esență, @OpenLedger 's RAG Attribution asigură că fiecare răspuns AI este trasabil la o sursă de date verificată, iar contribuabilii sunt recompensați pe baza frecvenței utilizării, permițând un ciclu de stimulare sustenabil. Acest sistem nu numai că crește transparența ieșirii, dar așază și baza pentru infrastructura AI verificabilă, monetizabilă și de încredere.
4. Progresul proiectului și colaborarea în ecosistem
@OpenLedger a lansat oficial testnet-ul său, cu prima fază concentrată pe Strat de Inteligență a Datelor—un depozit de date pe internet alimentat de comunitate. Acest strat agregă, îmbunătățește, clasifică și structurează datele brute în inteligență pregătită pentru model adecvat pentru antrenarea LLM-urilor specifice domeniului pe @OpenLedger . Membrii comunității pot rula noduri edge pe dispozitivele lor personale pentru a colecta și procesa date. În schimb, participanții câștigă puncte pe baza timpului de funcționare și a contribuțiilor la sarcini. Aceste puncte vor fi ulterior convertibile în $OPEN tokeni, cu mecanismul specific de conversie care va fi anunțat înainte de Evenimentul de Generare a Token-urilor (TGE).

Epoca 2: Lansarea Datanets
A doua fază a testnet-ului introduce Datanets, un sistem de contribuție doar pe listă albă. Participanții trebuie să treacă un pre-evaluare pentru a accesa sarcini precum validarea datelor, clasificarea sau anotarea. Recompensele se bazează pe acuratețe, nivelul de dificultate și clasamentul pe leaderboard.
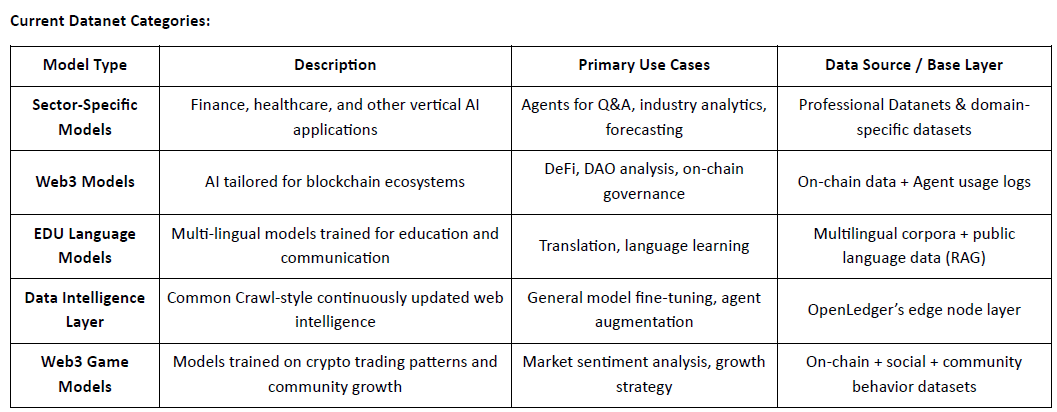
Foia de parcurs: Spre o economie AI descentralizată
@OpenLedger își propune să închidă bucla de la achiziția de date la desfășurarea agentului, formând un lanț valoric AI descentralizat complet:
Faza 1: Strat de Inteligență a Datelor
Nodurile comunității recoltează și procesează date de internet în timp real pentru stocare structurată.Faza 2: Contribuții ale comunității
Comunitatea contribuie la validare și feedback, formând "Setul de Date de Aur" pentru antrenarea modelului.Faza 3: Construiește modele și revendică
Utilizatorii ajustează și revendică proprietatea modelelor specializate, permițând monetizarea și compunerea.Faza 4: Construiește Agenți
Modelele pot fi transformate în agenți inteligenți pe lanț, desfășurați în diverse scenarii și cazuri de utilizare.
Parteneri în ecosistem: @OpenLedger colaborează cu jucători de top din domeniul calculului, infrastructurii, instrumentelor și aplicațiilor AI:
Calcul & Găzduire: Aethir, Ionet, 0G
Infrastructura Rollup: AltLayer, Etherfi, EigenLayer AVS
Instrumente & Interoperabilitate: Ambios, Kernel, Web3Auth, Intract
Agenți AI & Constructori de modele: Giza, Gaib, Exabits, FractionAI, Mira, NetMind
Momenți de marcă prin summituri globale: În ultimul an, @OpenLedger a găzduit Summituri DeAI la evenimente Web3 majore, inclusiv Token2049 Singapore, Devcon Thailand, Consensus Hong Kong și ETH Denver. Aceste întâlniri au avut speakeri și proiecte de top în AI descentralizat. Ca unul dintre puținele echipe de nivel infra care organizează constant evenimente de înaltă calitate în industrie, @OpenLedger a crescut semnificativ vizibilitatea și capitalul său de marcă în cadrul comunității dezvoltatorilor și al ecosistemului Crypto AI mai larg—stabilind o bază solidă pentru atracția viitoare și efectele rețelei.
5. Finanțare și fundalul echipei
@OpenLedger a finalizat o rundă de seed de 11.2 milioane de dolari în iulie 2024, susținută de Polychain Capital, Borderless Capital, Finality Capital, Hashkey, îngeri proeminenți printre care Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda), Trevor. Fondurile vor fi utilizate în principal pentru a avansa dezvoltarea rețelei sale AI Chain, inclusiv mecanismele de stimulare a modelului, infrastructura de date și desfășurarea mai largă a ecosistemului său de aplicații pentru agenți.@OpenLedger 's AI Chain network, including its model incentivization mechanisms, data infrastructure, and the broader rollout of its agent application ecosystem.
@OpenLedger Openledger a fost fondat de Ram Kumar, Contribuitor principal la @OpenLedger OpenLedger, care este un antreprenor din San Francisco cu o bază solidă în tehnologiile AI/ML și blockchain. El aduce o combinație de cunoștințe de piață, expertiză tehnică și leadership strategic proiectului. Ram a co-conducătorat anterior o companie de R&D în blockchain și AI/ML cu peste 35 de milioane de dolari în venituri anuale și a jucat un rol cheie în dezvoltarea parteneriatelor de înalt impact, inclusiv o joint venture strategică cu o subsidiară Walmart. Lucrările sale se concentrează pe dezvoltarea ecosistemului și construirea de alianțe care să conducă la adoptarea în lumea reală în diverse industrii.
6. Tokenomics și Guvernare
$OPEN este tokenul utilitar nativ al ecosistemului @OpenLedger . Acesta susține guvernarea platformei, procesarea tranzacțiilor, distribuția stimulentelor și operațiunile Agentului AI—formând fundația economică pentru circulația sustenabilă pe lanț a modelelor AI și a activelor de date. Deși cadrul tokenomic rămâne în stadii incipiente și este supus perfecționării, @OpenLedger se apropie de Evenimentul său de Generare a Token-urilor (TGE) în mijlocul unei atracții în creștere în Asia, Europa și Orientul Mijlociu.
Utilitățile cheie ale $OPEN includ:
Guvernare & Luarea deciziilor:
Deținătorii OPEN pot vota asupra aspectelor critice, cum ar fi finanțarea modelului, gestionarea agenților, actualizările protocolului și alocarea trezoreriei.Token de gaz & Plăți pentru taxe: OPEN servește ca token nativ de gaz pentru @OpenLedger L2, permițând modele de taxe personalizabile native AI și reducând dependența de ETH.
Stimulente bazate pe atribuire:
Dezvoltatorii care contribuie cu seturi de date, modele sau servicii agent la standarde înalte sunt recompensați în OPEN pe baza utilizării și impactului efectiv.Bridging între lanțuri:
OPEN sprijină interoperabilitatea între @OpenLedger L2 și Ethereum L1, îmbunătățind portabilitatea și compunerea modelelor și agenților.Staking pentru agenți AI:
Operarea unui agent AI necesită staking OPEN. Agenții subperformanți sau malițioși riscă să fie penalizați, stimulând astfel livrarea de servicii de înaltă calitate și fiabile.
Spre deosebire de multe modele de guvernare care leagă influența strict de deținerile de tokeni, @OpenLedger introduce un sistem de guvernare bazat pe merit în care puterea de vot este legată de crearea valorii. Acest design prioritizează contribuabilii care construiesc, rafinează sau utilizează activ modele și seturi de date, mai degrabă decât deținătorii pasivi de capital. Procedând astfel, @OpenLedger asigură sustenabilitatea pe termen lung și protejează împotriva controlului speculativ—rămânând aliniat cu viziunea sa de economie AI transparentă, echitabilă și condusă de comunitate.
7. Peisajul pieței și analiza competitivă
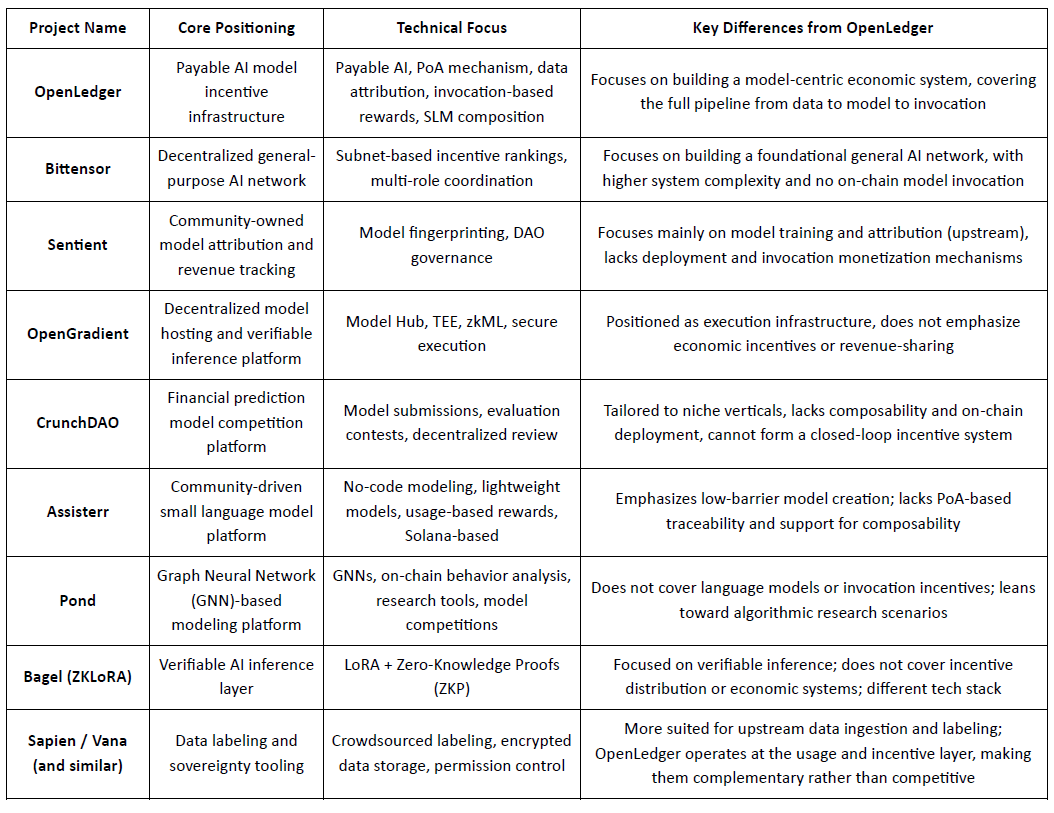
@OpenLedger , poziționat ca o infrastructură de stimulare a modelului "Payable AI", își propune să ofere căi de realizare a valorii verificabile, atribuite și sustenabile atât pentru contribuabilii de date, cât și pentru dezvoltatorii de modele. Centrându-se pe desfășurarea pe lanț, stimulentele bazate pe utilizare și compunerea modulară a agenților, a construit o arhitectură de sistem distinctă care se evidențiază în sectorul Crypto AI. Deși niciun proiect existent nu replică complet cadrul său de la un capăt la altul, acesta arată o comparabilitate puternică și potențial de sinergie cu mai multe protocoale reprezentative în domenii precum mecanismele de stimulare, monetizarea modelului și atribuirea datelor.
Stratul de stimulare: OpenLedger vs. Bittensor
Bittensor este una dintre cele mai reprezentative rețele AI descentralizate, operând un sistem colaborativ multi-rol condus de subrețele și scoruri de reputație, cu tokenul său $TAO stimulând participarea modelului, datelor și nodurilor de clasificare. În contrast, @OpenLedger se concentrează pe împărțirea veniturilor prin desfășurare pe lanț și invocarea modelului, punând accent pe infrastructura ușoară și coordonarea bazată pe agenți. Deși ambele împărtășesc un teren comun în logica stimulentelor, ele diferă în complexitatea sistemului și stratul ecosistemului: Bittensor își propune să fie stratul de bază pentru capacitatea AI generalizată, în timp ce @OpenLedger servește ca un strat de realizare a valorii la nivelul aplicației.
Proprietatea modelului și stimulentele de invocare: OpenLedger vs. Sentient
Sentient introduce conceptul "OML (Open, Monetizable, Loyal) AI", subliniind modelele deținute de comunitate cu identitate unică și urmărirea veniturilor prin Model Fingerprinting. În timp ce ambele proiecte pledează pentru recunoașterea contribuitorilor, Sentient se concentrează mai mult pe etapele de antrenare și creare a modelelor, în timp ce @OpenLedger se concentrează pe desfășurare, invocare și împărțirea veniturilor. Aceasta face ca cele două să fie complementare în diferite etape ale lanțului valoric AI—Sentient la amonte, @OpenLedger la aval.
Găzduirea modelului & Execuția verificabilă: OpenLedger vs. OpenGradient
OpenGradient se concentrează pe construirea unei infrastructuri de inferență securizată folosind TEE și zkML, oferind găzduire descentralizată pentru modele și execuție de încredere. @OpenLedger pe de altă parte, este construit în jurul ciclului de monetizare post-desfășurare, combinând Model Factory, OpenLoRA, PoA și Datanets într-un ciclu complet "antrenează–desfășoară–invocă–câștigă". Cele două operează în straturi diferite ale ciclului de viață al modelului—OpenGradient pe integritatea execuției, @OpenLedger pe stimularea economică și compunerea—cu un potențial clar de sinergie.
Modele Crowdsourced & Evaluare: OpenLedger vs. CrunchDAO
CrunchDAO se concentrează pe competiții de predicție descentralizate în finanțe, recompensând comunitățile pe baza performanței modelului trimis. Deși se potrivește bine în aplicații verticale, îi lipsesc capabilitățile de compunere a modelului și desfășurarea pe lanț. @OpenLedger oferă un cadru de desfășurare unificat și o fabrică de modele compusă, cu o aplicabilitate mai largă și mecanisme de monetizare native—făcând ca ambele platforme să fie complementare în structurile lor de stimulare.
Modele ușoare conduse de comunitate: OpenLedger vs. Assisterr
Assisterr, construit pe Solana, încurajează crearea de modele lingvistice mici (SLM-uri) prin instrumente fără cod și un sistem de recompensă bazat pe utilizarea $sASRR. În contrast, @OpenLedger pune un accent mai mare pe atribuirea trasabilă și buclele de venituri între straturile de date, model și invocare, utilizând mecanismul său PoA pentru distribuția stimulentelor de finețe. Assisterr este mai bine adaptat pentru colaborarea comunității cu barieră joasă, în timp ce @OpenLedger vizează infrastructura de model reutilizabilă și compusă.
Fabrica de Model: OpenLedger vs. Pond
Deși atât @OpenLedger cât și Pond oferă module "Fabrica de Model", utilizatorii lor țintiți și filozofiile de design diferă semnificativ. Pond se concentrează pe modelarea bazată pe rețele neuronale grafice (GNN) pentru a analiza comportamentul pe lanț, adresându-se oamenilor de știință ai datelor și cercetătorilor algoritmici printr-un model de dezvoltare bazat pe competiție. În contrast, OpenLedger oferă instrumente de ajustare fină ușoare bazate pe modele de limbaj (de exemplu, LLaMA, Mistral), concepute pentru dezvoltatori și utilizatori non-tehnici cu o interfață fără cod. Pune accent pe fluxurile de stimulente automatizate pe lanț și integrarea colaborativă a datelor-model, având ca scop construirea unei rețele de valoare AI bazate pe date.
Calea de Inferență Verificabilă: OpenLedger vs. Bagel
Bagel introduce ZKLoRA, un cadru pentru inferența criptografic verificabilă folosind modele ajustate LoRA și dovezi zero-knowledge (ZKP) pentru a asigura corectitudinea execuției off-chain. Între timp, @OpenLedger utilizează ajustarea fină LoRA cu OpenLoRA pentru a permite desfășurarea scalabilă și invocarea dinamică a modelului. @OpenLedger de asemenea, abordează inferența verificabilă dintr-o perspectivă diferită—prin atașarea dovezii de atribuire fiecărei ieșiri a modelului, explicând care date au contribuit la inferență și cum. Aceasta sporește transparența, recompensează cei mai buni contribuabili de date și construiește încredere în procesul de decizie. În timp ce Bagel se concentrează pe integritatea calculului, OpenLedger aduce responsabilitate și explicabilitate prin atribuire.
Calea de Colaborare a Datelor: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien și FractionAI se concentrează pe etichetarea descentralizată a datelor, în timp ce Vana și Irys se specializează în proprietatea și suveranitatea datelor. @OpenLedger , prin modulele sale Datanets + PoA, urmărește utilizarea datelor de înaltă calitate și distribuie stimulente pe lanț în consecință. Aceste platforme servesc diferite straturi ale lanțului valoric de date—etichetarea și gestionarea drepturilor la amonte, monetizarea și atribuirea la aval—făcându-le natural colaborative în loc de competitive.
În rezumat, OpenLedger ocupă o poziție de strat mediu în ecosistemul Crypto AI actual ca un protocol de legătură pentru assetizarea modelului pe lanț și invocarea pe bază de stimulente. Acesta leagă rețelele de antrenare la amonte și platformele de date cu straturile Agent de la aval și aplicațiile utilizatorilor finali—devenind o infrastructură critică care leagă oferta de valoare a modelului cu utilizarea în lumea reală.
8. Concluzie | De la date la modele—Să lase AI să câștige și el
@OpenLedger își propune să construiască o infrastructură "model-ca-actif" pentru lumea Web3. Prin crearea unui ciclu complet de desfășurare pe lanț, stimulente de utilizare, atribuirea proprietății și compunerea agentului, aduce modelele AI într-un sistem economic cu adevărat trasabil, monetizabil și colaborativ pentru prima dată.
Stiva tehnică—compusă din Model Factory, OpenLoRA, PoA și Datanets—oferă:
instrumente de antrenament cu barieră joasă pentru dezvoltatori,
atribuiție echitabilă a veniturilor pentru contribuabilii de date,
invocarea modelului compus și mecanismele de împărțire a recompenselor pentru aplicații.
Aceasta activează cuprinzător capetele de mult timp neglijate ale lanțului valoric AI: datele și modelele.
Mai degrabă decât a fi doar o altă versiune Web3 a HuggingFace, @OpenLedger seamănă mai mult cu un hibrid între HuggingFace + Stripe + Infura, oferind găzduire pentru modele, facturare bazată pe utilizare și acces API programabil pe lanț. Pe măsură ce tendințele de assetizare a datelor, autonomia modelului și modularizarea agentului accelerează, OpenLedger este bine poziționat pentru a deveni un lanț AI central sub paradigma "Payable AI".