Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Această cercetare independentă este susținută de IOSG Ventures, iar procesul de cercetare și scriere a fost inspirat de raportul de învățare prin întărire al lui Sam Lehman (Pantera Capital). Mulțumim lui Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare și Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang pentru sugestiile valoroase aduse acestui articol. Această lucrare își propune să fie obiectivă și precisă, unele puncte de vedere implicând judecăți subiective, inevitabil existând abateri, vă rugăm să înțelegeți.
Inteligența artificială trece de la învățarea statistică bazată pe „potrivirea modelului” la un sistem de capacități centrat pe „raționamentul structurat”, iar importanța post-antrenament (Post-training) crește rapid. Apariția DeepSeek-R1 marchează o răsturnare de paradigmă a învățării prin întărire în era modelelor mari, formând un consens în industrie: pre-antrenamentul construiește baza capacităților generale ale modelului, iar învățarea prin întărire nu mai este doar un instrument de aliniere a valorilor, ci s-a dovedit că poate îmbunătăți sistematic calitatea lanțului de raționament și capacitatea deciziilor complexe, evoluând treptat într-o cale tehnologică de îmbunătățire continuă a nivelului de inteligență.
Între timp, Web3 reconfigurează relațiile de producție AI prin rețele descentralizate de putere de calcul și sisteme de stimulente criptografice, iar cerințele structurale ale învățării prin întărire pentru eșantionarea rollout, semnalele de recompensă și antrenarea verificabilă se potrivesc perfect cu colaborarea pe bază de putere de calcul, distribuția stimulentelor și execuția verificabilă din blockchain. Această cercetare va descompune sistematic paradigma de antrenare AI și principiile tehnologiei învățării prin întărire, demonstrând avantajele structurale ale învățării prin întărire × Web3 și analizând proiecte precum Prime Intellect, Gensyn, Nous Research, Gradient, Grail și Fraction AI.
1. Cele trei etape ale antrenării AI: pre-antrenare, ajustare a instrucțiunilor și alinierea post-antrenării
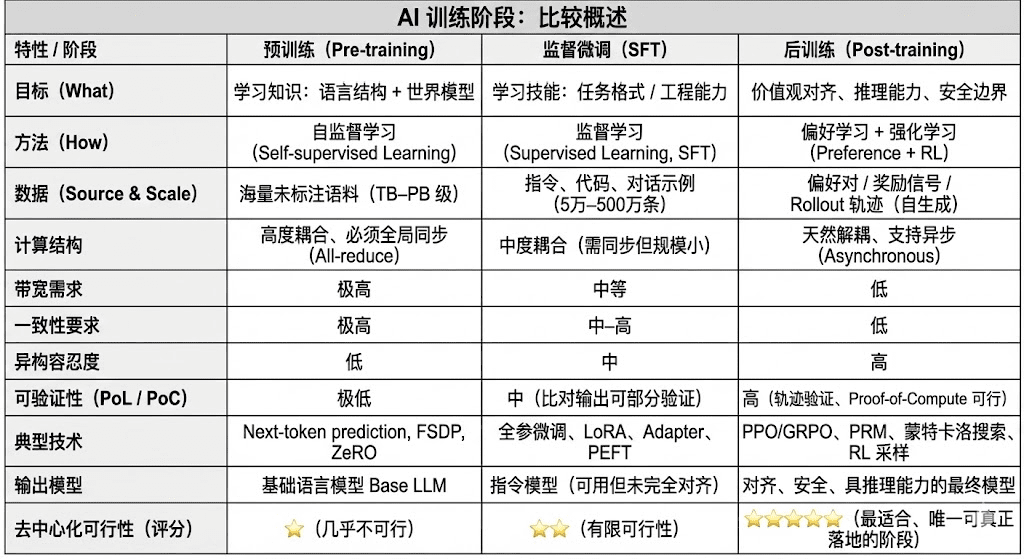
Ciclul de viață complet al antrenării modelelor de limbaj mari moderne (LLM) este de obicei împărțit în trei etape principale: pre-antrenare (Pre-training), microajustare supervizată (SFT) și post-antrenare (Post-training/RL). Fiecare dintre acestea îndeplinește funcții de „construire a modelului mondial - injectare a capacității sarcinii - formare a raționării și valorilor”, structura de calcul, cerințele de date și dificultățile de verificare determinând gradul de potrivire cu descentralizarea.
Pre-antrenarea (Pre-training) construiește structura statistică a limbajului/modelul mondial multimodal prin învățare auto-supervizată (Self-supervised Learning), fiind baza capacităților LLM. Această etapă necesită antrenare pe un corpus de trilioni într-un mod sincron la nivel global, depinzând de mii sau zeci de mii de clustere omogene H100, costul având o pondere de 80–95%, fiind extrem de sensibil la lățimea de bandă și drepturile de autor pentru date, de aceea trebuie finalizată într-un mediu extrem de centralizat.
Microajustarea (Supervised Fine-tuning) este utilizată pentru a injecta capacitatea sarcinii și formatul instrucțiunilor, având un volum mic de date, cu o pondere de cost de aproximativ 5–15%, microajustarea poate fi efectuată atât prin antrenarea tuturor parametrilor, cât și prin metode de microajustare eficientă din punct de vedere al parametrilor (PEFT), dintre care LoRA, Q-LoRA și Adapter sunt cele mai utilizate în industrie. Totuși, trebuie să se sincronizeze gradientele, limitând astfel potențialul de descentralizare.
Post-antrenarea (Post-training) este formată din mai multe sub-etape iterative, determinând capacitatea de raționare a modelului, valorile sale și limitele de securitate, metodele incluzând atât sistemele de învățare prin întărire (RLHF, RLAIF, GRPO), cât și metodele de optimizare a preferințelor fără RL (DPO), precum și modelul de recompensă al procesului (PRM). Această etapă are un volum de date și costuri mai mici (5–10%), concentrându-se pe Rollout-uri și actualizarea politicii; susținând în mod natural execuția asincronă și distribuită, nodurile nu trebuie să dețină greutăți complete, combinând calculul verificabil cu stimulentele on-chain pentru a forma o rețea de antrenare descentralizată deschisă, fiind cea mai potrivită etapă de antrenare pentru Web3.
2. Tehnologia învățării prin întărire în ansamblu: arhitectură, cadre și aplicații
2.1 Arhitectura sistemului de învățare prin întărire și etapele sale cheie
Învățarea prin întărire (Reinforcement Learning, RL) îmbunătățește capacitatea decizională a modelului prin „interacțiunea cu mediul - feedback-ul recompensei - actualizarea politicii”, structura sa de bază fiind un circuit de feedback format din stări, acțiuni, recompense și politici. Un sistem complet de RL conține de obicei trei tipuri de componente: Politica (Policy), Rollout (eșantionare experiențială) și Învățător (Learner). Politicile interacționează cu mediul pentru a genera traiectorii, Învățătorul actualizează politicile pe baza semnalelor de recompensă, formând astfel un proces de învățare continuă și optimizată:
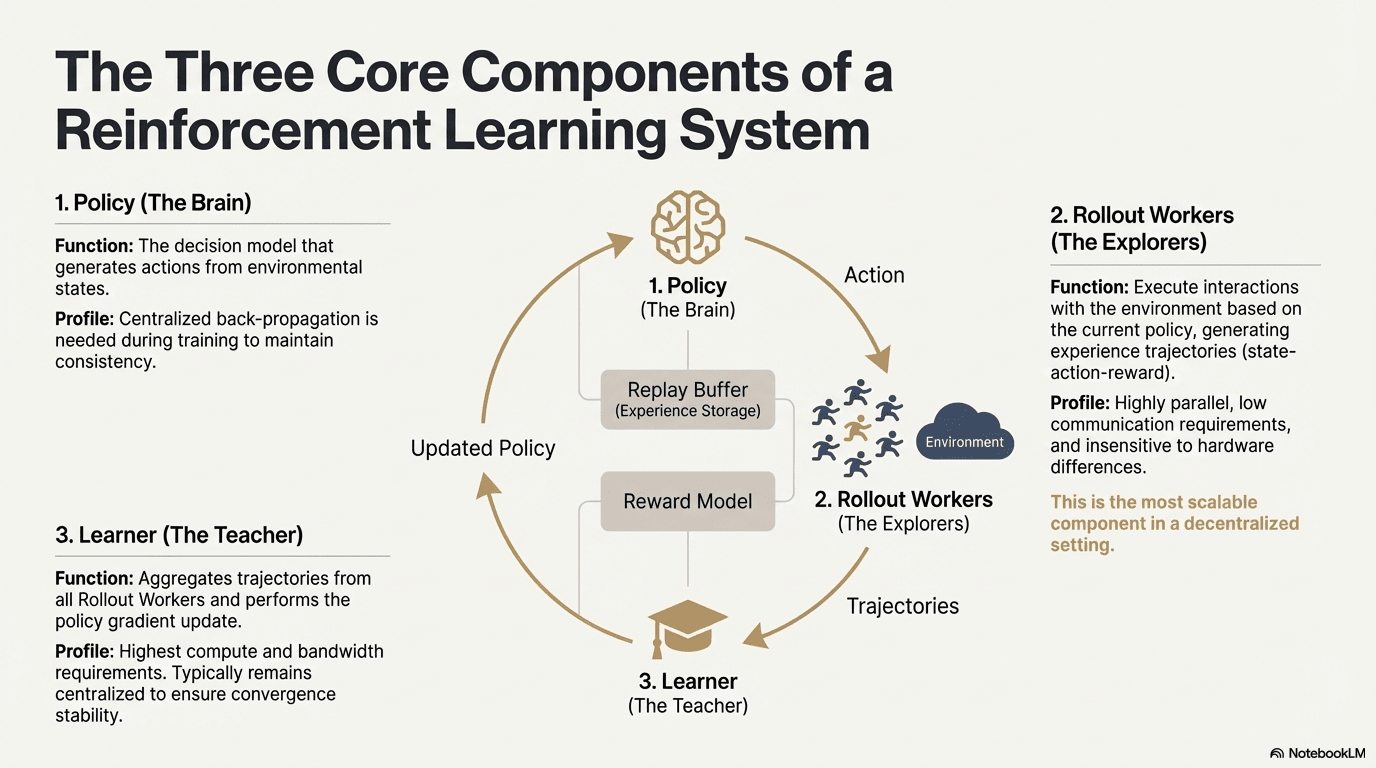
Rețeaua de politici (Policy): generează acțiuni din starea mediului, este nucleul decizional al sistemului. În timpul antrenării, necesită retropropagare centralizată pentru a menține consistența; în timpul inferenței poate fi distribuită pe diferite noduri pentru a rula în paralel.
Eșantionare experiențială (Rollout): nodurile interacționează cu mediul conform strategiei, generând traiectorii de stare-acțiune-recompensă etc. Acest proces este extrem de paralel, cu comunicație foarte scăzută și nu este sensibil la diferențele de hardware, fiind cel mai potrivit pentru scalarea descentralizată.
Învățător (Learner): agreghează toate traiectoriile Rollout și execută actualizări ale gradientului politic, este singurul modul cu cele mai mari cerințe de putere de calcul și bandă, astfel că de obicei se menține centralizat sau ușor centralizat pentru a asigura stabilitatea convergenței.
2.2 Cadru de etape ale învățării prin întărire (RLHF → RLAIF → PRM → GRPO)
Învățarea prin întărire poate fi împărțită în cinci etape, iar fluxul general este descris mai jos:
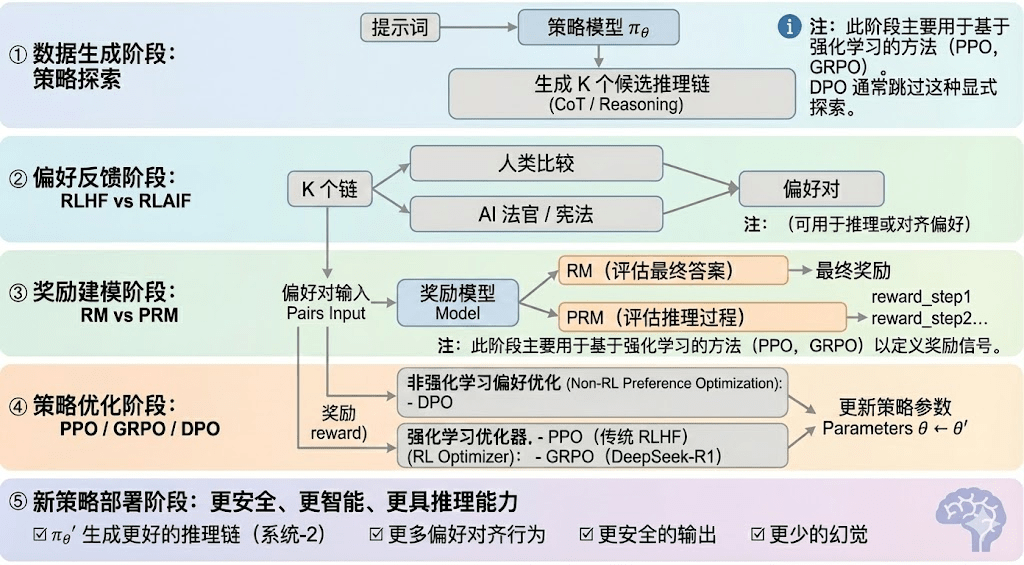
Etapa de generare a datelor (Policy Exploration): cu condiția că se oferă un prompt de intrare, modelul de strategie πθ generează mai multe lanțuri candidate de inferență sau traiectorii complete, oferind o bază de eșantion pentru evaluarea preferințelor și modelarea recompenselor, determinând astfel amplitudinea explorării strategice.
Etapa de feedback de preferință (RLHF / RLAIF):
RLHF (Reinforcement Learning from Human Feedback) optimizează răspunsurile candidate multiple, etichetează preferințele umane, antrenează un model de recompensă (RM) și utilizează PPO pentru a optimiza politica, astfel încât ieșirile modelului să fie mai conforme cu valorile umane, fiind un element cheie în tranziția de la GPT-3.5 la GPT-4.
RLAIF (Reinforcement Learning from AI Feedback) utilizează judecătorul AI sau reguli de tip constituțional pentru a înlocui etichetarea umană, automatizând obținerea preferințelor, reducând semnificativ costurile și având caracteristici de scalabilitate, devenind astfel paradigma standard de aliniere pentru Anthropic, OpenAI, DeepSeek și altele.
Etapa de modelare a recompenselor (Reward Modeling): preferințele se transformă în recompense pentru intrări, învățând să coreleze ieșirile cu recompensele. RM învață modelul „ce este un răspuns corect”, PRM învață modelul „cum să raționeze corect”.
RM (Modelul de Recompense) este utilizat pentru a evalua bunul sau răul răspunsului final, oferind scoruri doar pentru ieșiri:
Modelul de recompensă al procesului PRM (Process Reward Model) nu mai evaluează doar răspunsul final, ci oferă scoruri pentru fiecare pas de raționare, fiecare token, fiecare segment logic, fiind de asemenea o tehnologie cheie pentru OpenAI o1 și DeepSeek-R1, esențial în „a învăța modelul cum să gândească”.
Etapa de verificare a recompenselor (RLVR / Reward Verifiability): „implicarea constrângerilor verificabile” în procesul de generare și utilizare a semnalelor de recompensă, astfel încât recompensele să provină cât mai mult din reguli, fapte sau consensuri reproducibile, reducând riscurile de recompensă frauduloasă și abateri, crescând astfel capacitatea de audit și scalabilitatea în medii deschise.
Etapa de optimizare a politicii (Policy Optimization): actualizarea parametrilor politicii θ sub îndrumarea semnalelor oferite de modelul de recompense, pentru a obține o capacitate mai puternică de raționare, o securitate mai ridicată și un model de comportament mai stabil πθ′. Metodele de optimizare comune includ:
PPO (Proximal Policy Optimization): optimizatorul tradițional pentru RLHF, cunoscut pentru stabilitatea sa, dar în sarcini de raționare complexe întâmpină adesea limitări de convergență lentă și instabilitate.
GRPO (Group Relative Policy Optimization): inovația cheie a DeepSeek-R1, modelând distribuția avantajului în cadrul grupului de răspunsuri pentru a estima valoarea așteptată, mai degrabă decât a face o simplă clasificare. Această metodă păstrează informațiile despre amploarea recompenselor, fiind mai potrivită pentru optimizarea lanțurilor de raționare, procesul de antrenare fiind mai stabil, considerată importantă în cadrul RL pentru scenarii de raționare profundă, după PPO.
DPO (Direct Preference Optimization): metoda post-antrenare non-RL: nu generează traiectorii, nu construiește un model de recompensă, ci optimizează direct pe baza preferințelor, având costuri reduse și rezultate stabile, fiind astfel utilizată pe scară largă pentru modelele open-source Llama, Gemma etc., dar fără a îmbunătăți capacitatea de raționare.
Etapa de implementare a noii politici (New Policy Deployment): modelul optimizat se prezintă cu: o capacitate mai puternică de generare a lanțurilor de raționare (System-2 Reasoning), comportamente mai conforme cu preferințele umane sau AI, o rată a halucinațiilor mai mică și o securitate mai ridicată. Modelul învață continuu preferințele, optimizează procesul și îmbunătățește calitatea deciziilor, formând un ciclu închis.

2.3 Cinci categorii de aplicații industriale ale învățării prin întărire
Învățarea prin întărire (Reinforcement Learning) a evoluat de la inteligența de jocuri timpurii la un cadru centralizat de decizie autonomă, iar aplicațiile sale pot fi clasificate în cinci categorii, având fiecare un grad de maturitate tehnologică și realizări industriale, promovând progrese cheie în direcțiile respective.
Sistemul de jocuri și politici (Game & Strategy): este direcția în care RL a fost validat cel mai devreme, în medii „informații perfecte + recompense clare” precum AlphaGo, AlphaZero, AlphaStar, OpenAI Five, RL a demonstrat inteligența decizională capabilă să rivalizeze sau chiar să depășească experții umani, stabilind baza pentru algoritmii moderni de RL.
Robotică și inteligență încorporată (Embodied AI): RL, prin control continuu, modelare dinamică și interacțiuni cu mediul, permite roboților să învețe să controleze, să se miște și să îndeplinească sarcini multimodale (cum ar fi RT-2, RT-X), înaintând rapid către industrializare, fiind o tehnologie cheie pentru realizarea roboților în lumea reală.
Raționare digitală (Digital Reasoning / LLM System-2): RL + PRM îmbunătățește modelele mari din „imitarea limbajului” la „raționarea structurată”, rezultatele reprezentative includ DeepSeek-R1, OpenAI o1/o3, Anthropic Claude și AlphaGeometry, esența acestora fiind optimizarea recompensei la nivelul lanțului de raționare, și nu doar evaluarea răspunsului final.
Descoperirea științifică automată și optimizarea matematică (Scientific Discovery): RL caută structuri sau strategii optime în medii fără etichete, recompense complexe și spații enorme de căutare, având realizări fundamentale precum AlphaTensor, AlphaDev, Fusion RL, demonstrând capacități de explorare ce depășesc intuiția umană.
Sisteme de decizie economică și tranzacționare (Economic Decision-making & Trading): RL este utilizat pentru optimizarea strategiilor, controlul riscurilor înalte și generarea sistemelor de tranzacționare adaptive, având capacitatea de a învăța continuu în medii incerte, fiind o componentă importantă a finanțelor inteligente.
3. Potrivit învățării prin întărire pentru Web3
Combinația dintre învățarea prin întărire (RL) și Web3 se bazează pe faptul că ambele sunt în esență „sisteme bazate pe stimulente”. RL se bazează pe semnalele de recompensă pentru a optimiza politicile, iar blockchain-ul se bazează pe stimulentele economice pentru a coordona comportamentele participanților, făcând ca cele două să fie în mod natural consistente din punct de vedere mecanic. Cerințele centrale ale RL — Rollout-uri heterogene la scară mare, distribuția recompenselor și verificarea autenticității — sunt chiar avantajele structurale ale Web3.
Decuplarea inferenței de antrenare: procesul de antrenare al învățării prin întărire poate fi clar despărțit în două etape:
Rollout (eșantionare exploratorie): modelul generează o cantitate mare de date pe baza strategiei curente, fiind o sarcină intensivă din punct de vedere al calculului, dar rară din punct de vedere al comunicării. Nu necesită comunicare frecventă între noduri, fiind potrivit pentru generarea paralelă pe GPU-uri de consum distribuite global.
Actualizare (actualizarea parametrilor): bazată pe datele colectate pentru a actualiza greutățile modelului, necesită noduri centralizate cu bandă mare pentru a finaliza.
Decuplarea „inferență-antrenare” se potrivește perfect structurii descentralizate de putere de calcul heterogenă: Rollout-uri pot fi externalizate către rețele deschise, iar prin mecanismele de tokenizare se poate calcula compensarea în funcție de contribuție, în timp ce actualizarea modelului rămâne centralizată pentru a asigura stabilitatea.
Verificabilitate (Verifiability): ZK și dovada învățării (Proof-of-Learning) oferă modalități de a verifica dacă nodurile au executat cu adevărat inferența, rezolvând problema onestității în rețelele deschise. În sarcini deterministe precum coduri, raționamente matematice etc., verificatorii trebuie doar să verifice răspunsul pentru a confirma volumul de muncă, sporind semnificativ credibilitatea sistemului RL descentralizat.
Stratul de stimulente, bazat pe un mecanism de producție a feedback-ului pe baza tokenurilor: mecanismele de token din Web3 pot recompensa direct contribuțiile la feedback-urile preferințelor RLHF/RLAIF, făcând ca generarea datelor de preferință să beneficieze de o structură de stimulente transparentă, calculabilă și fără permisiune; staking-ul și reducerea (Staking/Slashing) restricționează suplimentar calitatea feedback-ului, formând o piață de feedback mai eficientă și mai aliniată decât în cazul tradițional.
Potentțialul învățării prin întărire multi-agent (MARL): blockchain-ul este în esență un mediu multi-agent deschis, transparent și în continuă evoluție, conturile, contractele și agenții își ajustează continuu strategiile sub influența stimulentelor, ceea ce conferă un potențial natural pentru construirea unor experimente MARL la scară mare. Deși este încă în stadiul incipient, caracteristicile sale de transparență publică, execuție verificabilă și stimulente programabile oferă un avantaj principial pentru dezvoltarea viitoare a MARL.
4. Analiza proiectelor clasice Web3 + învățare prin întărire
Pe baza cadrului teoretic de mai sus, vom analiza pe scurt cele mai reprezentative proiecte din ecosistemul actual:
Prime Intellect: paradigma de învățare prin întărire asincronă prime-rl
Prime Intellect se dedică construirii unei piețe globale de putere de calcul deschisă, reducând pragurile de antrenare, promovând antrenarea descentralizată colaborativă și dezvoltând un pachet complet de tehnologii superinteligente open-source. Sistemul său include: Prime Compute (mediu de calcul unificat/cloud distribuit), familia de modele INTELLECT (10B–100B+), centrul de medii de învățare prin întărire deschis (Environments Hub) și motorul de date sintetice la scară mare (SYNTHETIC-1/2).
Componenta de bază a infrastructurii Prime Intellect, cadrul prime-rl, este proiectată special pentru medii distribuite asincrone și este strâns legată de învățarea prin întărire, celelalte includ protocolul de comunicare OpenDiLoCo, care depășește constrângerile de bandă, mecanismele de verificare TopLoc care asigură integritatea calculului etc.
Prezentarea componentelor esențiale ale infrastructurii Prime Intellect

Piatra de temelie tehnologică: cadrul de învățare prin întărire asincron prime-rl
prime-rl 是 Prime Intellect 的核心训练引擎,专为大规模异步去中心化环境设计,通过 Actor–Learner 完全解耦实现高吞吐推理与稳定更新。执行者(Rollout Worker) 与 学习者(Trainer) 不再同步阻塞,节点可随时加入或退出,只需持续拉取最新策略并上传生成数据即可:
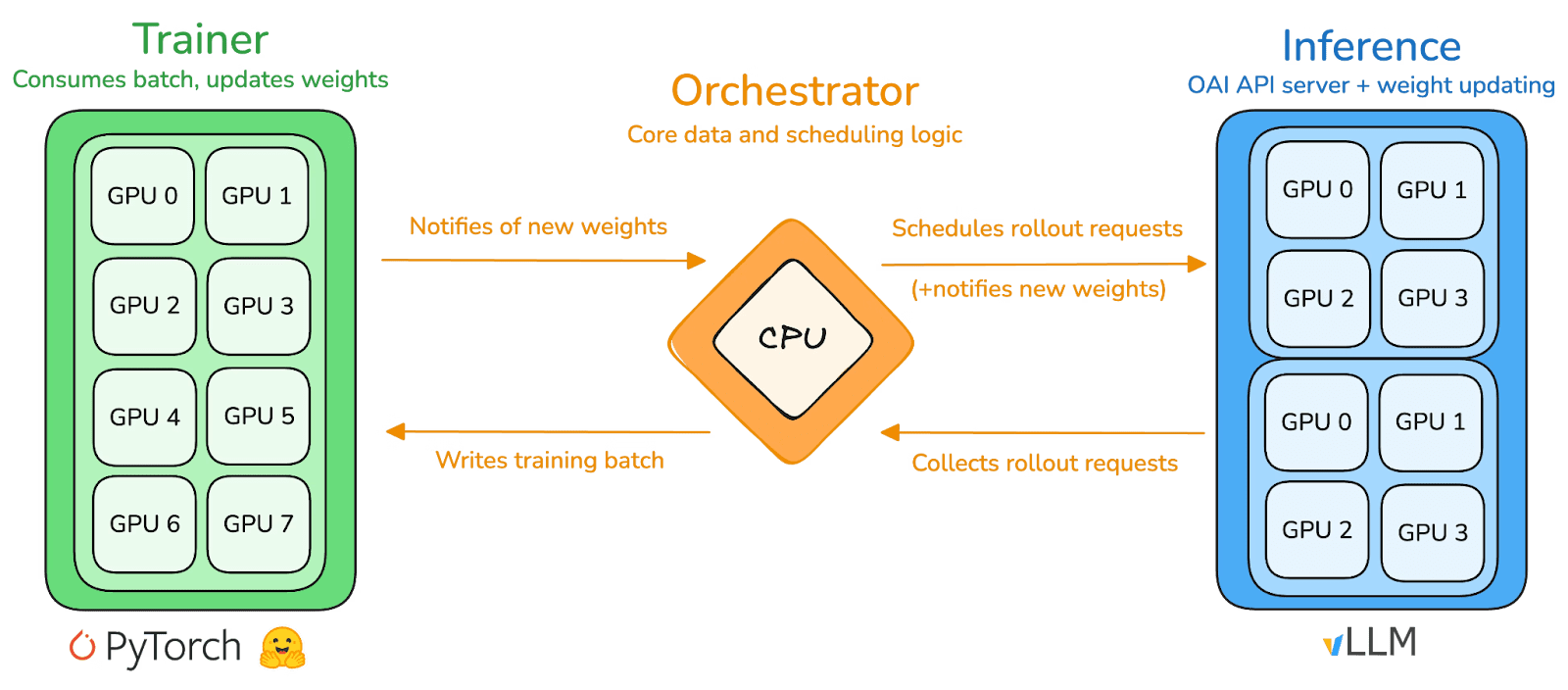
Executori Actor (Rollout Workers): responsabili pentru inferența modelului și generarea de date. Prime Intellect integrează inovator un motor de inferență vLLM în partea Actor. Tehnologia PagedAttention a vLLM și capacitatea de procesare continuă (Continuous Batching) permit Actorului să genereze traiectorii de inferență cu un throughput extrem de ridicat.
Învățător Learner (Trainer): responsabil pentru optimizarea politicii. Învățătorul trage date asyncron din zona de buffer de experiență (Experience Buffer) fără a aștepta finalizarea lotului curent de către toți Actorii.
Coordonator (Orchestrator): responsabil pentru programarea greutăților modelului și a fluxului de date.
Punctele cheie ale inovației prime-rl:
Adevărată asincronizare (True Asynchrony): prime-rl abandonează paradigma sincronizată tradițională a PPO, fără a aștepta nodurile lente, fără a necesita alinierea loturilor, permițând un număr arbitrar de GPU-uri cu performanțe variate să se conecteze oricând, stabilind fezabilitatea RL descentralizat.
Integrarea profundă FSDP2 și MoE: prin tăierea parametrelor FSDP2 și activarea rară MoE, prime-rl permite antrenarea eficientă a modelelor de sute de miliarde în medii distribuite, Actorul rulând doar experții activi, reducând semnificativ costurile de memorie și inferență.
GRPO+ (Group Relative Policy Optimization): GRPO elimină rețeaua Critic, reducând semnificativ costurile de calcul și memorie, adaptându-se natural la medii asincrone, GRPO+ de la prime-rl asigurând prin mecanisme de stabilizare convergența fiabilă în condiții de latență ridicată.
Familia de modele INTELLECT: un semn al maturității tehnologiilor RL descentralizate
INTELLECT-1(10B,2024年10月)首次证明 OpenDiLoCo 能在跨三大洲的异构网络中高效训练(通信占比 <2%、算力利用率 98%),打破跨地域训练的物理认知;
INTELLECT-2(32B,2025年4月)作为首个 Permissionless RL 模型,验证 prime-rl 与 GRPO+ 在多步延迟、异步环境中的稳定收敛能力,实现全球开放算力参与的去中心化 RL;
INTELLECT-3(106B MoE,2025年11月)采用仅激活 12B 参数的稀疏架构,在 512×H200 上训练并实现旗舰级推理性能(AIME 90.8%、GPQA 74.4%、MMLU-Pro 81.9% 等),整体表现已逼近甚至超越规模远大于自身的中心化闭源模型。
În plus, Prime Intellect a construit mai multe infrastructuri de susținere: OpenDiLoCo reduce de sute de ori volumul de comunicare al antrenamentului trans-regional prin comunicare rară în timp și diferențierea greutăților cuantificate, permițând INTELLECT-1 să mențină o rată de utilizare de 98% pe rețele transcontinentale; TopLoc + Verifiers formează un strat de execuție de încredere descentralizat, activând verificarea amprentei și a sandbox-ului pentru a asigura autenticitatea datelor de inferență și recompensă; motorul de date SYNTHETIC produce lanțuri de inferență de înaltă calitate la scară mare și permite rularea eficientă a modelului de 671B pe grupuri de GPU-uri de consum. Aceste componente oferă baza ingineriei esențiale pentru generarea de date, verificarea și throughput-ul inferenței RL descentralizate. Seria INTELLECT demonstrează că acest stivă tehnologică poate produce modele mondiale mature, marcând tranziția sistemului de antrenare descentralizat din faza de concept în faza practică.
Gensyn: Stiva centrală de învățare prin întărire RL Swarm și SAPO
Obiectivul Gensyn este de a reuni puterea de calcul globală neutilizată într-o infrastructură de antrenare AI deschisă, bazată pe încredere, și cu o scalabilitate nelimitată. Elementele sale de bază includ un strat de execuție standardizat între dispozitive, o rețea de coordonare peer-to-peer și un sistem de verificare a sarcinilor care nu necesită încredere, și prin contracte inteligente alocă automat sarcini și recompense. În jurul caracteristicilor învățării prin întărire, Gensyn introduce mecanisme cheie precum RL Swarm, SAPO și SkipPipe, decuplând cele trei etape de generare, evaluare și actualizare, utilizând „stupul” format din GPU-uri heterogene globale pentru a realiza evoluția colectivă. Rezultatul final nu este doar puterea de calcul, ci inteligența verificabilă (Verifiable Intelligence).
Aplicațiile învățării prin întărire din stiva Gensyn

RL Swarm: motorul de învățare prin întărire descentralizat de colaborare
RL Swarm prezintă un nou mod de colaborare. Nu mai este vorba doar de distribuirea sarcinilor, ci de un ciclu descentralizat „generare-evaluare-actualizare” care simulează învățarea din societatea umană, un ciclu infinit:
Solveri (executori): responsabili pentru inferența modelului local și generarea Rollout-urilor, nodurile heterogene nu constituie un obstacol. Gensyn integrează un motor de inferență de mare throughput (cum ar fi CodeZero) la nivel local, capabil să genereze traiectorii complete, nu doar răspunsuri.
Propozanți (creatori de sarcini): generează dinamic sarcini (probleme matematice, întrebări de cod etc.), susținând diversitatea sarcinilor și adaptabilitatea dificultății de tip Curriculum Learning.
Evaluatori (evaluatori): folosesc un „model de arbitru” sau reguli înghețate pentru a evalua Rollout-urile locale, generând semnale de recompensă locale. Procesul de evaluare poate fi auditat, reducând spațiul răului.
Cele trei formează o structură organizațională RL P2P, completând învățarea colaborativă la scară mare fără a necesita programare centralizată.
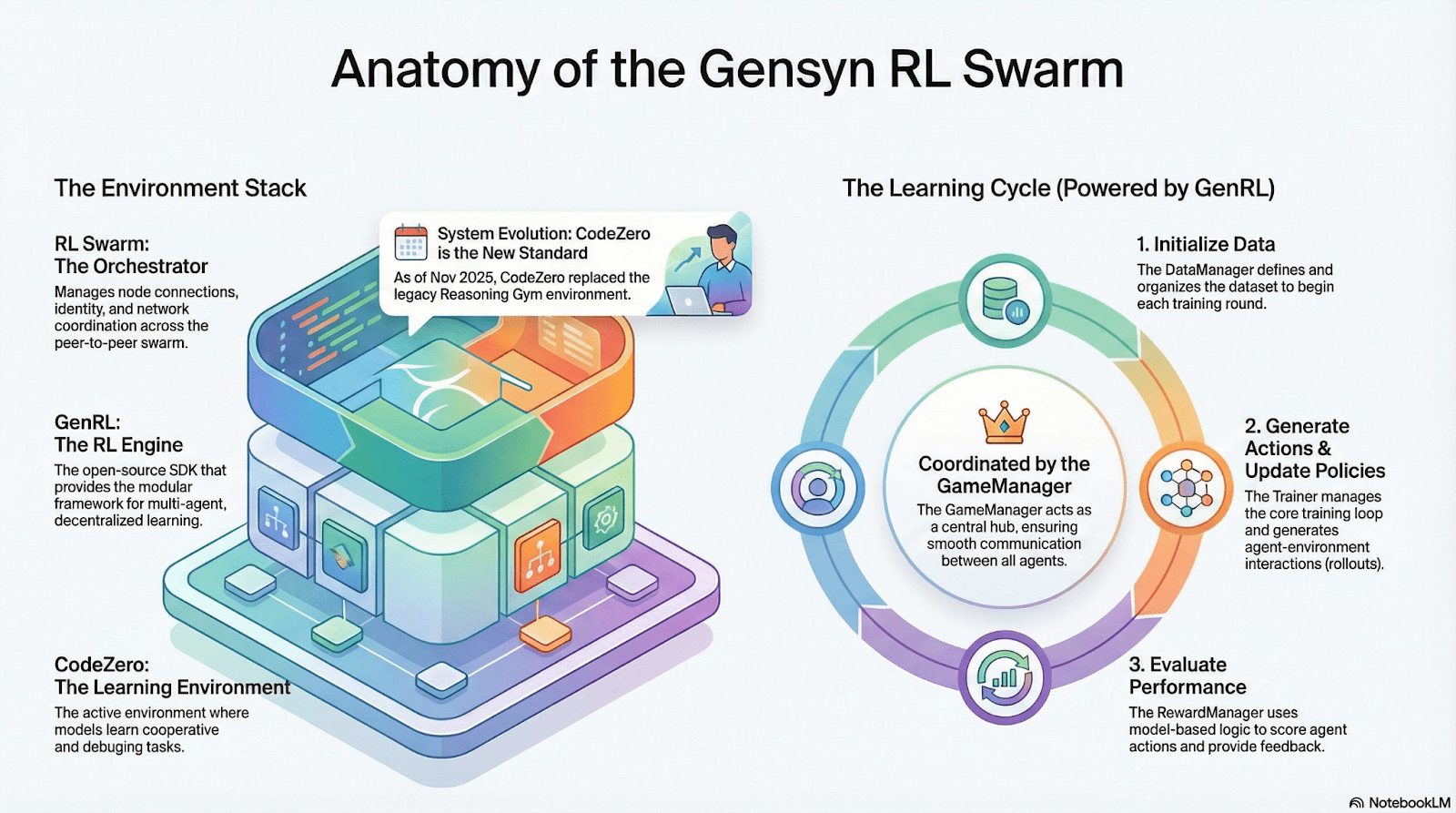
SAPO: Algoritmul de optimizare a politicii reconstruit pentru descentralizare: SAPO (Swarm Sampling Policy Optimization) se concentrează pe „împărtășirea Rollout-urilor și filtrarea exemplelor de semnal fără gradient, mai degrabă decât împărtășirea gradientelor”, prin eșantionarea Rollout-urilor descentralizate la scară mare și considerând Rollout-urile primite ca generate local, menținând convergența stabilă într-un mediu fără coordonare centralizată și cu întârzieri semnificative între noduri. Spre deosebire de PPO, care se bazează pe rețeaua Critic și are costuri de calcul mai mari, sau GRPO, care se bazează pe estimările avantajului din interiorul grupului, SAPO permite GPU-urilor de consum să participe eficient la optimizarea învățării prin întărire la scară mare, folosind o lățime de bandă extrem de redusă.
Prin RL Swarm și SAPO, Gensyn a demonstrat că învățarea prin întărire (în special RLVR în etapa de post-antrenare) se potrivește perfect arhitecturii descentralizate, deoarece depinde mai mult de explorarea pe scară largă și diversificată (Rollout), decât de sincronizarea frecventă a parametrilor. Combinând sistemele de verificare PoL și Verde, Gensyn oferă o cale alternativă pentru antrenarea modelelor cu parametrii de trilion, fără a depinde de un singur gigant tehnologic: o rețea de superinteligent auto-evolutivă formată din milioane de GPU-uri heterogene globale.
Nous Research: Mediu de învățare prin întărire verificabil Atropos
Nous Research construiește o infrastructură cognitivă descentralizată și auto-evolutivă. Componentele sale de bază — Hermes, Atropos, DisTrO, Psyche și World Sim sunt organizate într-un sistem de evoluție inteligentă închis continuu. Spre deosebire de fluxul liniar tradițional „pre-antrenare - post-antrenare - inferență”, Nous folosește tehnici de învățare prin întărire precum DPO, GRPO și eșantionare refuzată pentru a unifica generarea de date, verificarea, învățarea și inferența într-un circuit de feedback continuu, creând un ecosistem AI închis de auto-îmbunătățire.
Prezentare generală a componentelor Nous Research

Nivelul modelului: evoluția lui Hermes și a capacității de raționare
Seria Hermes reprezintă interfața principală a modelului orientată către utilizatori de la Nous Research, evoluția sa clar arată tranziția industriei de la alinierea tradițională SFT/DPO la învățarea prin întărire a inferenței (Reasoning RL):
Hermes 1–3: alinierea instrucțiunilor și abilitățile timpurii ale agenților: Hermes 1–3 se bazează pe DPO cu costuri reduse pentru a finaliza alinierea stabilă a instrucțiunilor, iar în Hermes 3 folosește date sintetice și introduce pentru prima dată mecanismul de verificare Atropos.
Hermes 4 / DeepHermes: scriind în greutăți lanțul de gândire System-2, îmbunătățind performanța matematică și a codului prin Test-Time Scaling, și bazându-se pe „eșantionare refuzată + verificare Atropos” pentru a construi date de inferență de mare puritate.
DeepHermes adoptă în continuare GRPO în locul PPO-ului greu de distribuit, permițând RL-ul de inferență să ruleze în rețeaua GPU descentralizată Psyche, stabilind baza ingineriei pentru scalabilitatea RL-ului de inferență open-source.
Atropos: Un mediu de învățare îmbunătățit bazat pe recompense verificabile
Atropos este adevăratul nucleu al sistemului RL de la Nous. Acesta învăluie sugestii, apeluri de instrumente, execuții de cod și interacțiuni multiple într-un mediu RL standardizat, permițând verificarea directă a corectitudinii ieșirii, oferind astfel un semnal de recompensă determinist. În plus, în rețeaua de antrenare descentralizată Psyche, Atropos acționează ca un „arbitru”, utilizat pentru a verifica dacă nodurile îmbunătățesc cu adevărat strategiile, susținând dovada de învățare (Proof-of-Learning) auditată, rezolvând astfel fundamental problema credibilității recompenselor în RL distribuit.
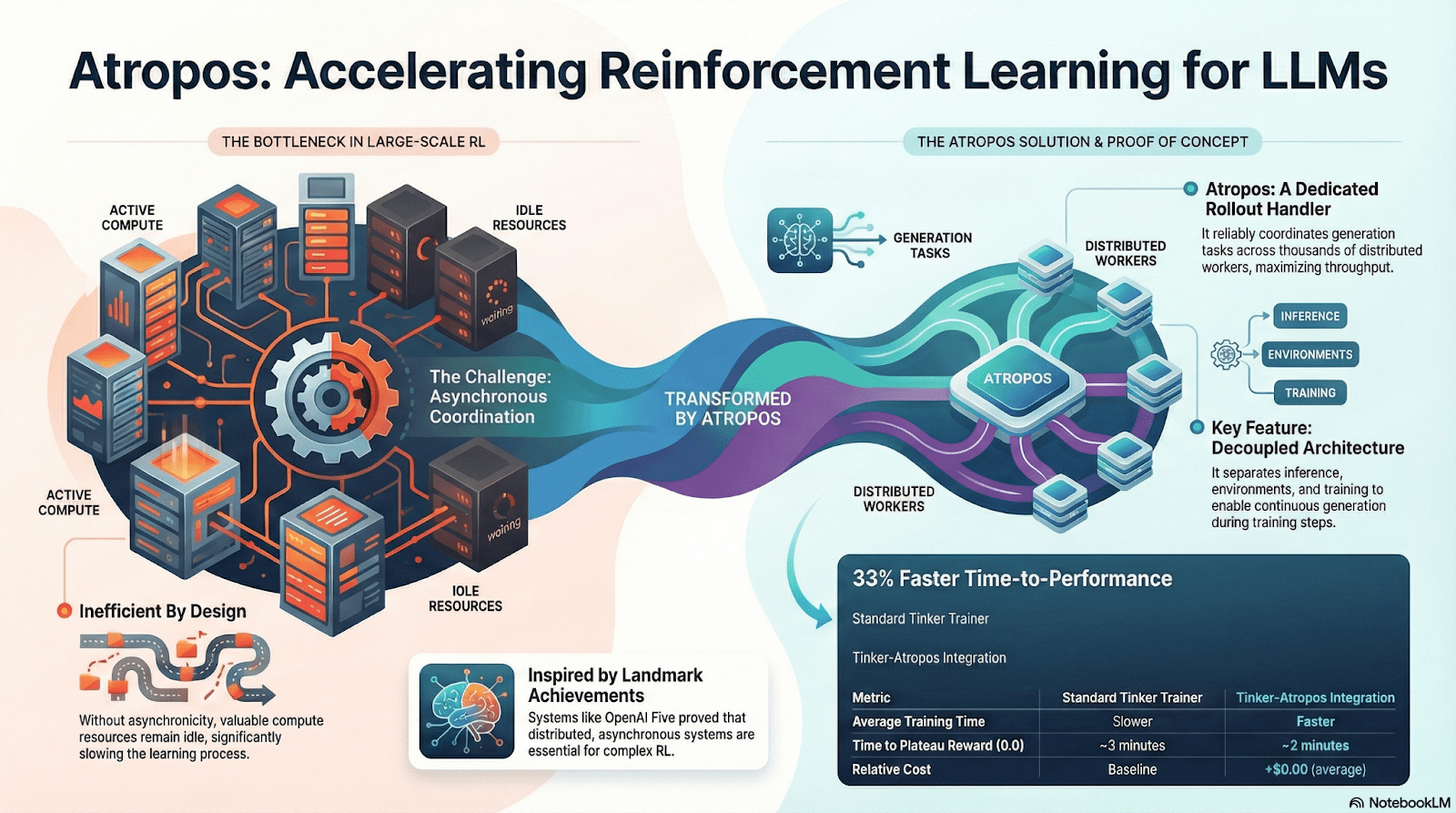
DisTrO și Psyche: stratul de optimizare pentru învățarea prin întărire descentralizată
传统 RLF(RLHF/RLAIF)训练依赖中心化高带宽集群,这是开源无法复制的核心壁垒。DisTrO 通过动量解耦与梯度压缩,将 RL 的通信成本降低几个数量级,使训练能够在互联网带宽上运行;Psyche 则将这一训练机制部署在链上网络,使节点可以在本地完成推理、验证、奖励评估与权重更新,形成完整的 RL 闭环。
În cadrul sistemului Nous, Atropos verifică lanțul de gândire; DisTrO comprimă comunicarea în timpul antrenării; Psyche rulează ciclul RL; World Sim oferă un mediu complex; Forge colectează inferențe reale; Hermes scrie toate învățările în greutăți. Învățarea prin întărire nu este doar o etapă de antrenare, ci protocolul central care leagă datele, mediul, modelul și infrastructura în arhitectura Nous, făcând din Hermes un sistem viu capabil de auto-îmbunătățire continuă într-o rețea de putere de calcul open-source.
Gradient Network: arhitectura de învățare prin întărire Echo
Viziunea centrală a Gradient Network este de a reconstrui paradigma de calcul AI prin „stiva deschisă de inteligență” (Open Intelligence Stack). Stiva tehnologică a Gradient este formată dintr-un set de protocoale de bază care pot evolua independent, dar colaborează heterogen. Sistemul său include de la comunicarea de bază până la colaborarea inteligentă de nivel superior: Parallax (inferență distribuită), Echo (antrenare descentralizată RL), Lattica (rețea P2P), SEDM / Massgen / Symphony / CUAHarm (memorie, colaborare, securitate), VeriLLM (verificare de încredere), Mirage (simulare de înaltă fidelitate), formând astfel o infrastructură de inteligență descentralizată în continuă evoluție.

Echo — arhitectura de antrenare prin întărire
Echo este cadrul de învățare prin întărire al Gradient, principiul său de design central constând în decuplarea antrenării, inferenței și datelor (recompense) în învățarea prin întărire, astfel încât generarea Rollout-urilor, optimizarea strategiilor și evaluarea recompenselor să poată fi extinse și programate independent în medii heterogene. Acesta funcționează în colaborare într-o rețea heterogenă formată din noduri de inferență și antrenare, menținând stabilitatea antrenării în medii extinse și heterogene prin mecanisme de sincronizare ușoară, atenuând eficient eșecurile SPMD și limitările utilizării GPU-urilor cauzate de rulările mixte de inferență și antrenare din RLHF tradițional / VERL.
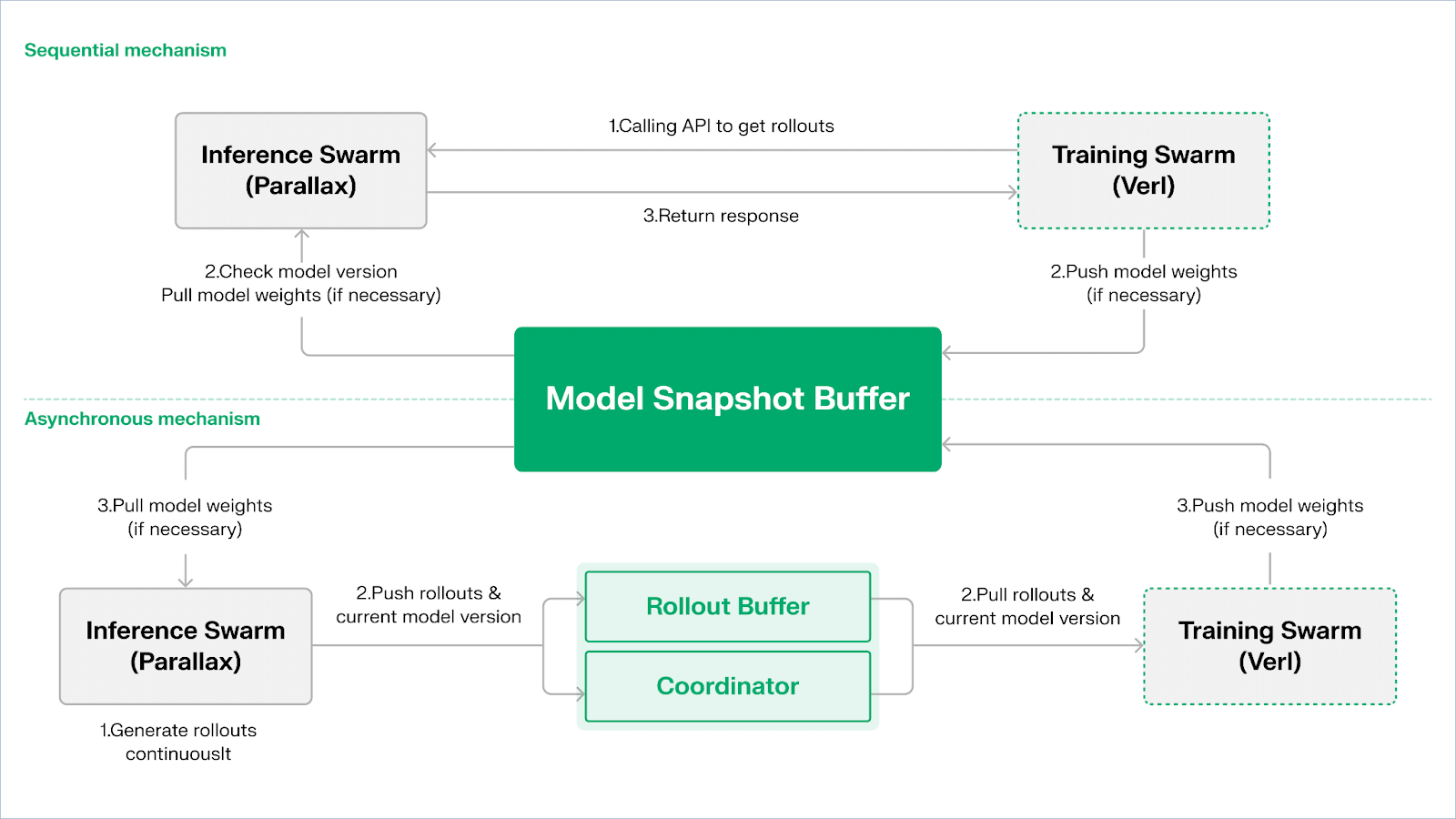
Echo 采用“推理–训练双群架构”实现算力利用最大化,双群各自独立运行,互不阻塞:
Maximizarea throughput-ului de eșantionare: roiul de inferență (Inference Swarm) este compus din GPU-uri de consum și dispozitive edge, construind eșantionere de mare throughput prin Parallax utilizând pipeline-parallel, concentrându-se pe generarea traiectoriilor;
Maximizarea puterii gradientului: roiul de antrenare (Training Swarm) este constituit dintr-o rețea de GPU-uri de consum care poate funcționa pe clustere centralizate sau pe multiple locații globale, responsabil pentru actualizarea gradientului, sincronizarea parametrilor și ajustarea LoRA, concentrându-se pe procesul de învățare.
Pentru a menține consistența între strategie și date, Echo oferă două tipuri de protocoale de sincronizare ușoară: secvențial (Sequential) și asincron (Asynchronous), realizând gestionarea bidirecțională a consistenței greutăților strategiei și a traiectoriilor:
Modul de extragere secvențială (Pull) | Precizie prioritară: Latura antrenării forțează nodurile să actualizeze versiunea modelului înainte de a extrage noi traiectorii, pentru a asigura prospețimea traiectoriilor, potrivit pentru sarcini extrem de sensibile la strategiile învechite;
Modul de extragere asincronă (Push–Pull) | Eficiență prioritară: Latura de inferență continuă generează traiectorii etichetate cu versiuni, iar latura de antrenare consumă în ritmul său, coordonatorul monitorizând abaterile de versiune și declanșând actualizarea greutăților, maximizând utilizarea dispozitivelor.
La nivel de bază, Echo este construit pe Parallax (inferență heterogenă în medii cu bandă redusă) și componente de antrenare distribuită ușoară (cum ar fi VERL), bazându-se pe LoRA pentru a reduce costurile de sincronizare între noduri, permițând învățarea prin întărire să funcționeze stabil pe rețele globale heterogene.
Grail: învățarea prin întărire din ecosistemul Bittensor
Bittensor, prin mecanismul său unic de consens Yuma, a construit o rețea vastă, rară și non-staționară de funcții de recompensă.
Covenant AI din ecosistemul Bittensor a construit un lanț de integrare vertical de la pre-antrenare la antrenarea post-RL prin SN3 Templar, SN39 Basilica și SN81 Grail. Aici, SN3 Templar se ocupă de pre-antrenarea modelului de bază, SN39 Basilica oferă o piață de putere de calcul distribuită, iar SN81 Grail acționează ca un „strat de inferență verificabil” pentru antrenarea post-RL, susținând fluxul central al RLHF/RLAIF, completând optimizarea închiderii de la modelul de bază la alinierea strategiei.

GRAIL目标是以密码学方式证明每条强化学习 rollout 的真实性与模型身份绑定,确保 RLHF 能够在无需信任的环境中被安全执行。协议通过三层机制建立可信链条:
Generarea provocărilor deterministe: utilizând drand, semnalul aleator și hash-ul blocului pentru a genera sarcini provocatoare imprevizibile, dar reproducibile (cum ar fi SAT, GSM8K), prevenind frauda prin pre-calcul;
Prin indexarea eșantionării PRF și angajamentele schiței, verificatorii pot verifica la costuri foarte reduse logprob-ul la nivel de token și lanțurile de inferență, confirmând că rollout-ul este generat de modelul declarat.
Identificarea modelului: legarea procesului de inferență de amprenta greutăților modelului și distribuția token-ului prin semnături structurale, asigurându-se că înlocuirea modelului sau reîncercarea rezultatelor va fi imediat identificată. Astfel, se oferă o bază de autenticitate pentru traiectoriile de inferență (rollout) în RL.
Pe baza acestui mecanism, subnet-ul Grail a realizat un proces de antrenare post-verificabil de tip GRPO: minerii generează mai multe căi de inferență pentru aceeași problemă, verificatorii evaluează corectitudinea, calitatea lanțului de inferență și scorul de satisfacție SAT, iar rezultatul normalizat este scris în blockchain ca greutate TAO. Experimentele publice arată că acest cadru a crescut precizia MATH a Qwen2.5-1.5B de la 12.7% la 47.6%, demonstrând că poate preveni frauda și poate îmbunătăți semnificativ capacitatea modelului. În cadrul stivei de antrenare a Covenant AI, Grail este fundația de încredere și execuție a RLVR/RLAIF descentralizate, care nu a fost încă lansată oficial pe rețeaua principală.
Fraction AI: Învățare prin întărire competitivă RLFC
Arhitectura Fraction AI este clar construită în jurul învățării prin întărire competitivă (Reinforcement Learning from Competition, RLFC) și etichetarea datelor gamificate, înlocuind recompensele statice și etichetarea umană din RLHF tradițional cu un mediu deschis și dinamic de competiție. Agenții se confruntă în diferite Spații, iar clasamentele lor relative și scorurile judecătorului AI formează împreună recompensele în timp real, transformând procesul de aliniere într-un sistem continuu de joc multiactori.
Diferența centrală dintre RLHF tradițional și RLFC de la Fraction AI:

Valoarea centrală a RLFC constă în faptul că recompensele nu mai provin dintr-un singur model, ci din adversari și evaluatori care evoluează continuu, evitând exploatarea modelului de recompensă și prevenind ecologia de a cădea în optimul local prin diversitatea strategiilor. Structura Spațiilor determină natura jocului (zero-sum sau non-zero-sum), promovând apariția comportamentului complex în adversitate și colaborare.
În arhitectura sistemului, Fraction AI descompune procesul de antrenare în patru componente cheie:
Agenți: unități de politică ușoară bazate pe LLM open-source, extinse prin QLoRA cu greutăți diferențiate, actualizări cu costuri reduse;
Spații: medii de domenii de sarcini izolate, agenții plătesc pentru a intra și obțin recompense în funcție de câștig și pierdere;
Judecători AI: strat de recompensă instantanee construit cu RLAIF, oferind evaluări descentralizate și scalabile;
Dovada învățării: legarea actualizărilor strategiei de rezultatele specifice ale competiției, asigurându-se că procesul de antrenare este verificabil și protejat de fraude.
Esenta Fraction AI este construirea unui motor de evoluție colaborativă om-mașină. Utilizatorii, ca „meta-optimizatori” ai stratului de politici, ghidează direcția explorării prin inginerie a sugestiilor (Prompt Engineering) și configurări de hiperparametrii; agenții, în competiția microscopică, generează automat cantități mari de date de preferință de înaltă calitate (Preference Pairs). Acest model permite etichetarea datelor prin „ajustarea fără încredere” (Trustless Fine-tuning) să realizeze un ciclu comercial.
Comparația arhitecturală a proiectelor Web3 de învățare prin întărire

5. Rezumat și perspective: Calea și oportunitățile învățării prin întărire × Web3
Pe baza analizei deconstruite a proiectelor de frontieră menționate mai sus, am observat că, deși punctele de plecare ale echipelor (algoritmi, inginerie sau piață) sunt diferite, atunci când învățarea prin întărire (RL) este combinată cu Web3, logica arhitecturală de bază converge într-un paradigmă extrem de consistentă de „decuplare-verificare-recompensare”. Aceasta nu este doar o coincidență tehnică, ci și un rezultat inevitabil al adaptării rețelelor descentralizate la proprietățile unice ale învățării prin întărire.
Caracteristicile arhitecturii generale de învățare prin întărire: soluționarea problemelor fundamentale de constrângeri fizice și de încredere
Decuplarea fizică a antrenării și învățării (Decoupling of Rollouts & Learning) — topologia de calcul implicită
Comunicarea rară și paralelă a Rollout-urilor este externalizată către GPU-uri de consum din întreaga lume, actualizările parametrilor cu bandă mare sunt concentrate pe câteva noduri de antrenare, de la Actor–Learner asincron Prime Intellect până la arhitectura cu două roiuri a Gradient Echo.
Stratul de încredere bazat pe verificare (Verification-Driven Trust) — infrastructură
În rețelele fără permisiune, autenticitatea calculului trebuie să fie garantată prin design matematic și mecanic, reprezentând implementări precum PoL de la Gensyn, TOPLOC de la Prime Intellect și verificarea criptografică a Grail.
Ciclul de stimulente tokenizate (Tokenized Incentive Loop) — auto-reglarea pieței
Oferirea de putere de calcul, generarea datelor, ordonarea verificării și distribuția recompenselor formează un ciclu închis, prin stimulentele recompenselor participarea este stimulată, iar prin Slash se inhibă frauda, permițând rețelei să rămână stabilă și în continuă evoluție în medii deschise.
Calea tehnologică diferențiată: diferite „puncte de cotitură” sub aceeași arhitectură
Deși arhitecturile sunt similare, fiecare proiect a ales o fosa tehnologică diferită în funcție de genele sale:
Școala de rupere a algoritmilor (Nous Research): încearcă să rezolve contradicțiile fundamentale ale antrenării distribuite (constrângerea lățimii de bandă) dintr-o bază matematică. Optimizerul său DisTrO își propune să comprime volumul de comunicare al gradientului de mii de ori, obiectivul fiind de a permite lățimea de bandă de acasă să poată susține antrenarea modelelor mari, acesta fiind o „lovitură de dimensiune” asupra limitărilor fizice.
Școala de inginerie de sistem (Prime Intellect, Gensyn, Gradient): se concentrează pe construirea următoarei generații de „sisteme de rulare AI”. ShardCast de la Prime Intellect și Parallax de la Gradient sunt concepute pentru a extrage eficiența maximă a clustrelor heterogene prin metode extreme de inginerie, în condițiile existente ale rețelei.
Școala de jocuri de piață (Bittensor, Fraction AI): se concentrează pe proiectarea funcțiilor de recompensă (Reward Function). Prin proiectarea unor mecanisme de evaluare ingenioase, se ghidează minerii să caute în mod spontan cele mai bune strategii, accelerând astfel emergența inteligenței.
Avantaje, provocări și perspective finale
În paradigma combinării învățării prin întărire și Web3, avantajele la nivel de sistem se reflectă în primul rând în restructurarea structurii de costuri și a structurii de guvernare.
Restructurarea costurilor: cererea de Rollout-uri în antrenarea post-RL (Post-training) este infinită, Web3 poate activa puterea de calcul globală a cozii lungi la costuri extrem de reduse, un avantaj de cost pe care furnizorii centralizați de cloud nu-l pot egala.
Alinierea suverană (Sovereign Alignment): ruperea monopolului marilor companii asupra valorilor AI (Alignment), comunitatea poate decide prin voturi token ce înseamnă „un răspuns bun” pentru model, democratizând guvernarea AI.
Între timp, acest sistem se confruntă și cu două constrângeri structurale majore.
Bandwidth Wall: Deși există inovații precum DisTrO, întârzierea fizică limitează antrenarea totală a modelelor cu parametri foarte mari (70B+) și în prezent Web3 AI este limitat mai mult la ajustări și inferențe.
Legea Goodhart (Reward Hacking): Într-o rețea foarte stimulată, minerii sunt predispuși să „supra-antreneze” regulile de recompensă (falsificarea scorurilor) în loc să îmbunătățească inteligența reală. Proiectarea unei funcții de recompensă robuste anti-fraudă este o provocare eternă.
Atacuri de tip Byzantine de noduri malefice (BYZANTINE worker): Manipularea activă a semnalelor de antrenare și contaminarea pentru a distruge convergența modelului. Problema principală nu constă în proiectarea continuă a funcțiilor de recompensă anti-fraudă, ci în construirea unor mecanisme cu robustețe împotriva atacurilor.
Îmbinarea învățării prin întărire cu Web3 se bazează în esență pe rescrierea mecanismelor prin care „inteligența este produsă, aliniată și distribuită în valoare”. Calea sa de evoluție poate fi rezumată în trei direcții complementare:
Rețea de antrenare descentralizată: de la minerii de putere de calcul la rețelele de politici, externalizând Rollout-urile paralele și verificabile către GPU-urile globale de lungă durată, concentrându-se pe piața inferenței verificabile pe termen scurt, evoluând pe termen mediu în subrețele de învățare prin întărire clusterizate pe sarcini;
Assetizarea preferințelor și recompenselor: de la muncitorii de etichetare la drepturile de date. Realizarea assetizării preferințelor și recompenselor transformând feedback-ul de înaltă calitate și modelul de recompensă în active de date guvernabile și distribuibile, actualizând „muncitorii de etichetare” în „drepturi de date”.
Evoluția „micii și frumoase” în domenii verticale: în scenarii verticale în care rezultatele sunt verificabile și veniturile cuantificabile, se dezvoltă agenți RL dedicați puternici, cum ar fi executarea strategiilor DeFi, generarea codului, legând direct îmbunătățirea strategiilor de captarea valorii, având șanse să depășească modelele generice închise.
În general, adevărata oportunitate a învățării prin întărire × Web3 nu constă în replicarea unei versiuni descentralizate a OpenAI, ci în rescrierea „relațiilor de producție inteligente”: făcând ca execuția antrenării să devină o piață deschisă de putere de calcul, făcând ca recompensele și preferințele să devină active on-chain guvernabile, astfel încât valoarea adusă de inteligență să nu mai fie concentrată pe platformă, ci să fie redistribuită între antrenori, aliniatori și utilizatori.
Declinare de responsabilitate: Acest articol a fost creat cu ajutorul instrumentelor AI ChatGPT-5 și Gemini 3, autorul a făcut tot posibilul pentru a corecta și asigura informațiile reale și precise, dar nu poate fi evitată complet omisiunea, vă rugăm să ne iertați. Este important de menționat că piața activelor criptografice prezintă adesea o neconcordanță între fundamentul proiectului și performanța prețului în piață. Conținutul acestui articol este destinat doar integrării informațiilor și schimbului academic / de cercetare și nu constituie nicio recomandare de investiție, nici nu ar trebui să fie considerat un sfat de cumpărare sau vânzare pentru vreun token.