
Everyone assumes migrating massive amounts of blob state between committees is a disruptive event that stops the system. Walrus proves you can perform epoch-scale state migrations without blocking a single write. This is infrastructure maturity: the system keeps running while its foundation shifts beneath it.
The State Migration Problem
Here's what makes decentralized storage fragile: committees change. Validators rotate. New validators join. Old validators leave. When this happens at scale—migrating terabytes of blobs from one committee to another—traditional systems have to stop accepting writes while migration completes.
Why? Because you can't reliably guarantee data availability while you're moving it between committees. The old committee might lose track of a blob. The new committee might not have received it yet. In the window between committees, the blob is vulnerable.
Most systems handle this by blocking new writes during migration. No new blobs are accepted until the migration completes. This creates latency spikes and unpredictable system behavior.
Walrus handles this differently. New blobs can be written continuously while state migration happens in the background.
The Two-Committee Architecture
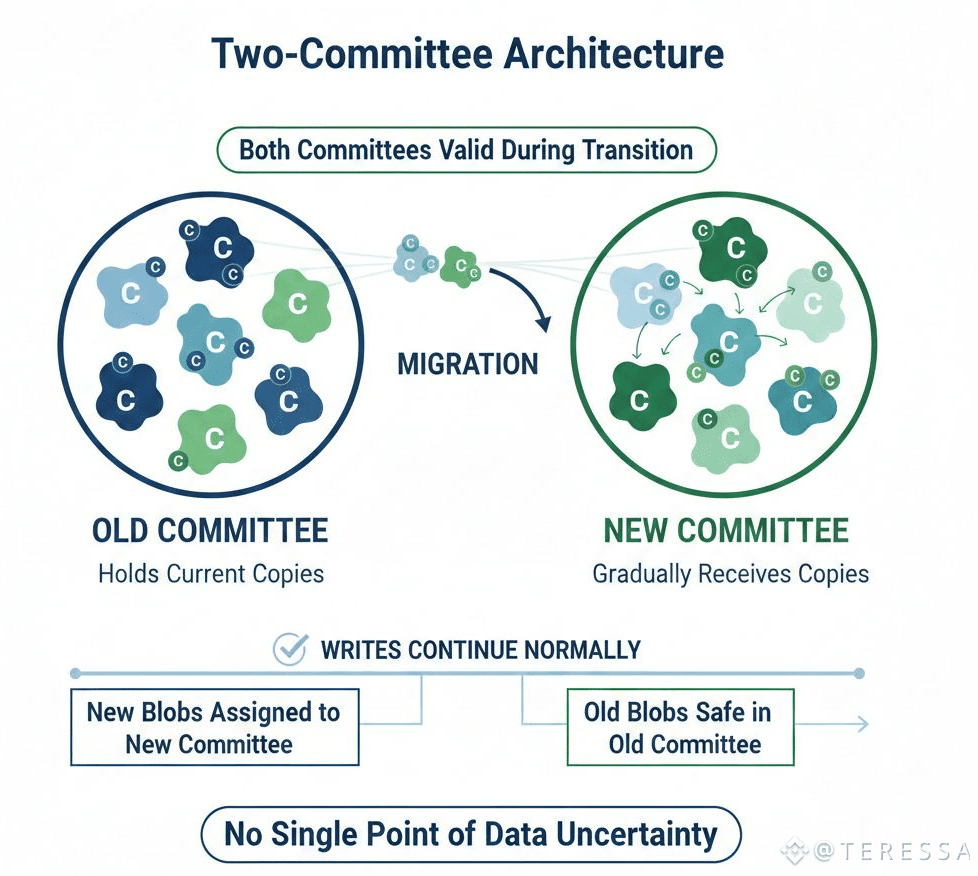
Walrus uses an elegant architectural trick: blobs exist in two committees simultaneously during migration. The old committee holds the current copies. The new committee gradually receives copies. Both committees are valid during the transition.
This means writes can continue normally. New blobs are assigned to the new committee. Old blobs are safe in the old committee while copies propagate to the new one. The system never has a single point where data availability is uncertain.
The migration is transparent to writers. They don't know or care that committees are changing. They write blobs and they're stored safely.
Staged Migration Strategy
State migration doesn't happen all at once. It's staged across epochs. Each epoch, a fraction of the blobs migrate from the old committee to the new one. This spreading prevents sudden massive data transfers that would cause congestion.
In epoch 1, the first batch of blobs begins replication to the new committee. In epoch 2, the second batch starts while the first batch completes. This cascading approach means migration load is distributed smoothly across multiple epochs.
The network never sees a spike of migration traffic that would block normal operations.
Verifiable Handoff
As blobs migrate from old to new committees, the handoff is verifiable on-chain. The old committee cryptographically proves they released custody. The new committee cryptographically proves they received it. The chain records each handoff.
If something goes wrong during migration—a blob is lost in transit, a committee fails to receive it—the on-chain evidence makes it clear. The system can detect and repair migration failures.
No silent data loss. No ambiguity about who's responsible. The handoff is transparent.
New Writes to New Committee
While migration is happening, new writes go straight to the new committee. They don't go through the old committee. This means new data immediately benefits from the new committee structure while migration of old data proceeds in parallel.
This creates natural separation. New blobs are distributed across the new validator set from day one. They don't need migration later. Old blobs migrate gradually.
The system naturally transitions to new state without disrupting the write path.
Handling Committee Changes
Committee rotation happens for multiple reasons. Some validators leave. Some are slashed for misbehavior. The network grows and new validators join. All of these create pressure to rebalance committees.
Walrus handles each scenario through the dual-committee migration. Leaving validators finish their custody obligations and are replaced. Slashed validators are kicked out and their blobs are reallocated. New validators gradually receive blobs to backfill their capacity.
The system adapts to changing validator sets without hiccups.
Prioritized Migration
Not all blobs have the same importance. Some are critical—referenced constantly by applications. Others are archival—rarely accessed. Walrus can prioritize migration of critical blobs.
Critical blobs migrate first. They're replicated to the new committee quickly. By the time old validators go offline, critical data is already safely in the new committee.
Less critical blobs migrate more slowly. The system trades off speed for critical data versus resource efficiency for archival data.
Bandwidth Optimization During Migration
Walrus doesn't just copy entire blobs from old committee to new committee. It uses intelligent recovery to minimize migration bandwidth.
When new committee members need to receive a blob, they can receive just the slivers they're assigned to hold rather than full copies. They gather slivers from the old committee, verify against the Blob ID, and store only their pieces.
This reduces migration bandwidth to O(|blob|/n) per new committee member instead of O(|blob|) for full blob copies.
At terabyte scale with thousands of validators, this is the difference between sustainable and impossible migration overhead.
Self-Healing During Migration
If a blob gets lost in transit during migration, the self-healing mechanism activates. Remaining validators in both old and new committees work together to reconstruct the lost piece.
The blob is recovered before it causes an actual availability failure. From the outside, migration continues smoothly. The self-healing happens transparently.
This is defensive engineering. The system doesn't assume migration succeeds perfectly. It plans for failures and recovers automatically.
Economic Incentives Through Migration
Old committee members are paid until their blobs are fully migrated. Once a blob successfully reaches the new committee, the old validator's custody obligation ends and their payment stops.
This creates economic incentive for old validators to cooperate with migration. They want their custody obligations to end so they can move on to new assignments. Blocking or delaying migration extends their work without reward.
New validators get paid starting when they receive their first blobs. They're incentivized to receive quickly and efficiently.
Read Path During Migration
What happens if a client tries to read a blob that's being migrated? Walrus handles this transparently. The client can read from either old or new committee. As long as one has the blob, retrieval succeeds.
The read path is agnostic to which committee holds the blob. It queries both if needed. It gets data from whoever responds fastest.
Clients don't care about internal migration. They just get their data reliably.
Atomic Migration Guarantees
The on-chain handoff creates atomic migration. A blob is either fully in the old committee or fully migrated to the new committee. There's no state where it's partially migrated and vulnerable.
If migration to the new committee hasn't completed, the blob remains in the old committee. The system doesn't transition until the new committee has provable custody.
This atomic property means data is never in an undefined state.
Massive Scale Migration
Consider a scenario where the network grows from 1,000 validators to 10,000. That's a massive rebalancing. Terabytes of blobs need to be re-assigned from old committees to new committees.
In traditional systems, this would require a maintenance window. The network would stop accepting writes. Migration would complete. Then normal operations resume.
Walrus handles this gracefully. New validators join and gradually receive blobs. New writes go to new committees. Old blobs migrate slowly across epochs. The network never stops. There's no maintenance window.
Users experience no disruption.
Rollback Capability
If migration goes wrong—perhaps the new committee structure is inefficient or has bugs—Walrus can roll back. The old committee remains the source of truth until migration completes.
If the new committee is deemed inadequate, migration can be paused. Blobs can migrate back to the old committee. The system reverts to the previous stable state.
This fallback mechanism provides safety net. Migration can be attempted without risk of catastrophic failure.
Migration Verification
Any participant can verify migration progress by checking on-chain records. How many blobs have completed handoff? How many are in progress? Which validators are still responsible for which blobs?
This transparency means the community can monitor migration health. If migration stalls or is inefficient, it becomes visible. The network can diagnose problems and adjust.
Transparency enables community participation in ensuring migration succeeds.
Comparison to Traditional State Migrations
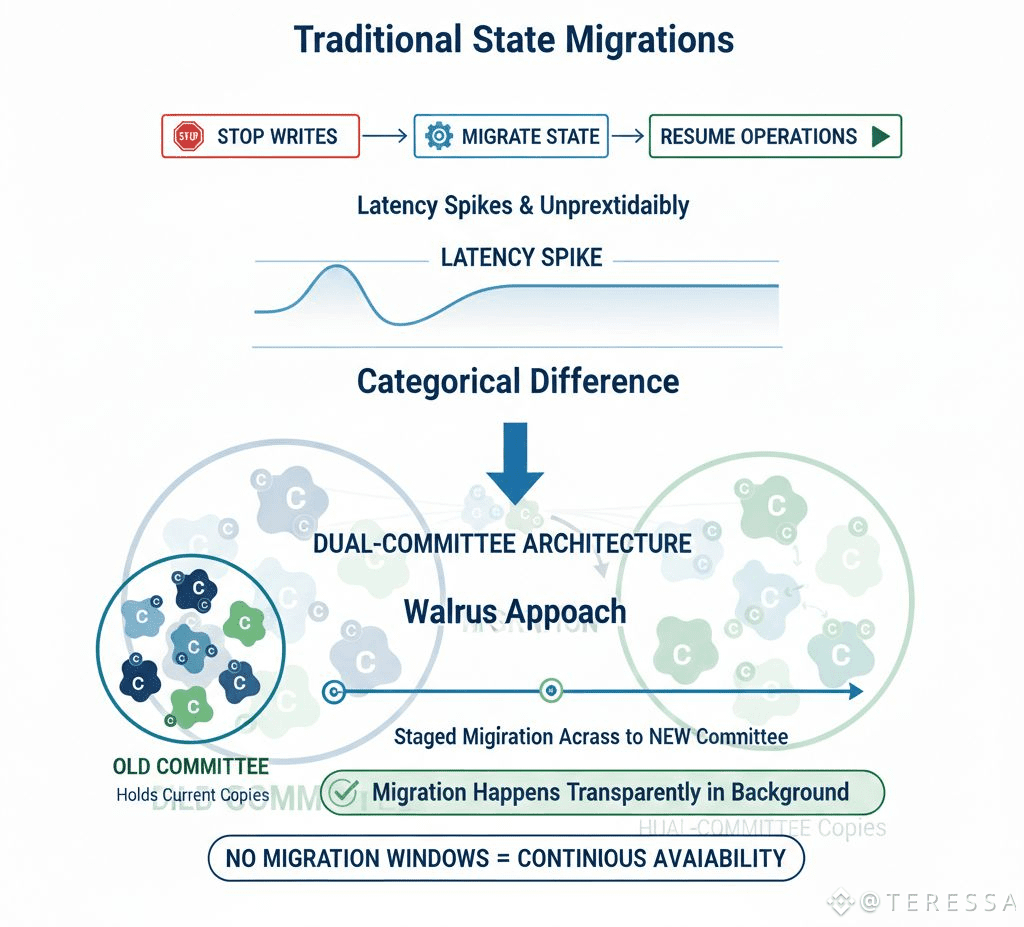
Traditional approaches: stop accepting writes, migrate state, resume operations. This causes latency spikes and unpredictability.
Walrus approach: dual-committee architecture, staged migration across epochs, writes continue to new committee, migration happens transparently in background.
The difference is categorical. Traditional systems have migration windows. Walrus has gradual background migration.
The Reliability Implication
A storage system that can migrate massive state without blocking writes is fundamentally more reliable. It can adapt to validator changes, network growth, and configuration improvements without user-facing disruption.
This is what production infrastructure looks like. Changes happen. The system adapts. Users don't notice.
@Walrus 🦭/acc state migration represents architectural maturity in decentralized storage. Massive state movements between committees happen without blocking writes through dual-committee architecture and staged epoch-wise migration. New blobs go to new committees. Old blobs migrate gradually. The read path works regardless of committee membership. The entire system remains available and responsive during rebalancing.
For storage infrastructure serving real applications that can't tolerate maintenance windows, this is foundational. You can scale validator sets, retire old validators, optimize committee structure, and improve the system—all while blobs are being written and read continuously. Walrus makes state migration invisible. Everyone else makes it a disruptive event.

