Autor: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Acest raport de cercetare independent este susținut de IOSG Ventures. Procesul de cercetare și scriere a fost inspirat de munca lui Sam Lehman (Pantera Capital) în învățarea prin întărire. Mulțumiri lui Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare și Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang pentru sugestiile lor valoroase cu privire la acest articol. Acest articol aspiră la obiectivitate și acuratețe, dar unele puncte de vedere implică judecăți subiective și pot conține prejudecăți. Apreciem înțelegerea cititorilor.
Inteligența artificială se îndreaptă de la învățarea statistică bazată pe modele către sisteme de raționare structurate, cu post-antrenamentul—în special învățarea prin recompensă—devenind centrală pentru scalarea capacităților. DeepSeek-R1 semnalează o schimbare de paradigmă: învățarea prin recompensă îmbunătățește acum demonstrabil profunzimea raționării și luarea deciziilor complexe, evoluând de la un simplu instrument de aliniere la un traseu continuu de îmbunătățire a inteligenței.
În paralel, Web3 transformă producția AI prin calcul descentralizat și stimulente criptografice, a căror verificabilitate și coordonare se aliniază natural cu nevoile învățării prin recompensă. Acest raport examinează paradigmele de antrenament AI și fundamentele învățării prin recompensă, evidențiază avantajele structurale ale "Învățării prin Recompensă × Web3" și analizează Prime Intellect, Gensyn, Nous Research, Gradient, Grail și Fraction AI.
I. Trei Etape ale Antrenamentului AI
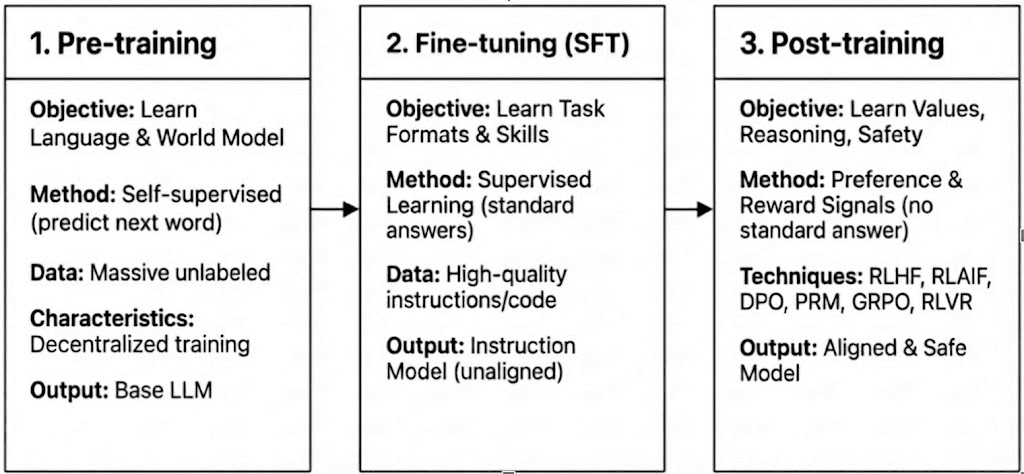
Antrenamentul modern LLM se desfășoară pe trei etape—pre-antrenament, ajustare fină supervizată (SFT) și post-antrenament/învățare prin recompensă—corespunzând construirii unui model de lume, injectării capabilităților de sarcină și modelării raționării și valorilor. Caracteristicile lor computaționale și de verificare determină cât de compatibile sunt cu descentralizarea.
Pre-antrenament: stabilește fundațiile statistice și multimodale de bază prin învățare auto-supervizată masivă, consumând 80–95% din costul total și necesită clustere GPU omogene și sincronizate strâns și acces la date cu lățime de bandă mare, făcându-l intrinsec centralizat.
Ajustare Fină Supervizată (SFT): adaugă capabilități de sarcină și instrucțiune cu seturi de date mai mici și costuri mai reduse (5–15%), folosind adesea metode PEFT precum LoRA sau Q-LoRA, dar depinde încă de sincronizarea gradientelor, limitând descentralizarea.
Post-antrenament: Post-antrenamentul constă din multiple etape iterative care formează capacitatea de raționare a unui model, valorile sale și limitele de siguranță. Include atât abordări bazate pe RL (de exemplu, RLHF, RLAIF, GRPO), optimizarea preferințelor fără RL (de exemplu, DPO), și modelele de recompensă de proces (PRM). Cu cerințe mai mici de date și costuri (aproximativ 5–10%), computația se concentrează pe desfășurări și actualizări ale politicii. Suportul său nativ pentru execuția asincronă, distribuită—adesea fără a necesita greutăți complete ale modelului—face ca post-antrenamentul să fie faza cel mai bine adaptată pentru rețelele de antrenament descentralizate bazate pe Web3, combinate cu calcul verificabil și stimulente pe blockchain.
II. Peisajul Tehnologic al Învățării prin Recompensă
2.1 Arhitectura Sistemului de Învățare prin Recompensă
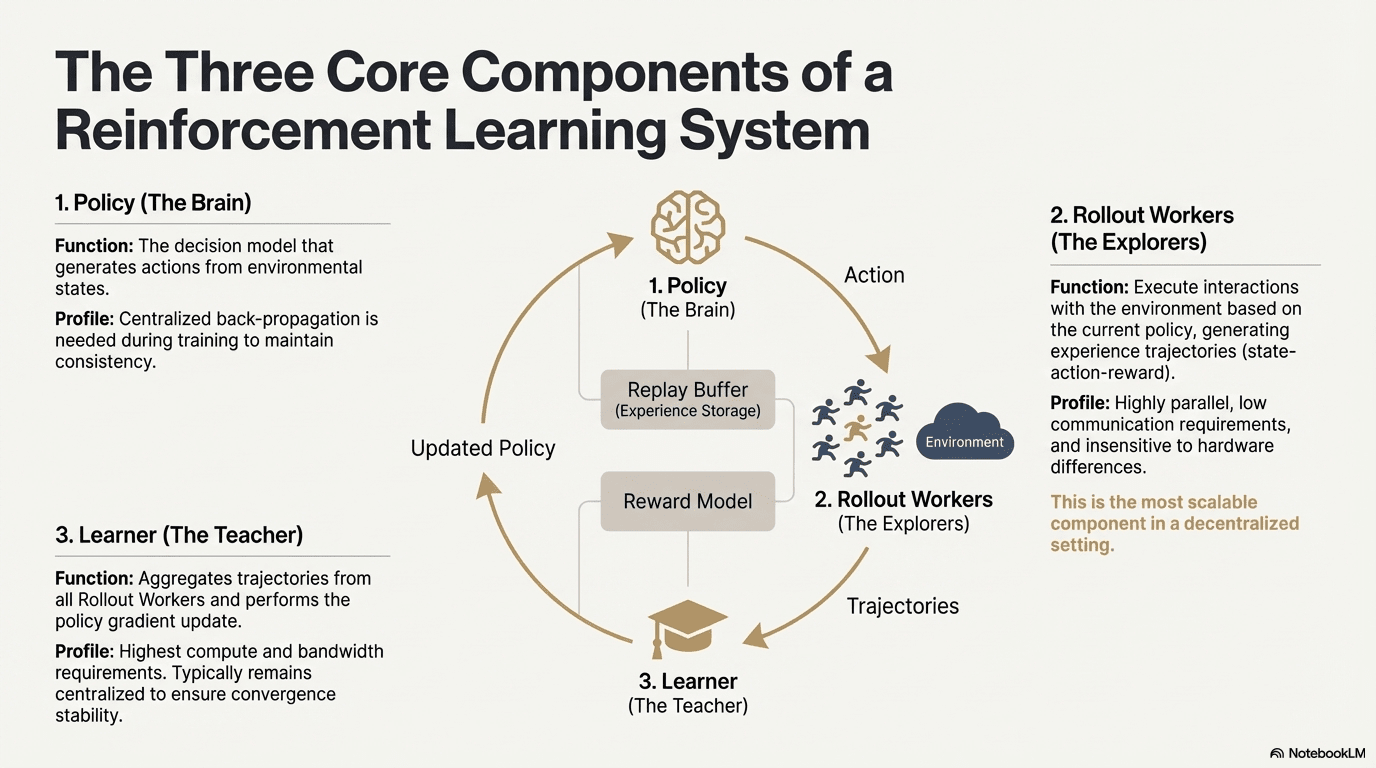
Învățarea prin recompensă permite modelelor să îmbunătățească luarea deciziilor printr-o buclă de feedback a interacțiunii cu mediu, semnale de recompensă și actualizări ale politicii. Structurally, un sistem RL constă din trei componente de bază: rețeaua de politică, desfășurarea pentru eșantionarea experienței și învățătorul pentru optimizarea politicii. Politica generează traiectorii prin interacțiunea cu mediu, în timp ce învățătorul actualizează politica pe baza recompenselor, formând un proces continuu de învățare iterativă.
Rețeaua de Politică (Politica): Generează acțiuni din stările de mediu și este nucleul decizional al sistemului. Necesită o propagare înapoi centralizată pentru a menține coerența în timpul antrenamentului; în timpul inferenței, poate fi distribuită la diferite noduri pentru operare paralelă.
Eșantionarea Experienței (Desfășurare): Nodurile execută interacțiuni cu mediu bazate pe politică, generând traiectorii de stare-acțiune-recompensă. Acest proces este extrem de paralel, are o comunicare extrem de scăzută, este insensibil la diferențele hardware și este cel mai potrivit component pentru expansiunea în descentralizare.
Învățător: Agregă toate traiectoriile desfășurării și execută actualizările gradientului politic. Este singurul modul cu cele mai mari cerințe pentru puterea de calcul și lățimea de bandă, așa că este de obicei păstrat centralizat sau ușor centralizat pentru a asigura stabilitatea convergenței.
2.2 Cadru de Etapă pentru Învățarea prin Recompensă
Învățarea prin recompensă poate fi de obicei împărțită în cinci etape, iar procesul general este următorul:
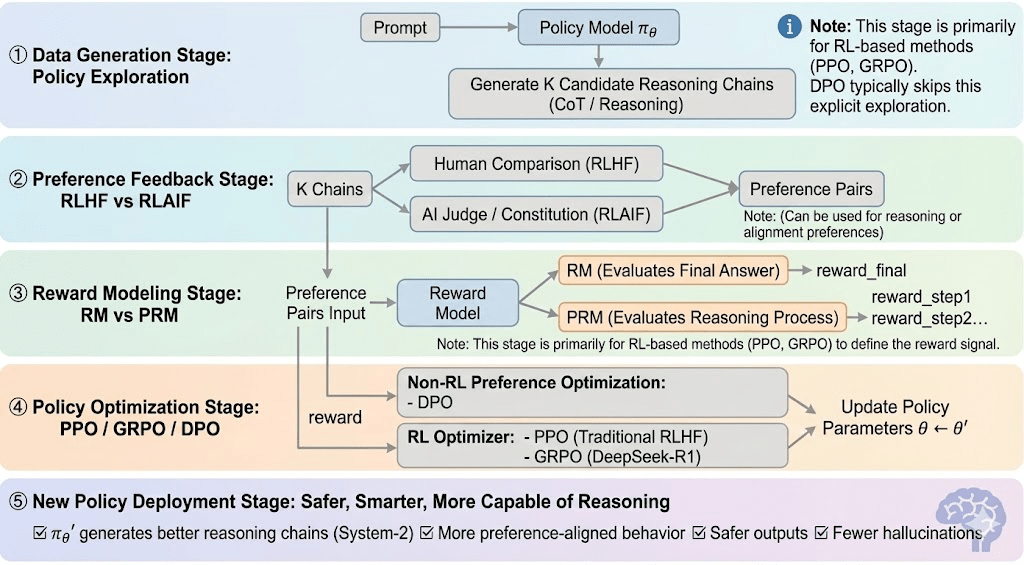
Stadiul Generării de Date (Explorarea Politicii): Dând o solicitare, politica eșantionează multiple lanțuri de raționare sau traiectorii, furnizând candidați pentru evaluarea preferințelor și modelarea recompenselor și definind domeniul de explorare a politicii.
Stadiul Feedback-ului Preferințelor (RLHF / RLAIF):
RLHF (Învățarea prin Recompensă din Feedback Uman): antrenează un model de recompensă din preferințele umane și apoi folosește RL (de obicei PPO) pentru a optimiza politica pe baza acelui semnal de recompensă.
RLAIF (Învățarea prin Recompensă din Feedback AI): înlocuiește oamenii cu judecători AI sau reguli constituționale, reducând costurile și scalând alinierea—acum abordarea dominantă pentru Anthropic, OpenAI și DeepSeek.
Stadiul Modelării Recompensei (Modelarea Recompensei): Învăță să mappeze output-urile la recompense pe baza perechilor de preferințe. RM învață modelul "care este răspunsul corect," în timp ce PRM învață modelul "cum să raționeze corect."
RM (Modelul Recompensei): Folosit pentru a evalua calitatea răspunsului final, punctând doar output-ul.
Modelul Recompensei Procesului (PRM): punctează raționarea pas cu pas, antrenând efectiv procesul de raționare al modelului (de exemplu, în o1 și DeepSeek-R1).
Verificarea Recompensei (RLVR / Verificabilitatea Recompensei): Un strat de verificare a recompensei restrânge semnalele de recompensă pentru a deriva din reguli reproducibile, fapte de bază sau mecanisme de consens. Acest lucru reduce hacking-ul recompenselor și bias-ul sistemic și îmbunătățește auditabilitatea și robustețea în medii de antrenament deschise și distribuite.
Stadiul Optimizării Politicii (Optimizarea Politicii): Actualizează parametrii politicii $\theta$ sub îndrumarea semnalelor date de modelul de recompensă pentru a obține o politică $\pi_{\theta'}$ cu capabilități de raționare mai puternice, siguranță mai mare și modele de comportament mai stabile. Metodele de optimizare principale includ:
PPO (Optimizarea Politicii Proximală): optimizerul standard RLHF, apreciat pentru stabilitate dar limitat de convergența lentă în raționare complexă.
GRPO (Optimizarea Politicii Relative de Grup): introdus de DeepSeek-R1, optimizează politicile folosind estimări de avantaj la nivel de grup mai degrabă decât simple clasificări, păstrând magnitudinea valorii și permițând o optimizare mai stabilă a lanțului de raționare.
DPO (Optimizarea Preferințelor Directe): ocolește RL prin optimizarea direct pe perechile de preferințe—ieftin și stabil pentru aliniere, dar ineficient în îmbunătățirea raționării.
Stadiul de Implementare a Noii Politici (Implementarea Noii Politici): modelul actualizat arată raționare mai puternică de tip Sistem-2, o aliniere mai bună a preferințelor, mai puține halucinații și o siguranță mai mare și continuă să se îmbunătățească prin bucle de feedback iterative.

2.3 Aplicații Industriale ale Învățării prin Recompensă
Învățarea prin Recompensă (RL) a evoluat de la inteligența timpurie a jocurilor la un cadru de bază pentru luarea deciziilor autonome în întreaga industrie. Scenariile sale de aplicare, bazate pe maturitatea tehnologică și implementarea industrială, pot fi rezumate în cinci mari categorii:
Joc & Strategie: Direcția cea mai timpurie în care RL a fost verificat. În medii cu "informații perfecte + recompense clare" precum AlphaGo, AlphaZero, AlphaStar și OpenAI Five, RL a demonstrat inteligența decizională comparabilă sau superioară experților umani, punând bazele algoritmilor RL moderni.
Robotica & AI Încorporați: Prin control continuu, modelarea dinamicii și interacțiunea cu mediu, RL permite roboților să învețe manipularea, controlul mișcării și sarcinile cross-modal (de exemplu, RT-2, RT-X). Se îndreaptă rapid spre industrializare și este o cale tehnică cheie pentru desfășurarea roboților în lumea reală.
Raționare Digitală / Sistem-2 LLM: RL + PRM conduce modele mari de la "imitația limbajului" la "raționarea structurat." Realizările reprezentative includ DeepSeek-R1, OpenAI o1/o3, Anthropic Claude și AlphaGeometry. Practic, efectuează optimizarea recompenselor la nivelul lanțului de raționare, nu doar evaluând răspunsul final.
Descoperire Științifică & Optimizarea Matematică: RL găsește structuri sau strategii optime în spații de recompensă etichetate fără, complexe și uriașe. A realizat progrese fundamentale în AlphaTensor, AlphaDev și Fusion RL, arătând capacități de explorare dincolo de intuiția umană.
Decizii Economice & Tranzacționare: RL este folosit pentru optimizarea strategiilor, controlul riscurilor de înaltă dimensiune, și generarea sistemelor de tranzacționare adaptive. Comparativ cu modelele cantitative tradiționale, poate învăța continuu în medii incerte și este o componentă importantă a finanțelor inteligente.
III. Potrivire Naturală Între Învățarea prin Recompensă și Web3
Învățarea prin recompensă și Web3 sunt aliniate natural ca sisteme conduse de stimulente: RL optimizează comportamentul prin recompense, în timp ce blockchain-urile coordonează participanții prin stimulente economice. Nevoile de bază ale RL—desfășurări heterogene la scară mare, distribuția recompenselor și execuția verificabilă—se aliniază direct cu punctele forte structurale ale Web3.
Decuplarea Raționării și Antrenamentului: Învățarea prin recompensă se separă în faze de desfășurare și actualizare: desfășurărilor le sunt costisitoare din punct de vedere computațional, dar ușoare în comunicare și pot rula în paralel pe GPU-uri distribuite pentru consumatori, în timp ce actualizările necesită resurse centralizate cu lățime de bandă mare. Această decuplare permite rețelelor deschise să gestioneze desfășurările cu stimulente tokenizate, în timp ce actualizările centralizate mențin stabilitatea antrenamentului.
Verificabilitate: ZK (Zero-Knowledge) și Dovada învățării oferă mijloace de a verifica dacă nodurile au executat cu adevărat raționarea, rezolvând problema onestității în rețelele deschise. În sarcini deterministe precum raționarea codului și matematic, verificatorii trebuie doar să verifice răspunsul pentru a confirma volumul de muncă, îmbunătățind semnificativ credibilitatea sistemelor RL descentralizate.
Stratul de Stimulente, Mecanism de Producție a Feedback-ului pe Bază de Economie Token: Stimulentele token Web3 pot recompensate direct contribuabilii de feedback RLHF/RLAIF, permițând generarea preferințelor transparentă și fără permisiune, cu staking și slashing impunând calitatea mai eficient decât crowdsourcing-ul tradițional.
Potențial pentru Învățarea prin Recompensă Multi-Agent (MARL): Blockchain-urile formează medii multi-agent deschise, conduse de stimulente, cu stare publică, execuție verificabilă și stimulente programabile, făcându-le un teren de testare natural pentru MARL la scară mare, în ciuda faptului că domeniul este încă la început.
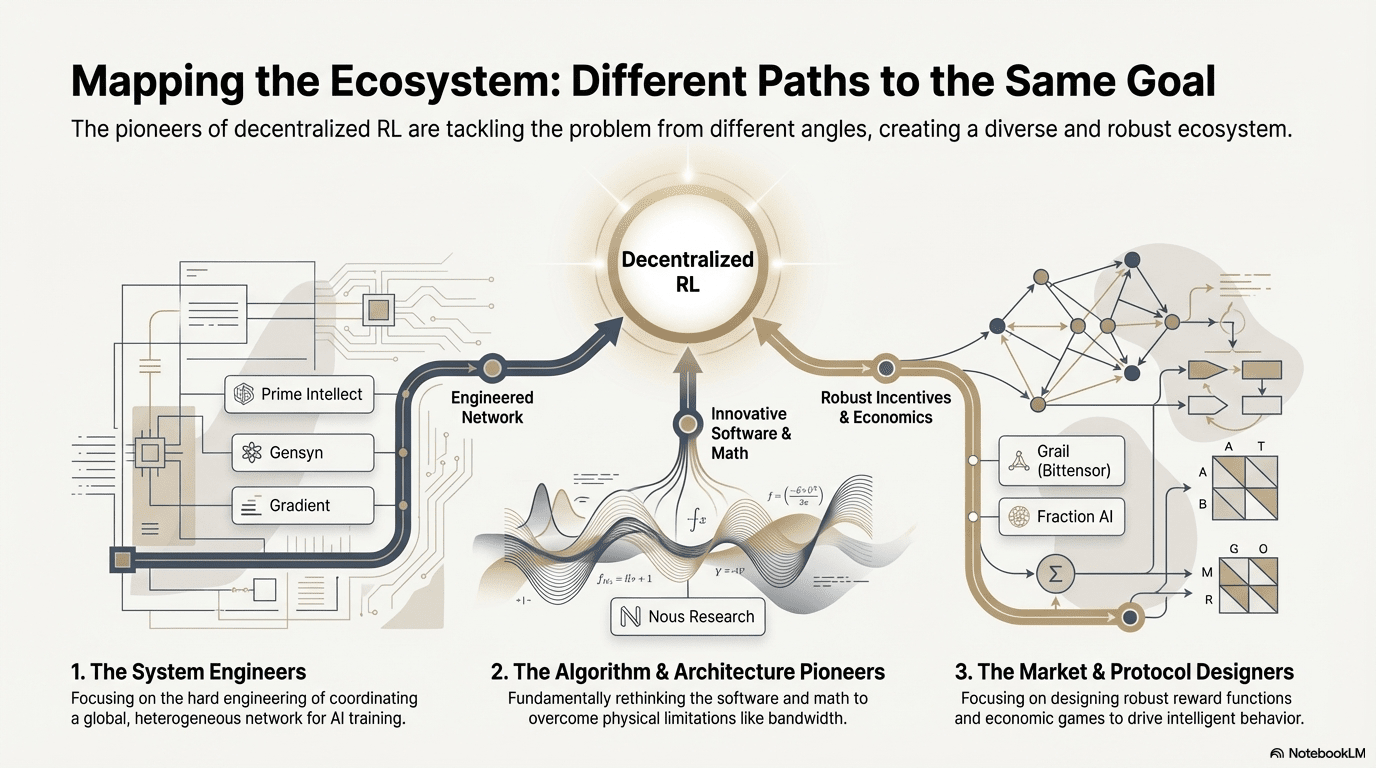
IV. Analiza Proiectelor Web3 + Învățarea prin Recompensă
Pe baza acestui cadru teoretic, vom analiza pe scurt cele mai reprezentative proiecte din ecosistemul actual:
Prime Intellect: Învățare prin Recompensă Asincronă prime-rl
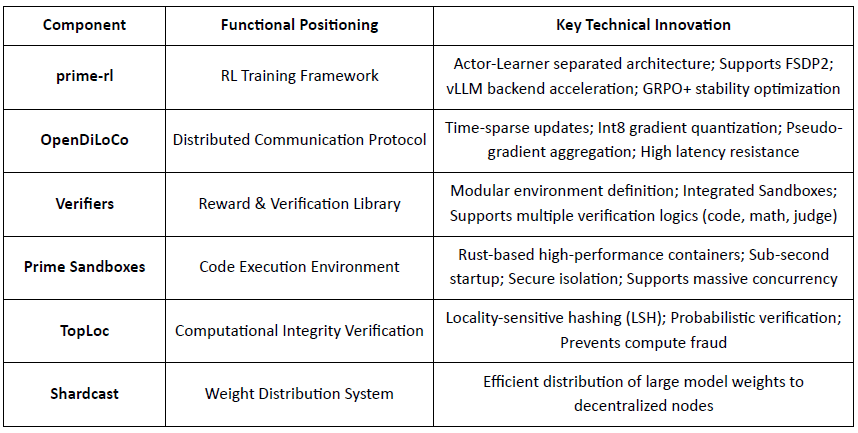
Prime Intellect își propune să construiască o piață globală de calcul deschisă și un stivă de superinteligență open-source, extinzându-se pe Prime Compute, familia de modele INTELLECT, medii RL deschise și motoare de date sintetice la scară mare. Cadrele sale prime-rl sunt concepute special pentru RL distribuit asincron, completate de OpenDiLoCo pentru antrenament eficient din punct de vedere al lățimii de bandă și TopLoc pentru verificare.
Prezentarea Componentelor Infrastructurii Core Prime Intellect
Piatra de temelie tehnică: prime-rl Cadru de Învățare prin Recompensă Asincronă
prime-rl este motorul central de antrenament al lui Prime Intellect, conceput pentru medii descentralizate asincrone la scară mare. Acesta realizează inferență de înalt debit și actualizări stabile prin decuplarea completă Actor–Learner. Executorii (Lucrătorii de Desfășurare) și Învățătorii (Antrenorii) nu se blochează sincron. Nodurile pot adera sau părăsi în orice moment, fiind necesar doar să tragă continuu politica cea mai recentă și să încarce datele generate:
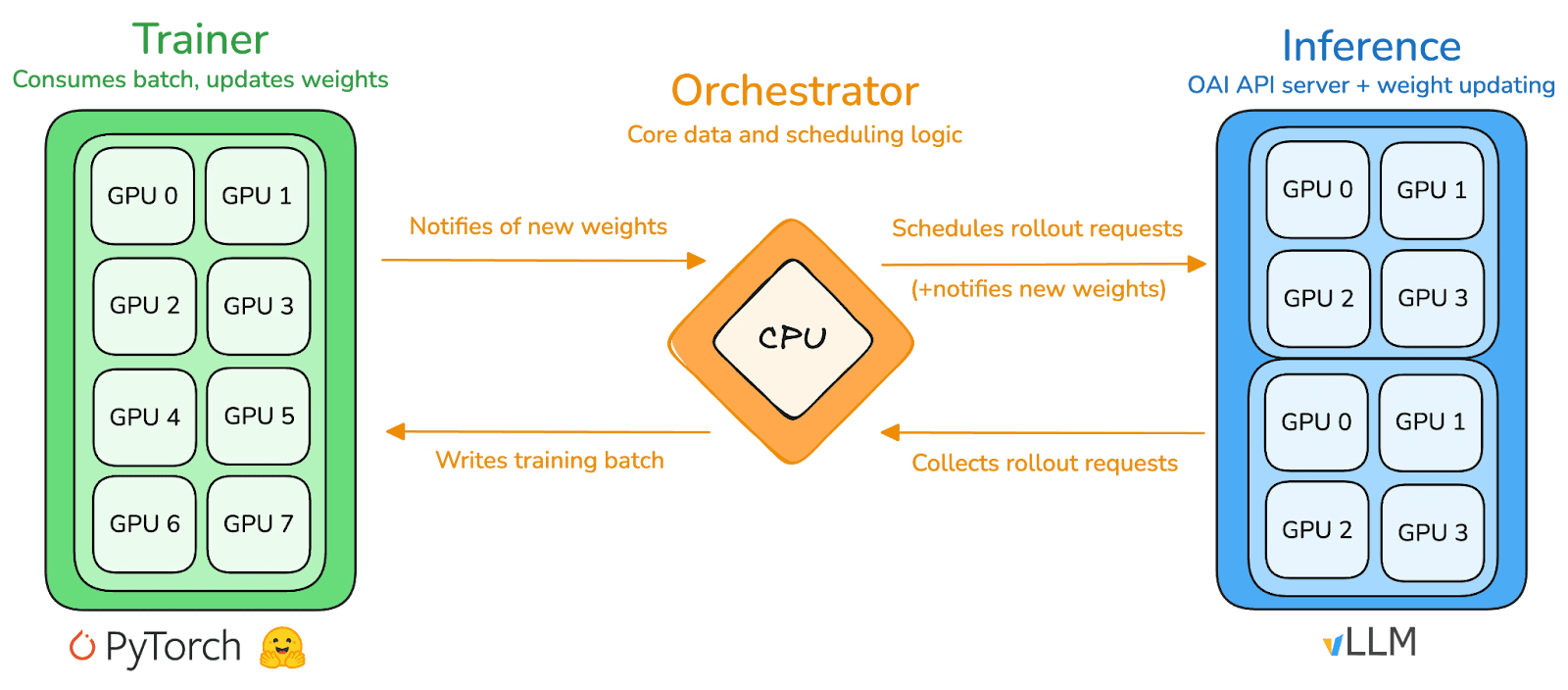
Actor (Lucrători de Desfășurare): Responsabili pentru inferența modelului și generarea de date. Prime Intellect a integrat inovativ motorul de inferență vLLM la capătul Actor. Tehnologia PagedAttention a vLLM și capacitatea Continuous Batching permit Actorilor să genereze traiectorii de inferență cu un debit extrem de ridicat.
Învățător (Antrenor): Responsabil pentru optimizarea politicii. Învățătorul trage asincron date din bufferul de experiență partajat pentru actualizări de gradient fără a aștepta ca toți Actorii să finalizeze lotul curent.
Orchestrator: Responsabil pentru programarea greutăților modelului și fluxul de date.
Inovații Cheie ale prime-rl:
Adevărata Asincronitate: prime-rl abandonează paradigma tradițională sincronă a PPO, nu așteaptă nodurile lente și nu necesită alinierea lotului, permițând oricărui număr și performanță de GPU-uri să acceseze în orice moment, stabilind fezabilitatea RL descentralizat.
Integrarea profundă a FSDP2 și MoE: Prin fragmentarea parametrilor FSDP2 și activarea rară MoE, prime-rl permite antrenarea eficientă a modelelor cu zeci de miliarde de parametri în medii distribuite. Actorii rulează doar experții activi, reducând semnificativ costurile VRAM și de inferență.
GRPO+ (Optimizarea Politicii Relative de Grup): GRPO elimină rețeaua Critic, reducând semnificativ computația și suprasarcina VRAM, adaptându-se natural la medii asincrone. GRPO+ al prime-rl garantează o convergență fiabilă în condiții de latență mare prin mecanisme de stabilizare.
Familia Modelului INTELLECT: Un Simbol al Maturității Tehnologiei RL Descentralizate
INTELLECT-1 (10B, Oct 2024): A demonstrat pentru prima dată că OpenDiLoCo poate antrena eficient într-o rețea heterogenă pe trei continente (partea de comunicare < 2%, utilizarea calculului 98%), rupând percepțiile fizice despre antrenamentul trans-regional.
INTELLECT-2 (32B, Apr 2025): Ca primul model RL fără permisiune, validează capacitatea de convergență stabilă a prime-rl și GRPO+ în medii de latență multi-pas și asincrone, realizând RL descentralizat cu participarea globală la calcul deschis.
INTELLECT-3 (106B MoE, Nov 2025): Adoptă o arhitectură rară activând doar 12B de parametri, antrenată pe 512×H200 și obținând performanțe de inferență de vârf (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, etc.). Performanța generală se apropie sau depășește modelele centralizate cu sursă închisă de mult mai mari decât ea însăși.
Prime Intellect a construit un stivă RL complet descentralizată: OpenDiLoCo reduce traficul de antrenament trans-regional cu ordine de magnitudine în timp ce menține ~98% utilizare pe continente; TopLoc și Verificatorii asigură inferența și datele de recompensă de încredere prin amprente de activare și verificare în sandbox; iar motorul de date SINTHETIC generează lanțuri de raționare de înaltă calitate în timp ce permite modelelor mari să ruleze eficient pe GPU-uri de consum prin paralelism de pipeline. Împreună, aceste componente susțin generarea de date scalabilă, verificarea și inferența în RL descentralizat, seria INTELLECT demonstrând că astfel de sisteme pot livra modele de clasă mondială în practică.
Gensyn: Stiva de bază RL Swarm și SAPO
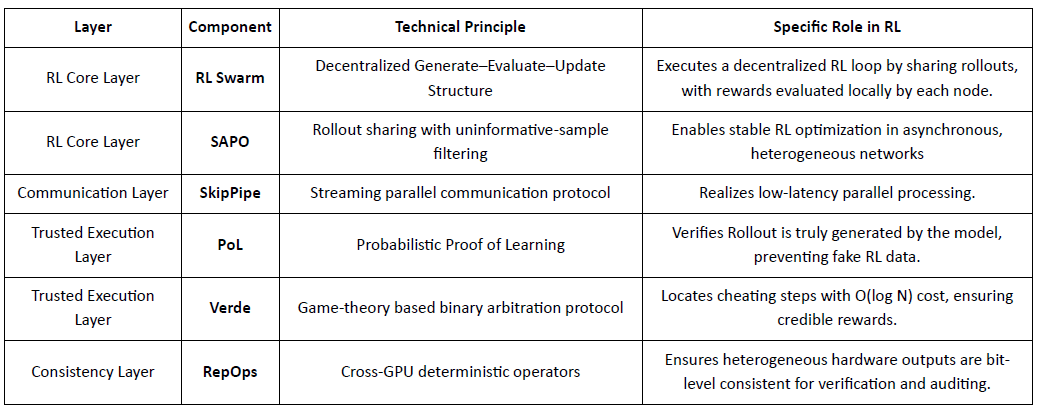
Gensyn caută să unească calculul global inutilizat într-o rețea de antrenament AI descentralizată, scalabilă, combinând execuția standardizată, coordonarea P2P și verificarea sarcinilor pe blockchain. Prin mecanisme precum RL Swarm, SAPO și SkipPipe, decuplează generarea, evaluarea și actualizările între GPU-uri heterogene, oferind nu doar calcul, ci și inteligență verificabilă.
Aplicații RL în Stiva Gensyn
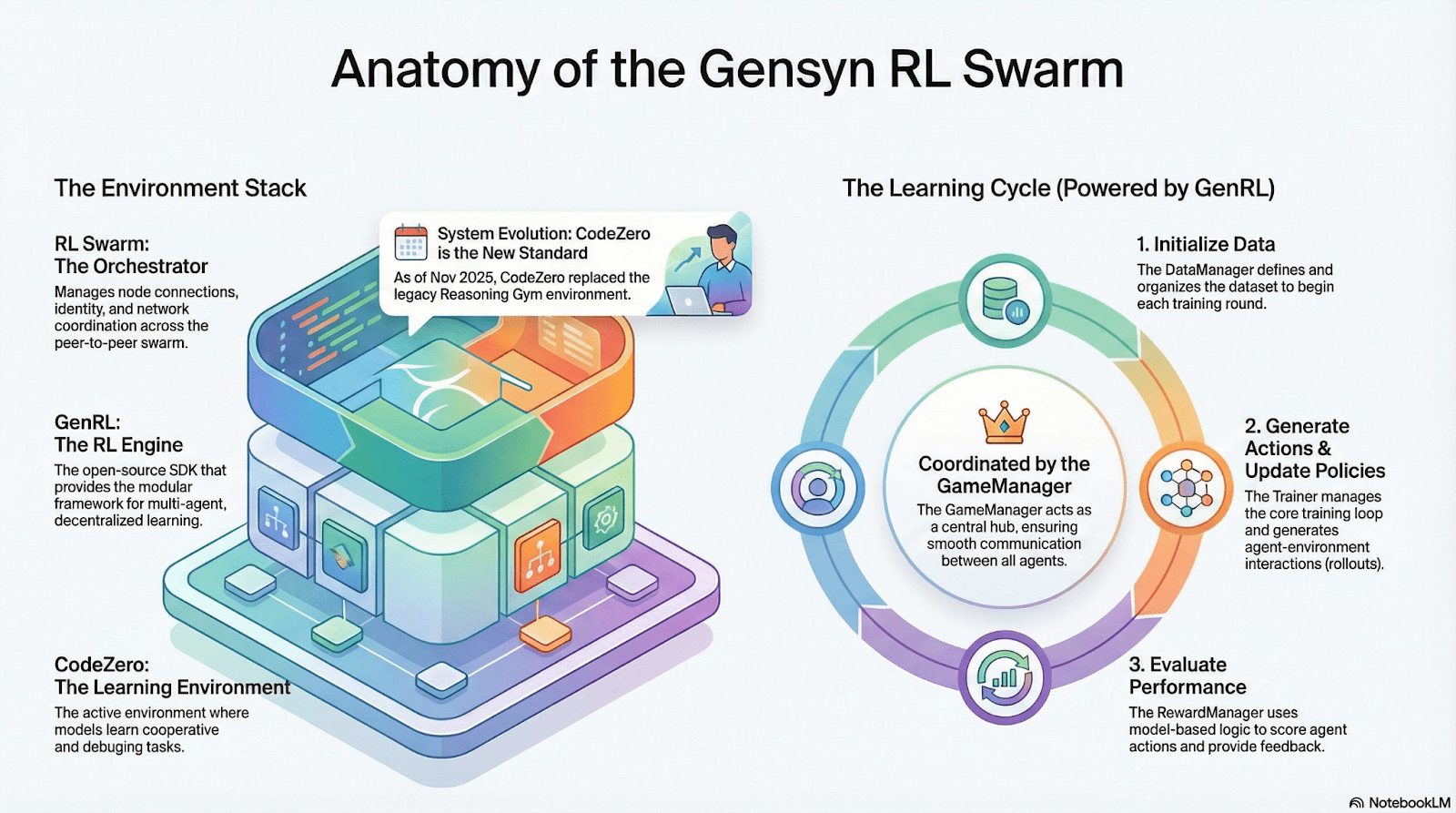
RL Swarm: Motor de Învățare prin Recompensă Colaborativă Descentralizată
RL Swarm demonstrează un mod nou de colaborare. Nu mai este vorba doar de distribuirea sarcinilor, ci de un ciclu infinit de generare–evaluare–actualizare descentralizat inspirat de învățarea colaborativă care simulează învățarea socială umană:
Executori (Executanți): Responsabili pentru inferența locală a modelului și generarea desfășurărilor, fără a fi împiedicați de heterogenitatea nodurilor. Gensyn integrează motoare de inferență cu debit mare (precum CodeZero) local pentru a produce traiectorii complete, nu doar răspunsuri.
Propozanți: Generează dinamic sarcini (probleme matematice, întrebări de cod etc.), permițând diversitate în sarcini și adaptarea de tip curriculum pentru a adapta dificultatea antrenamentului la capabilitățile modelului.
Evaluatori: Folosesc "Modele Judecătorî Congelate" sau reguli pentru a verifica calitatea output-ului, formând semnale de recompensă locale evaluate independent de fiecare nod. Procesul de evaluare poate fi auditat, reducând locul pentru răutate.
Cele trei formează o structură organizațională P2P RL care poate finaliza învățarea colaborativă la scară mare fără programare centralizată.
SAPO: Algoritm de Optimizare a Politicii Reconstruit pentru Descentralizare
SAPO (Optimizarea Politicii de Eșantionare a Swarm-ului) se concentrează pe partajarea desfășurărilor în timp ce filtrează cele fără semnal de gradient, mai degrabă decât să împărtășească gradientele. Prin facilitarea eșantionării desfășurărilor descentralizate la scară mare și tratând desfășurărilor primite ca fiind generate local, SAPO menține convergența stabilă în medii fără coordonare centrală și cu heterogenitate semnificativă a latenței nodurilor. Comparativ cu PPO (care se bazează pe o rețea critică care domină costul computațional) sau GRPO (care se bazează pe estimarea avantajului la nivel de grup mai degrabă decât pe clasificarea simplă), SAPO permite GPU-urilor de consum să participe eficient la optimizarea RL la scară mare cu cerințe extrem de scăzute de lățime de bandă.
Prin RL Swarm și SAPO, Gensyn demonstrează că învățarea prin recompensă—în special post-antrenamentul RLVR—se potrivește natural arhitecturilor descentralizate, deoarece depinde mai mult de explorarea diversă prin desfășurări decât de sincronizarea parametrilor cu frecvență înaltă. Combinat cu sistemele de verificare PoL și Verde, Gensyn oferă o cale alternativă către antrenarea modelelor cu trilioane de parametri: o rețea de superinteligență auto-evolutivă compusă din milioane de GPU-uri heterogene din întreaga lume.
Nous Research: Mediu de Învățare prin Recompensă Atropos
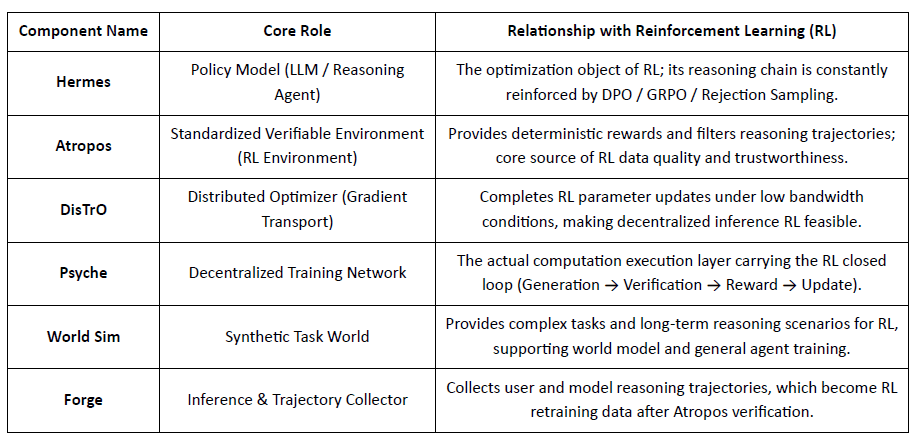
Nous Research construiește un stivă cognitivă descentralizată, auto-evolutivă, unde componentele precum Hermes, Atropos, DisTrO, Psyche și World Sim formează un sistem de inteligență în buclă închisă. Folosind metode RL precum DPO, GRPO și eșantionarea de respingere, înlocuiește conductele de antrenament liniare cu feedback continuu între generarea de date, învățare și inferență.
Prezentarea Componentelor Nous Research
Stratul Model: Hermes și Evoluția Capacităților de Raționare
Seria Hermes este principala interfață model a Nous Research pentru utilizatori. Evoluția sa demonstrează clar calea industriei migrând de la alinierea tradițională SFT/DPO la RL de Raționare:
Hermes 1–3: Alinierea Instrucțiunilor & Capabilitățile Timpurii ale Agenților: Hermes 1–3 s-a bazat pe DPO cu costuri reduse pentru alinierea robustă a instrucțiunilor și a folosit date sintetice și prima introducere a mecanismelor de verificare Atropos în Hermes 3.
Hermes 4 / DeepHermes: Scrie gândirea lentă de tip Sistem-2 în greutăți prin Chain-of-Thought, îmbunătățind performanța matematică și a codului cu Test-Time Scaling, și bazându-se pe "Rejection Sampling + Verificarea Atropos" pentru a construi date de raționare de înaltă puritate.
DeepHermes adoptă în continuare GRPO pentru a înlocui PPO (care este greu de implementat în principal), permițând RL-ul de Raționare să ruleze pe rețeaua GPU descentralizată Psyche, punând baza ingineriei pentru scalabilitatea RL-ului de Raționare open-source.
Atropos: Mediu de Învățare prin Recompensă Condus de Verificare
Atropos este adevăratul hub al sistemului Nous RL. Acesta încadrează solicitările, apelurile de instrumente, execuția codului și interacțiunile multi-între în medii RL standardizate, verificând direct dacă rezultatele sunt corecte, oferind astfel semnale de recompensă deterministe pentru a înlocui etichetarea umană costisitoare și nescalabilă. Mai important, în rețeaua de antrenament descentralizată Psyche, Atropos acționează ca un "judecător" pentru a verifica dacă nodurile au îmbunătățit într-adevăr politica, susținând dovada audibilă a învățării, rezolvând fundamental problema credibilității recompensei în RL distribuit.
DisTrO și Psyche: Strat de Optimizer pentru Învățarea prin Recompensă Descentralizată
Antrenamentul tradițional RLF (RLHF/RLAIF) se bazează pe clustere centralizate de lățime de bandă mare, o barieră de bază pe care sursa deschisă nu o poate replica. DisTrO reduce costurile de comunicare RL cu ordine de magnitudine prin decuplarea impulsului și comprimarea gradientului, permițând antrenamentul să ruleze pe lățimea de bandă a internetului; Psyche implementează acest mecanism de antrenament pe o rețea pe blockchain, permițând nodurilor să finalizeze inferența, verificarea, evaluarea recompenselor și actualizările greutăților local, formând o buclă completă RL închisă.
În sistemul Nous, Atropos verifică lanțurile de gândire; DisTrO comprimă comunicarea antrenamentului; Psyche rulează bucla RL; World Sim oferă medii complexe; Forge colectează raționarea reală; Hermes scrie toată învățarea în greutăți. Învățarea prin recompensă nu este doar o etapă de antrenament, ci protocolul central care leagă datele, mediu, modelele și infrastructura în arhitectura Nous, făcând din Hermes un sistem viu capabil de auto-îmbunătățire continuă pe o rețea de calcul deschisă.
Rețea Gradient: Arhitectura Învățării prin Recompensă Echo
Rețeaua Gradient își propune să reconstruiască calculul AI printr-un Stivă de Inteligență Deschisă: un set modular de protocoale interoperabile care se extind la comunicarea P2P (Lattica), inferență distribuită (Parallax), antrenament RL descentralizat (Echo), verificare (VeriLLM), simulare (Mirage) și coordonare a memoriei și agenților la nivel superior—formând împreună o infrastructură de inteligență descentralizată în evoluție.
Echo — Arhitectura de Antrenament a Învățării prin Recompensă
Echo este cadrul de învățare prin recompensă al Gradient. Principiul său de design de bază constă în decuplarea antrenamentului, inferenței și căilor de date (recompensă) în învățarea prin recompensă, rulându-le separat în Swarm-uri de Inferență și Antrenament heterogene, menținând un comportament stabil de optimizare în medii variate și heterogene cu protocoale de sincronizare ușoară. Acest lucru atenuează efectiv eșecurile SPMD și blocajele de utilizare a GPU-urilor cauzate de amestecarea inferenței și antrenamentului în RLHF / VERL tradițional.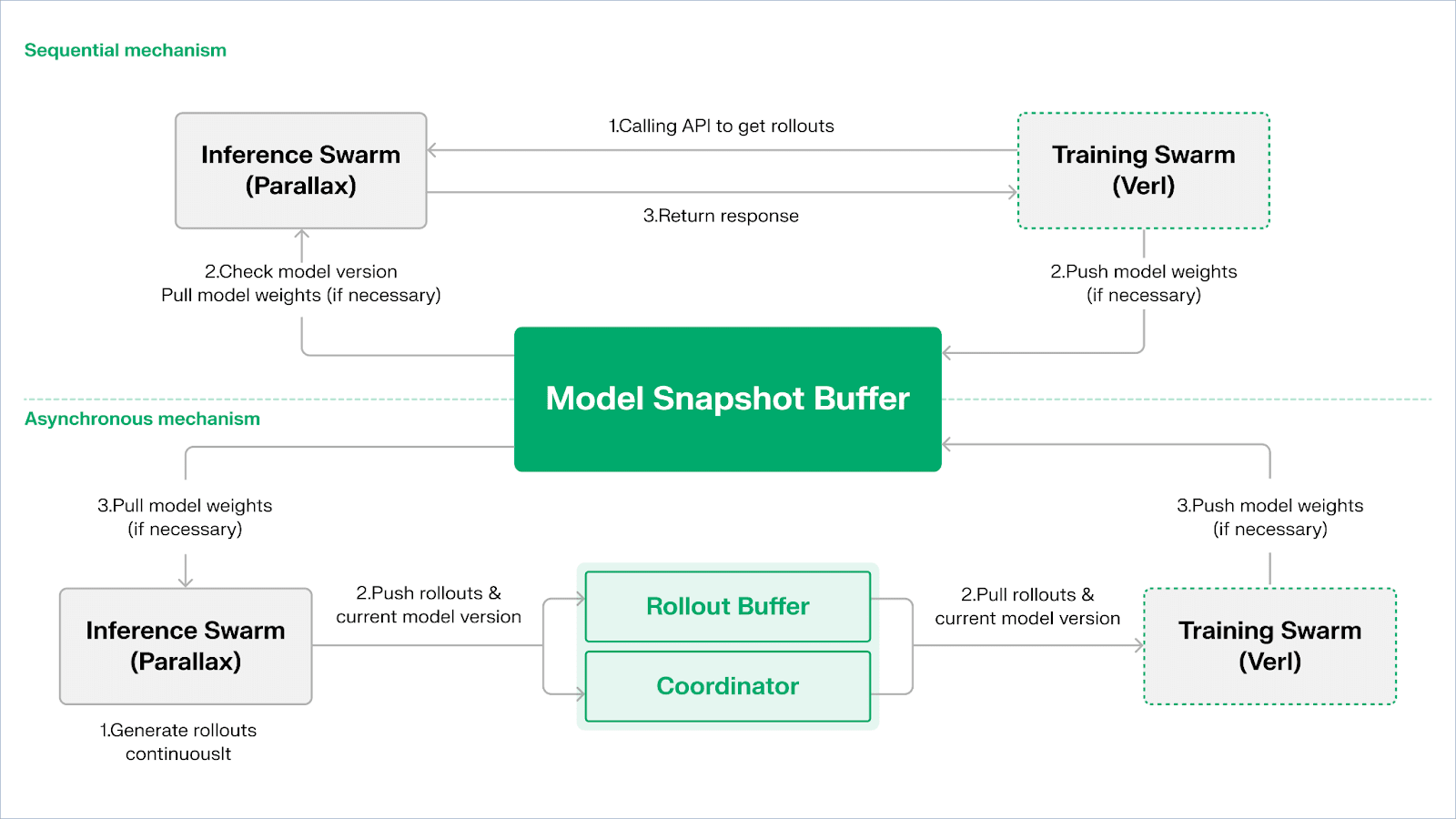
Echo folosește o "Arhitectură Duală de Inferență-Antrenament" pentru a maximiza utilizarea puterii de calcul. Cele două swarm-uri rulează independent fără a se bloca reciproc:
Maximizează Debitul de Eșantionare: Swarm-ul de Inferență constă din GPU-uri de consum și dispozitive edge, construind eșantionatoare de înalt debit prin paralele de pipeline cu Parallax, concentrându-se pe generarea traiectoriilor.
Maximizează Puterea de Calcul a Gradientului: Swarm-ul de Antrenament poate rula pe clustere centralizate sau pe rețele globale distribuite de GPU-uri de consum, responsabil pentru actualizările gradientului, sincronizarea parametrilor, și ajustarea LoRA, concentrându-se pe procesul de învățare.
Pentru a menține consistența politicii și a datelor, Echo oferă două tipuri de protocoale de sincronizare ușoară: Secvențial și Asincron, gestionând coerența bidirecțională a greutăților politicii și traiectoriilor:
Modul de Extracție Secvențială (Acuratețe Întâi): Partea de antrenament forțează nodurile de inferență să reîmprospăteze versiunea modelului înainte de a extrage noi traiectorii pentru a asigura prospețimea traiectoriilor, potrivit pentru sarcini extrem de sensibile la vechimea politicii.
Modul Asincron de Împingere–Extracție (Eficiență Întâi): Partea de inferență generează continuu traiectorii cu etichete de versiune, iar partea de antrenament le consumă la propriul ritm. Coordonatorul monitorizează deviația versiunii și declanșează reîmprospătările greutăților, maximizând utilizarea dispozitivelor.
La nivelul de bază, Echo este construit pe Parallax (inferență heterogenă în medii cu lățime de bandă redusă) și componente de antrenament distribuit ușoare (de exemplu, VERL), bazându-se pe LoRA pentru a reduce costurile de sincronizare între noduri, permițând învățarea prin recompensă să ruleze stabil pe rețele globale heterogene.
Grail: Învățare prin Recompensă în Ecosistemul Bittensor
Bittensor construiește o rețea uriașă, rară și non-staționară de funcții de recompensă prin mecanismul său unic de consens Yuma.
Covenant AI în ecosistemul Bittensor construiește un pipeline integrat vertical de la pre-antrenament la post-antrenament RL prin SN3 Templar, SN39 Basilica, și SN81 Grail. Dintre acestea, SN3 Templar este responsabil pentru pre-antrenamentul modelului de bază, SN39 Basilica furnizează o piață de putere de calcul distribuită, iar SN81 Grail servește ca "strat de inferență verificabil" pentru post-antrenamentul RL, purtând procesele de bază ale RLHF / RLAIF și completând optimizarea în buclă închisă de la modelul de bază la politica aliniată.

GRAIL verifică criptografic desfășurările RL și le leagă de identitatea modelului, permițând RLHF fără încredere. Folosește provocări deterministe pentru a preveni pre-computarea, eșantionarea de cost redus și angajamentele pentru a verifica desfășurările, și amprentele modelului pentru a detecta substituția sau reîncercarea—stabilind autenticitatea de la un capăt la altul pentru traiectele de inferență RL.
Subrețeaua Grail implementează o buclă de post-antrenament de tip GRPO verificabil: minerii produc multiple căi de raționare, validatorii evaluează corectitudinea și calitatea raționării, iar rezultatele normalizate sunt scrise pe blockchain. Testele publice au crescut acuratețea Qwen2.5-1.5B MATH de la 12.7% la 47.6%, demonstrând atât rezistența la înșelăciune cât și câștigurile puternice de capacitate; în Covenant AI, Grail servește ca nucleu de încredere și execuție pentru RLVR/RLAIF descentralizat.
Fraction AI: Învățare prin Recompensă Bazată pe Competiție RLFC
Fraction AI reformulează alinierea ca Învățare prin Recompensă din Competiție, folosind etichetarea gamificată și concursuri agent-versus-agent. Clasificările relative și scorurile judecătorilor AI înlocuiesc etichetele umane statice, transformând RLHF într-un joc continuu, competitiv, multi-agent.
Diferențe Cheie Între RLHF Tradițional și RLFC al Fraction AI:
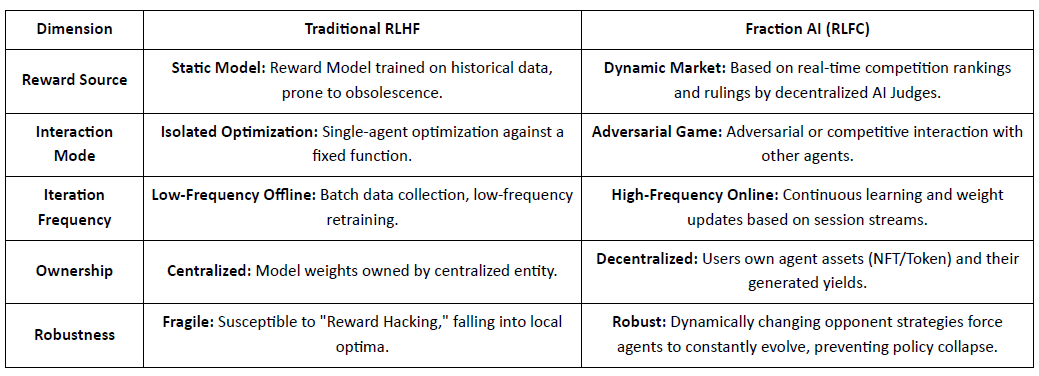
Valoarea de bază a RLFC este că recompensele provin din adversari și evaluatori evoluând, nu dintr-un singur model, reducând hacking-ul recompenselor și păstrând diversitatea politicii. Proiectarea spațiului modelează dinamica jocului, permițând comportamente complexe competitive și cooperative.
În arhitectura sistemului, Fraction AI descompune procesul de antrenament în patru componente cheie:
Agenti: Unități de politică ușoare bazate pe LLM-uri open-source, extinse prin QLoRA cu greutăți diferențiale pentru actualizări cu costuri reduse.
Spații: Medii de domeniu de sarcini izolate unde agenții plătesc pentru a intra și câștigă recompense prin câștig.
Judecători AI: Strat de recompensă imediat construit cu RLAIF, oferind evaluări descentralizate și scalabile.
Dovada învățării: Leagă actualizările politicii de rezultate specifice ale competiției, asigurând că procesul de antrenament este verificabil și rezistent la înșelăciune.
Fraction AI funcționează ca un motor de co-evoluție uman–mașină: utilizatorii acționează ca meta-optimizatori ghidând explorarea, în timp ce agenții concurează pentru a genera date de preferință de înaltă calitate, facilitând ajustările comerciale fără încredere.
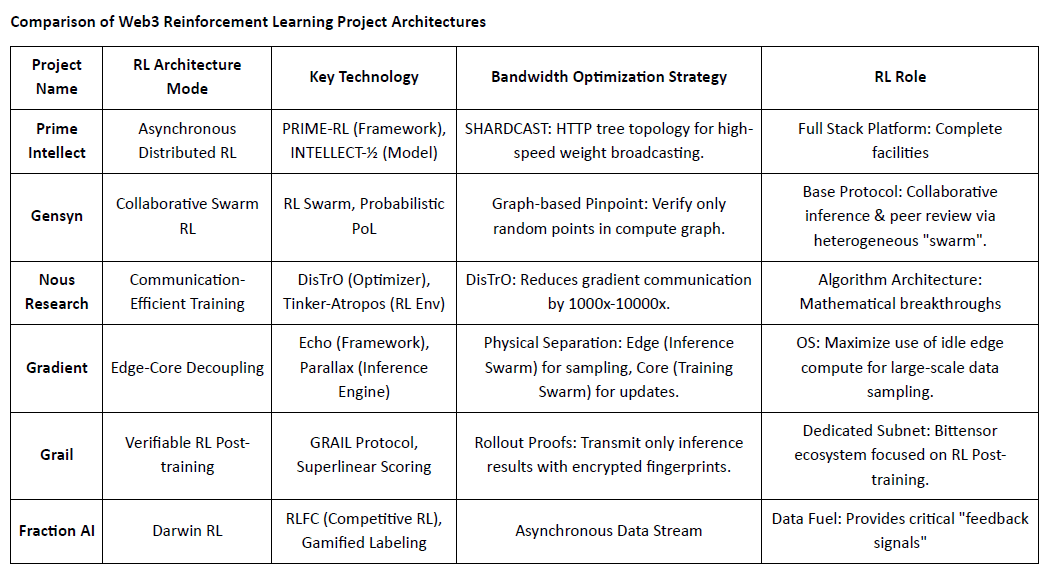
Compararea Arhitecturilor Proiectelor de Învățare prin Recompensă Web3
V. Calea și Oportunitatea Învățării prin Recompensă × Web3
În aceste proiecte de frontieră, în ciuda punctelor de intrare diferite, RL combinat cu Web3 converge constant la o arhitectură comună "decuplare–verificare–stimulare"—un rezultat inevitabil al adaptării învățării prin recompensă la rețelele descentralizate.
Caracteristici Generale ale Arhitecturii Învățării prin Recompensă: Rezolvarea Limitelor Fizice de Bază și Problemelor de Încredere
Decuplarea desfășurărilor & Învățării (Separarea Fizică a Inferenței/Antrenamentului) — Topologia de Calcul Implicită: Desfășurările sparse, paralelizabile sunt externalizate către GPU-uri de consum global, în timp ce actualizările parametrilor cu lățime de bandă mare sunt concentrate în câteva noduri de antrenament. Acest lucru este adevărat de la Actor–Learner-ul asincron al lui Prime Intellect până la arhitectura dual-swarm a Gradient Echo.
Încredere Condusă de Verificare — Infrastructuralizare: În rețelele fără permisiuni, autenticitatea computațională trebuie să fie garantată forțat prin matematică și design de mecanisme. Implementările reprezentative includ PoL-ul Gensyn, TopLoc-ul Prime Intellect și verificarea criptografică a Grail.
Bucla de Stimulente Tokenizate — Autoreglarea Pieței: Oferta de calcul, generarea de date, sortarea verificărilor și distribuția recompenselor formează o buclă închisă. Recompensele stimulează participarea, iar Slashing suprimă înșelătoria, menținând rețeaua stabilă și evoluând continuu într-un mediu deschis.
Trasee Tehnice Diferentiate: Diferite "Puncte de Spargere" Sub o Arhitectură Consistentă
Deși arhitecturile converg, proiectele aleg diferite obstacole tehnice în funcție de ADN-ul lor:
Școala de Spargere de Algoritmi (Nous Research): Abordează blocajul de lățime de bandă al antrenamentului distribuit la nivelul optimizerului—DisTrO comprimă comunicarea gradientului cu ordine de magnitudine, având ca scop să permită antrenamentul modelului mare pe lățimea de bandă de acasă.
Școala de Inginerie a Sistemelor (Prime Intellect, Gensyn, Gradient): Se concentrează pe construirea următoarei generații de "Sistem de Rulare AI." ShardCast-ul Prime Intellect și Parallax-ul Gradient sunt concepute pentru a extrage cea mai înaltă eficiență din clusterele heterogene în condițiile existente ale rețelei prin mijloace extreme de inginerie.
Școala Jocurilor de Piață (Bittensor, Fraction AI): Se concentrează pe proiectarea Funcțiilor de Recompensă. Prin proiectarea unor mecanisme sofisticate de punctare, ghidează minerii să găsească spontan strategii optime pentru a accelera apariția inteligenței.
Avantaje, Provocări și Perspective Finale
Sub paradigma Învățării prin Recompensă combinată cu Web3, avantajele la nivel de sistem se reflectă mai întâi în rescrierea structurilor de cost și a structurilor de guvernanță.
Restructurarea Costurilor: Post-antrenamentul RL are o cerere nelimitată pentru eșantionare (Desfășurare). Web3 poate mobiliza puterea de calcul globală de lungă durată la costuri extrem de reduse, un avantaj de cost dificil de egalat de furnizorii de cloud centralizați.
Alinierea Suverană: Rupterea monopolului marilor tehnologii asupra valorilor AI (Alinierea). Comunitatea poate decide "ce este un răspuns bun" pentru model prin vot token, realizând democratizarea guvernanței AI.
În același timp, acest sistem se confruntă cu două constrângeri structurale:
Peretele de Lățime de Bandă: În ciuda inovațiilor precum DisTrO, latența fizică limitează în continuare antrenamentul complet al modelelor cu parametrii ultra-mari (70B+). În prezent, AI Web3 este mai limitat la ajustări și inferență.
Hacking-ul Recompenselor (Legea lui Goodhart): În rețele extrem de stimulate, minerii sunt extrem de predispuși la "suprainvățare" a regulilor recompenselor (jocul sistemului) mai degrabă decât la îmbunătățirea adevăratei inteligențe. Proiectarea funcțiilor de recompensă robuste și rezistente la înșelăciune este un joc etern.
Lucrători Byzantine Malefici: se referă la manipularea deliberată și otrăvirea semnalelor de antrenament pentru a perturba convergența modelului. Provocarea principală nu este proiectarea continuă a funcțiilor de recompensă rezistente la înșelăciune, ci mecanismele cu robustețe adversarială.
RL și Web3 transformă inteligența prin rețele descentralizate de desfășurare, feedback activ pe blockchain și agenți RL verticali cu captare directă a valorii. Adevărata oportunitate nu este un OpenAI descentralizat, ci noi relații de producție a inteligenței—piețe de calcul deschise, recompense și preferințe guvernabile, și valoare partajată între antrenori, aliniatori și utilizatori.
Declinare: Acest articol a fost finalizat cu asistența instrumentelor AI ChatGPT-5 și Gemini 3. Autorul a depus toate eforturile pentru a corecta și a asigura autenticitatea și acuratețea informațiilor, dar omisiunile pot exista în continuare. Vă rugăm să înțelegeți. Trebuie menționat în mod special că piața activelor criptografice experimentează adesea divergențe între fundamentele proiectului și performanța prețurilor pe piața secundară. Conținutul acestui articol este pentru integrarea informațiilor și schimbul academic/ de cercetare doar și nu constituie nicio recomandare de investiție și nu ar trebui să fie considerat o recomandare de a cumpăra sau vinde orice token.