

Nobody argues with storage when it’s cheap.
The argument starts when availability has to compete with something else.
On Walrus, that moment usually doesn’t arrive with a failure. It arrives with a choice nobody scheduled. A blob that used to sit quietly suddenly matters at the same time the network is busy doing ordinary work.. rotations, repairs, churn that looks routine on a dashboard. Nothing exceptional. Just enough overlap to make availability feel conditional.
That’s when teams stop using the word “available” and start adding qualifiers without noticing.
Available if traffic stays flat.
Available if the next window clears cleanly.
Available if no one else needs the same pieces right now.
Walrus exposes that tension because availability here isn’t a vibe. It’s enforced through windows, proofs, and operator behavior that doesn’t pause because a product deadline is nearby. The blob doesn’t get special treatment just because it became important later than expected.
From the protocol’s point of view, nothing is wrong. Obligations are defined. Thresholds are met. Slivers exist in sufficient quantity. Repair loops run when they’re supposed to. The chain records exactly what cleared and when.
From the builder’s point of view, something shifted.
Retrieval still works, but it’s no longer boring. Latency stretches in places that didn’t stretch before. A fetch that used to feel deterministic now feels like it’s borrowing time from something else in the system. Engineers start watching p95 more closely than they admit. Product quietly asks whether this path really needs to be live.
Nobody writes an incident report for that.
They write compensations instead.
A cache gets added “just until things settle.”
A launch plan starts including prefetch steps that didn’t exist before.
A supposedly decentralized path becomes the fallback instead of the default.
Walrus didn’t break here. It stayed strict.
What broke was the assumption that availability is something you claim once and then stop thinking about. On Walrus, availability is an obligation that keeps reasserting itself at the worst possible time... when demand spikes, when operators are busy, when repairs are already consuming bandwidth.
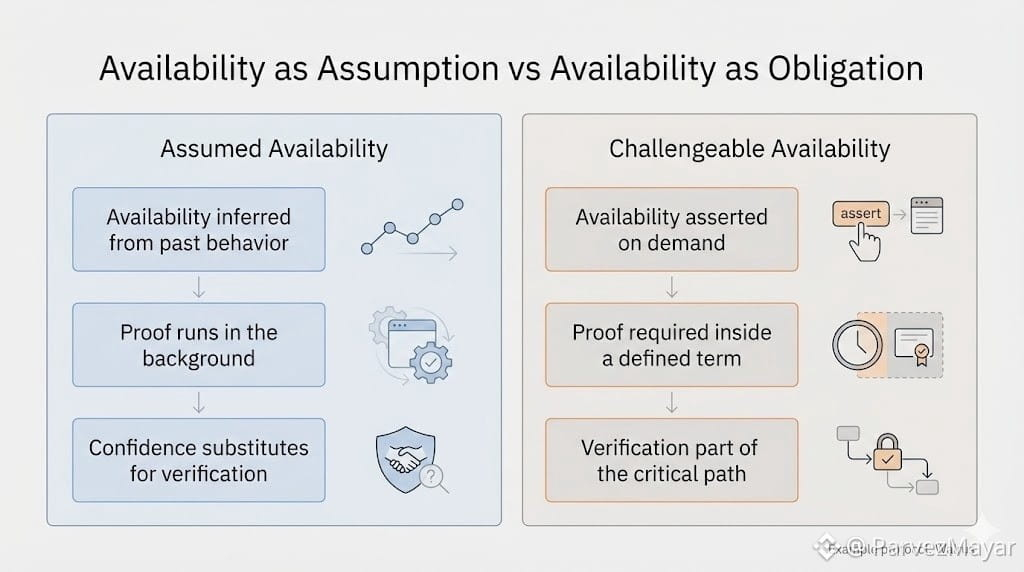
That’s the uncomfortable part. Availability isn’t isolated from load. It competes with it.
When reads and repairs want the same resources, the system has to express a priority. And whatever that priority is, builders will learn it fast. Not by reading docs. By watching which requests get delayed and which ones don’t.
Over time, that learning hardens into design.
Teams stop asking “can this blob be retrieved?”
They start asking “is this blob safe to depend on during pressure?”
Those are not the same question.
Walrus doesn’t smooth that distinction away. It lets correctness and confidence diverge long enough for builders to feel the gap. The data can be there, provably so, and still fall out of the critical path because nobody wants to renegotiate availability under load.
That’s the real risk surface.
Not loss.
Not censorship.
Not theoretical decentralization debates.
It’s the moment availability turns into something you have to manage actively instead of assuming passively.
Most storage systems delay that realization for years.
Walrus surfaces it early, while teams can still change how they design—before “stored” quietly stops meaning “safe to build on.”