Я начал писать эту статью с простой мысли: объяснить, как я понимаю методологию Pyth Network, стараясь сделать это как можно более ясно и с возможностью повторного использования; одновременно поместить это в контекст более широкого рынка данных и институциональных приложений. В последние годы я долго следил за эволюцией оракулов и коммерциализацией данных, постепенно сформировав простое, но полезное суждение: действительно важное в цепочке поставок данных — это не декоративная «децентрализация», а надежное производство и проверяемая доставка. Когда предложение и спрос могут напрямую взаимодействовать в цепочке, в аудируемой форме, ценность легче стабильно улавливать.
Для меня Pyth - это не «еще один компонент ценовых котировок», а производственная линия ценовых данных, которая начинается от источника и распределяется по многим цепям. Традиционная модель больше похожа на «посредника информации», где агрегаторы, сборщики и промежуточные узлы последовательно пересылают данные; задержки, неопределенности и отсутствие отслеживаемости часто становятся питательной средой для системных рисков. Pyth использует модель первичных данных, позволяя биржам, маркет-мейкерам и профессиональным поставщикам данных подписывать и публиковать прямо на цепи; затем через Pythnet агрегирует, проверяет и вычисляет доверительные интервалы и распределяет по запросу для заемных, опционных, синтетических активов, индексов и других приложений. Я обобщаю этот путь как: не быть мегафоном, а строить «проверяемую производственную линию цен».
Один, потолок трассы и реальные потребности.
Ценность рынка данных исходит с двух концов: с одной стороны - качество и своевременность от источника, с другой - доступность и чувствительность к затратам для потребителей. В традиционных финансах распределение данных и актуальные рыночные данные являются долгосрочными стабильными платными категориями; переходя в мир криптовалют, спрос не изменился, только требования к «проверяемости» и «программируемости» стали выше. Стратегии заемного расчета требуют низкой задержки и стабильных обновлений; оценка опционов зависит от разумной оценки волатильности; синтетические активы требуют согласованности цен в условиях высокой волатильности. Эти основные требования создают постоянный спрос на высококачественные ценовые котировки, и это является основной мотивацией для моих постоянных исследований и креативной работы. Видение Pyth, начиная с DeFi, стремится к более широким услугам рыночных данных; я считаю, что это «трудный, но правильный» путь.
Два, операционная распаковка продуктов и архитектуры.
Я обычно разбиваю любой продукт данных на пять этапов: первичное производство, проверенная публикация, агрегированная проверка, распределение и расчет, обратная оптимизация. В Pyth первичное производство происходит от ведущих бирж, маркет-мейкеров и профессиональных поставщиков данных; они выступают в роли «публикаторов» на цепи, каждая сообщение содержит подпись источника, что является предпосылкой для отслеживаемости. Проверенная публикация основывается на Pythnet, где проводятся дублирование, очистка, выравнивание временных меток и вычисление доверительных интервалов на основе многопоточных данных. После агрегированной проверки обновления цен распределяются по приложениям на различных цепях через межцепочечные каналы; механизм «подписки и запросов» позволяет пользователям определять частоту триггеров в зависимости от предпочтений по затратам и срокам, уменьшая ненужные сделки и шум в сети. Этот дизайн помещает «скорость» и «устойчивость» под один и тот же инженерный цель. По моему опыту, разработчики, если разберутся в структуре полей объекта цены, временной точности и доверительного интервала, могут легко завершить интеграцию.
На этой структурной диаграмме показаны ключевые узлы и проверяемые точки данных от источника до применения, что облегчает коммуникацию с командой о деталях реализации и границах.
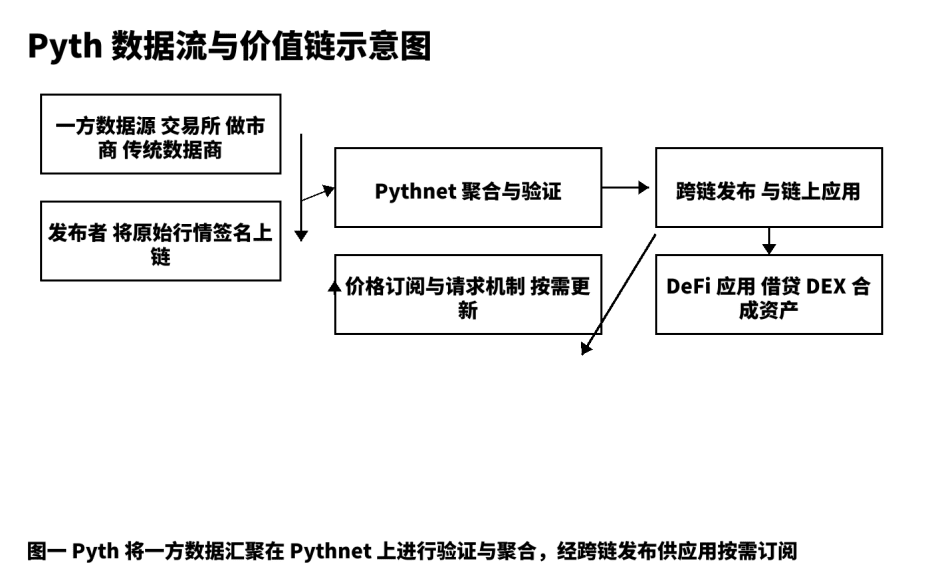
Три, сравнение по пяти измерениям и выбор стратегии.
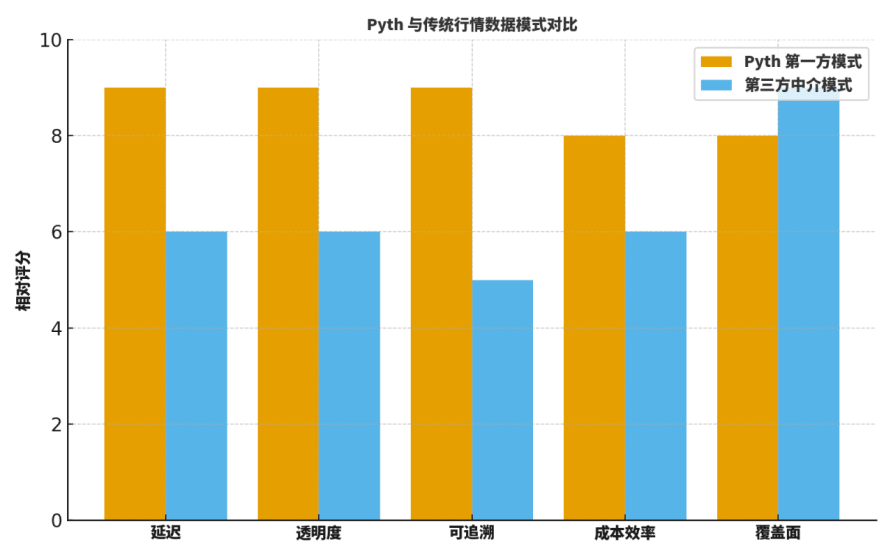
Многие студенты спрашивают: каковы различия между Pyth и традиционными «посредническими оракулами» или старыми поставщиками данных? Обычно я сравниваю по пяти измерениям: задержка, прозрачность, отслеживаемость, эффективность затрат, охват.
Первое, что касается задержки, прямая передача от первичного источника значительно уменьшает количество промежуточных шагов, что проявляется в более быстром обновлении;
Второе, что касается прозрачности и отслеживаемости, подпись источника и проверяемый процесс агрегирования обеспечивают детализированную видимость;
Третье, с точки зрения эффективности затрат, это исключает значительные затраты на внешнюю выборку и многослойную пересылку;
Четвертое, в плане охвата, традиционные гиганты все еще имеют преимущества в исторических категориях и географическом распределении;
Пятое, в отношении инженерного сотрудничества, «подписка по запросу» Pyth способствует взаимодействию с параметрами рисков и системой уведомлений.
Поэтому стратегия не является «однородной», а предполагает приоритетное использование Pyth в ключевых сценариях: заем, расчет, опционы, синтетические активы и т.д. - именно это я считаю «выставочным залом» при выборе.
Чтобы помочь читателю установить интуицию, я предоставляю сравнительный график «относительных оценок», это не абсолютный вывод, но очень подходит для точки начала обсуждения и шаблона анализа.
Четыре, «второй этап» в дорожной карте: подписка на данные уровня института.
В практике создания контента и консультациях я разделяю путь Pyth на два взаимосвязанных этапа:
Первый этап - создание стандартов ценовых котировок для высокоскоростных сценариев DeFi, основной акцент на качестве и скорости;
Второй этап - переход к продуктам «подписки на данные уровня института», включая: соглашения об уровне обслуживания (SLA) с задержкой, проверяемые журналы, системы меток аномалий для управления рисками, модульный расчет и интерфейсы сверки.
Этот этап расширяет инженерные возможности в сервисные: связывает ценовые сигналы с организационными способностями управления, соблюдения и рисков; также связывает «устойчивый доход» с управлением сетью. Меня особенно интересует, сможет ли повторяемая модель услуг работать, например:
(1) Предоставление подписок с несколькими уровнями задержки и частоты обновлений;
(2) Источник, подпись, временная метка и список агрегаторов, участвующих в каждом обновлении цен, могут быть экспортированы и оставлены в журнале;
(3) Метки аномалий для управления рисками, которые можно воспроизвести, анализировать и связывать с событиями риска.
Эти детали определяют, готовы ли институты к миграции и до какой степени они готовы платить.
Пять, полезность токена и экономический замкнутый цикл.
Чтобы оценить, здоров ли сеть, нужно обратить внимание на две вещи: первое, связаны ли доходы с созданием ценности; второе, связаны ли стимулы с долгосрочным качеством. Для $PYTH я понимаю это как тройную роль: топливо для производства и обслуживания данных; вес управления и верификации; рычаг расширения экосистемы. Публикаторы и обслуживающие участники участвуют через предсказуемые токеновые стимулы; доход сети поступает от подписки на данные и использования, и распределяется через управление между обслуживанием, стимулами и расширением экосистемы. На основе этого я нарисовал схему «распределения полезности», конкретные пропорции могут быть немного скорректированы по мере эволюции управления, но принцип остается прежним: публикация и обслуживание занимают значительную долю; управление и верификация обеспечивают стабильность; экосистема и сообщество отвечают за расширение и преодоление границ.
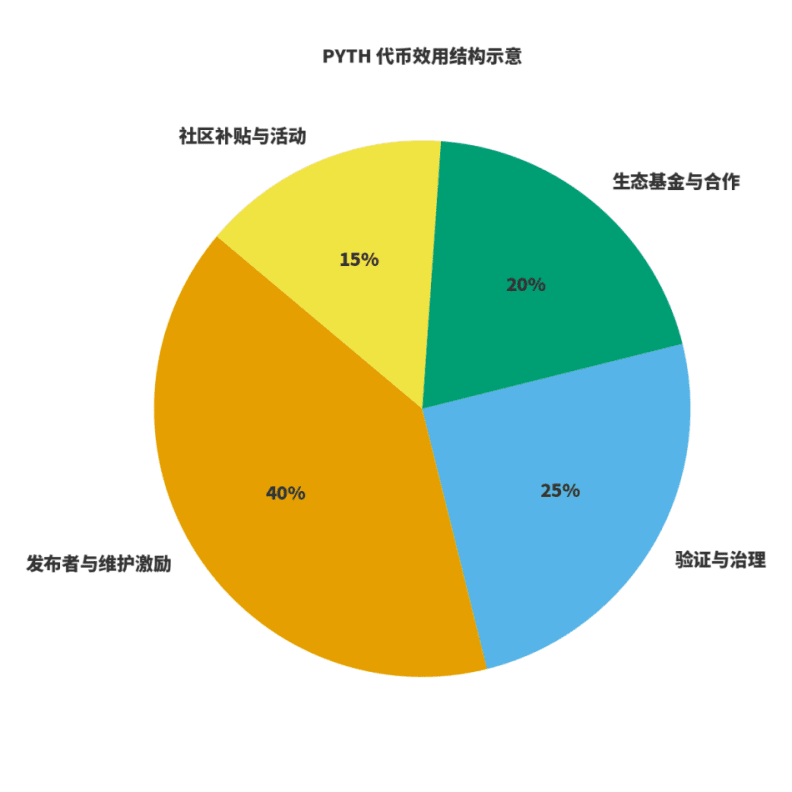
Шесть, список внедрения для институтов.
Основываясь на предыдущем опыте интеграции, я составил список, который можно использовать напрямую:
Первое, четко определить область данных и границы услуг: какие являются базовыми ценами, а какие относятся к уровню добавленной стоимости;
Второе, согласовать соглашения об уровне обслуживания: включая задержки обновлений, стабильность, обработку аномалий, стратегию предупреждений и планы по восстановлению после сбоя;
Третье, предоставить проверяемую журнализацию: регистрировать источник каждой обновления цен, изменения доверительных интервалов и метки аномалий;
Четвертое, интегрировать внутренние системы управления рисками и обратного тестирования: подключить поток цен к системе воспроизведения, проверяя стабильность стратегий при различных порогах и окнах;
Пятое, стандартизировать расчеты и сверку: институты больше заботятся о предсказуемых сроках расчетов и понятных деталях сверки.
В этом списке явным преимуществом Pyth является проверяемость от «источника до агрегирования», что может значительно сократить время оценки соблюдения и управления рисками.
Семь, карта рисков и дизайн антикрихкости.
Я делю риски на три категории: аномальные публикации от источника, аномалии синхронизации между цепями и увеличение задержки в условиях экстремальных рыночных условий. Соответствующие меры смягчения должны быть «институционализированы» в инженерии. Часто используемые мною методы включают: многократные подписки с проверкой порога; автоматическое снижение плеча, связанное с доверительными интервалами; временное взвешивание и защита от проскальзывания на стороне торговых контрактов; а также тренировки на экстремальные рыночные условия раз в квартал, с унифицированными сценариями воспроизведения и шаблонами анализа. Эти дисциплинарные инженерные практики в сочетании с проверяемыми журналами Pyth могут значительно повысить устойчивость системы.
Восемь, рекомендации по повествованию для создателей контента и разработчиков.
Я всегда подчеркиваю: ценность создателя заключается в том, чтобы перевести сложную инженерную ценность на язык, который читатели и пользователи «могут понять и использовать». Если говорить о Pyth, я рекомендую начать с «изменения парадигмы», а не оставаться на уровне «спора оракула». Говорить о том, как он согласовывает предложение и спрос с проверяемым способом на цепи; говорить о том, как он снижает хвостовые риски через доверительные интервалы и визуализированные процессы агрегации; говорить о том, как он соединяет возможности услуг и коммерческий замкнутый цикл через «подписку уровня института». Это более убедительно для практиков, чем просто перечисление показателей.
Девять, показатели, которые я буду отслеживать в следующем году.
Первое, широта и глубина подключения к экосистеме: охват четырех крупных проектов в области заемов, синтетических активов, опционов и индексов;
Второе, прогресс продуктовой подписки для институтов: задержка, соглашения об уровне обслуживания, проверяемые журналы обновляются по расписанию;
Третье, прозрачность доходов и распределения по протоколу: формируется ли общедоступный проверяемый стандарт данных;
Четвертое, прогресс соблюдения в разных юрисдикциях: включая соблюдение правил экспорта данных и соблюдение финансовых услуг.
Эти показатели напрямую влияют на темы и ритм, которые я выбираю в контенте, и также повлияют на мою долгосрочную оценку диапазона PYTH.
Десять, руководство для разработчиков: от нуля до одного.
Чтобы помочь новичкам быстрее продвигаться, я предлагаю набор из трех шагов.
Первый шаг - завершить один вызов подписки на цены в тестовом окружении; понять структуру цен, временную точность и поля доверительного интервала;
Второй шаг - встроить «стратегию подписки и запросов» в контракты или торговые роботы, сравнить различия в доходах при различных порогах и окнах через систему обратного тестирования;
Третий шаг - настроить мониторинг уведомлений; установить пороги предупреждений на основе показателей управления рисками и включить метки аномалий в воспроизведение и анализ.
Когда вы завершите три шага, вы не только начнете использовать Pyth, но и внедрите «идею проверяемых данных» в код.
Одиннадцать, сравнение отраслей и пространство для сотрудничества.
Я не поддерживаю нулевую сумму «взаимных потерь». В сценариях с более широким охватом, но менее строгими временными требованиями, традиционные поставщики данных все еще имеют преимущества; в то время как в сценариях, чувствительных к задержке и проверяемости, первичная модель Pyth имеет больше шансов на успех. В будущем я ожидаю, что разработчики будут комбинировать различные потоки данных модульным образом, принимая во внимание целевую функцию и динамически балансируя между затратами и производительностью.
@Pyth Network #PythRoadmap $PYTH