I. Introducere | Saltul nivelului modelului în Crypto AI
Datele, modelele și puterea de calcul sunt cele trei elemente esențiale ale infrastructurii AI, asemănătoare combustibilului (date), motorului (modele) și energiei (puterea de calcul), fiecare fiind indispensabil. Similar cu calea de evoluție a infrastructurii din industria AI tradițională, domeniul Crypto AI a trecut și el prin etape similare. La începutul anului 2024, piața a fost dominată de proiecte GPU descentralizate (Akash, Render, io.net etc.), care au subliniat în mod general logica de creștere brută a „puterii de calcul”. Odată ce am intrat în 2025, punctele de interes ale industriei s-au ridicat treptat la nivelul modelului și al datelor, marcând tranziția Crypto AI de la competiția pentru resursele de bază la o construcție de nivel mediu, mai durabilă și cu valoare aplicativă.
Modele mari generale (LLM) vs. modele specializate (SLM)
Modelele de limbaj tradiționale (LLM) depind foarte mult de seturi mari de date și arhitecturi distribuite complexe, dimensiunea parametrilor variind de la 70B la 500B, iar costul unei sesiuni de antrenament ajunge adesea la milioane de dolari. În schimb, SLM (Model de Limbaj Specializat) este un tip de paradigmă de ajustare ușoară bazată pe un model de bază reutilizabil, care se bazează în general pe modele open-source precum LLaMA, Mistral, DeepSeek etc., combinând un număr mic de date profesionale de înaltă calitate și tehnici precum LoRA pentru a construi rapid modele de experți cu cunoștințe specifice domeniului, reducând semnificativ costurile de antrenament și pragurile tehnice.
Este de menționat că SLM-ul nu va fi integrat în greutățile LLM, ci va colabora cu LLM-ul prin arhitectura Agent, rutare dinamică prin sistemul de pluginuri, conectarea la modulele LoRA și RAG (Generare Augmentată prin Recuperare). Această arhitectură păstrează capacitatea de acoperire largă a LLM-ului, iar modulele de ajustare îmbunătățesc performanța profesională, formând un sistem inteligent extrem de flexibil și combinabil.
Crypto AI în valoarea și limitele modelului
Proiectele Crypto AI sunt în esență greu de îmbunătățit direct capacitățile de bază ale modelelor de limbaj (LLM), motivul principal fiind
Pragurile tehnice sunt prea ridicate: volumul de date, resursele de calcul și capacitățile ingineriei necesare pentru antrenarea Modelului de Bază sunt extrem de mari, în prezent doar gigantii tehnologici din SUA (OpenAI etc.) și China (DeepSeek etc.) dispun de capacitățile corespunzătoare.
Limitările ecosistemului open-source: deși modelele de bază de mainstream precum LLaMA și Mixtral au fost open-source, adevărata cheie pentru a impulsiona avansul modelului rămâne concentrată în instituțiile de cercetare și sistemele de inginerie closed-source, proiectele de pe lanț au o participare limitată la nivelul modelului de bază.
Cu toate acestea, pe baza modelelor de bază open-source, proiectele Crypto AI pot extinde valoarea prin ajustarea modelelor de limbaj specializate (SLM), combinând verificabilitatea și mecanismele de stimulente ale Web3. Ca "strat de interfață" în lanțul de producție AI, acest lucru se reflectă în două direcții cheie:
Stratul de verificare de încredere: prin înregistrarea pe lanț a traseelor de generare a modelului, contribuția datelor și utilizarea, se îmbunătățește trasabilitatea și rezistența la manipulare a outputului AI.
Mecanismul de stimulente: folosind tokenul nativ pentru a stimula comportamente precum încărcarea datelor, apelarea modelului, executarea agenților (Agent), construind un ciclu pozitiv de antrenare și servicii pentru model.
Clasificarea tipurilor de modele AI și analiza aplicabilității blockchainului

Astfel, este evident că punctele de plecare fezabile ale proiectelor de tip Crypto AI concentrate pe modele sunt în principal în ajustarea ușoară a SLM-urilor mici, accesul și validarea datelor pe lanț în arhitectura RAG, precum și desfășurarea și stimularea modelelor Edge. Combinând verificabilitatea blockchainului și mecanismele tokenurilor, Crypto poate oferi o valoare unică pentru aceste scenarii cu resurse medii și scăzute, formând o valoare diferențiată a "stratului de interfață AI".
Blockchain AI Chain bazat pe date și modele poate înregistra clar și irevocabil sursa contribuției fiecărei date și model, crescând semnificativ credibilitatea datelor și trasabilitatea antrenării modelului. În același timp, prin mecanismele de contract inteligent, recompensele sunt distribuite automat în momentul apelării datelor sau modelului, transformând comportamentele AI în valori tokenizate măsurabile și tranzacționabile, construind un sistem de stimulente sustenabil. În plus, utilizatorii comunității pot evalua performanța modelului prin voturi tokenizate, participa la formularea regulilor și iterații, îmbunătățind structura de guvernare descentralizată.
Doi, prezentarea proiectului | Viziunea lanțului AI OpenLedger
@OpenLedger este unul dintre puținele proiecte AI blockchain care se concentrează pe mecanismele de stimulare a datelor și modelelor de pe piață. A propus pentru prima dată conceptul de "AI plătibil", având scopul de a construi un mediu de operare AI corect, transparent și combinabil, stimulând colaborarea între contribuabilii de date, dezvoltatorii de modele și constructorii de aplicații AI pe aceeași platformă, și obținând venituri pe lanț în funcție de contribuția reală.
@OpenLedger oferă un ciclu complet de la "furnizarea datelor" la "desfășurarea modelului" și apoi "distribuția profitului", modulele sale de bază includ:
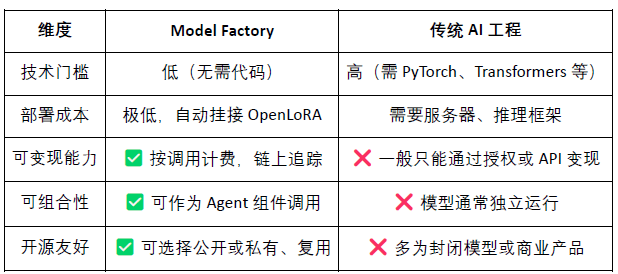
Fabrica de modele: fără programare, se poate folosi LoRA pentru antrenamentul și desfășurarea modelului personalizat bazat pe LLM open-source;
OpenLoRA: susține coexistența a mii de modele, cu încărcare dinamică pe cerere, reducând semnificativ costurile desfășurării;
PoA (Dovada Atribuirii): prin înregistrările apelurilor pe lanț se realizează măsurarea contribuției și distribuirea recompenselor;
Datanets: rețea de date structurată pentru scenarii verticale, construită și validată prin colaborarea comunității;
Platforma de propuneri pentru modele: piața de modele combinabile, apelabile și plătibile pe lanț.
Prin aceste module, @OpenLedger a construit o infrastructură de economie a agenților "inteligentă și bazată pe date", promovând lanțul valorii AI.
În ceea ce privește adoptarea tehnologiei blockchain, @OpenLedger folosește OP Stack + EigenDA ca fundament, construind un mediu de date și contracte de înaltă performanță, cu costuri reduse și verificabilitate pentru modelele AI.
Construit pe OP Stack: bazat pe tehnologia Optimism, susține execuția cu un throughput ridicat și costuri reduse;
Decontare pe rețeaua principală Ethereum: asigurând securitatea tranzacțiilor și integritatea activelor;
Compatibilitate EVM: facilitează desfășurarea și extinderea rapidă a dezvoltatorilor bazate pe Solidity;
EigenDA oferă suport pentru disponibilitatea datelor: reducând semnificativ costurile de stocare, asigurând verificabilitatea datelor.
Comparativ cu NEAR, care este mai orientat spre infrastructură, având ca scop suveranitatea datelor și arhitectura "AI Agents on BOS", @OpenLedger se concentrează mai mult pe construirea unei lanțuri dedicate AI pentru stimulentele datelor și modelelor, având ca scop realizarea dezvoltării și apelării modelului pe lanț, asigurând trasabilitatea, combinabilitatea și sustenabilitatea valorii. Este infrastructura de stimulente pentru modele în lumea Web3, combinând găzduirea de tip HuggingFace, tarifarea utilizării de tip Stripe și interfețele combinate pe lanț de tip Infura, promovând realizarea "modelului ca activ".
Trei, componentele și arhitectura tehnică de bază ale OpenLedger
3.1 Fabrica de modele, fără cod pentru model factory
ModelFactory este @OpenLedger o platformă de ajustare a modelului de limbaj (LLM) de mari dimensiuni. Spre deosebire de cadrele tradiționale de ajustare, ModelFactory oferă o interfață pur grafică, fără a necesita instrumente de linie de comandă sau integrarea API. Utilizatorii pot ajusta modelele pe baza seturilor de date autorizate și revizuite completate pe @OpenLedger . A realizat un flux de lucru integrat pentru autorizarea datelor, antrenarea modelului și desfășurarea acestuia, procesul său principal incluzând:
Controlul accesului la date: utilizatorii trimite cereri de date, furnizorii le aprobat, iar datele sunt integrate automat în interfața de antrenare a modelului.
Selectarea și configurarea modelului: suport pentru LLM-uri principale (de exemplu, LLaMA, Mistral), configurare a hiperparametrilor prin GUI.
Ajustare ușoară: motorul LoRA / QLoRA integrat, afișând în timp real progresul antrenării.
Evaluarea modelului și desfășurarea: instrumente de evaluare integrate, suport pentru exportul desfășurării sau apelurilor partajate în ecosistem.
Interfața de verificare interactivă: oferă o interfață de tip chat, facilitând testarea directă a capacității de răspuns a modelului.
RAG generare de trasabilitate: răspunsurile includ referințe de sursă, sporind încrederea și auditabilitatea.
Arhitectura sistemului Model Factory include șase module, acoperind autentificarea identității, permisiunile datelor, ajustarea modelului, evaluarea desfășurării și trasabilitatea RAG, construind o platformă de servicii pentru model integrată, sigură, controlabilă, interactivă în timp real și capabilă de monetizare sustenabilă.
Tabelul de abilități al modelelor de limbaj mari susținute de ModelFactory este următorul:
Seria LLaMA: cel mai larg ecosistem, comunitate activă, performanță generală puternică, fiind unul dintre cele mai populare modele de bază open-source.
Mistral: arhitectură eficientă, performanță excelentă în raționare, potrivită pentru desfășurări flexibile și resurse limitate.
Qwen: produs de Alibaba, performanțele în sarcini în limba chineză sunt excelente, având abilități generale puternice, fiind alegerea principală pentru dezvoltatorii din țară.
ChatGLM: rezultate de conversație excelente în limba chineză, potrivit pentru servicii clienți de nișă și scenarii localizate.
Deepseek: performanțe superioare în generarea codului și raționarea matematică, potrivit pentru instrumentele de asistență pentru dezvoltare inteligentă.
Gemma: model ușor lansat de Google, structură clară, ușor de utilizat și de experimentat rapid.
Falcon: a fost un reper de performanță, potrivit pentru cercetări fundamentale sau teste comparative, dar activitatea comunității a scăzut.
BLOOM: suport multilingv puternic, dar performanța în raționare este slabă, potrivit pentru cercetări cu acoperire lingvistică.
GPT-2: model clasic din prima generație, adecvat doar pentru scopuri didactice și de verificare, nu este recomandat pentru utilizare efectivă.
Deși @OpenLedger combinațiile de modele nu includ cele mai recente modele MoE de performanță înaltă sau modele multimodale, strategia sa nu este depășită, ci este o configurație „prioritate practică” bazată pe constrângerile reale ale desfășurării pe lanț (costurile de raționament, adaptarea RAG, compatibilitatea LoRA, mediul EVM).
Fabrica de modele, ca instrument fără cod, are integrat un mecanism de dovadă a contribuției, asigurându-se că drepturile contribuabililor de date și dezvoltatorilor de modele sunt protejate, având avantajele de prag scăzut, monetizare și combinabilitate, comparativ cu instrumentele tradiționale de dezvoltare a modelului:
Pentru dezvoltatori: oferă un parcurs complet pentru incubarea, distribuția și venitul modelului;
Pentru platformă: formează o circulație a activelor modelului și un ecosistem de combinații;
Pentru utilizatori: pot combina modelele sau agenții la fel ca apelurile API.
3.2 OpenLoRA, activarea pe lanț a modelului ajustat
LoRA (Adaptarea de Rang Scăzut) este o metodă eficientă de ajustare a parametrilor, învățând sarcini noi prin inserarea de "matrice de rang scăzut" în modelele mari pre-antrenate, fără a modifica parametrii modelului original, reducând astfel semnificativ costurile de antrenare și cerințele de stocare. Modelele tradiționale de limbaj de mari dimensiuni (de exemplu, LLaMA, GPT-3) au de obicei zeci de miliarde sau chiar sute de miliarde de parametri. Pentru a le utiliza pentru sarcini specifice (de exemplu, întrebări legale, consultații medicale), este necesară ajustarea (fine-tuning). Strategia principală a LoRA este: "înghețarea parametrilor modelului mare original, antrenând doar matricele de parametri nou inserate.", având parametri eficienți, antrenament rapid și desfășurare flexibilă, fiind în prezent cea mai potrivită metodă de ajustare pentru desfășurarea și apelul combinat al modelului Web3.
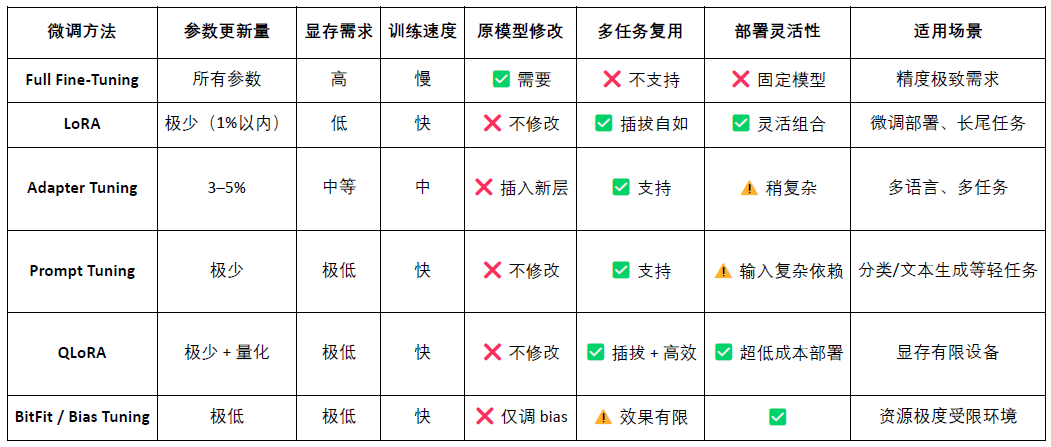
OpenLoRA este @OpenLedger un cadru ușor de desfășurare, construit special pentru desfășurarea și partajarea resurselor mai multor modele. Obiectivul său principal este de a rezolva problemele comune ale desfășurării modelelor AI, cum ar fi costurile ridicate, reutilizarea scăzută și risipa de resurse GPU, promovând implementarea "AI-ului plătibil".
Componentele de bază ale arhitecturii sistemului OpenLoRA, bazate pe un design modular, acoperă modelul de stocare, execuția raționării, rutarea cererilor și alte etape cheie, realizând capacități eficiente și cu costuri reduse pentru desfășurarea și apelul mai multor modele:
Modulul de stocare LoRA Adapter (LoRA Adapters Storage): adaptoarele LoRA ajustate sunt găzduite pe @OpenLedger , realizând încărcarea la cerere, evitând încărcarea tuturor modelelor în prealabil în memorie, economisind resurse.
Stratul de găzduire a modelului și fuziunea dinamică (Model Hosting & Adapter Merging Layer): toate modelele ajustate împărtășesc modelul de bază (base model), iar în timpul raționării adaptoarele LoRA sunt combinate dinamic, susținând raționarea combinată a mai multor adaptoare (ensemble), îmbunătățind performanța.
Motorul de raționare (Inference Engine): integrează mai multe tehnici de optimizare CUDA precum Flash-Attention, Paged-Attention, SGMV etc.
Modulul de rutare a cererilor și output în flux (Request Router & Token Streaming): rotează dinamic către adaptorul corect în funcție de modelul necesar din cerere, realizând generarea în flux la nivel de token prin optimizarea nucleului.
Fluxul de raționament al OpenLoRA aparține procesului de "servicii de model mature și generale" din punct de vedere tehnic, după cum urmează:
Încărcarea modelului de bază: sistemul preîncarcă modele mari de bază precum LLaMA 3, Mistral etc. în memoria GPU.
Recuperare dinamică LoRA: la primirea cererii, se încarcă dinamic adaptorul LoRA specificat din Hugging Face, Predibase sau dintr-un director local.
Activarea fuziunii adaptorilor: prin optimizarea nucleului, adaptorul este combinat în timp real cu modelul de bază, susținând raționarea combinată a mai multor adaptoare.
Execuția raționării și outputul în flux: modelul combinat începe să genereze răspunsuri, folosind output în flux la nivel de token pentru a reduce latența, combinând cuantizarea pentru a asigura eficiența și precizia.
Sfârșitul raționării și eliberarea resurselor: după finalizarea raționării, adaptorul este descărcat automat, eliberând resursele de memorie. Asigură rotirea eficientă pe un singur GPU și servirea a mii de modele ajustate, susținând rotirea eficientă a modelelor.
OpenLoRA a îmbunătățit semnificativ eficiența desfășurării și raționării mai multor modele printr-o serie de metode de optimizare de bază. Acestea includ încărcarea dinamică a adaptoarelor LoRA (încărcare JIT), reducând eficient utilizarea memoriei; paralele tensoriale (Tensor Parallelism) și atenția paginată (Paged Attention) pentru a realiza o procesare concurentă și pentru texte lungi; suport pentru fuziunea mai multor modele (Multi-Adapter Merging) pentru a permite execuția combinată a LoRA; în același timp, prin atenția Flash, nucleele CUDA precompilate și tehnicile de cuantizare FP8/INT8, se îmbunătățește suportul pentru optimizarea și cuantizarea CUDA de bază, sporind viteza raționării și reducând latența. Aceste optimizări permit OpenLoRA să servească eficient mii de modele ajustate într-un mediu cu un singur GPU, echilibrând performanța, scalabilitatea și utilizarea resurselor.
OpenLoRA nu este doar un cadru eficient de raționare LoRA, ci și un sistem care îmbină profund raționarea modelului cu mecanismele de stimulente Web3, având ca scop transformarea modelelor LoRA în active Web3 care pot fi apelate, combinate și care pot distribui profit.
Modelul ca activ (Model-as-Asset): OpenLoRA nu este doar un model de desfășurare, ci oferă fiecărui model ajustat o identitate pe lanț (Model ID) și le leagă comportamentul de apel și stimulentele economice, realizând "apelul înseamnă distribuția profitului".
Combinare dinamică a mai multor LoRA + atribuirea profitului: Susține apelurile dinamice pentru combinații de mai multe adaptoare LoRA, permițând diferitelor combinații de modele să formeze noi servicii Agent, în timp ce sistemul poate distribui cu precizie profitul pentru fiecare adaptor pe baza volumului de apeluri conform mecanismului PoA (Dovada Atribuirii).
Susținerea înțelepciunii lungi a modelului "împărțit în mai multe chirii": prin încărcarea dinamică și mecanismele de eliberare a memoriei, OpenLoRA poate servi mii de modele LoRA într-un mediu cu un singur GPU, fiind deosebit de potrivit pentru modelele de nișă din Web3, asistenții AI personalizați și alte scenarii de apeluri frecvente și cu reutilizare ridicată.

În plus, @OpenLedger a publicat viziunea sa asupra indicatorilor de performanță OpenLoRA, comparativ cu desfășurarea tradițională a modelului cu parametrii compleți, utilizarea memoriei a fost redusă semnificativ la 8–12 GB; timpul de comutare a modelului poate teoretic fi sub 100 ms; capacitatea de procesare poate ajunge la 2000+ tokens/sec; controlul întârzierii se menține în intervalul 20–50 ms. În general, acești indicatori de performanță sunt tehnic realizabili, dar sunt mai aproape de "performanța limită", iar în medii de producție reale, performanța poate fi afectată de hardware, strategii de programare și complexitatea scenariului, trebuind considerată "limită ideală" și nu "stabilă zilnic".
3.3 Datanets (rețeaua de date), de la suveranitatea datelor la inteligența datelor
Datele de înaltă calitate și specifice domeniului devin elemente cheie pentru construirea unor modele de performanță înaltă. Datanets este @OpenLedger infrastructura "date ca activ", utilizată pentru colectarea și gestionarea seturilor de date specifice domeniului, pentru agregarea, validarea și distribuția datelor specifice domeniului printr-o rețea descentralizată, oferind surse de date de înaltă calitate pentru antrenarea și ajustarea modelelor AI. Fiecare Datanet este ca un depozit de date structurat, în care contribuabilii încarcă date, asigurând trasabilitatea și credibilitatea acestora prin mecanismele de atribuire pe lanț, și prin stimulentele și controlul transparent al permisiunilor, Datanets realizează co-crearea și utilizarea de încredere a datelor necesare pentru antrenarea modelului.
Comparativ cu proiecte precum Vana, care se concentrează pe suveranitatea datelor, @OpenLedger nu se limitează doar la "colectarea datelor", ci prin Datanets (etichete colaborative și seturi de date de atribuire), Model Factory (instrumente de antrenare a modelului fără cod) și OpenLoRA (adaptoare de model urmărite, combinate) extinde valoarea datelor la antrenarea modelului și apelurile pe lanț, construind un ciclu complet de "de la date la inteligență". Vana subliniază "cine deține datele", în timp ce @OpenLedger se concentrează pe "cum sunt antrenate, apelate și recompensate datele", ocupând poziții cheie în asigurarea suveranității datelor și în calea de monetizare a datelor în ecosistemul Web3 AI.
3.4 Dovada Atribuirii (contribuție): remodelarea nivelului de stimulente pentru distribuția beneficiilor
Dovada atribuirii (PoA) este @OpenLedger mecanismul central prin care se realizează atribuirea datelor și distribuția stimulentelor, prin înregistrări criptografice pe lanț, stabilind o asociere verificabilă între fiecare set de date de antrenament și rezultatul modelului, asigurându-se că contribuitorii primesc recompensa cuvenită în apelurile modelului. Procesul de atribuire a datelor și stimulentele este următorul:
Submisia datelor: utilizatorii încarcă seturi de date structurate și specifice domeniului, iar acestea sunt înregistrate pe lanț.
Evaluarea impactului: sistemul evaluează valoarea acestora în funcție de caracteristicile datelor și reputația contribuabililor la fiecare raționare.
Validarea antrenamentului: jurnalele de antrenament înregistrează utilizarea reală a fiecărei date, asigurându-se că contribuția este verificabilă.
Distribuția stimulentelor: în funcție de influența datelor, contribuabilii primesc recompense Token legate de efect.
Guvernarea calității: penalizarea datelor de slabă calitate, redundante sau malițioase, pentru a asigura calitatea antrenării modelului.
Comparativ cu rețeaua de stimulente blockchain de tip Bittensor, care are un mecanism de evaluare bazat pe subrețele, @OpenLedger se concentrează pe captarea valorii și mecanismele de distribuire a profitului la nivelul modelului. PoA nu este doar un instrument de distribuire a stimulentelor, ci și un cadru destinat transparenței, urmăririi surselor și atribuției în mai multe etape: acesta înregistrează pe lanț întregul proces de încărcare a datelor, apelarea modelului și execuția agenților, realizând un parcurs de valoare verificabil de la cap la cap. Acest mecanism permite ca fiecare apel al modelului să fie trasabil la contribuabilii de date și dezvoltatorii de modele, astfel realizând o "consensualizare a valorii" și "venituri disponibile" în sistemul AI pe lanț.
RAG (Generare Augmentată prin Recuperare) este o arhitectură AI care combină sistemele de recuperare cu modelele generative, având ca scop rezolvarea problemelor legate de "cunoaștere închisă" și "creație falsă" ale modelelor de limbaj tradiționale, prin introducerea unor baze de date externe pentru a îmbunătăți capacitatea de generare a modelului, făcând outputul mai real, explicabil și verificabil. Atribuirea RAG este @OpenLedger mecanismul de atribuire a datelor și stimulentelor stabilit în scenariile de Generare Augmentată prin Recuperare (Retrieval-Augmented Generation), asigurându-se că conținutul generat de model este trasabil și verificabil, contribuabilii fiind recompensați, realizând în final credibilitatea generării și transparența datelor, procesul incluzând:
Întrebarea utilizatorului → Recuperarea datelor: AI primește întrebarea și caută conținutul relevant din indexul de date @OpenLedger .
Datele sunt apelate și generează răspunsuri: conținutul recuperat este utilizat pentru a genera răspunsurile modelului și comportamentul de apel este înregistrat pe lanț.
Contribuitorii primesc recompense: datele utilizate recompensează contribuabilii în funcție de suma și relevanța calculată.
Rezultatele generate includ referințe: outputul modelului vine cu linkuri către sursa originală a datelor, realizând răspunsuri transparente și conținut verificabil.

@OpenLedger atribuirea RAG oferă posibilitatea ca fiecare răspuns AI să fie trasabil la sursa reală a datelor, contribuabilii fiind recompensați în funcție de frecvența citării, realizând "cunoașterea are o sursă, apelul poate fi monetizat". Acest mecanism nu numai că îmbunătățește transparența outputului modelului, dar construiește și un ciclu de stimulente sustenabil pentru contribuțiile de date de calitate, fiind o infrastructură cheie pentru a promova AI de încredere și activarea datelor.
Patru, progresele proiectului OpenLedger și colaborarea ecologică
În prezent@OpenLedger a fost lansat pe rețeaua de testare, stratul de inteligență a datelor (Data Intelligence Layer) este@OpenLedger prima etapă a rețelei de testare, având scopul de a construi un depozit de date pe internet condus în comun de nodurile comunității. Aceste date sunt filtrate, îmbunătățite, clasificate și procesate în mod structurat, formând în cele din urmă inteligența auxiliară potrivită pentru modele de limbaj de mari dimensiuni (LLM), folosite pentru construirea@OpenLedger de modele AI pe domeniu. Membrii comunității pot rula noduri pe dispozitive periferice, participând la colectarea și procesarea datelor, nodurile vor folosi resursele de calcul locale pentru a executa sarcini legate de date, participanții obținând puncte de recompensă în funcție de activitate și finalizarea sarcinilor. Aceste puncte vor fi convertite în viitor în tokenuri OPEN, iar raportul de schimb specific va fi anunțat înainte de evenimentul de generare a tokenurilor (TGE).
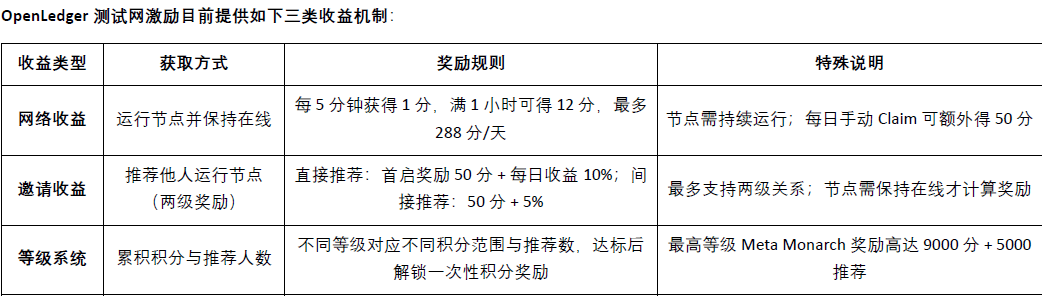
Epoch 2 a rețelei de testare concentrează pe introducerea mecanismului de rețea de date Datanets, această etapă fiind limitată la utilizatorii cu listă albă, care trebuie să finalizeze o evaluare preliminară pentru a debloca sarcinile. Sarcinile includ validarea datelor, clasificarea etc., iar după finalizare se obțin puncte în funcție de acuratețe și dificultate, stimulând contribuțiile de calitate prin clasamente. Site-ul oficial oferă în prezent modele de date care pot fi utilizate astfel:
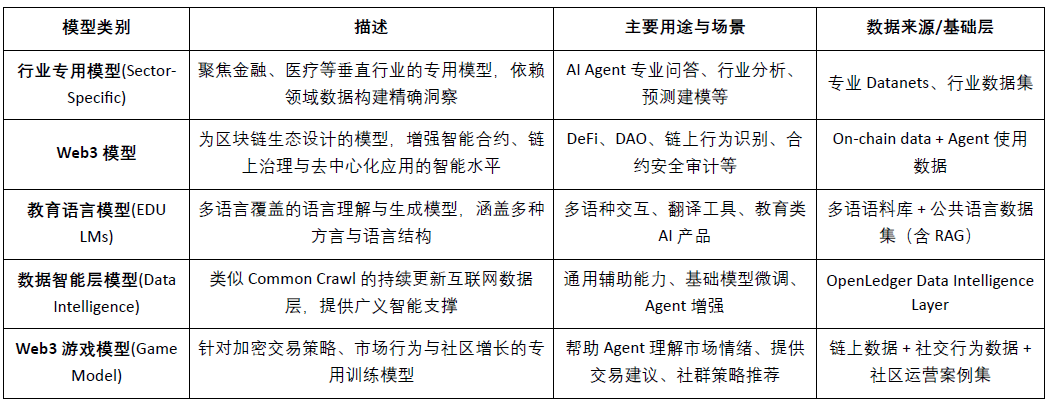
însă @OpenLedger are o planificare a foilor de parcurs pe termen lung, de la colectarea datelor și construirea modelului până la ecosistemul Agent, realizând treptat "date ca activ, model ca serviciu, Agent ca agent inteligent".
Faza 1 · Strat de inteligență a datelor (Data Intelligence Layer): comunitatea colectează și procesează datele de pe internet prin intermediul nodurilor periferice, construind un strat de inteligență a datelor de înaltă calitate, care se actualizează continuu.
Faza 2 · Contribuțiile comunității la date (Community Contributions): comunitatea participă la validarea și feedbackul datelor, construind împreună un set de date de aur (Golden Dataset) de încredere, oferind inputuri de calitate pentru antrenarea modelului.
Faza 3 · Construirea modelului și declarația de atribuire (Build Models & Claim): bazat pe datele de aur, utilizatorii pot antrena modele specializate și își pot revendica atribuirea, realizând activarea modelului și eliberarea valorii combinabile.
Faza 4 · Crearea agenților (Build Agents): bazându-se pe modelele publicate, comunitatea poate crea agenți personalizați (Agents), realizând desfășurări în multiple scenarii și evoluții continue.
@OpenLedger partenerii ecologici includ platforme de calcul, infrastructură, lanțuri de instrumente și aplicații AI. Partenerii săi includ Aethir, Ionet, 0G și alte platforme de calcul descentralizate, AltLayer, Etherfi și AVS de pe EigenLayer oferind suport pentru scalabilitate și decontare de bază; Ambios, Kernel, Web3Auth, Intract și alte instrumente oferind capacități de autentificare și integrare pentru dezvoltare; în domeniul modelelor AI și agenților, @OpenLedger colaborează cu Giza, Gaib, Exabits, FractionAI, Mira, NetMind și alte proiecte pentru a avansa desfășurarea modelelor și implementarea agenților, construind un ecosistem AI Web3 deschis, combinabil și sustenabil.
În ultimul an, #OpenLedger a organizat în mod constant summituri DeAI cu tematica Crypto AI în cadrul Token2049 Singapore, Devcon Thailand, Consensus Hong Kong și ETH Denver, invitând numeroase proiecte de bază și lideri tehnologici din domeniul AI descentralizat să participe. Ca unul dintre puținele proiecte capabile să planifice continuu evenimente de înaltă calitate în industrie, #OpenLedger a folosit summitul DeAI pentru a-și întări eficient recunoașterea de marcă și reputația profesională în comunitatea dezvoltatorilor și ecosistemul de antreprenoriat AI Web3, punând astfel o bază solidă pentru extinderea ecologică ulterioară și implementarea tehnologică.
Cinci, finanțare și fundalul echipei
@OpenLedger a finalizat o finanțare de seed round de 11.2 milioane de dolari în iulie 2024, investitorii incluzând Polychain Capital, Borderless Capital, Finality Capital, Hashkey, precum și mai mulți investitori angelici cunoscuți, precum Sreeram Kannan (EigenLayer), Balaji Srinivasan, Sandeep (Polygon), Kenny (Manta), Scott (Gitcoin), Ajit Tripathi (Chainyoda) și Trevor. Fondurile vor fi utilizate în principal pentru a avansa construcția rețelei AI Chain @OpenLedger , mecanismele de stimulare a modelului, infrastructura de date și ecosistemul aplicațiilor Agent.

@OpenLedger a fost fondată de Ram Kumar, un contributor de bază al #OpenLedger , fiind un antreprenor rezident în San Francisco, având un fundal tehnic solid în domeniile AI/ML și blockchain. El aduce o combinație organică de viziune de piață, expertiză tehnică și leadership strategic. Ram a condus anterior o companie de dezvoltare blockchain și AI/ML cu venituri anuale de peste 35 de milioane de dolari, jucând un rol important în promovarea colaborărilor cheie, inclusiv un proiect de joint venture strategic cu o subsidiară Walmart. El se concentrează pe construirea ecosistemului și colaborări de mare leverage, dedicându-se accelerării aplicațiilor realiste în diverse industrii.
Șase, proiectarea modelului economic al tokenului și guvernarea
$OPEN este tokenul funcțional central al ecologiei @OpenLedger , sprijină guvernarea rețelei, funcționarea tranzacțiilor, distribuția stimulentelor și operarea AI Agent, formând baza economică a circulației sustenabile a modelului AI și a datelor în lanț. În prezent, economiile de tokenuri oficial publicate se află în stadiul incipient de proiectare, detaliile nefiind complet clare, dar pe măsură ce proiectul se apropie de evenimentul de generare a tokenurilor (TGE), creșterea comunității, activitatea dezvoltatorilor și experimentele cu scenarii de aplicație continuă să progreseze rapid în Asia, Europa și Orientul Mijlociu.
Guvernare și decizii: deținătorii de Open pot participa la votul privind finanțarea modelelor, gestionarea agenților, actualizările protocolului și utilizarea fondurilor.
combustibilul de tranzacții și plata taxelor: ca token gaz nativ al rețelei @OpenLedger , susține un mecanism de rată personalizată nativ AI.
Stimulente și recompense de atribuire: dezvoltatorii care contribuie cu date, modele sau servicii de calitate pot primi distribuții Open în funcție de impactul utilizării.
capabilitățile de poduri între lanțuri: Open susține poduri L2 ↔ L1 (Ethereum), îmbunătățind utilizarea multiplă a modelului și agenților.
Mecanismul de stakare a agenților AI: funcționarea agenților AI necesită stakare $OPEN , iar performanța slabă va duce la o reducere a stakării, stimulând outputul de servicii eficiente și de încredere.
Spre deosebire de multe protocoale de guvernare a tokenurilor legate de influență și numărul de tokenuri, @OpenLedger a introdus un mecanism de guvernare bazat pe valoarea contribuției. Ponderea votului este legată de valoarea creată efectiv, și nu de ponderea capitalului, prioritizând împuternicirea celor care participă la construirea, optimizarea și utilizarea modelelor și seturilor de date. Această arhitectură ajută la asigurarea sustenabilității pe termen lung a guvernării, prevenind comportamentele de speculație care să domine deciziile, aliniindu-se cu viziunea sa de "transparență, corectitudine, comunitate" a economiei descentralizate AI.
Șapte, peisajul pieței de date, modele și stimulente, și comparația cu concurenții
@OpenLedger ca infrastructură de stimulente pentru modele "plătibile AI", dedicată furnizării de căi de monetizare sustenabile și verificabile pentru contribuabilii de date și dezvoltatorii de modele. Aceasta construiește un sistem modular cu caracteristici diferențiate în jurul desfășurării pe lanț, stimulentelor apelului și mecanismelor de combinare a agenților, având o poziție distinctă în actuala competiție Crypto AI. Deși nu există proiecte care să se suprapună complet în arhitectura generală, OpenLedger și mai multe proiecte reprezentative arată o comparabilitate și potențial de colaborare pe dimensiuni cheie precum stimulentele protocolului, economia modelului și drepturile asupra datelor.
Nivelul de stimulente pentru protocol: OpenLedger vs. Bittensor
Bittensor este în prezent cea mai reprezentativă rețea AI descentralizată, construind un sistem de colaborare multi-rol bazat pe subrețele (Subnet) și mecanisme de evaluare, stimulând participanții precum tokenul $TAO pentru modele, date și noduri de clasificare. Comparativ,@OpenLedger Concentrându-se pe desfășurarea pe lanț și distribuția profitului din apelurile modelului, subliniind arhitectura ușoară și mecanismele de colaborare ale agenților. Deși logica stimulentelor celor două se suprapune, nivelurile de obiective și complexitatea sistemului sunt clar diferite: Bittensor se concentrează pe rețeaua de capacitate AI generalizată,@OpenLedger Acesta se poziționează ca platformă de suport pentru aplicațiile AI.
Atribuția modelului și stimulentele apelului: OpenLedger vs. Sentient
Sentient a propus conceptul „OML (Open, Monetizable, Loyal) AI” în atribuirea modelului și proprietatea comunității în comparație cu@OpenLedger Unele idei sunt similare, punând accent pe realizarea identificării și urmăririi veniturilor prin Model Fingerprinting. Diferența constă în faptul că Sentient se concentrează mai mult pe antrenarea și generarea modelului, în timp ce@OpenLedger concentrându-se pe desfășurarea pe lanț a modelului, apelul și mecanismul de distribuire a profitului, cele două se află în amonte și aval în lanțul valorii AI, având o complementaritate naturală.
Platforma de găzduire a modelului și raționamentul de încredere: OpenLedger vs. OpenGradient
OpenGradient se concentrează pe construirea unui cadru de execuție sigur pentru raționamente pe baza TEE și zkML, oferind găzduire descentralizată pentru modele și servicii de raționament, concentrându-se pe mediile de operare de încredere de bază. În contrast,@OpenLedger se concentrează mai mult pe calea de captare a valorii după desfășurarea pe lanț, în jurul Model Factory, OpenLoRA, PoA și Datanets, construind un ciclu complet "antrenare – desfășurare – apel – distribuție a profitului". Cele două se află în cicluri de viață diferite ale modelului: OpenGradient se concentrează pe fiabilitate, OpenLedger pe stimulentele veniturilor și combinația ecologică, având un spațiu complementar ridicat.
Modele de crowdsourcing și stimulente de evaluare: OpenLedger vs. CrunchDAO
CrunchDAO se concentrează pe un mecanism descentralizat de competiție pentru modelele de predicție financiară, încurajând comunitatea să trimită modele și să obțină recompense pe baza performanței, fiind potrivit pentru anumite scenarii verticale. Comparativ,@OpenLedger Oferă un market de modele combinabile și un cadru de desfășurare unificat, având o versatilitate mai largă și capacitatea de a monetiza nativ pe lanț, potrivit pentru extinderea scenariilor de agenți inteligenți de diferite tipuri. Cele două se completează în logica stimulentelor modelului, având potențial de sinergie.
Platforma de modele ușoare conduse de comunitate: OpenLedger vs. Assisterr
Assisterr, construit pe Solana, încurajează comunitatea să creeze modele de limbaj mici (SLM) și să îmbunătățească frecvența utilizării prin instrumente fără cod și mecanisme de stimulare $sASRR. Comparativ,@OpenLedger se concentrează mai mult pe urmărirea și distribuția profitului închis în ciclul datelor-modele-apel, folosind PoA pentru a realiza o distribuție fină a stimulentelor. Assisterr este mai potrivit pentru comunități de colaborare a modelelor cu praguri scăzute,@OpenLedger dedicat construirii unei infrastructuri de model reutilizabilă și combinabilă.
Fabrica de modele: OpenLedger vs. Pond
Pond și@OpenLedger de asemenea, oferă modulul "Model Factory", dar poziționarea și obiectivele de servicii sunt semnificativ diferite. Pond se concentrează pe modelarea comportamentului pe lanț bazată pe rețele neuronale grafice (GNN), vizând în principal cercetătorii în algoritmi și oamenii de știință ai datelor, și stimulează dezvoltarea modelului prin mecanisme de competiție, fiind mai înclinat spre competiția modelului; OpenLedger, pe de altă parte, se bazează pe ajustarea modelului de limbaj (de exemplu, LLaMA, Mistral), servind dezvoltatorii și utilizatorii non-tehnici, punând accent pe experiența fără cod și mecanismele automate de distribuție pe lanț, construind un ecosistem de stimulente AI bazat pe date, OpenLedger fiind mai înclinat spre cooperarea pe date.
Calea raționării de încredere: OpenLedger vs. Bagel
Bagel a lansat cadrul ZKLoRA, utilizând modele de ajustare LoRA și tehnologia dovezilor zero-knowledge (ZKP) pentru a realiza verificabilitatea criptografică a procesului de raționare off-chain, asigurând corectitudinea execuției raționării. În schimb,@OpenLedger sprijină desfășurarea extensibilă și apelurile dinamice ale modelelor de ajustare LoRA prin OpenLoRA, rezolvând problema verificabilității raționării din perspective diferite - prin adăugarea dovezilor de atribuire (Proof of Attribution, PoA) la fiecare output al modelului, urmărind sursele de date pe care se bazează raționarea și influența acestora. Acest lucru nu doar că îmbunătățește transparența, ci oferă și recompense contribuabililor de date de calitate, sporind interpretabilitatea și încrederea în procesul de raționare. Pe scurt, Bagel se concentrează pe validarea corectitudinii rezultatelor de calcul, în timp ce@OpenLedger realizează urmărirea responsabilității și interpretabilitatea procesului de raționare prin mecanismele de atribuire.
Calea de colaborare pe partea de date: OpenLedger vs. Sapien / FractionAI / Vana / Irys
Sapien și FractionAI oferă servicii descentralizate de etichetare a datelor, Vana și Irys se concentrează pe suveranitatea datelor și mecanismele de atribuire.@OpenLedger prin Datanets + modulul PoA, se realizează urmărirea utilizării datelor de înaltă calitate și distribuția stimulentelor pe lanț. Primul poate acționa ca sursă de aprovizionare a datelor,@OpenLedger cel din urmă acționând ca un centru de distribuție a valorii și apelurilor, cele trei având o bună colaborare în lanțul valorii datelor, mai degrabă decât o relație de competiție.
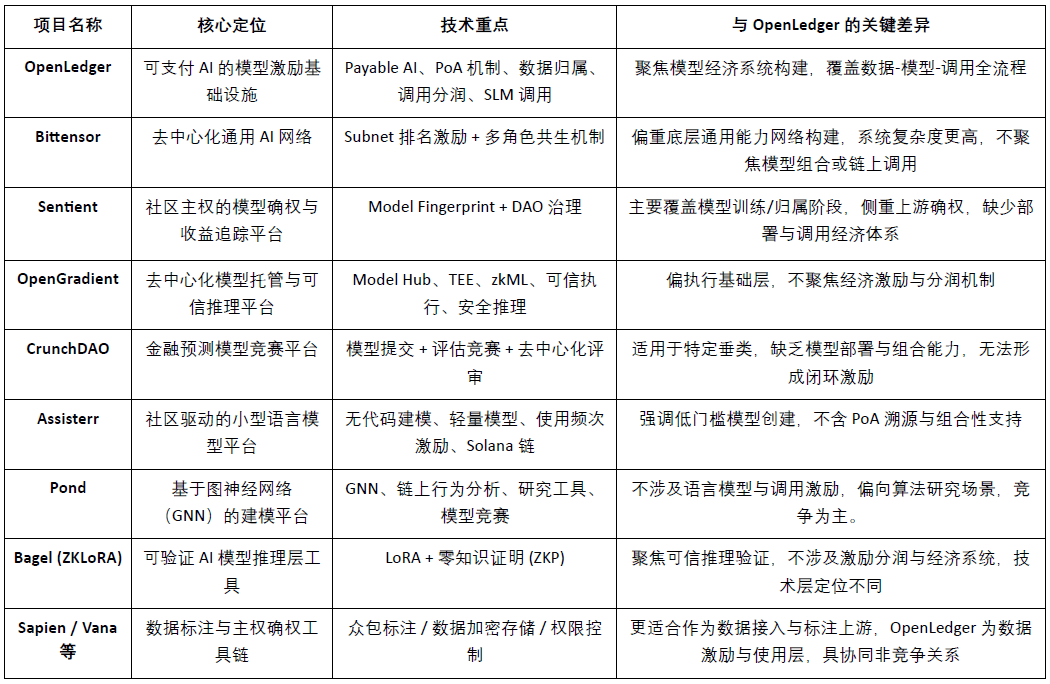
În concluzie, @OpenLedger ocupa o poziție intermediară în ecosistemul Crypto AI actual, având rolul de "activare și stimulare a modelului pe lanț", putând conecta rețelele de antrenament cu platformele de date, precum și să ofere servicii pentru nivelul Agent și aplicațiile finale, fiind un protocol cheie care leagă furnizarea valorii modelului de apelurile aplicate.
Opt, concluzie | De la date la model, calea de monetizare a lanțului AI
#OpenLedger se angajează să construiască infrastructura "model ca activ" în lumea Web3, realizând prin construirea desfășurării pe lanț, stimulentele apelului, atribuția drepturilor și combinarea agenților un ciclu complet, aducând pentru prima dată modelele AI într-un sistem economic care poate fi cu adevărat trasabil, monetizabil și colaborativ. Aceasta construiește un sistem tehnologic în jurul Model Factory, OpenLoRA, PoA și Datanets, oferind instrumente de antrenare cu prag scăzut pentru dezvoltatori, asigurându-se că contribuțiile de date sunt recompensate și oferind părților aplicații un mecanism combinabil de apelare a modelului și distribuire a profitului, activând complet resursele de "date" și "modele" care au fost pe termen lung ignorate în lanțul valorii AI.
#OpenLedger este mai degrabă o fuziune între HuggingFace + Stripe + Infura în lumea Web3, oferind găzduire pentru modele AI, tarifare pentru apeluri și interfețe API configurabile pe lanț. Pe măsură ce tendințele de activare a datelor, autonomia modelului și modularitatea agenților evoluează, OpenLedger are potențialul de a deveni un AI Chain central important sub modelul "AI plătibil".