
@Vanarchain Когда люди говорят, что хотят «AI-родные dApps», они обычно имеют в виду что-то проще и более неудобное: им надоела программное обеспечение, которое забывает. Им надоело оборудование, которое может «генерировать», но не может оставаться последовательным, не может держать нить, не может учиться, не превращаясь в кошмар для конфиденциальности, и не может действовать, постоянно прося разрешения, как нервный стажер. Прошлый год вынес это недовольство на поверхность. Агенты стали лучше в выполнении задач, но большинство из них по-прежнему ведут себя так, будто у них амнезия. Они могут составлять проекты, торговать, подводить итоги, маршрутизировать заявки, даже координировать действия с другими агентами, но в тот момент, когда вы перезапускаете процесс, переключаете модели или перемещаете устройства, интеллект вытекает из системы.
Вот почему формулировка Vanar начала находить отклик у людей, которые действительно строят: относитесь к памяти и рассуждению как к инфраструктуре, а не как к приятной функции, прикрепленной к приложению. В собственных материалах Vanar цепь позиционируется как "созданная с нуля для поддержки ИИ-агентов", с нативной поддержкой ИИ-нагрузок и примитивов, таких как векторное хранилище и поиск по сходству, встроенными в стек. Часть, которая имеет значение для меня, - это следствие: если сама цепь предполагает, что ваши приложения будут интеллектуальными, тогда самые полезные dApps перестают выглядеть как статические интерфейсы и начинают выглядеть как системы, которые могут помнить, предсказывать и координировать под реальным давлением.
Самый конкретный "AI-родной" шаг, на который постоянно указывает Vanar, - это Neutron. Neutron не представлен как еще один уровень хранения, куда вы размещаете файлы и надеетесь, что ссылки не испортятся. Он описывается как превращение файлов и разговоров в "программируемые семена", сжимающие и структурирующие данные так, чтобы они стали доступными для запросов и готовыми для агентов. Vanar ставит резкую цифру на это: сжатие 25 МБ до 50 КБ и даже называет коэффициент сжатия 500:1 операционной целью, а не демонстрацией в лаборатории. Верите ли вы в каждое маркетинговое утверждение или нет, цель ясна: сделать данные достаточно маленькими для легкого обмена, организованными для анализа и надежными для проверки. Доверие - это тихое узкое место в каждой истории об агентах. Большинство "предсказательных инструментов" сегодня умные, пока не ошибаются, а затем становятся опасными, потому что не могут показать свою работу. Язык Neutron от Vanar сильно опирается на доказательства и проверяемость: семена представлены как "полностью проверяемые", а система говорит о криптографических доказательствах и "доказательной надежности", так что то, что вы получаете, остается действительным, даже когда оно сильно сжато. В документации та же философия появляется в более трезвой форме: семена могут храниться вне цепи по умолчанию для скорости, с дополнительным уровнем в цепи для проверки, владения и долгосрочной целостности, плюс такие вещи, как неизменяемая метаинформация, отслеживание владения и следы аудита. Мне нравится это разделение, потому что оно признает правду, с которой живут строители: не все принадлежит в цепи, но те вещи, которые имеют наибольшее значение, часто нуждаются в окончательной, устойчива к подделке опоре.
Доверие - это тихое узкое место в каждой истории об агентах. Большинство "предсказательных инструментов" сегодня умные, пока не ошибаются, а затем становятся опасными, потому что не могут показать свою работу. Язык Neutron от Vanar сильно опирается на доказательства и проверяемость: семена представлены как "полностью проверяемые", а система говорит о криптографических доказательствах и "доказательной надежности", так что то, что вы получаете, остается действительным, даже когда оно сильно сжато. В документации та же философия появляется в более трезвой форме: семена могут храниться вне цепи по умолчанию для скорости, с дополнительным уровнем в цепи для проверки, владения и долгосрочной целостности, плюс такие вещи, как неизменяемая метаинформация, отслеживание владения и следы аудита. Мне нравится это разделение, потому что оно признает правду, с которой живут строители: не все принадлежит в цепи, но те вещи, которые имеют наибольшее значение, часто нуждаются в окончательной, устойчива к подделке опоре.
Когда вы это принимаете, вы можете увидеть, как "агенты" становятся больше, чем просто модное слово. Они становятся новым пользовательским интерфейсом для финансов, рабочих процессов и соблюдения норм - областей, где забывание дорого. Vanar явно описывает семена Neutron как способные "запускать приложения", инициировать смарт-контракты или служить входными данными для автономных агентов, и он даже утверждает, что выполнение ИИ в цепи встроено непосредственно в узлы валидаторов. Это амбициозное направление, но оно указывает на правильную проблему: агенты не должны быть прикреплены к хрупким внецепочечным трубопроводам, которые ломаются в тот момент, когда вас ограничивает скорость API или меняется структура базы данных.
Kayon - это другая половина аргумента о "реальной полезности": рассуждение. Vanar позиционирует Kayon как движок контекстного рассуждения, который превращает семена и корпоративные данные в "проверяемые инсайты, прогнозы и рабочие процессы", и он упоминает нативные API на основе MCP, которые подключаются к исследователям, панелям мониторинга, ERP и пользовательским бэкендам. Здесь предсказательные инструменты становятся менее мистическими и более практичными. Полезный прогноз в бизнесе редко звучит как "цена вырастет". Это "шаблон платежей этому продавцу выглядит аномально" или "эти кошельки вели себя так перед голосованием по управлению" или "этот кластер адресов недавно контактировал с санкционированными субъектами". Примеры Vanar сами наклоняются в этом направлении, включая мониторинг соблюдения норм в разных юрисдикциях и превращение результатов в оповещения и случаи.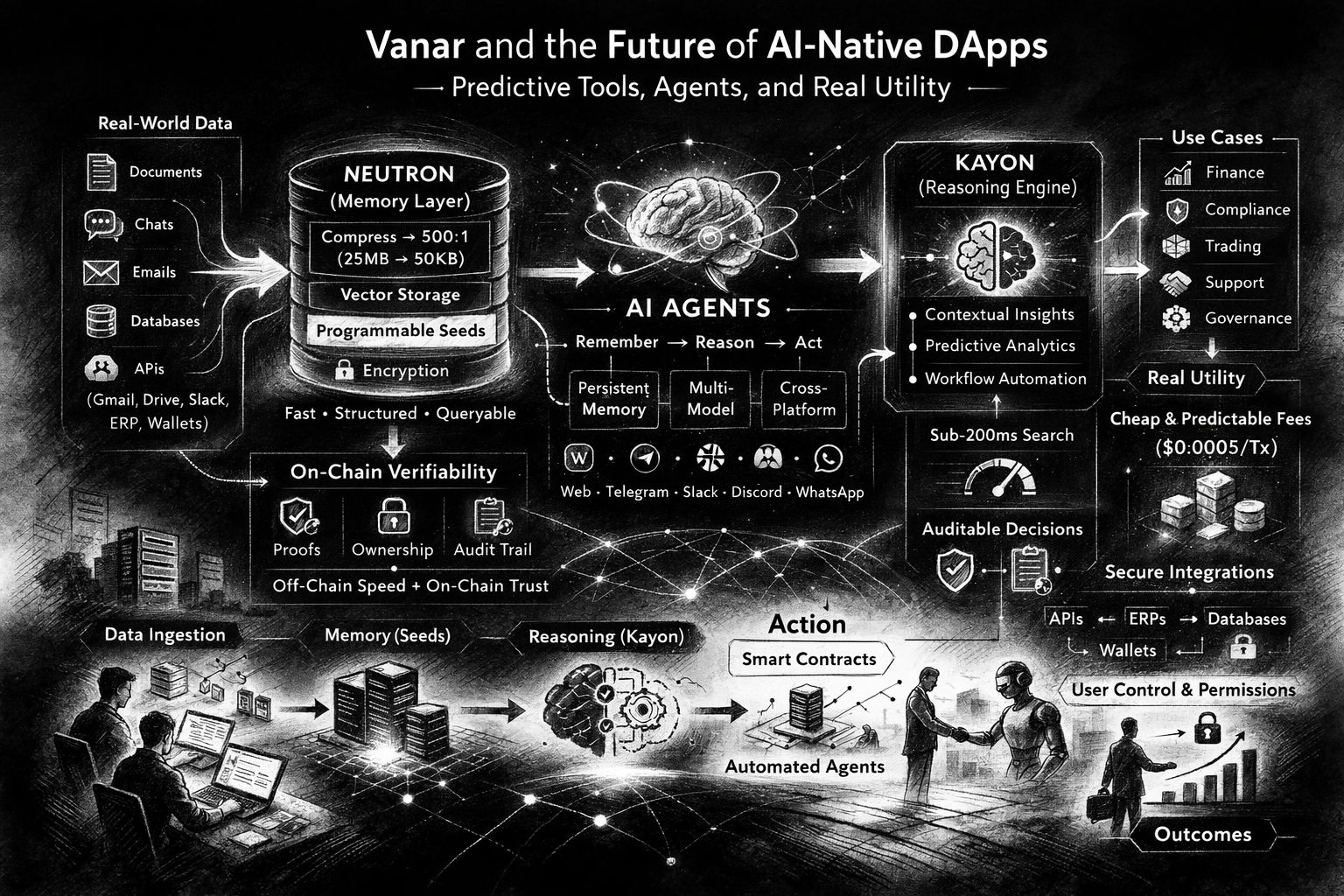
То, что делает эту тенденцию особенно актуальной, это то, что мир ИИ наконец начинает стандартизировать, как перемещается контекст. В тот момент, когда соединения в стиле MCP становятся нормой, вопрос переходит от "может ли мой агент делать X?" к "может ли мой агент надежно помнить то, что он должен помнить, и забывать то, что он должен забыть?" Документация Vanar по Neutron подчеркивает безопасные соединения, разрешения, предоставленные пользователем, зашифрованные токены, непрерывную синхронизацию и своевременное удаление отозванного контента - в основном скучное управление доступом к данным, которое требуют реальные развертывания. Список интеграций тоже говорит о многом: Gmail и Google Drive "в настоящее время доступны", с длинной дорожной картой систем рабочего места, которые появятся позже, от Slack и Notion до GitHub и банковских API. Это не крипто-список желаний. Это карта того, где на самом деле живет институциональная память.
Самая яркая иллюстрация проблемы памяти - и причина, по которой люди сейчас говорят об этом - это сама экосистема агентов. Страница Vanar, ориентированная на OpenClaw, описывает постоянную память для агентов через каналы обмена сообщениями, такие как WhatsApp, Telegram, Discord, Slack и iMessage, и она становится необычно конкретной в отношении производительности: семантический поиск менее 200 мс, извлечение на основе pgvector и 1024-мерные встраивания Jina v4 для мультимодального поиска по тексту, изображениям и документам. Также упоминается многопользовательская изоляция, пакеты для организации знаний и REST API с SDK на TypeScript. Эти детали важны, потому что они перемещают идею из "магии ИИ" в "поверхность разработчика". Вы можете представить, как строится агент поддержки, который не просто отвечает на запросы, а помнит историю клиента через каналы и может доказать, на какую версию политики он полагался, когда принимал решение.
Существует также более тихое ограничение, которое появляется, как только агенты начинают выполнять настоящую работу: предсказуемость затрат. Если ваша система зависит от миллионов мелких запросов и микро-действий, вы не можете запускать ее на сборах, которые ведут себя как смена настроения. Разработческие материалы Vanar указывают фиксированную целевую цену транзакции в размере 0,0005 долларов за транзакцию. А в документации даже есть описание архитектуры того, как агрегируются и очищаются данные о ценах токенов, как удаляются выбросы и как сборы обновляются на уровне протокола с периодичностью блока с резервным поведением, если поток данных выходит из строя. Это не гламурно, но это разница между агентом, который может действовать непрерывно, и тем, который приостанавливается, потому что экономика изменилась за ночь.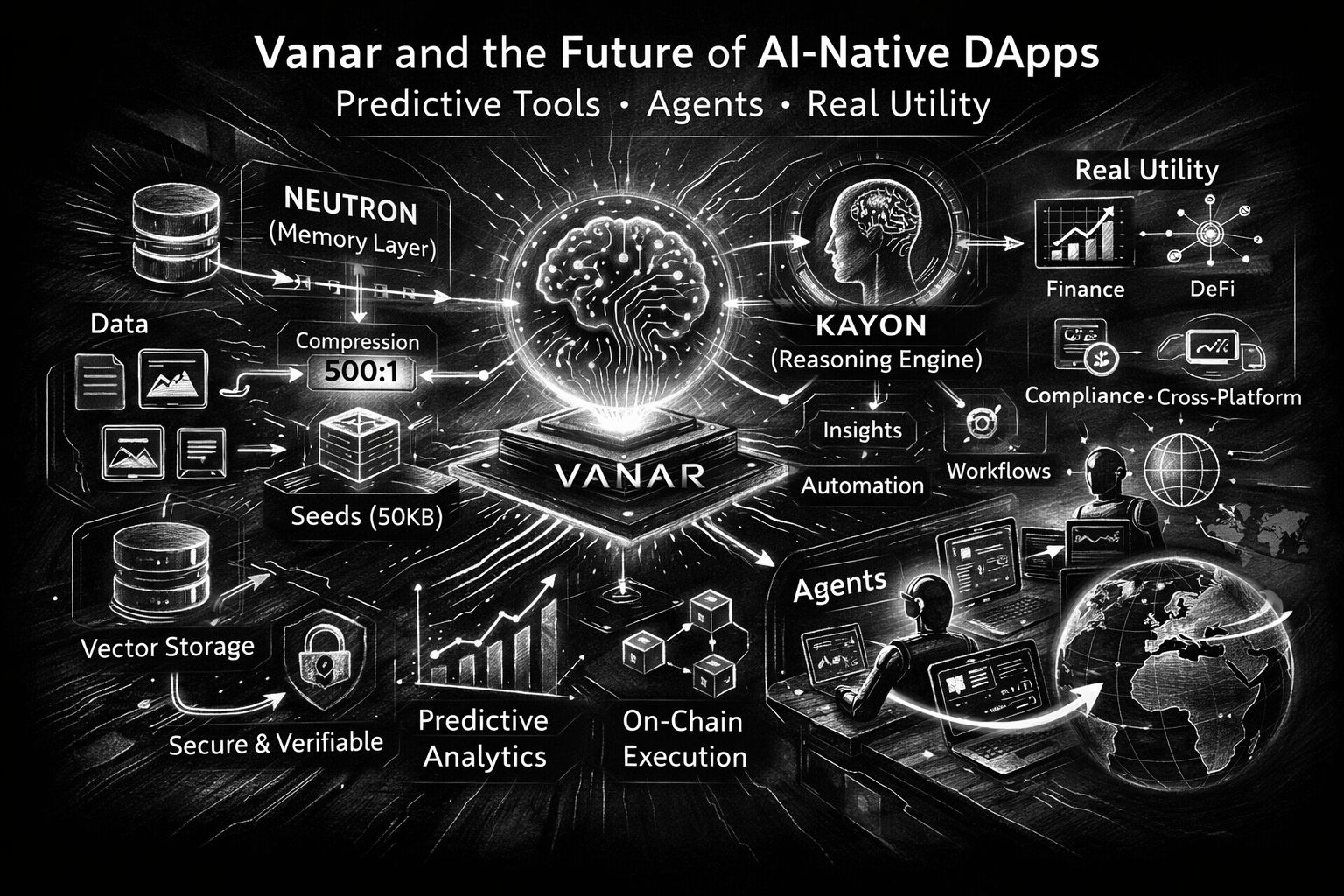
Если я отдалюсь, тезис Vanar о ИИ-родных dApps в основном такой: сделать знания долговечными, сделать рассуждения проверяемыми, сделать действия дешевыми и предсказуемыми, и дать строителям путь к интеграции с инструментами, где жизнь действительно происходит. Neutron превращает необработанные данные в компактные, поисковые семена с опциональной целостностью в цепи. Kayon превращает эти семена в вопросы, которые вы можете задать на обычном языке, а затем в рабочие процессы, которые вы можете защитить в аудите. И уровень агентов становится правдоподобным, когда память быстрая, переносимая и правильно разрешенная, а не заперта внутри контекстного окна одной модели.
Мой вывод, сколько бы это ни стоило, заключается в том, что следующая волна dApps не выиграет, чувствуя себя более футуристичной. Они выиграют, чувствуя себя более надежными. Предсказательные инструменты будут оцениваться не по тому, насколько умно они звучат, а по тому, насколько хорошо они остаются последовательными на протяжении нескольких недель использования. Агенты будут оцениваться не по одной впечатляющей демонстрации, а по тому, выживет ли их интеллект после перезапусков, миграций и изменения поставщиков модели. Если Vanar сможет продолжать переводить свой стек на скучные, повторяемые результаты - память, которая не гниет, рассуждение, которое можно проверить, и затраты, которые не удивляют вас - тогда "AI-родные dApps" перестанет быть нарративом и начнет быть категорией, которой люди действительно могут доверять.